Introduction
- ICD coding : clinical notes들과 같은 patient's visit data를 ICD code로 classification하는 과정.
- 수동 ICD coding은 사람에 따라 다른 판단을 할 수 있기에 prone to human errors하고, 많은 노동력과 시간이 필요하다. ML을 이용하여 이를 utilize할 것.
- 기존의 최상의 모델은 CNN을 이용한 모델인데, 고정된 window sizes를 이용하기에 한계가 있었음. 이 논문에서는, 여러 길이와 ICD코드와 Text fragments간의 상호의존성을 다룰 수 있도록 새로운 모델을 제시함. : Label attention model
- SOTA가 이전의 가장 좋은 성능을 보인 모델
CNNs with single or several fixed window sizes - densely connected CNN, multi-filter based CNN이 나오면서 여러가지 사이즈의 single text fragment를 다룰 수는 있었지만, 최적은 window size를 정하는것은 여전히 문제점.
Methods
- Label Attention Model
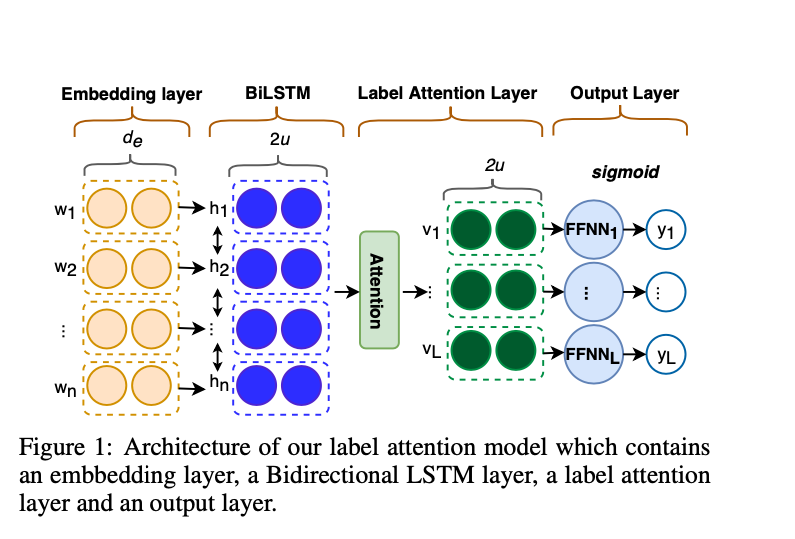
a. Embedding layer : n word token → embedding vector e1, e2, ..., en
b. Bidirectional LSTM layer

c. Attention Layer
- transform H into label-specific vectors.
- Z = tanh(WH), A = softmax(UZ)
- V = HA^T (Each ith column of V is a representation of D regarding the ith label in L)
d. Output Layer - each label-specific representation v -> (FFNN) -> sigmoid : output (probability)
- Hierarchical Joint Learning Mechanism
a. 대부분의 ICD codes는 빈번하게 나타나지 않기에 데이터셋이 아주 불균형적이라 할 수 있음.
b. ICD 코드들 사이에는 계층적 관계가 있는데, 예를 들어 같은 앞 세글자를 가지면 같은 상위 카테고리에 속하듯, 이 구조를 이용하여 모델이 빈번하지 않게 등장하는 ICD 코드들에 대해서 더 좋은 성능을 낼 수 있도록 하는 구조.
c. JointLAAT
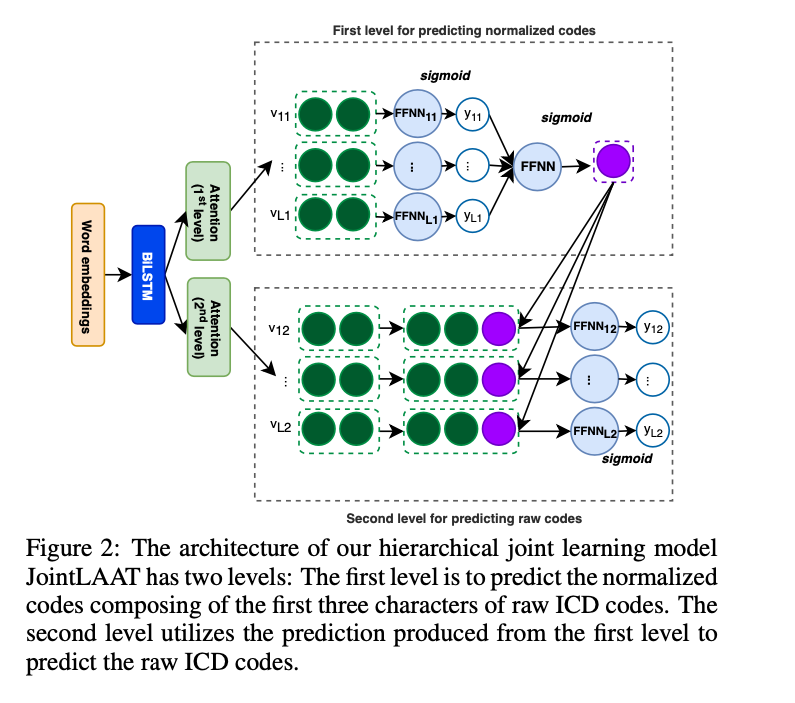
- first level : predict the normalized codes composing of the first three characters of raw ICD codes.
- second level : utilize the prediction produced from the first level to predict the raw ICD codes.
Dataset
- MIMIC-3 : 52722개의 퇴원 요약 기록과 8929개의 특별한 코드들이 있음. 환자 아이디를 기준으로 training, validation, test sets으로 나누었음.
a. MIMIC3-full, MIMIC-3-50
b. 첫번째 실험에서는 모든 코드셋을 사용하였고, 두번째 실험에서는 50개의 가장 빈도 높은 코드들을 사용하고 11317개의 퇴원요약기록을 train, validation, test데이터로 나누어 사용. (각각을 MIMIC3-full, MIMIC3-50 이라고 denote) - MIMIC-2도 사용하였음.
a. MIMIC-2-full - Preprocessing : tokenize the text and lowercase all the tokens and remove non-alphabetic characters.
a. MIMIC3-full에 대해서는 100차원으로 CBOW Word2Vec을 이용하여 word embedding pre-train.
b. text length 최대치가 2500~6500일때 큰 성능 차이가 없으므로 maximum length 를 4000으로 텍스트를 자름. (for the fairness and reducing the computational cost)
Implementation ( SOTA base )
- train models with AdamW (lr=0.001, batch size = 8, epochs = 50)
- lr scheduler, early stopping, dropout( p = 0.3 ), shuffling train data.
- same hyperparameters를 가지고 10번 다른 랜덤 시드로 반복적으로 시행. 그리고 이들의 평균으로 score를 매김.
- Recent SOTA Baselines
a. LR : train 데이터에 나와있는 모든 레이블에 대해 이진 분류기(1대 나머지)를 구축해 mimic dataset를 이용한 ICD coding에 적용.
b. SVM : MIMIC-2-full dataset에 SVM을 이용하여 hierarchical classifiers를 구축. 이때 hierarchical SVM이 flat SVM보다 우수한 성능.
c. CNN, BiGRU
d. C-MemNN : memory network + iterative condensed memory representations.
e. C-LSTM-att : Character-aware LSTM-based Attention model
f. HA-GRU : Hierarchical Attention Gated Recurrent Unit
g. LEAM : Label Embedding Attentive Model, labels and words가 같은 latent space로 임베딩. text-label compatibility로 text representation 구축.
h. CAML : convolutional attention network for multi-label cls.(high performances on the MIMIC datasets), a single layer CNN + attention layer to generate label-dependent representation for each label.
i. DR-CAML : CAML + incorporating the text description of each code.
j. MSATT-KG : Multi-scale feature attention and structured knowledge graph, densely CNN ( produce variable n-gram features and a multi-scale feature attention to adaptively select mult-scale features ), graph CNN ( capture the hierarchical relationships among medical codes.)
k. MultiResCNN : Multi-Filter Residual CNN, multi filter convolutional layer(capture various text patterns with different length and residual convolutional layer )
Result
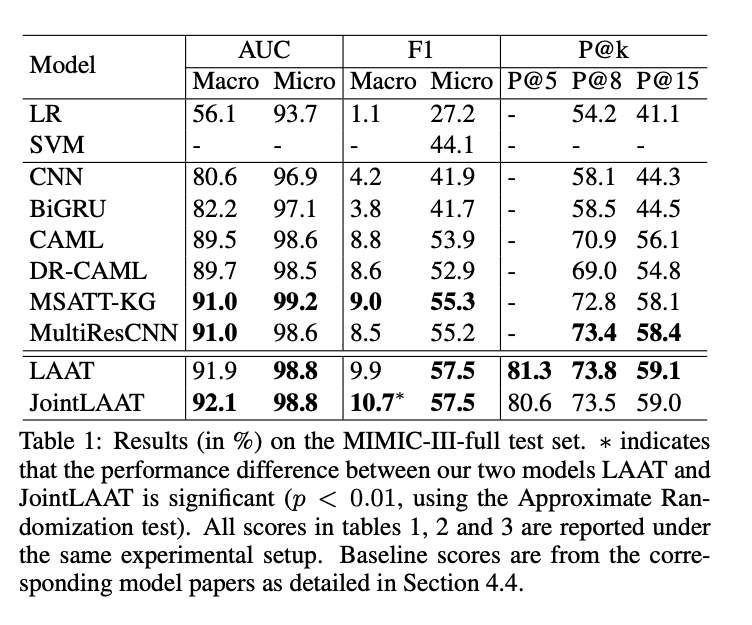
- MIMIC-3-full
a. LR,SVM,CNN,BIGRU ->(attention mechanism) CAML -> (not fixed window size) MASATT-KG,MultiResCNN -> LAAT 순으로 우수한 성능을 보임.
b. JointLAAT가 macro-AUC, macro-F1에서 LAAT보다 우수한 성능을 보임 => JointLAAT는 LAAT보다 infrequent codes에서 우수한 성능을 가짐을 보여줌. - MIMIC-3-50
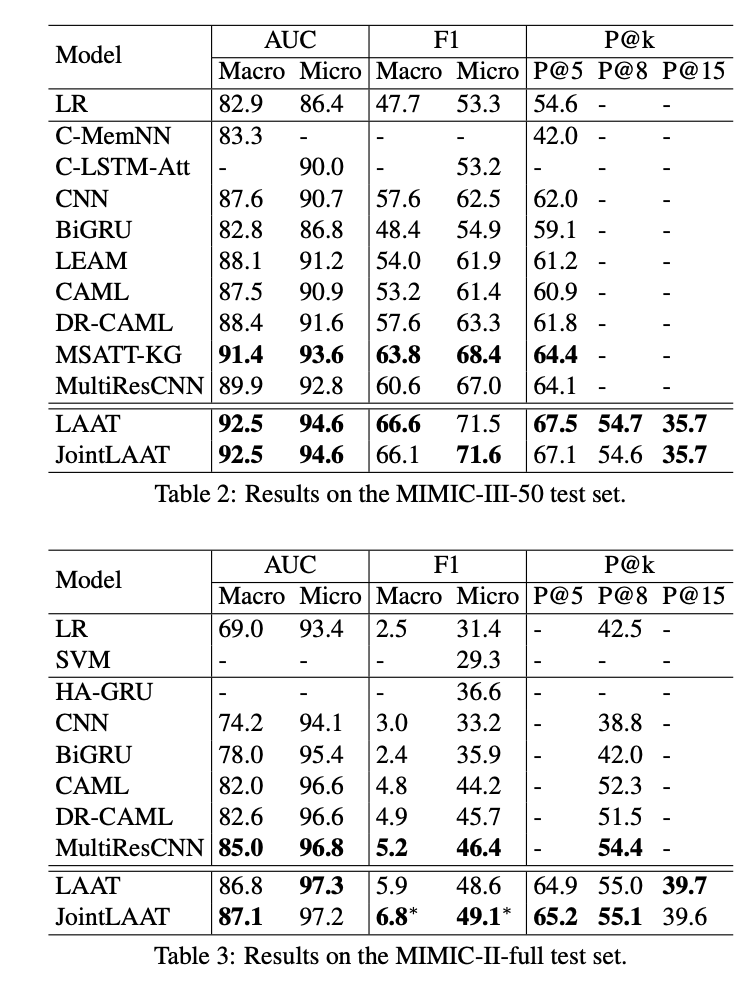
a. LAAT가 전반적인 Baseline모델들보다 뛰어난 성능을 보임.
b. 그러나 JointLAAT가 LAAT에 비해 크게 향상된 성능을 보이지 않는데, 이 이유는 이 데이터셋에는 infrequent codes가 거의 없기 때문일 것이라 예상. - MIMIC-2-full
a. LAAT가 상당히 다른 베이스라인 모델들보다 뛰어난 성능을 보임.
b. MIMIC-3-full dataset과 유사하게 JointLAAT가 LAAT 보다 macro-F1에서 우수한 성능을 보여줌. 이 또한 infrequent codes에서 성능을 향상시킨 것으로 보임.
Contributions
- (LAAT) 이 논문에서는 label attention model을 제시하여 ICD coding에서의 various lengths 문제를 해결하고, ICD codes와 관련된 text fragments들 사이의 상호의존성을 다룸.
a. 이 모델에서 BiLSTM 인코더가 input data간의 contextual info를 포착함.
b. Label specific vector : 특정 라벨과 관련된 중요한 clinical text fragments를 나타냄. 이 모델에서 label attention mechanism은 self attention mechanism을 이용하여 이 label specific vector를 학습함. - (JointLAAT) hierarchical joint learning mechanism을 제시해서 imbalanced data problem을 해결했음.
a. infrequent codes에 대한 성능을 향상시킴.

타인에게 영감을 주는 것을 애정합니다. 그래서 책을 내고 싶습니다. 이 꿈을 위한 조각들을 아카이빙합니다.