MLP Multi-layer perceptron
CNN Convolutional Neural Network
MLP, CNN의 개념 및 학습 성능 비교
실험의 dataset으로 CIFAR 10을 사용했다.
#1 MLP
MLP는 다층신경망 구조로 퍼셉트론 뉴련을 다층으로 쌓을 구조이다.
단일뉴런의 경우 입력층과 출력층으로 구성되는 데,
이 사이에 은닉층(hidden layer)를 추가하여 구성한다.
이 인접한 두 layer는 FC(fully connected) 관계이다.
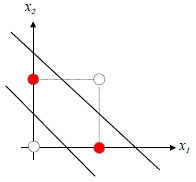
다층 뉴런이 필요한 예시는 아래와 같다.
XOR의 경우 선형 결정선으로 패턴 분류가 불가,
비선형 분리를 통해 데이터의 분류를 할 수 있다.
MLP는 2~3개의 계층으로 구성하는 것이 일반적이다.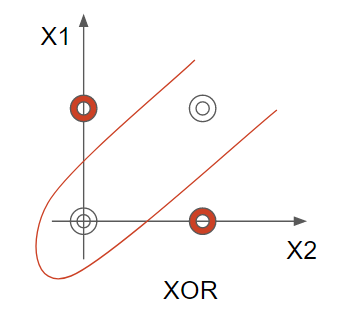
다층 퍼셉트론의 동작 원리에 앞서 필요한 용어와
단층 퍼셉트론의 동작 원리에 대해 설명한다.
1. Activation function(활성화 함수)
활성화 함수는 입력 데이터에 가중치를 곱한 합을 출력 신호로
변환하는 함수이다.
MLP에서 여러 종류의 비선형 함수를 활성화 함수로 사용하는데
대표적으로
1) sigmoid function
2) tanh function
3) relu function
4) leaky relu function
이 있다.
* sigmoid function
Logistic function으로도 불리는 sigmoid function은
0~1이 값을 출력하는 함수로
1 / 1 + exp(-x)의 꼴이다.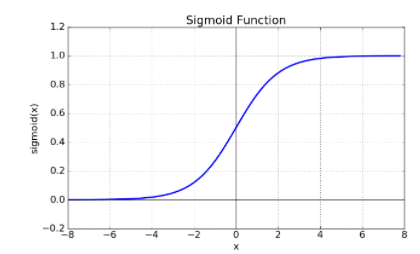
sigmoid function은 Vanishing Gradient Problem이 존재한다.
Vanishing Gradient Problem은 입력 값이 최종 출력 층에
미치는 영향이 부족해지는 문제이다.
이렇게 되면 은닉층의 깊이가 깊어졌을 때 오차율을 계산하기 어렵고
또한 sigmoid는 함수의 중심이 0이 아니기 때문에 학습이 느리다.
* tanh function
Sigmoid function을 보완하기 위해 변형해서얻는 함수이다.
Hyperbolic tangent function의 줄임말이다.
Sigmoid가 중심점을 0으로 갖지 않아 성능이 느렸던 문제를 보완했지만
여전히 Vanishing Gradient Problem이 존재한다.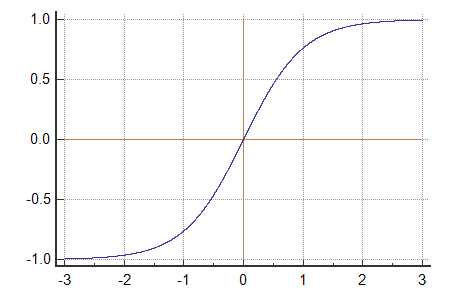
* ReLU function
Rectified Linear Unit function으로 가장 많이 사용된다.
Gradient Vanishing Problem을 해결하기 위해 제시되었다.
Sigmoid, Tanh가 빅했을 때, 학습이 빠르고 비용이 적으며
구현이 간단하다.
하지만 0보다 작은 값에서 함수 값을 0으로 만들기 때문에
0보다 작은 데이터 값을 죽일 수 있다.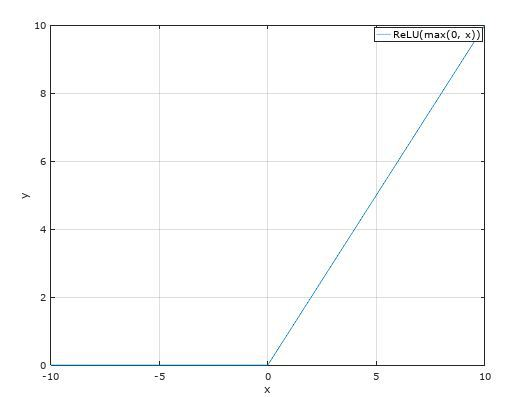
* Leaky Relu
Relu에서 뉴런이 죽는 문제를 해결하기 위해 제시되었다.
0보다 작은 데이터에 대해서도 어느 정도 작은 기울기를 제공하여
데이터를 유지한다.
이외의 부분은 Relu와 동일하게 진행된다.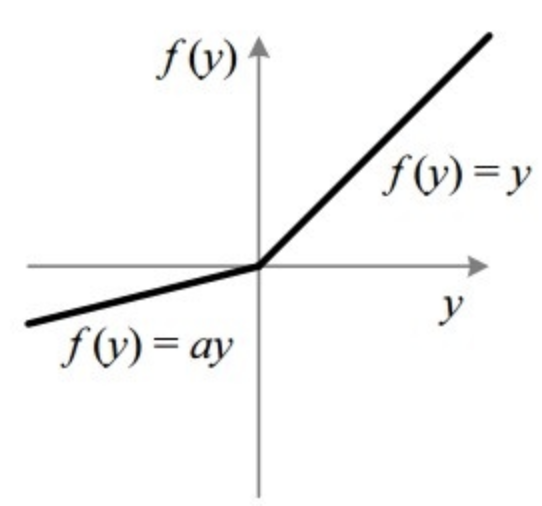
2. 손실함수
손실 함수는 MSE를 사용하는 데, 결국 학습을 통해 얻은 값이
우리가 원하는 값과 얼마나 차이가 존재하는 지를 검증하는 것이다.class MLP(nn.Module):
def __init__(self, input_size, active_func, output_size):
super(MLP,self).__init__()
self.activation_func=active_func
self.linear1 = torch.nn.Linear(input_size, 1024)
self.linear2 = torch.nn.Linear(1024, 512)
self.linear3 = torch.nn.Linear(512, 256)
self.linear4 = torch.nn.Linear(256, 64)
self.linear5 = torch.nn.Linear(64, 32)
self.linear6 = torch.nn.Linear(32, output_size)
self.seq = nn.Sequential(
self.linear1, self.activation_func,
self.linear2, self.activation_func,
self.linear3, self.activation_func,
self.linear4, self.activation_func,
self.linear5, self.actviation_func,
self.linear6
)
def forward(self, x):
x = flatten(x) # feature map을 1차원 vector화 하는 함수
x = self.seq(x)
return x
코드는 현재 선택한 활성화 함수, 입력 크기, 출력 크기를
인자로 받고 입출력 층을 포함하여 총 7개의 층으로 구성된 다층 구조이다.
데이터가 10개의 class로 구성이 되어 있기 때문에
최종적으로 output_size=10으로 데이터를 가공한다.
input->1024->512->256->64->32->output
실험에서 activation function은 relu로 선택했고 이유는
다음에 제시한다.Neural Network with Pytorch #2에서 CNN에 대한 내용으로 이어간다.

Whiplash We Flash