Modern CNN - 1x1 convolution의 중요성
개요
- ILSVRC, ImageNet Large-Scale Visual Rcognition Challenge, 이미지넷 대회 1등 모델들 볼 것
- 분류, 감지, 지역화 등 다양한 문제 있음
- 많은 데이터 있음
- 사람의 오차율은 5.1% 인데 2015 년 오차율은 3.5%, 딥러닝이 사람보다 좋아짐
- 해봐야 몇 년 안됐지만 모던이라 하자
- 발전할수록 네트워크는 더 깊어지고 파라미터 개수는 줄어듦
- 파라미터 개수와 네트워크 뎁스를 잘 보자
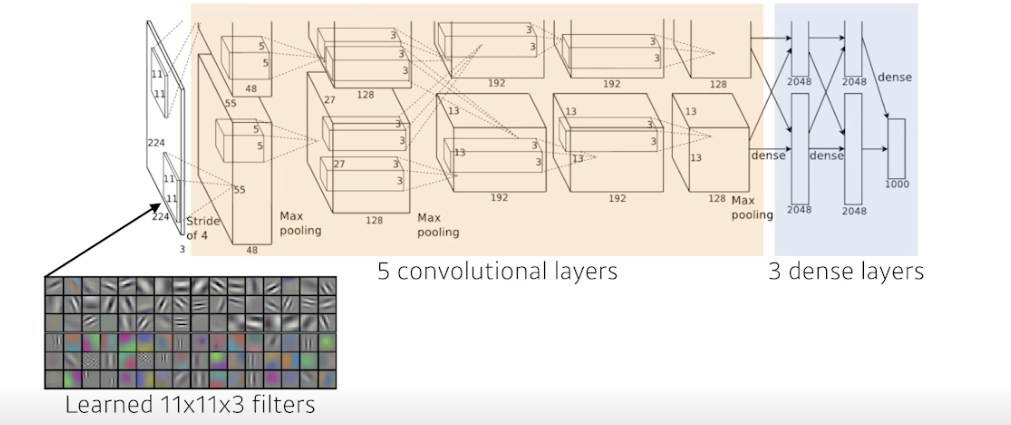
AlexNet
-
처음에 두개의 아웃풋이 나오는 이유 : 당시 기계 성능 문제로 나눠서 진행한 것
-
처음 11x11 이 사람입장에서 좋은 숫자는 아님, 하나의 컨볼루션 커널이 볼 수 있는 영역은 커지지만 더 많은 파라미터 필요
-
5개의 컨볼루션 레이어와 3개의 덴스레이어 = 8단 레이어
-
키 아이디어
-
Rectified Linear Unit (ReLU) activation
-
2 개의 GPU 사용
-
Local reponse normalization , Overlapping pooling
-
Data augmentation
-
Dropout
⇒ 요즘 흔히 사용하는 방법들을 제시한 것
-
-
ReLU Activation
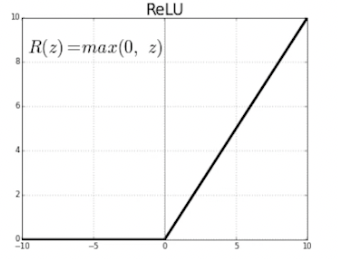
- 선형 모델의 특성 유지
- 경사하강법으로 최적화하기 용이
- generalization 에 좋음
- vanishing gradient problem 해결
- sigmoid 나 tanh 를 미분하면 범위가 [0, 1/4], 더 미분하면 계속 0 에 가까워지는 문제
VGGNet
- 특징
- 3x3 컨벌루션 필터 (stride = 1) 만 사용 (중요)
- 풀리 커넥티드 레이어를 위해 1x1 컨벌루션 사용 (안중요)
- dropout(p=0.5)
- VGG16, VGG19 사용
- 왜 3x3 컨벌루션?
- 컨벌루션이 사이즈가 크면 한 번에 많이 볼 수 있지만, 그것보다 사이즈를 작게하여 여러 뎁스로 더 보는게 나음
- Receptive field, 하나의 출력에 관여하는 입력 픽셀의 개수
- 컨벌루션이 사이즈가 크면 한 번에 많이 볼 수 있지만, 그것보다 사이즈를 작게하여 여러 뎁스로 더 보는게 나음
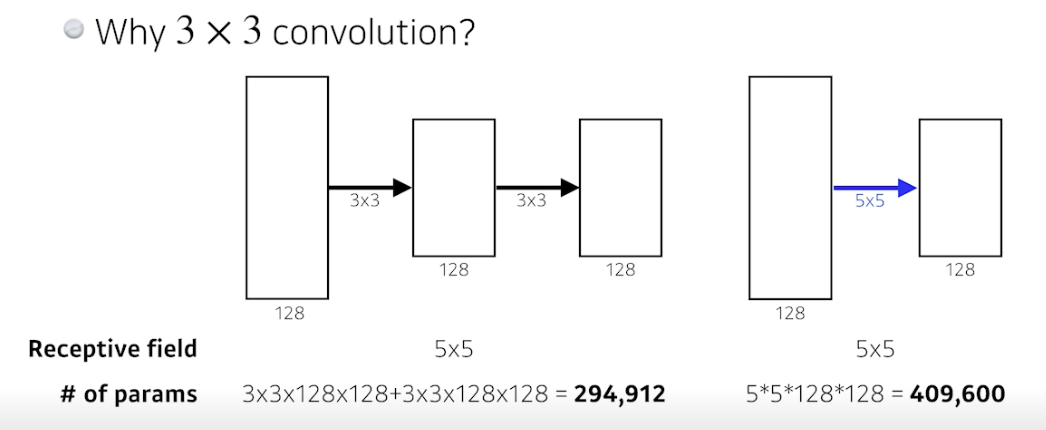
- 3x3 레이어를 두 개 쌓으면 9 * 2 = 18, 5x5 레이어 한 개 쓰면 25 이므로 파라미터 개수가 더 적음
GoogLeNet

- 특징
- NiN, Network in Network 구조
- Inception blocks 활용
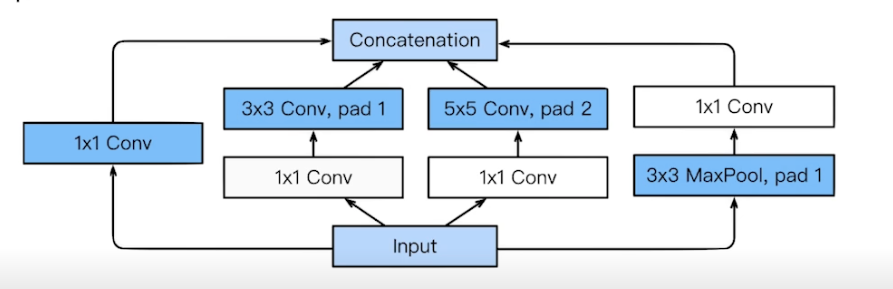
- 하나의 입력이 들어왔을 때 여러 개로 퍼졌다가 합쳐짐
- 각각의 패스를 보면 3x3 Conv 하기 전에 1x1 Conv 를 사용해줌 (중요)
- 파라미터 개수 줄여줌
- 어떻게?
- 1x1 convolution 은 채널방향으로 차원을 줄이는 효과가 있음
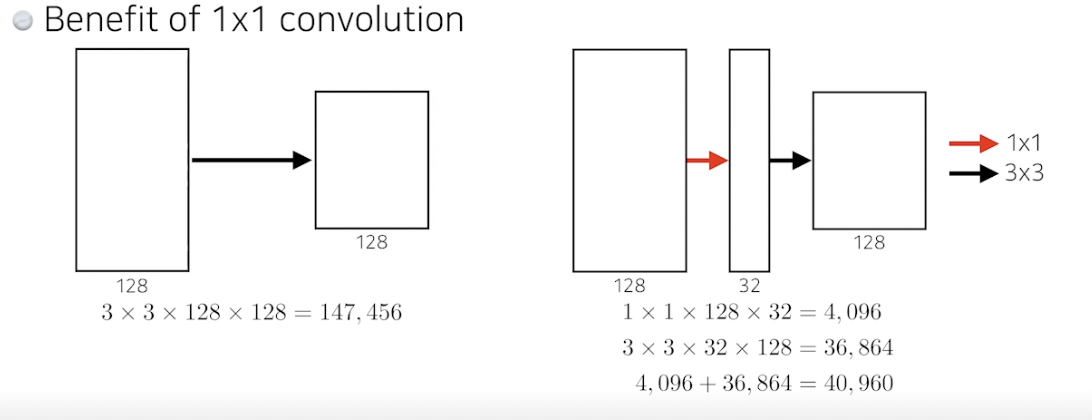
- 입력과 출력은 같지만 파라미터 개수 엄청 줄어듦
ResNet
- 오버피팅은 주로 파라미터 개수 때문에 야기됨, 근데 레이어가 깊은 모델은 오버피팅 때문이 아니라 그냥 레이어 적절한거보다 성능이 안나옴 (학습이 잘 안됨)
- Residual connection (Identity map)
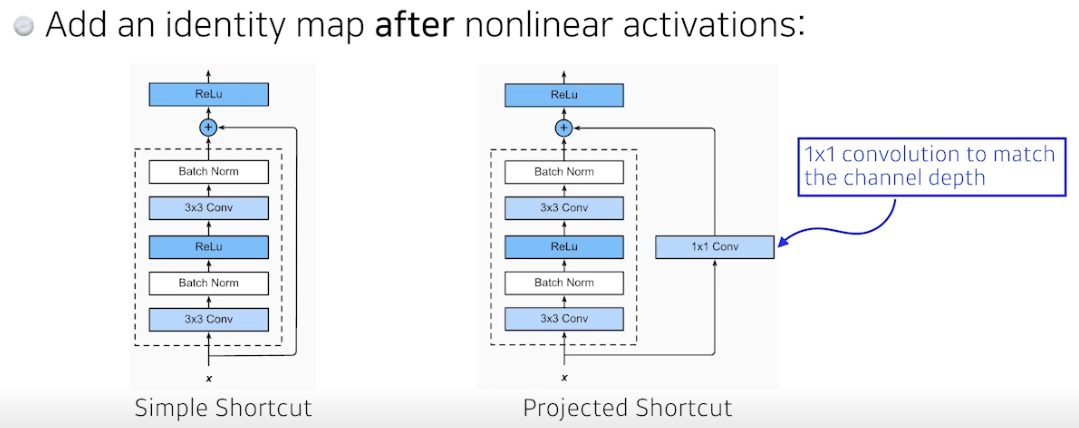
- 예측값에 x 를 더해줌
- 차이를 학습하기를 원함
- 덕분에 레이어 깊어져도 얕은 구조보다 학습 잘 됨
- projected shortcut 은 차원을 맞춰주기 위해 1x1 conv 사용하는 것, 근데 simple shortcut 더 사용함
- conv → batch norm → 활성화 구조인데 활성화 → BN 하는게 더 잘된다는 말도 있음
- Bottleneck architecture
- 구글의 NiN 과 비슷
- 3x3 하기 전에 1x1 로 줄이고, 3x3 하고 나서 1x1 로 늘려서 차원 낮춰줌
DenseNet
- ResNet 은 두 값을 더해주는 구조, DenseNet 은 더하지 않고 concatenate 해줌
- 문제는 채널이 커짐 → 파라미터 숫자가 커짐 → 중간에 한 번씩 채널을 줄여줌, 1x1 conv 사용
- Dense Block : 합치기
- Transition Block : 채널 줄이기
- 간단한 분류할 때 ResNet 이나 DenseNet 쓰면 성능 잘나옴
Summary
- VGG : repeated 3x3 blocks
- GoogLeNet : 1x1 convolution
- ResNet : skip-connetcion (원래값 더하기, 차이 학습)
- DenseNet : concatenation
Further Question
- 수업에서 다룬 modern CNN network의 일부는, Pytorch 라이브러리 내에서 pre-trained 모델로 지원합니다. pytorch를 통해 어떻게 불러올 수 있을까요?
import torchvision.models as models
resnet18 = models.resnet18(pretrained=True)Computer Vision Applications
Semantic Segmentation
- 이미지를 픽셀마다 분류하는 문제
- 일반적인 문제는 전체를 하나로 분류했다면, 세그멘테이션은 이미지 안에 다양한 픽셀들을 각자 레이블로 분류함
- 자율주행 등에 활용, 자동차, 사람, 인도, 차도 등 구분
- 지금까지는 Fully Convolutional Network 구조 배웠음, 컨벌루션 진행하다가 flat 하고 dense 진행 후 라벨 확인
- 이제는 dense 부분을 없애고 싶음, conv로 바꾸자! Convolutionalization
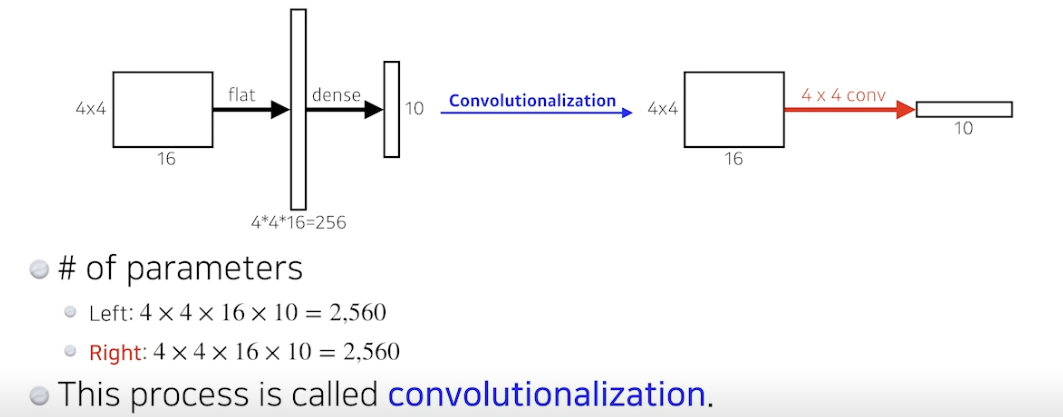
- flat 하고 dense 하는거나 conv 로 바꾸는거나 파라미터 개수 같음
- 사실은 같은거, 아무것도 달라진게 없음
- 왜할까?
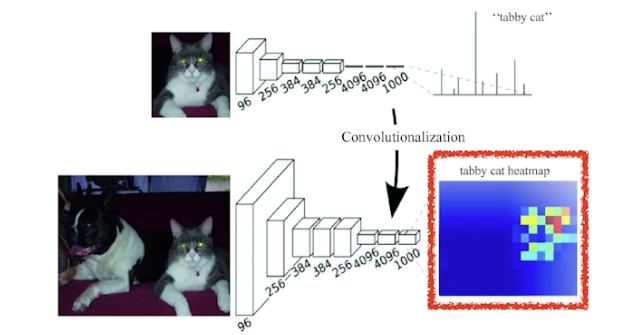
- 원래는 결과가 확률분포 식으로 단순 분류할 수만 있었다면, 이제는 히트맵에 분포가 나오게 됨 → 세그멘테이션 가능
- 해당 이미지에 고양이가 어디 있는지 나오게 됨
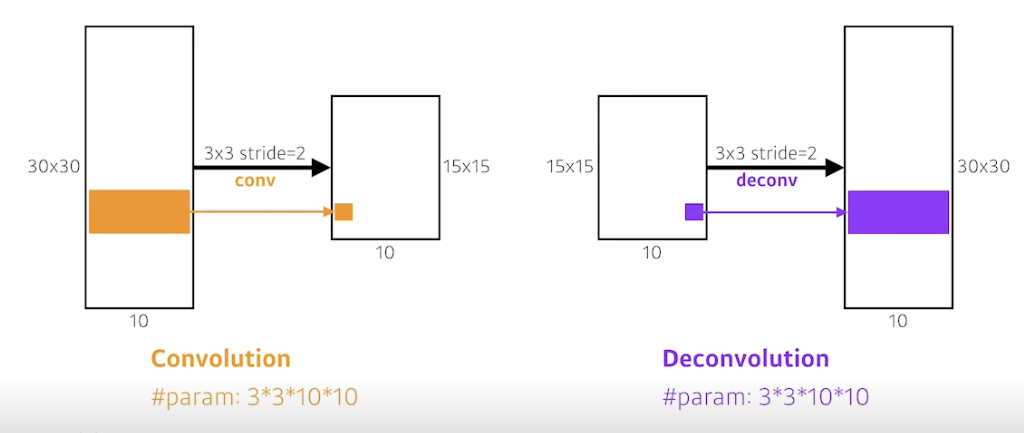
Deconvolution (conv transpose)
- convolution 의 역연산
- 컨벌루션하면 디멘션이 줄어듦 5x5 → 2x2, 디컨벌루션하면 디멘션이 늘어남 2x2 → 5x5
- 엄밀하게는 컨벌루션의 역연산이란 건 없음 (10 이라는 숫자가 원래 뭐로 만들었는지 알 수 없기 때문)
- 나머지 부분을 다 패딩으로 만들어줌
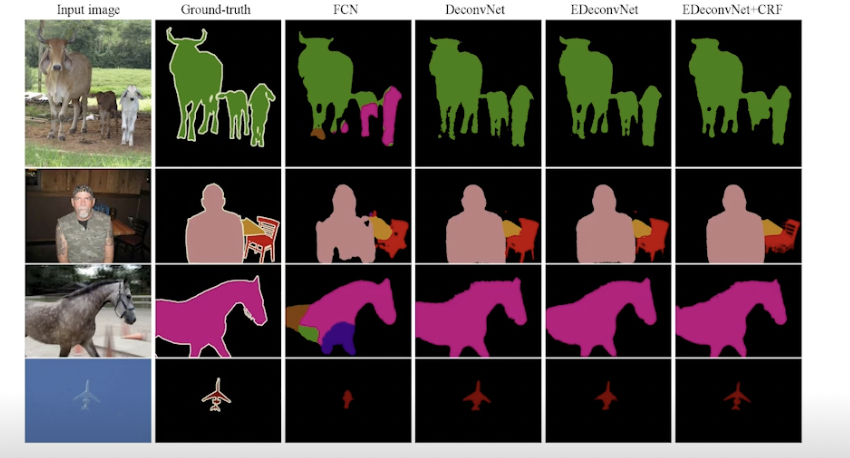
- 결과
Detection
-
이미지 안에서 어느 물체가 어디있는가? per-pixel 말고 바운딩 박스로 찾기
-
이미지 안에서 패치 (지역) 를 엄청 뽑음 (selective search)
-
RCNN
-
이미지 가져옴
-
이미지 안에서 사물인거같은 지역 2,000 개 뽑음
-
알렉스넷으로 각 지역에 대한 피쳐 계산
-
linear SVMs 로 분류
→ bruteforce 같음
-
문제점 : 지역에 대해 모두 CNN 돌리는 것
-
-
SPPNet
- 이미지 안에서 CNN 한 번만 돌리자
- 이미지 안에서 바운딩 박스 뽑고, 이미지 전체에 대해서 convolution 피쳐 맵을 만들어 뽑힌 위치에 해당하는 텐서만 긁어오기
-
Fast RCNN
1) 입력 이미지로 바운딩 박스 뽑음
2) CNN 한 번 돌려서 convolutional feature map 생성 (SPPNet 과 동일)
3) 각 지역에 대해 고정 길이 피쳐를 ROI pooling 으로 부터 얻음
4) 클래스와 바운딩 박스 regressor 두 결과를 얻어냄 -
Faster RCNN
- 이미지를 통해 바운딩 박스를 뽑아내는 Region Proposal 도 학습을 시켜버리자
→ Region Proposal Network (RPN) + Fast R-CNN - RPM
- 어떤 이미지를 주면 어떤 지역 안에 물체가 있을지 판단
- anchor boxes : 어떤 크기들의 물체들이 있을지 미리 아는것 (템플릿)
- 이미지를 통해 바운딩 박스를 뽑아내는 Region Proposal 도 학습을 시켜버리자
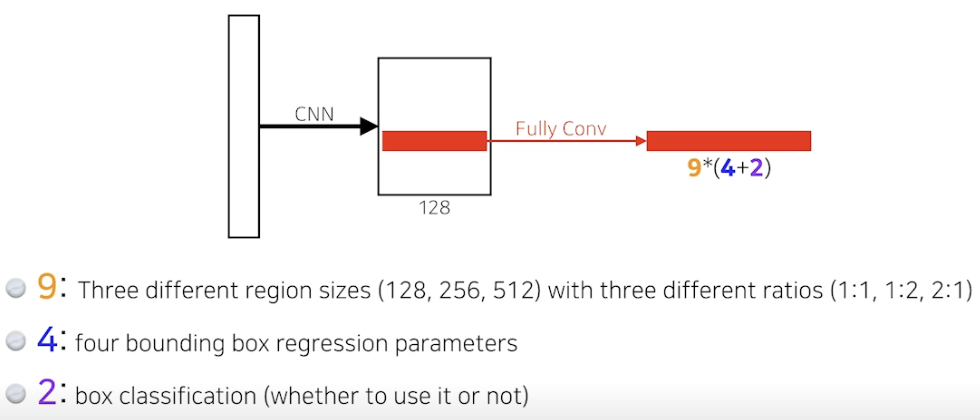
-
YOLO(v1), You Only Look Once
-
아주 빠른 object detection algorithm
- baseline : 45fps / smaller version : 155fps
-
RPN 을 사용하는게 아니라 이미지를 한 번에 바로 체크
- 여러 바운딩 박스와 분류 확률 계산을 동시에 진행하여 예측함
-
과정
-
이미지가 들어오면 SxS 그리드로 나눔
-
물체를 바운딩 박스로 감지 + 분류 확률에 비춰봄 → 바로 결과 나옴
-
각 셀은 B=5 (논문기준) 개의 바운딩 박스를 예측함
- 그 바운딩 박스들이 box probability 를 통해 쓸모 있는지 없는지 확인
- box refinement 와 confidence 체크를 이용
-
각 셀은 C class probabilities 를 예측함
⇒ 두 정보를 취합하여 박스 + 클래스를 알게됨
-
-
-

참조
BoostCamp AI Tech
