
얼핏 듣기에 랜덤(random)으로 무언가를 결정한다는 건, 효율성과 거리가 멀어보인다.
우연에 맡기고 아무거나 고른다고?
그게 전략적으로 무언가를 선택하는 것보다 나을 수가 있을까?
하지만 우연성, '랜덤'은 컴퓨터 공학에서 굉장히 중요한 역할을 한다.
많은 알고리즘에서 더 나은 답을 위해서 '랜덤'을 사용한다.
매번 정확히 똑같은 방식으로 각 단계를 거쳐가는 알고리즘을
결정론적 알고리즘(Deterministic Algorithm)이라고 한다.
반면에 '무작위 알고리즘(Randomized Algorithm)'은
무작위로 생성된 '난수'를 사용해서 문제를 푼다.
이번에 알아볼 '퀵 정렬(Quick Sort)'도, 대표적인 무작위 알고리즘 중 하나다.

파티셔닝 (Partitioning)
앞서 우리는 분할 정복을 사용하는 합병 정렬 (Merge Sort)를 살펴봤다.
퀵 정렬도 마찬가지로 '분할 정복(Divide and Conquer)'을 사용한다.
합병 정렬은 주어진 리스트를 절반으로 나눠 분할하고,
퀵 정렬은 주어진 리스트를 '파티셔닝'으로 분할한다.
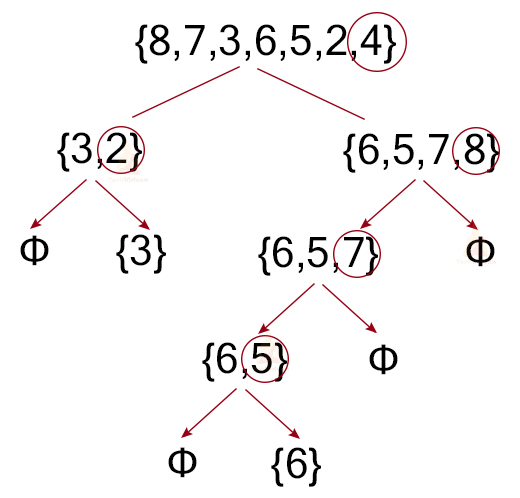
파티셔닝은 단순한 작업이다.
- 정렬을 해야할 리스트에서 임의의 수를 고른다.
- 나머지 수를 고른 수와 하나씩 비교한다.
- 고른 수보다 작은 숫자는 왼쪽으로 옮기고, 고른 수보다 큰 숫자는 오른쪽으로 옮긴다.
예를 들어 주어진 리스트가 다음과 같다고 하자.
[1, 3, 9, 8, 2, 7, 5]
우리는 맨 끝에 있는 '5'를 고르기로 하자.
'5'보다 작은 수는 왼쪽에 두고,
'5'보다 큰 수는 오른쪽에 둔다.
결과적으로 리스트는 이런 순서가 된다.
[1, 3, 2, 5, 9, 8, 7]
이게 파티셔닝이다.
파티셔닝을 해도 여전히 모든 리스트가 정렬된 상태는 아니다.
'5'보다 앞에 있는 수들, '5'보다 뒤에 있는 수들은 여전히 정렬이 되지 않았다.
하지만 파티셔닝의 결과로 '5'만큼은 확실하게 정렬된다.
'5'의 양쪽을 정렬해도 어차피 '5'의 위치는 바뀌지 않기 때문이다.
따라서 우리가 고른 '5'라는 숫자는 정확히 제자리에 와있는 상태다.
우리가 고른 '5'라는 숫자를 '피벗(pivot)'이라고 부른다.
피벗은 '중심축' 혹은 '중심축을 중심으로 회전한다'는 뜻이다.
주어진 배열을 '5'라는 중심축(pivot)을 가지고 나눈다...고 이해하면 쉽다.
파티셔닝으로 분할 정복하는 퀵 정렬
파티셔닝에 대해서 이해했으니, 퀵 정렬을 사용해 정렬 문제를 분할 정복해보자.
분할 (Divide)
- 주어진 배열을 파티셔닝한다.
- 피벗의 왼쪽 리스트와, 오른쪽 리스트에 각각 다시 퀵 정렬을 해준다.
- 더 이상 나누는 게 불가능할 때까지 반복한다.
정복 (베이스 조건)
-
분할한 리스트의 길이가 0이나 1이 되면, 더 이상 파티셔닝을 할 수 없다.
-
퀵 정렬을 한번 호출할 때마다, 최소 하나 이상의 숫자가 정렬된다.
따라서 리스트의 길이는 계속 줄어들고, 언젠가는 베이스 조건에 도달한다. -
길이가 0이나 1일 때는 이미 주어진 리스트가 정렬된 상태라고 할 수 있다.
따라서 그냥 주어진 리스트를 반환해주면 된다. 간단하게 문제가 풀린다.
조합 (Combine)
- 분할한 리스트에 퀵 정렬을 실행하면 정렬된 배열이 나온다.
- 피벗의 왼쪽, 오른쪽에 합치면 전체 리스트의 정렬된 결과로 만들수 있다.
(파티셔닝을 하는 방법도 구체적으로 들어가면 여러가지가 있는데, 자세한 구현 코드는 여기를 참고하자.)
퀵 정렬의 시간복잡도
퀵 정렬은 문제를 더 작게 쪼갤 때마다 '파티셔닝'을 해야한다.
피벗을 기준으로 숫자를 왼쪽으로 옮겨 모으고,
오른쪽으로 옮겨 모으려면 최대 n-1번의 비교를 해야한다.
파티셔닝의 시간 복잡도는 O(n)이다.
퀵 정렬은 호출하는 재귀가 한단계 깊어질 때마다 O(n) 작업을 하게 된다.
재귀 호출은 리스트의 길이가 0이나 1이 되면 끝난다.
여기서 이 글을 읽는 여러분이 생각해봐야할 게 있다.
길이가 n인 리스트에 파티셔닝을 몇 번 해야,
쪼개진 리스트의 길이가 0 혹은 1이 될까?
여기가 퀵 정렬이 까다로워지는 부분이다.
재귀 호출 횟수: 최선, 최악, 평균
잠시 합병 정렬에서 어떻게 분할을 했는지 생각해보자.
중간 위치를 구한 다음 그냥 절반으로 뚝 잘랐다.
쪼개진 배열의 길이는 무조건 2분의 1이 된다.
하지만 퀵 정렬에서는 우리가 피벗을 뭘로 고르냐에 따라서
쪼개진 배열의 길이가 완전히 달라진다.
최선의 경우
[1, 3, 9, 8, 2, 7, 5]
우리가 이 배열에서 피벗을 5로 골랐다면,
왼쪽: [1,3,2]
오른쪽: [9,8,7]
이렇게 3개씩 같은 길이로 쪼개진다.
우리가 계속해서 피벗을 중위값으로만 고른다면,
배열은 계속 절반으로 쪼개진다.
배열의 길이가 1이 되려면 총 log n번 분할하게 된다.
물론 우리는 무엇이 중위값인지 모르기 때문에
log n번을 모두 중위값을 고른다는 건 로또 당첨에 가까운 운이 될 것이다.
최악의 경우
만약 이 배열에서 피벗을 1로 골랐다면?
왼쪽: [ ] // 없음
오른쪽: [3,9,8,2,7]
오른쪽만 5개가 된다. 배열의 길이가 1밖에 줄지 않았다.
아니 왜 1을 골라? 당연히 중위값에 가까운 걸 골라야지...
라고 생각할 수 있다.
하지만 말했듯이 우리는 무엇이 중위값인지 모른다.
정렬되지 않은 배열이니까 쉽게 중위값을 찾을 수가 없다.
우리가 계속해서 최대값이나 최소값을 고른다는 최악의 경우를 가정하면,
배열의 길이가 1이 될때까지 총 n-1번을 쪼개야 한다.
그러면 전체 시간복잡도는 O(n^2)이 된다. 매우 느리다.
평균적인 경우
하지만 우리가 n-1번을 쪼개는 동안
모두 최소값이나 최대값을 고를 확률은 아주아주 작다.
- n개의 배열에서 1번 최대값이나 최소값을 고를 확률은 2/n이다.
- 모든 파티셔닝에서 최소/최대값을 고를 확률은, (2/n)^n 이다.
n이 무한히 커질 때 이 확률은 0에 수렴한다.
대부분의 경우에는 최소/최대값이 아닌 중간의 값을 고르게 된다.
결과적으로 재귀 호출은 대부분 log n에 가까운 횟수로 수렴하게 된다.
'평균적인 경우'를 가정한다면,
퀵 소트는 O(n log n)으로 매우 빠른 알고리즘이다.
최악의 경우 (우리가 고르는 족족 최소/최대값을 고를 경우)엔,
O(n^2)의 성능으로 떨어져버릴 수가 있다.
퀵 정렬의 장점
1. 추가적인 공간이 필요하지 않다.
합병 정렬은 조합 단계에서 새로운 배열을 만들어야 했다.
O(n)의 공간이 추가적으로 필요하다.
반면 퀵 정렬은 새로운 배열을 만들지 않고 합칠 수 있다.
그래서 추가적인 공간이 들지 않다는 게 장점이다.
2. 평균적인 경우 다른 O(n log n) 정렬보다 빠르다.
Big O 표기법으로 봤을 때, 퀵 정렬은 O(n log n) 알고리즘이다.
합병 정렬이나 힙 정렬과 똑같다.
하지만 Big O 표기법은 아주 정확하게 실제 작업 속도를 측정하는 것이 아니다.
실제 프로그램의 실행에서는 하드웨어 등 여러가지 변수들이 개입한다.
퀵 소트는 추가적인 공간을 할당하는 시간이 없고,
한번 결정한 피벗이 연산에서 제외되고,
계속 같은 주소를 참조해서 '캐시' 활용을 잘하기 때문에,
실제로 돌려보면 합병 정렬이나 힙 정렬보다 약간 더 빠르다.
그래서 퀵 정렬이라는 이름이 붙었다고 한다.
왜 빠른지는 알고리즘의 범위를 벗어나니까 깊이 들어가진 말자.
퀵 정렬의 단점
1. 가끔 헛발질을 한다.
이렇게 빠르신 퀵 정렬의 문제는,
결정적인 순간에 헛발질을 할 수가 있다는 거다.

우리가 파티셔닝을 할 때 피벗을 i번째에서 고른다고 하자.
그런데 우리가 정렬해야할 리스트가,
하필 i번째 위치에 있는 숫자가 모두 최대/최소값인 경우도 있을 수 있다.
더 쉬운 예를 들어보자.
맨 앞에 있는 숫자를 피벗으로 고르도록 파티셔닝을 짰다.
근데 [1,2,3,4,5,6,7]을 정렬하게 된다면?
우리의 퀵 정렬은 장렬한 헛발질을 날리면서,
피할 수 없는 O(n^2) 연산의 늪에 빠지게 된다.

좋은 피벗을 어떻게 고를 것인가?
이렇듯 헛발질할 가능성이 있다보니,
보통의 퀵 정렬은 '불안정한(instable)' 알고리즘이다.
평균적인 경우에는 헛발질 확률이 0에 가깝지만,
혹시라도 정렬이 이미 되어있는 인풋이 들어오게 되면,
100%의 확률로 O(n^2) 연산을 하게 된다.
이러면... 아무리 빨라도 믿고 쓰기가 힘들잖아?

그렇다면 좋은 피벗을 고를 수 있는 다른 방법은 없을까?
퀵 정렬을 안정적으로 만들 수는 없을까?
중위값을 고르면 가장 좋겠지만...
우리는 어디가 중위값인지 모른다.
만약 맨 마지막이나 맨 처음을 피벗으로 고르면
정렬된 알고리즘이 들어왔을 때 문제가 발생한다.
그러면 다른 위치를 피벗으로 고르면?
그래봤자 마찬가지다.
퀵 정렬이 i번째 요소를 피벗으로 계속 고른다면,
i번째 요소에 계속 최대값/최소값이 있는 순서의 배열이 들어올 수 있다.
이 경우 퀵 정렬은 100% 확률로 무조건 O(n^2) 연산을 하게 된다.
하지만.. 피벗을 '랜덤'으로 고른다면 어떻게 될까?
피벗을 매번 무작위로 고른다
매번 퀵 정렬이 호출될 때마다 고르는 피벗의 위치가 달라진다면?
원래 알고리즘에서는
1번째 호출에서 i번째를 피벗으로 고르고,
2번째 호출에서 i번째를 피벗으로 고르고,
3번째 호출에서도 i번째를 피벗으로 고른다.
하지만 만약 '난수'를 생성해 피벗을 고른다면
1번째 호출에서는 i번째를 피벗으로 고르고,
2번째 호출에서는 j번째를 피벗으로 고르고,
3번째 호출에서는 k번째를 피벗으로 고르게 된다!
만약 최악의 순서인 배열이 들어온다고 가정해보자.
그래도 난수를 사용하면 피벗을 고르는 위치가 계속 바뀐다.
피벗으로 고른 모든 숫자가 최대/최소값일 확률은 0에 수렴하게 된다.
최악의 인풋이 들어와도
우리는 평균적인 경우의 성능을 얻을 수 있다.
n개의 범위에서 난수를 생성할 때는 O(n)의 연산이 더 들어간다.
하지만 파티셔닝도 O(n)이기 때문에 전체 복잡도는 바뀌지 않는다.
난수를 생성해서 피벗을 고른다 해도 여전히 최악의 경우가 없어진 것은 아니다.
하지만 어떤 인풋이 들어와도 O(n^2) 연산을 하게 될 가능성은 0에 수렴한다.
마음놓고 퀵 정렬의 성능을 즐길 수 있게 된 것이다!
랜덤으로 알고리즘을 더 좋게 개선한 우아한 사례다.

랜덤을 활용하는 알고리즘의 2가지 종류
우연성, 랜덤은 생각보다 많은 알고리즘에 쓰이고 있다.
컴퓨터 알고리즘에서 랜덤을 쓰는 경우는 크게 2가지로 나눌 수 있다.
1. 라스베가스 알고리즘 (Las Vegas)

랜덤을 활용하지만 항상 정확한 답을 구할 수 있는 알고리즘이다.
답이 랜덤인 것은 아니고 '답을 구하는 과정'에서 난수를 사용한다.
위에서 본 '무작위 퀵 정렬'이 바로 라스베가스 알고리즘에 속한다.
또 다른 유명한 알고리즘으로는 '무작위 해싱(Randomized hashing)'이 있다.
해싱(Hashing)을 사용하면, 키(key)를 사용해 O(1) 연산으로 값에 접근할 수 있다.
굉장히 유용하게 쓰이는 자료구조다.
하지만 같은 해시 함수를 똑같이 사용한다면,
최악의 경우 똑같은 해시가 2번 생성되는 '해시 충돌'이 일어날 수 있다.
이 때 여러가지 해시 함수를 후보로 두고, 이 중에서 랜덤으로 하나를 골라 해싱한다.
이걸 '무작위 해싱'이라고 한다.
무작위 퀵 정렬과 마찬가지로 최악의 경우에도 성능을 보장한다.
2. 몬테카를로 알고리즘
실행할 때마다 값이 달라지지만,
아주 많이 반복해서 근사치를 추정할 수 있는 알고리즘이다.
몬테카를로 알고리즘은 직접 풀어내려면 매우 어렵고 시간이 많이 드는 알고리즘에 적용한다.
랜덤한 입력값을 엄청 많이 반복해서 나온 결과를 가지고 값을 추정한다.
반드시 정확한 답을 보장하지는 않는다. 좋은 가성비로 적당히 좋은 결과를 낸다.
대표적인 게 '무작위 샘플링(Randomized Sampling)'이다.
우리가 10만 개의 값 중에서 중위값을 찾고 싶다고 하자.
근데 하나하나 비교해서 찾으면 O(n^2) 연산이다.
너무 많은 시간이 걸린다.
그러면 무작위로 전체 숫자 중에서 20개만 뽑아본 다음 그중에서 중위값을 찾는다.
그리고 또 다시 20개를 뽑은 다음 중위값을 찾는다.
그렇게 매우 많이 반복하다보면,
샘플 중위값을 가지고 전체 중위값을 추정할 수 있다.
물론 약간 오차가 있겠지만 말이다.
소수의 인원으로 전체 여론을 파악하는 여론 조사와 똑같은 원리다.
알고리즘 분야에서 굉장히 유명한 '영지식 증명(Zero-knowlege Proof)'라는 것도 있다.
내가 비밀번호를 입력하지 않아도 비밀번호를 알고 있다는 것을 증명할 수 있는 매우 신박한 알고리즘이다.
ZKP도 무작위성을 사용해서 믿을 수 있는 확률을 도출해내는 아이디어를 사용한다.
머신 러닝에서도 몬테카를로 알고리즘이 많이 활용된다.
요약 정리
- 퀵 정렬은 파티셔닝을 사용해 주어진 배열을 분할한다.
- 파티셔닝으로 나눈 양쪽 배열에 퀵 정렬을 한 후 합치면, 정렬된 전체 배열을 만들 수 있다.
- 퀵 정렬의 시간복잡도는 '평균적으로' O(n log n)이다.
- 퀵 정렬은 추가적인 공간이 필요하지 않고, 다른 O(n log n) 정렬보다 좀 더 빠르다.
- 대신 최악의 인풋이 들어오는 경우, O(n^2) 연산을 하게 된다.
- 피벗을 랜덤하게 고르면 어떤 입력이 들어와도 안정적으로 O(n log n) 연산을 할 수 있다.
- 알고리즘에서는 랜덤을 활용해서 최악의 경우를 방어하거나, 아니면 가성비 좋게 추정치를 얻는 방법을 많이 사용한다.
관련 글

30개의 댓글


Download the latest GB WhatsApp APK v18.30 to access advanced messaging features, enhanced privacy options, and customizable themes. form https://gbwhata.net


The Latest version of GB WhatsApp was introduced. It kept all the beloved features but free the ads, making it the go-to choice for users who wanted an ad-free experience with full customization and privacy control.
https://gbplusz.net.pk/

great post i liked more. if you want to Use Premium features of Chat app like GB WhatsApp then visit our official website https://gbwaplus.net/

GB WhatsApp Update introduces advanced privacy settings which allow users to hide their online status, add blue ticks, and customize who can view their profile picture. Hence providing users with more control over their privacy.

great artical thanks for sharing, if you want to download Gb whatsapp please click here-
https://gbwhetsapp.com/
GBWhatsApp is a social media platform similar to WhatsApp. It lets users send messages, make calls, share photos, videos, and documents with friends and family. What sets GBWhatsApp apart are its enhanced features like auto-replying to messages,
read more-
https://gbwhitsapp.com/

Do you want to earn real money just by playing online games? Then join Ok Win! visit - https://okwinz.com/
Enhance your Bus Simulator Indonesia adventure with a wide range of free vehicle mods. From buses and trucks to cars and motorbikes, Mod Bussid offers it all. Easy to download and install, these mods bring fresh excitement to the game. Perfect for players who love customizing their driving experience!
https://modbussid.io/
Six Game is made for users in Pakistan who want fun and quick games with a chance to win real cash. It gives you many options for games.
https://six-game.pk/

YouTube automation https://www.nexlev.io/ways-to-make-money-with-youtube-automation involves using tools or outsourcing to streamline tasks like video creation, uploading, SEO, and audience engagement. It helps creators scale their channels without handling every detail manually. Common methods include AI tools, content repurposing, and virtual assistants.

Descargar Whatsapp Plus Última Versión y disfruta de características avanzadas. Mejora tu privacidad con las opciones exclusivas de Descargar Whatsapp Plus Última Versión!
https://whatsappplus.com.pk/es/

Moto X3M is my favorite bike racing game! I love the crazy stunts and smooth controls. It keeps me coming back every day for more fun and challenges.

The first method to download GB WhatsApp latest version is to use the official site and download the APK from there. This is the easiest method to perform a GB Whatsapp 2025 as it's coming directly from the official creator of the app.
https://gbroid.net.pk/

Stability Created by Chance" in Quick Sort highlights the fascinating randomness that sometimes leads to efficient outcomes in algorithms. It’s a reminder that even unpredictable elements can produce great results.
Similarly, gb whatapp apk
offers flexible and powerful features not found in the standard app—giving users more control and better performance, even beyond the expected
if you want to see more related to this you can visit this site : https://gbwadown.com/
퀵 정렬은 우연적인 피벗 선택이 오히려 정렬의 안정성과 효율성을 높여주는 흥미로운 알고리즘이네요. 🔄 마찬가지로, 많은 사람들이 GBWhatsApp을 선택하는 이유도 다양한 추가 기능과 맞춤형 옵션이 의사소통을 더 유연하고 안정적으로 만들어주기 때문입니다." for more you can visit this site : https://whatsmody.net/gb-whatsapp/

Instagram Pro makes sharing and exploring content smoother and more enjoyable!
https://instaproin.com
“Snap Tube APK Download makes video downloading fast, simple, and reliable!”
https://snaptube.ro/
“Download VidMate Latest Version for a smooth, fast, and reliable video experience.”
https://vidmate.ro/
“Spotify APK makes music streaming simple, smooth, and enjoyable.”
https://spotifyapp.su/
Cinema HD v3 Official delivers smooth streaming with great quality and an easy to use interface.
https://cinemahd3.com/
GB WhatsApp allows you to edit and enhance images and videos. There is no need to include another editor to colour the media. You can add amazing effects and filter images to share. You can easily use the effects after selecting images.
https://gbappsdl.com.pk/

Just like algorithms improve by adding randomness for better results, apps also evolve with new features. That’s why many people choose GB WhatsApp APK download, as it offers more options and flexibility than the standard version.
Vist now: https://gbwhatpure.com/

Thanksgiving brings us closer, and in 2025, it’s a moment to pause and recognize the kindness, support, and blessings that fill our lives. https://thanksgivingday2025.com/

Randomness plays an interesting role in computer science, as algorithms like Quick Sort often become more efficient when it’s applied. It’s similar to creativity, where experimenting can lead to the best outcomes. For video editing, I like using since it makes exploring different effects easy and enjoyable.
https://www.thecutpro.com/
좋은 글 잘봤습니다!