--22.CNN을 활용한 이미지분류.ipynb--
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import os
import tensorflow as tf
from tensorflow import keras
실행마다 동일한 결과를 얻기 위해 케라스에 랜덤 시드를 사용하고 텐서플로 연산을 결정적으로 만듭니다.
tf.keras.utils.set_random_seed(42)
tf.config.experimental.enable_op_determinism()
base_path=r'/content/drive/MyDrive/dataset'
데이터 준비
from sklearn.model_selection import train_test_split
(train_input, train_target), (test_input, test_target) = \
keras.datasets.fashion_mnist.load_data()
(48000, 28, 28) => (48000, 28, 28, 1) : (batch, height, width, channel)
train_scaled = train_input.reshape(-1, 28, 28, 1) / 255.0
train_scaled, val_scaled, train_target, val_target = \
train_test_split(train_scaled, train_target, test_size=0.2, random_state=42)
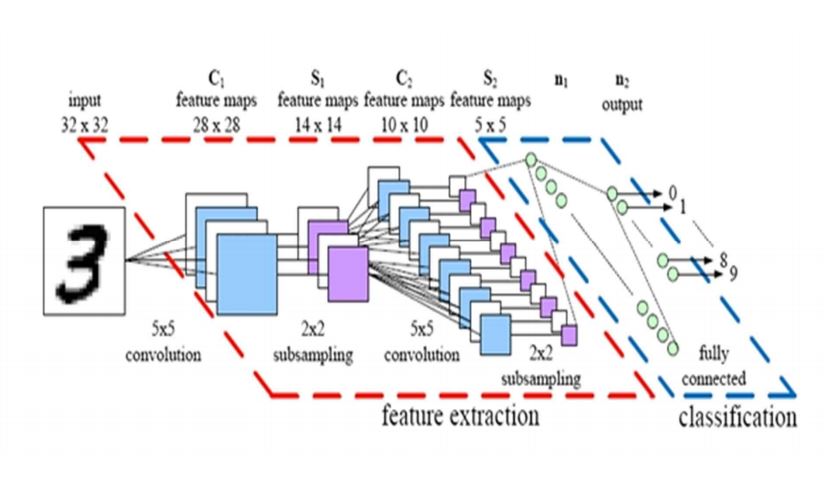
CNN 만들기
CNN 위 두 파트
-
Feature Extraction
-
Classification

model = keras.Sequential()
▶ Feature Extraction
model.add(keras.layers.Input(shape=(28, 28, 1)))
Conv2D : (3, 3) 커널의 크기 x 32개 필터, same padding, 활성화 함수 relu, 입력 차원(28, 28, 1)
model.add(keras.layers.Conv2D(32, 3, padding='same', activation='relu'))
Q] 출력 shape 은 어케 되나? -> (28, 28, 32) ※ 나중에 각 층의 출력 크기를 summary() 로 확인해보자
Q] 모델 파라미터 개수는? -> (3 x 3 x 1 + 1(bias)) x 32개 => 320
MaxPooling2D : 풀링크기 (2, 2)
model.add(keras.layers.MaxPooling2D(2))
출력 shape => (14, 14, 32)
Conv2D : 두번째 합성곱, 64개의 필터, 커널크기 (3,3), 나머지 동일
model.add(keras.layers.Conv2D(64, 3, padding='same', activation='relu'))
Q] 출력 shape 는? -> (14, 14, 64)
Q] 모델 파라미터 개수는? -> (3 x 3 x 32 + 1(bias)) x 64 = 18496
MaxPooling2D :
model.add(keras.layers.MaxPooling2D(2))
출력 shape => (7, 7, 64)
▶ Classification
Flatten
model.add(keras.layers.Flatten())
출력 shape? => 7 x 7 x 64 => (3136,)
hidden Dense layer
model.add(keras.layers.Dense(100, activation='relu'))
출력 shape? => (100,)
모델 파라미터 개수는? => (3136(입력) + 1(bias)) x 100(출력) = 313700
DropOut
model.add(keras.layers.Dropout(0.4))
출력 shape? => (100,)
ouput Dense layer : 10개의 뉴런
model.add(keras.layers.Dense(10, activation='softmax'))
출력 shape? => (10,)
모델 파라미터 개수는? => (100 + 1(bias)) x 10 = 1010
model.summary()
keras.utils.plot_model(model)
keras.utils.plot_model(model, show_shapes=True,
to_file=os.path.join(base_path, 'cnn-architecture.png'), dpi=200)
모델 컴파일, 훈련
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics='accuracy')
checkpoint_cb = keras.callbacks.ModelCheckpoint(os.path.join(base_path, 'best-cnn-model.keras'),
save_best_only=True)
early_stopping_cb = keras.callbacks.EarlyStopping(patience=2,
restore_best_weights=True)
history = model.fit(train_scaled, train_target, epochs=20,
validation_data=(val_scaled, val_target),
callbacks=[checkpoint_cb, early_stopping_cb])
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(['train', 'val'])
plt.show()
model.evaluate(val_scaled, val_target)
[0.21702449023723602, 0.9195833206176758]
Epoch 6/20
- loss: 0.2154 - accuracy: 0.9198 - val_loss: 0.2170 - val_accuracy: 0.9196
predict()
검증세트의 첫번째 샘플
plt.imshow(val_scaled[0].reshape(28, 28), cmap='gray_r')
plt.show()
fit(), predict(), evaluate() 메소드 모두 입력의 첫번째 차원은 batch 차원이어야 함!!
즉, 하나의 샘플을 전달 할 때에도 (28, 28, 1) 이 아니라 (1, 28, 28, 1) 이어야 한다.
preds = model.predict(val_scaled[0:1])
print(preds)
plt.bar(range(1,11), preds[0])
plt.xlabel('class')
plt.ylabel('prob.')
plt.show()
클래스 이름들의 리스트 준비
classes = ['티셔츠', '바지', '스웨터', '드레스', '코트',
'샌달', '셔츠', '스니커즈', '가방', '앵클 부츠']
classes[np.argmax(preds)]
test 세트로 모델의 일반화 성능
train 세트에 적용했던 것 처럼 '정규화' 와 shape 변경!!
test_scaled = test_input.reshape(-1, 28, 28, 1) / 255.0
model.evaluate(test_scaled, test_target)
