TransICD : Transformer Based Code-wise Attention Model for Explainable ICD Coding
medical NLP paper review
목록 보기
6/8

Abstract and Introduction
- 현재 문제점
a. ICD codes를 clinical note에 수동적으로 부여하는 것은 아주 비효율적이며 많은 에러를 야기시킬 확률이 큼.
b. 게다가 Training skilled coders작업은 많은 시간과 노력을 필요로 함.
c. 위 두가지 이유로, automating ICD code determination은 중요한 작업임. 인공지능이 발전하면서 이 작업의 훌륭한 대안들이 생겨나고 있음. - 대안
a. documents의 토큰들 사이의 상호관계를 포착하기 위해서 transformer-based architecture를 적용함.
b. 전체 document를 code-specific 표현으로 나타내기 위한 학습을 시키기 위하여 code-wise attention mechanism을 사용함.
c. 이 외에도 code간의 imbalance한 frequency를 해결하기 위해서 label distribution aware margin loss function을 사용함.(LDAM) - Challenges
a. ICD-9에는 15000개 이상의 코드들이 존재하기에 이들을 분류하는 것은 높은 차원의 라벨 공간으로 multi-label classification하는 problem이라는 점.
b. 코드 대부분이 희귀하고 드문 질병들과 관련되어 있는 것이므로 빈번하지않게 사용됨. 이는 데이터셋의 불균형성을 야기시킴.
c. clinical records : noisy, lengthy and contain a large amount of medical vocabulary. - Previous models
a. CNNs, LSTMs가 previous well-known models -> 긴 퇴원요약 기록을 인코딩하는데 뛰어나지 않음.
b. self-attention based Transformer는 LSTM의 long term dependency문제를 해결해냄. 그러나 기존 대부분의 pre-trained transformer models은 smaller sequence length와 OOV(out of vocabulary) 의 한계가 있음.
c. 위에서 제기 했던 트랜스포머 모델의 한계를 의료 도메인에서 pre-trained CBOW embedding을 시키면 해결할 수 있음. - Contributions
a. transformer encoder를 이용해서 clinical note 속 토큰들의 contextual representation을 얻어내고 이 표현들을 집계하기 위해 structured self-attention mechanism을 추가하여 entire note의 label-specific hidden representations을 추출하는 구조의 ICD coding model을 제시함.
b. LDAM(label distribution aware margin loss function)을 적용하여 long-tailed distribution of ICD codes을 해결. 이를 평가하기 위해 MIMIC-3 datasets의 well-known models과 비교 분석을 보임.
Dataset
- MIMIC-3
a. benchmark datasets that provides ICU medical records
b. widely used in ICD coding prediction
c. discharge summary describing diagnoses and procedures that took place during a patient's stay, ICD-9 codes 사용.
d. LAAT논문에서 처럼, MIMIC-3-full, MIMIC-3-50이렇게 두가지 setting으로 사용. - Preprocessing
a. lowercase and tokenize the text
b. remove punctuations, numbers, English stop-words, and any token with less than 3 characters
c. replacing remaining digits with 'n' => as a result, 98% of the discharge summaries are bound within 2500 d. tokens. => maximum length of token sequence = 2500
e. 128차원으로 word2vec CBOW method으로 임베딩 진행.
f. 총 123916 Token from training set, 'PAD' : padding token, 'UNK' : out of vocabulary token.
Method
- Problem
a. discharge summary sample : 여러개의 ICD code와 관련 => multi-label classification problem.
b. W = (w1, w2 ,..., wn) => yl ( 0 or 1 ) - Transformer based Label Attention Model
a. transformer의 multi-headed self-attention 구조 확장. ( to encode the tokens of the clinical notes )
b. Embedding Layer : clinical note : W => embedding vec E
c. TransformerEncoder : employs multi-headed self attention mechanism to the sequence as a whole and provides us with contextual word representations.(H = TransformerEncoder(E))
d. Code-specific Attention Model : 멀티라벨 분류 테스크이므로, encoding된 H를 code-wise한 representation으로 바꿀 필요가 있음.
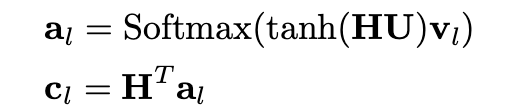
e. Multi-label classification : y(hat) = sigmoid(Zcl + b)
loss function = binary cross-entropy
f. loss function = binary cross-entropy - LDAM(label-distribution-aware margin)
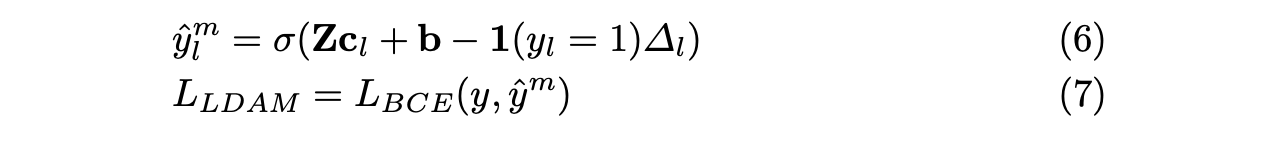
a. yl = 1) is 1 if yl = 1.
b. delta(l) = C / nl 0.25 ( C is a constant, nl is the total count of training notes having l as true label. ) - Training Details
a. Encoder layer = 2, attention head = 8, epochs = 30, lr = 0.001, dropout rate = 0.1
b. da = 2 * de , C=3
Result
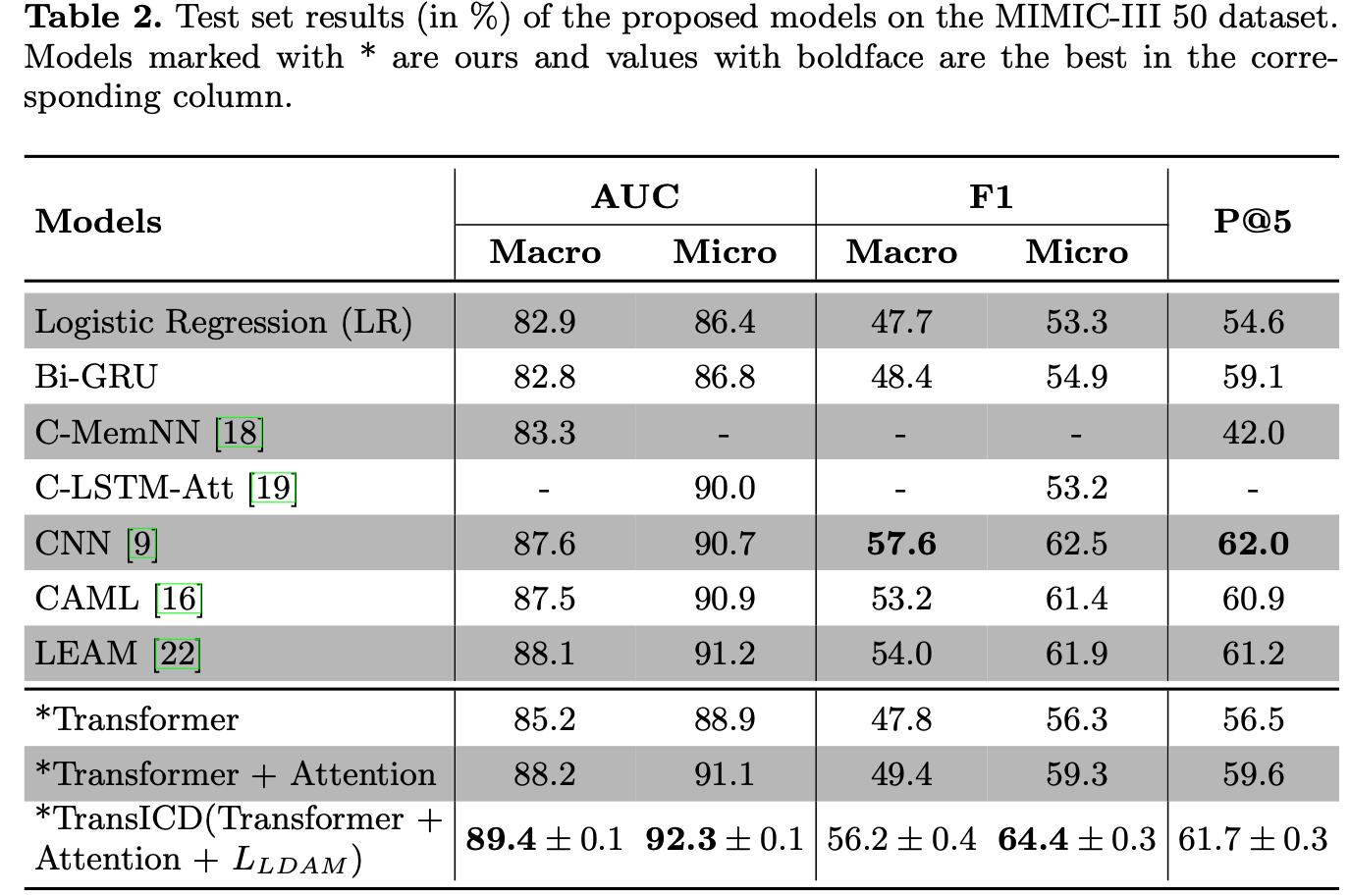
1. 5번 다 다른 랜덤 시드로 model parameters를 initialize해서 돌린 결과 낮은 standard deviation을 보였기에 이 모델은 stable함을 알 수 있음.
2. 기존의 recurrent model, convolutional 기반 모델보다 우수한 성능을 보임.(than BI-GRU, C-LSTM-Att, CNN, CAML)
3. attention없이 단순하게 encoded token vectors를 mean pooling 하여 상요한 basic transformer model 또한 LR모델보다 우수한 성능을 보임. 이는 tranformer encoder의 long-term dependency of. he tokens을 잘 포착하는 능력에 기반한 것으로 판단.
4. Code-wise attention과 LDAM Loss 를 이용한 TransICD는 대부분 baseline모델들 보다 우수한 성능을 보였지만, F1 Macro에서는 CNN 다음의 위치를 차지함.
5. 이전모델들과 비교를 해보면 LR이 가장 성능이 안좋고 다른 것들도 고려해보았을 때, attention-based model이 다른 것들에 비하여 우수한 성능을 보임.
6. LDAM loss를 사용하지 않으면 상당한 성능 저하를 볼 수 있는데, 이는 LDAM loss가 imbalanced frequency of the labels을 만났을 때 강력한 역할을 함을 암시함.
Visualization
- 특정 질병에 대해 주어진 텍스트의 각 토큰들이 얼마나 그 질병에 관련되어 있는지를 visualization 해 본 결과, 같은 text에 대해서 다른 질병을 주니, 확연한 attention의 차이가 있었고, 실제로 관련된 토큰들을 잘 추출해냄.
- 결론적으로 이 모델이 더 높은 신뢰성과 투명성으로 ICD 코딩 프로세스에서 임상의에게 도움이 될 것이라 판단됨.


타인에게 영감을 주는 것을 애정합니다. 그래서 책을 내고 싶습니다. 이 꿈을 위한 조각들을 아카이빙합니다.