Overview
We will explore the integration of Large Language Models (LLMs) with autonomous driving systems by examining the following two papers:
-
DriveGPT4: Interpretable End-to-End Autonomous Driving via Large Language Model
IEEE RA-L 2024Can we implement an explainable end-to-end autonomous driving system using LLMs?
-
LMDrive: Closed-Loop End-to-End Driving with Large Language Models
CVPR 2024Can we build cognitive autonomous driving systems on top of LLMs that can interact with human passengers or navigation software using natural language?
DriveGPT4
Motivation
🚗 The Challenge of End-to-End Autonomous Driving
- End-to-end learning-based autonomous driving models act as black boxes, making it difficult to interpret their decisions.
- Lack of explainability raises ethical and legal concerns, limiting real-world deployment.
🧠 Why use LLMs?
- LLMs can provide natural language explanations for driving actions, improving interpretability.
- By leveraging multimodal learning, LLMs can process both visual data and textual queries, enabling a more transparent decision-making process.
Model Architecture
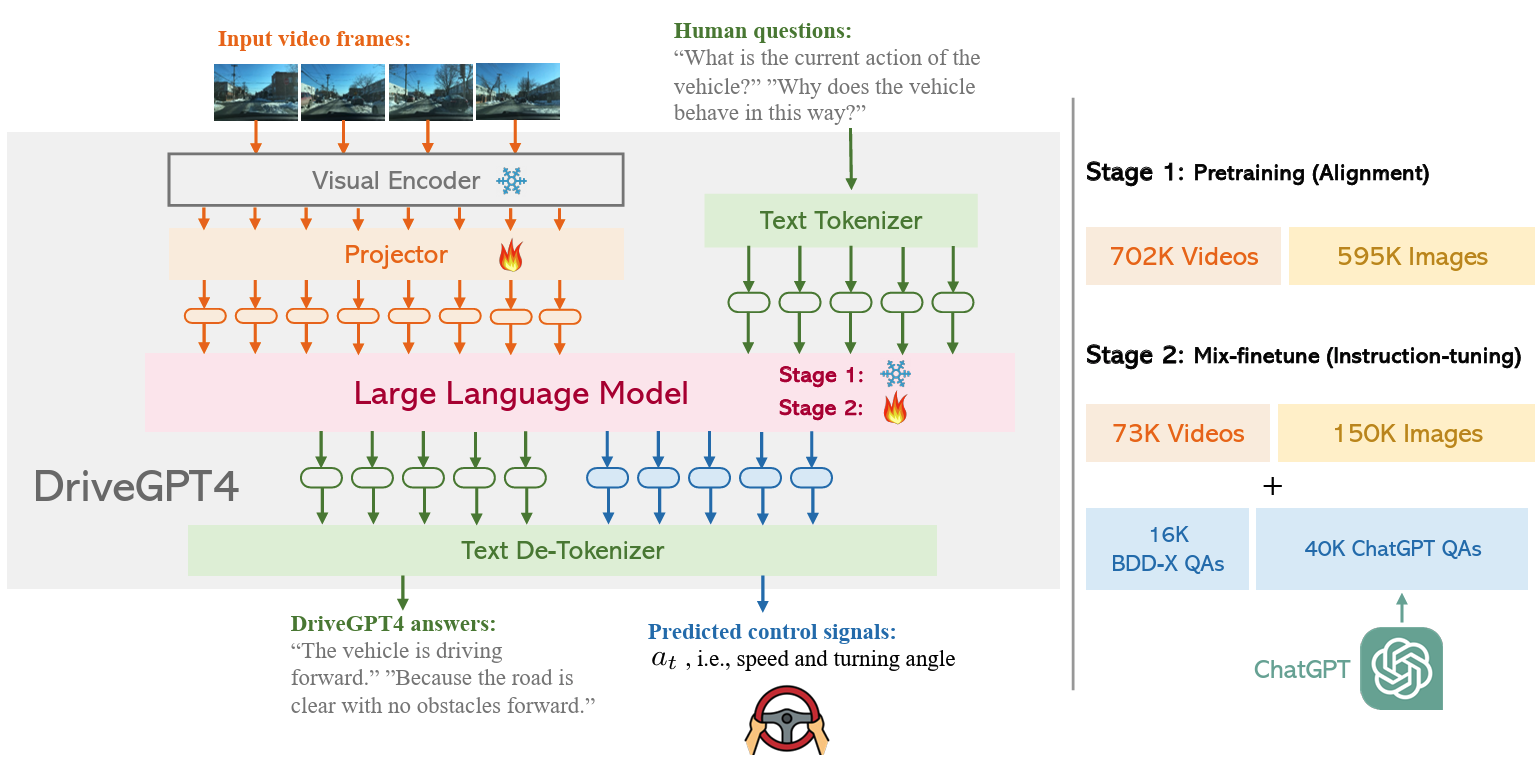
Video Tokenizer
Video frames
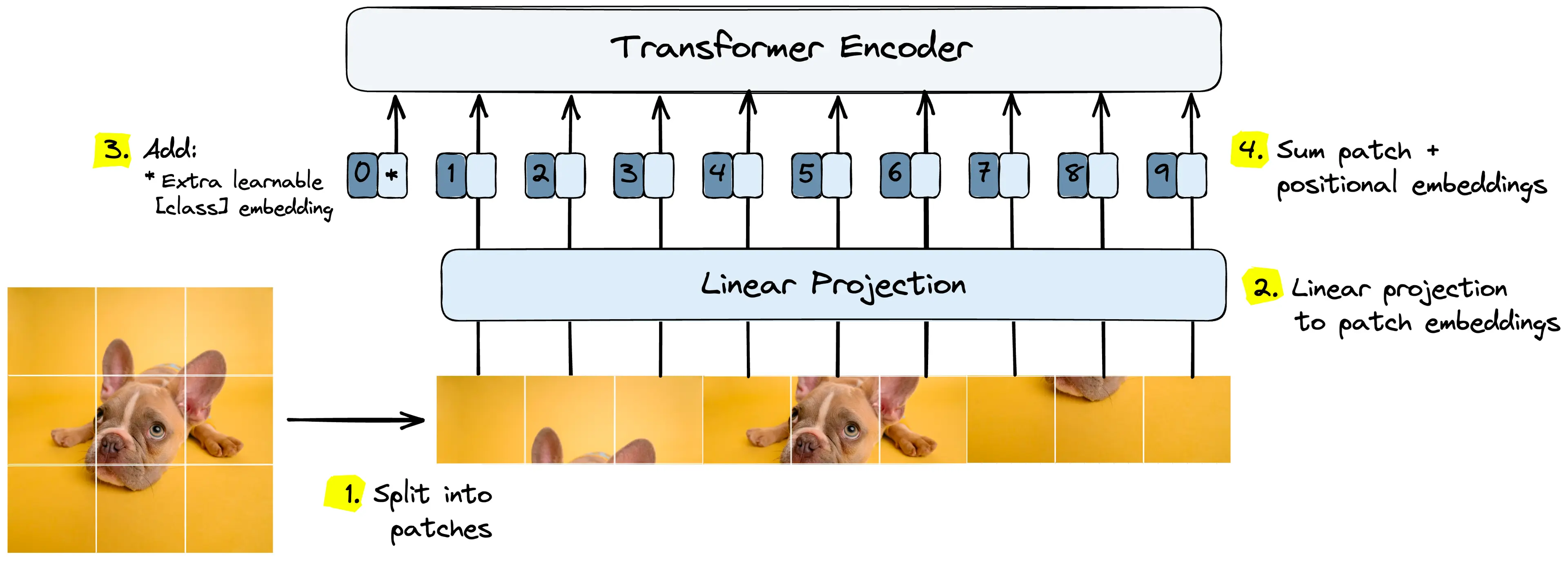
For each , the pretrained CLIP visual encoder is used to extract its feature
- The global feature
- The local patch features
Visual encoder splits the image to patches and extract the local features of each patch. (ViT)
The temporal visual feature of the entire video can then be expressed as:
The spatial visual feature of the whole video is given by:
Ultimately, both the temporal feature and spatial feature are projected into the text domain using a projector.
Text and Control Signals
Inspired by RT-2, control signals are processed similarly to texts.
- The speed of ego vehicle and time length of the video clip are included in the text input.
- The turning angle represents the relative angle between the current and the previous frame.

Training
DriveGPT4’s training consists of two stages:
- the pretraining stage, focusing on video-text alignment
- the mix-finetuning stage, aimed at training the LLM
to answer questions related to interpretable end-to-end
autonomous driving.
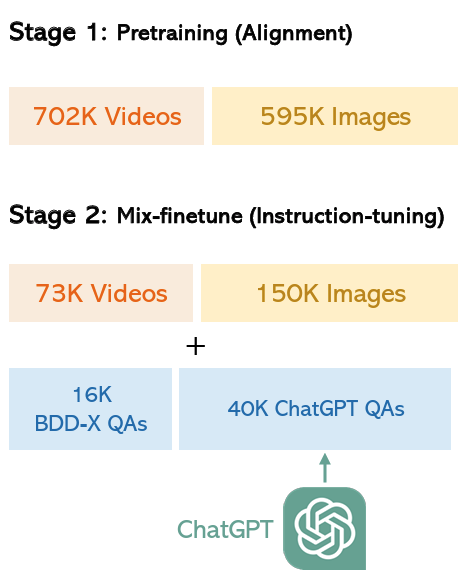
The pretraining stage
- 595K image-text pairs + 702K video-text pairs.
- The pretraining images and videos encompass various
topics and arenot specifically designed for autonomous driving
applications. - During this phase, the CLIP encoder and LLM weights
remain fixed. Only the projector is trained.
The mix-finetuning stage
- To enable DriveGPT4 to understand and process domain
knowledge, it is trained with the 56K video-text
instruction-following data

- 56K is not sufficient for LLM fine-tuning.
- 223K general instruction-following data generated
by LLaVA and Valley.

Experiment
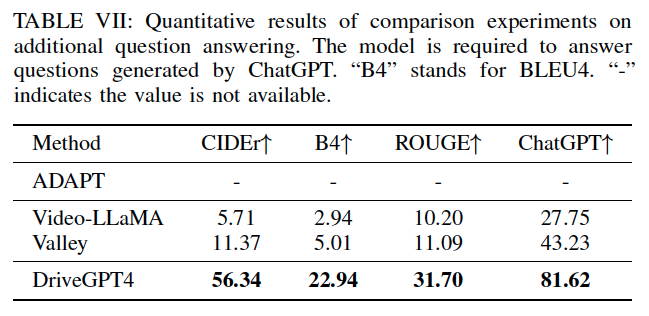
Interpretable Autonomous Driving
- ADAPT serves as the state-of-the-art baseline work.
- Recent multimodal video understanding LLMs are also considered for comparison.
- All methods use 8-frame videos as input.
Testing Set Split
| Split | Scenes | Amount |
|---|---|---|
| Easy | Stopped; Driving forward; Parked; etc. | 1202 |
| Medium | Lane switch; Acceleration; Intersection; etc. | 295 |
| Hard | Vehicle turning; Traffic light change; etc. | 312 |
Evaluation Metrics
CIDEr, BLEU4, and ROUGE-L: metric scores widely used in the NLP community.
- CIDEr: Is the explanation human-readable? (Naturalness)
- BLEU-4: Are the words accurately matched? (Precision)
- ROUGE-L: How smoothly does the sentence flow? (Coherence)
Also, ChatGPT is prompted to assign a numerical score between 0 and 1 for evaluate answers of questions generated by ChatGPT.
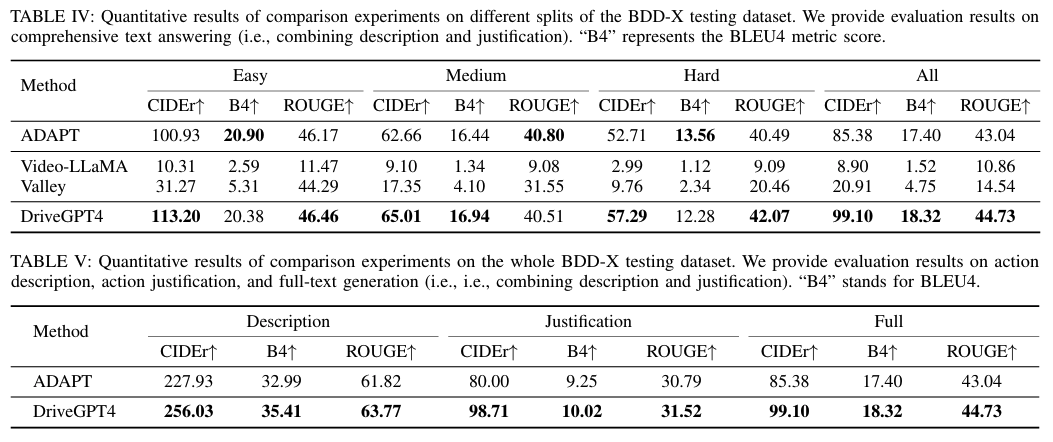
Additional Question Answering
End-to-end Control
- RMSE: root mean squared error
- : threshold accuracies
- the proportion of test samples with prediction errors lower than .

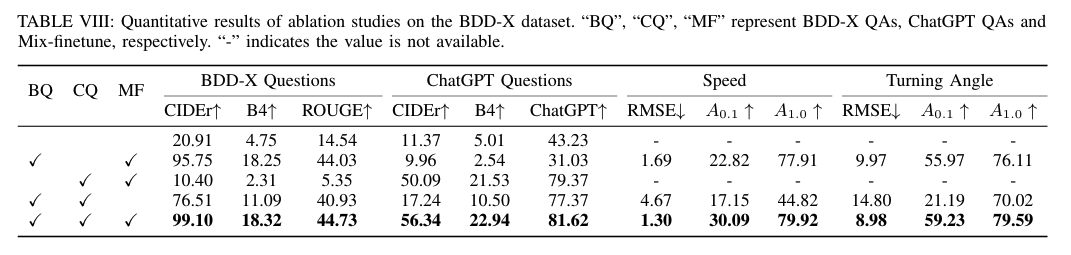
Ablation Studies
LMDrive
Motivation
🚗 Challenges in Autonomous Driving
- Traditional models rely on fixed-format sensor inputs, limiting human interaction.
"Can we build cognitive autonomous driving systems on top of LLMs, that can interact with human passengers or navigation software simply by natural language?”
LMDrive, a language-guided, end-to-end, closed-loop autonomous driving framework
🧠 Why LLM?
- In long-tail unforeseen events and challenging urban situations, the language-aware AVs can easily survive by following instructions from passengers or navigation software.
- AVs can adapt to passengers’ sudden notice simply via natural language, which was previously non-trial and required a large amount of handcrafted rules
🔁 Closed-Loop
The absence of closed-loop evaluation leads to insufficient consideration of critical issues
- cumulative errors, human-robot interaction, and temporal consistency of actions.
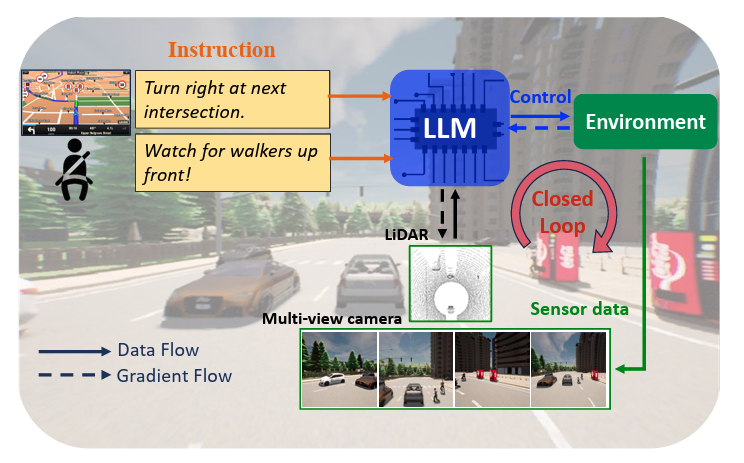
Contributions
- End-to-End Closed-Loop Autonomous Driving
- First language-based framework that integrates multimodal sensor data with real-time control execution.
- Language-Guided Driving Dataset
- Collected 64K data clips in CARLA, containing navigation instructions, notice instructions, sensor data, and control signals.
- LangAuto Benchmark
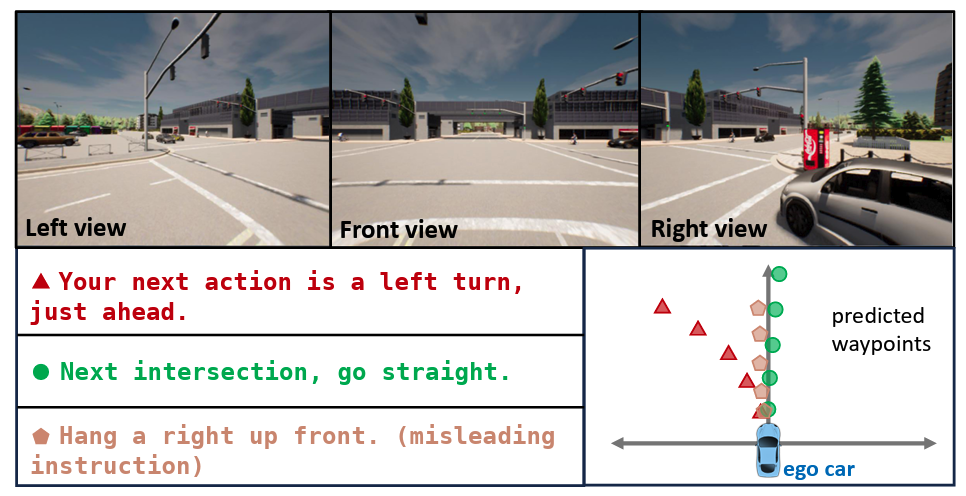
- Designed a new evaluation set including misleading instructions, complex scenarios, and adversarial conditions.
- Extensive Closed-Loop Experiments
- Conducted detailed component analysis to validate LMDrive’s effectiveness.
Dataset generation
Three sources of input
- sensor data (multi-view camera and LiDAR)
- navigation instructions
- human notice instruction
The data collection consists of two stages:
- collecting sensor data and control signals with an expert agent.
- parsing and labeling collected data with instructions.
Dataset generation
Sensor and control data collection
- rule-based expert agent creates a dataset including about 3M driving frames.
- camera data, LiDAR data, and control actions
- the agent runs on 2.5k routes, 8 towns, and 21 kinds of environmental conditions.

- four RGB cameras (left, front, right, rear) and one LiDAR
- center crop the front image as an additional focus-view image to capture the status of the distant traffic light
Parsing and language annotation.
If the agent started to turn left at frame and ended at frame
- label as a new clip with the instruction “Hang a left at the next crossroads”
If an adversarial event occurs at time
- add one notice instruction into this clip.

Instruction design
Consider three types of navigation instructions (follow, turn, and others) + notice instruction. (consists 56 different instructions)

To enable the agent to drive in realistic instructional settings,
-
Diversifying the instructions with ChatGPT API

- Incorporating misleading instructions.
- "Change to left lane" on a single-lane road.
- Connecting multiple instructions.
- "Turn right at this intersection, then go straight to the next intersection and turn right again."
Model Architecture
Sensor Encoding
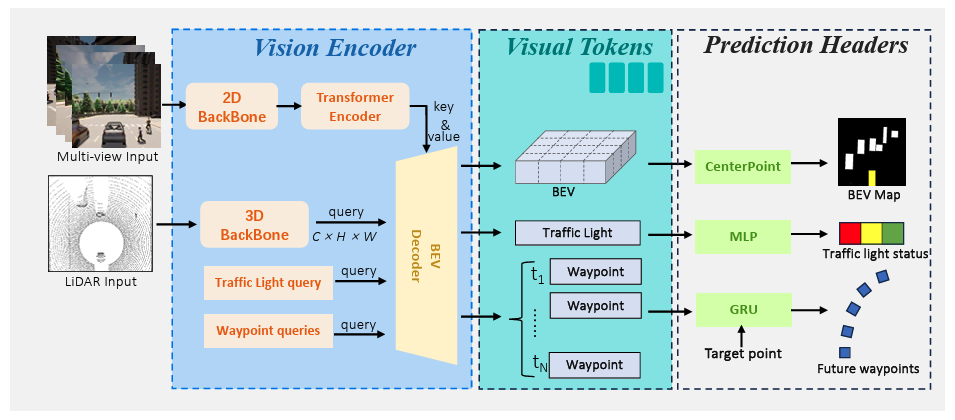
Multi-view camera
- 2D backbone ResNet to extract the image feature map
- each layer containing Multi-Headed Self-Attention, MLP blocks and layer normalization.
LiDAR input
- 3D backbone PointPillars processes the raw point cloud data into ego-centered LiDAR features.
- PointNet aggregates features and downsamples the feature map.
BEV Decoder
- BEV Decoder is designed as a standard transformer with layers.
- Generates three types of visual tokens (BEV, waypoint, and traffic light).
Pre-training with prediction headers
- Object detection, future waypoint prediction, and traffic light status classification.
- Discarded after pre-training.
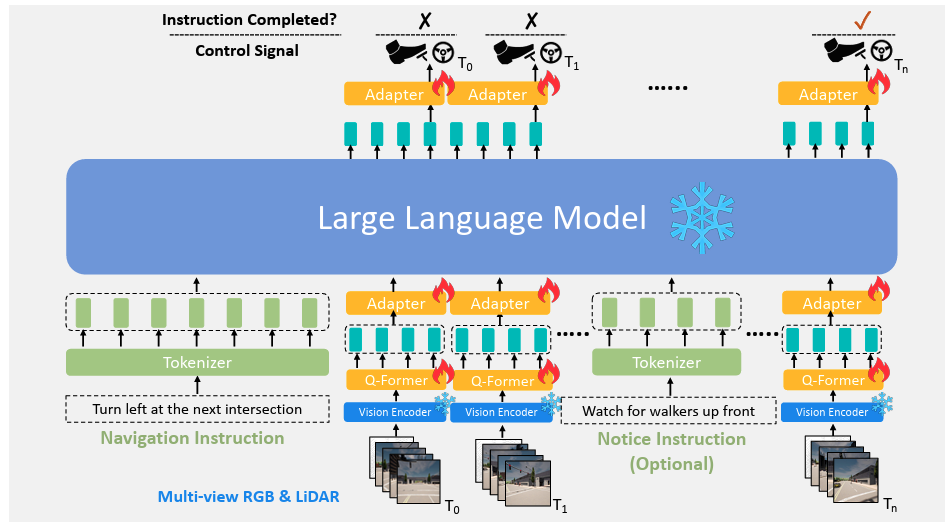
LLM for instruction-following auto driving
Instruction and visual tokenization
- The vision encoder generates visual tokens ( BEV tokens, waypoint tokens, and one traffic light token) for each frame
- It's too large for the LLM because usually hundreds of frames are needed to complete one instruction.
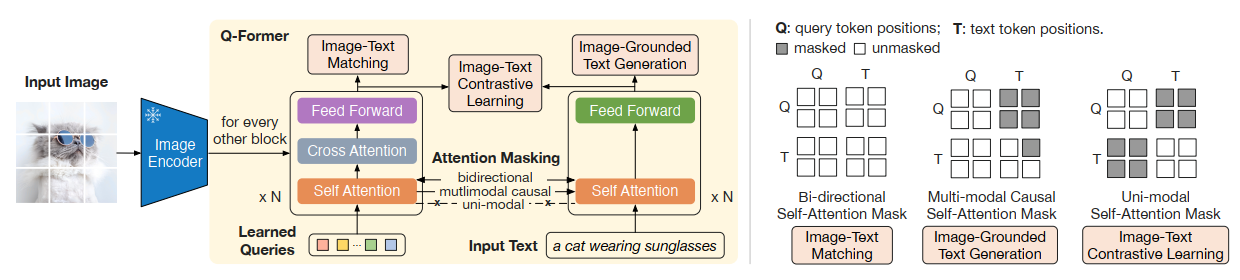
- To overcome this, we follow BLIP-2 to use the Q-Former to reduce the number of visual tokens.
- Subsequently, we use a 2-layer MLP adapter to convert the tokens extracted by the Q-Former to share the same dimension as the language token
Action prediction
After LLM predicts the action tokens, Another 2-layer MLP adapter predicts
- future waypoints
- a flag to indicate whether the given instruction has been completed.
To get the final control signal, which includes braking, throttling, and steering
- use two PID controllers for latitudinal and longitudinal control to track the heading and velocity of predicted waypoints respectively.
Training Objectives
- waypoint loss.
- the classification loss. (instruction completed flag, cross-entropy)
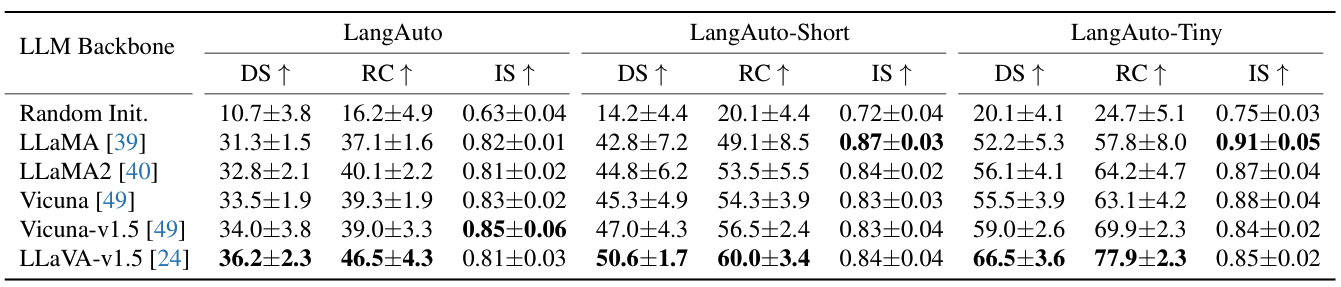
LangAuto Benchmark
Metrics
- Route completion (RC)
- the percentage of the total route length that has been completed
- Infraction score (IS)
- infractions triggered by the agent.
- collisions or traffic rule violations.
- Driving score (DS)
- RC IS
Quantitative Results
LLM Backbone
Module design

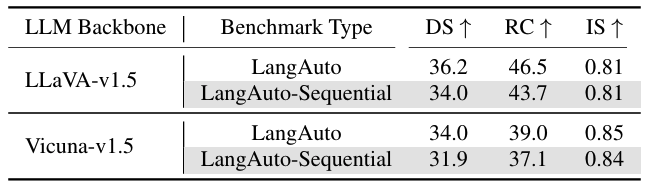
LangAuto-Notice Benchmark

LangAuto-Sequential Benchmark
Prediction Example