[Compression] WeConvene: Learned Image Compression with Wavelet-Domain Convolution and Entropy Model (ECCV 2024) 리뷰
Image Compression
논문 제목
WeConvene: Learned Image Compression with Wavelet-Domain Convolution and Entropy Model (ECCV 2024)
URL: https://arxiv.org/abs/2407.09983
인용수 : 0회 (24.11.12 기준)
Code : https://github.com/fengyurenpingsheng
Wavelet Transform 관련 논문을 찾아보던 중 ECCV 2024에서 발표된 paper를 보게되었다. 이 논문의 경우 Lifting Scheme같은 2세대 웨이블릿을 사용하지 않고, pywt 파이썬 라이브러리를 활용한 순수 웨이블릿 변환을 모델에 적용한 케이스였다.
딥러닝 이전의 전통적인 압축 방법인 JPEG, JPEG-2000 모두 DCT, DWT를 기반으로 압축을 해왔기 때문에 딥러닝에서도 유효하게 적용되었을 것 같습니다.
Abstract
- 최근의 학습 기반 이미지 압축(LIC) 연구는 DCT나 DWT를 사용하는 전통적인 접근 방식보다 뛰어난 퍼포먼스를 보여줌.
- LIC는 주로 오토인코더와 엔트로피 코딩에서 spatial redundancy를 줄이며, DCT나 DWT처럼 주파수 도메인의 correlation을 제거하진 않는다.
- 공간 & 주파수 도메인의 장점을 모두 이용하기 위해 DWT를 CNN과 엔트로피 코딩에 도입. (WeConv, WeChARM)
- 두 모듈을 결합한 WeConvene 프레임워크를 통해 비교 모델 대비 성능 향상.
- WeConv 레이어는 이미지/비디오 압축 이외의 다양한 컴퓨터 비전 태스크에서도 사용가능함.
Introduction
본 논문에서 학습 기반 이미지 압축(LIC) 프레임워크의 오토인코더와 엔트로피 코딩 부분에서 DWT를 효율적이면서 간단하게 사용하는 방법을 제안했다.
이는 전통적인 접근 방식에서 기대할 수 있는 성능 향상을 LIC에서도 얻을 수 있음을 입증했다.
본 논문의 주요 contribution은 아래와 같다.
-
DWT와 IDWT 사이에 컨볼루션을 포함하는 effective, low-cost, modular한 plug-and-play 방식의 WeConv를 제안. 이는 CNN의 장점을 그대로 유지하면서도 DWT 도메인에서의 sparsity를 향상시킨다. 모델 크기와 실행 시간의 변화는 미미했음.
-
WeConv 모듈을 통해 개선된 sparsity를 활용할 수 있는 wavelet domain quantization 및 엔트로피 코딩인 WeChARM을 제안. 이를 적용할 경우 모델 크기와 실행시간이 다소 증가.
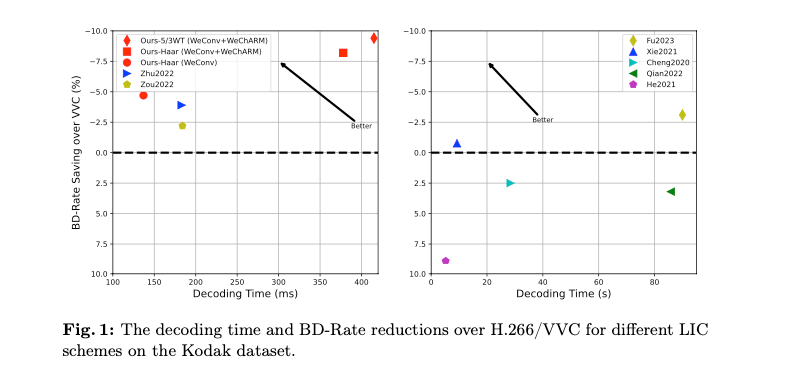
-
제안된 방법은 CNN 기반이므로 학습이 더 쉽고, 트랜스포머 기반 방법보다 GPU 요구 사항이 낮다.
또한 non-local module과 같은 높은 복잡도의 연산을 사용하지 않는다. 따라서 복잡성과 성능 간의 trade-off를 이뤘다. -
전통적인 웨이블릿 변환을 적절히 사용하면 LIC에서도 좋은 성능을 보여줄 수 있음을 시사함. 제안된 WeConv 모듈은 이미지 압축 이외의 다른 컴퓨터 비전 분야에서도 사용될 수 있다.
Background and Related Work
생략
WeConvene: LIC with Wavelet-Domain Convolution and Entropy Model
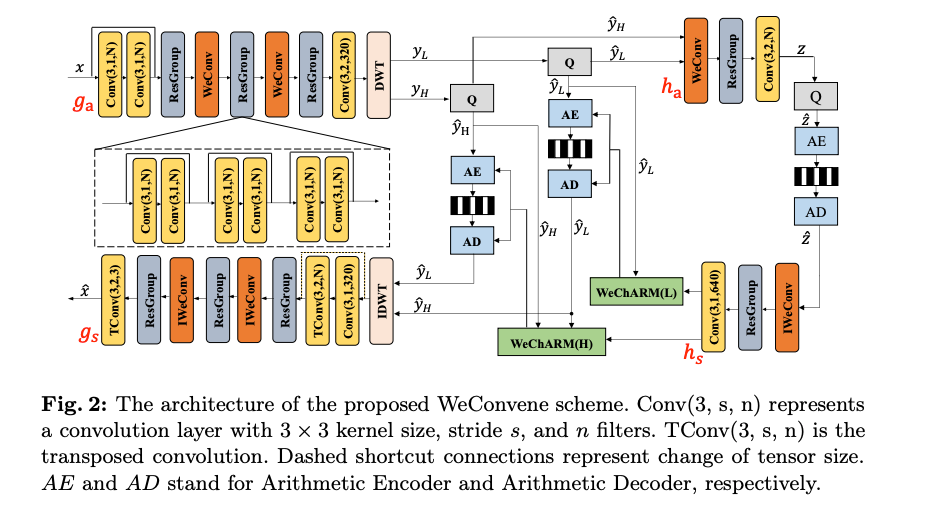
제안된 WeConvene의 전체 프레임워크는 Fig 2와 같다.
기존 LIC 방법과 마찬가지로, 입력 이미지의 잠재 표현을 추출하는 , 이미지를 복원하는 , 잠재 표현의 엔트로피 코딩을 돕기 위한 부가 정보를 인코딩 & 디코딩하는 하이퍼프라이어 가 포함된다.
입력 컬러 이미지의 크기는 이며, 픽셀 값은 [-1, 1]로 정규화했다고 한다.
에는 다수의 컨볼루션 레이어와 leaky ReLU가 포함되며, 3개의 Residual Block이 포함된 ResGroup이 3개 존재한다.
이 프레임워크의 핵심적인 특징은 인코더 네트워크 끝에 DWT를 적용하여 잠재표현을 웨이블릿 도메인으로 변환하는 것이다.
웨이블릿 계수를 더 sparse하게 만들어서 이후의 양자화 및 엔트로피 코딩을 개선한다고 한다.
웨이블릿 도메인 계수는 양자화 후, bit-rate를 줄이기 위해 엔트로피 코딩이 두 단계로 나뉜다.
먼저 저주파 서브밴드 이 인코딩되고, 이를 통해 세 개의 고주파 서브밴드 가 인코딩/디코딩 된다.
하이퍼프라이어에서도 WeConv모듈이 사용되고, 디코더에서는 IWeConv 모듈과 TConv(transposed convolution)을 같이 사용한다.
Wavelet-domain Convolution (WeConv) Module
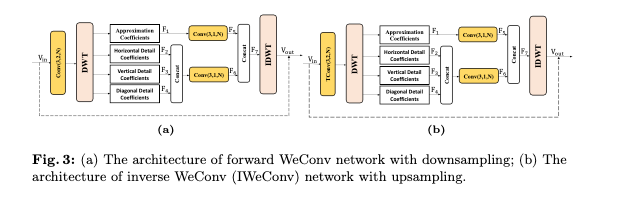
Fig 3은 제안된 WeConv 및 IWeConv 모듈의 디테일을 보여준다.
본 논문에서는 다운샘플링이 될 때 WeConv을 업샘플링이 될 때 IWeConv를 사용하였다.
논문에서 DWT는 JPEG 2000에서 사용되는 2x2 Haar 변환, 5/3 및 9/7 웨이블릿을 사용했다.
플로우를 살펴보면 DWT 후 저주파와 고주파 밴드를 분리 후 고주파 서브밴드는 Concat하여 Convolution을 진행한다.
Figure에서는 고주파 밴드의 컨볼루션 output 채널이 N으로 나와있지만 오피셜 코드를 살펴보면 3*N으로 되어있다.
컨볼루션으로 얻어진 저주파, 고주파 성분은 채널로 Concat 후 IDWT를 통해 최종 output이 만들어진다.
IWeConv는 Conv 대신 업샘플링을 위해 TConv를 사용하였다.
WeConv와 IWeConv 모듈에된 활성화 함수를 GDN을 사용했고, Leaky ReLU보다 좋은 성능을 냈다고한다.
Wavelet-domain Channel-Wise Auto-Regressive Entropy Model(WeChARM)
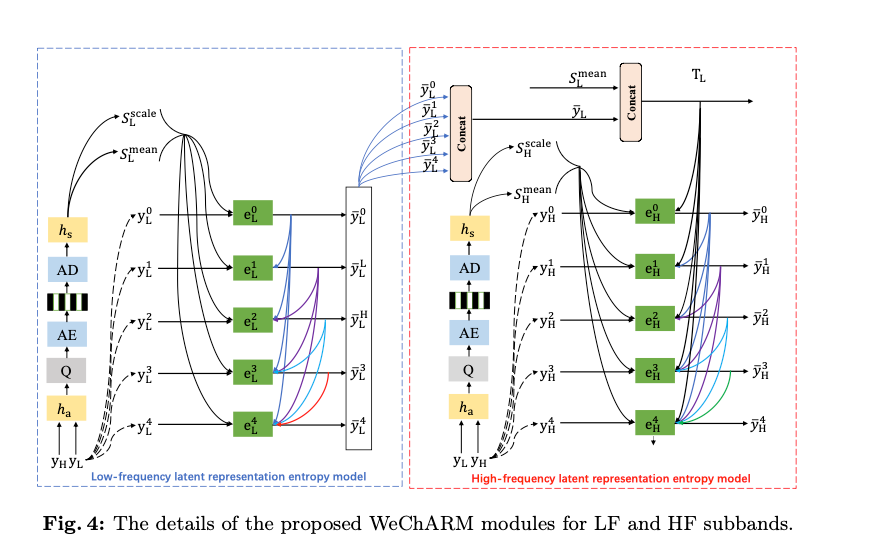
WeChARM은 웨이블릿 도메인에서 저주파 및 고주파 요소인 과 를 인코딩한다.
본 논문에서는 Context Model은 Channel-wise AutoRegressive Model을 사용했으며, Slice는 5개로 설정했다
다섯개의 LF 슬라이스는 하이퍼프라이어의 scale 및 mean과 이전 슬라이스로부터의 출력을 사용하여, 각각 다섯개의 슬라이스 코딩 네트워크인 (i=0,...4)를 통해 순차적으로 인코딩된다. 여기서 은 가우시안 분포를 따른다고 가정한다.
LF 컴포넌트가 코딩된 이후, 다섯 개의 HF 슬라이스 는 를 통해 코딩된다.
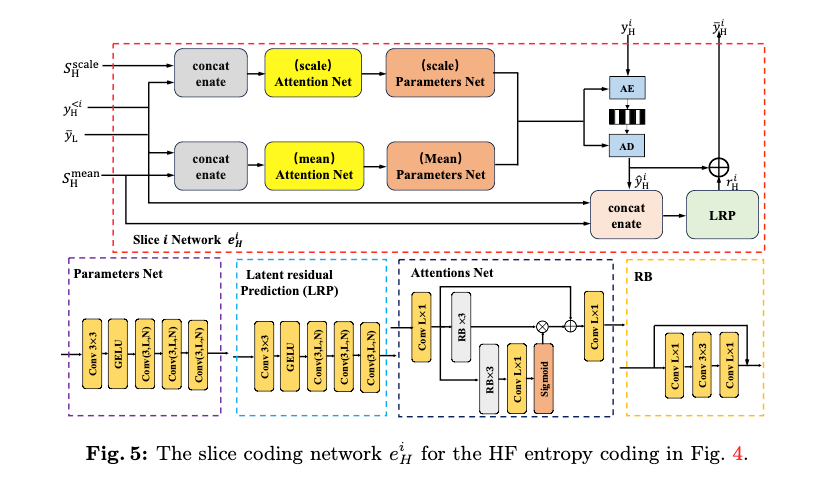
Fig 5는 의 디테일을 나타나낸 그림이다.
은 의 구조는 유사하나, 로부터의 prior 정보만 빼면 된다고 한다.
Loss Function
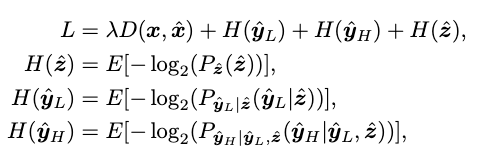
기존 논문들과 다르게 저주파, 고주파 성분을 나누어 비트스트림으로 만들기 때문에, 각각의 엔트로피를 구하여 rate loss를 계산한다.
Experimental Results
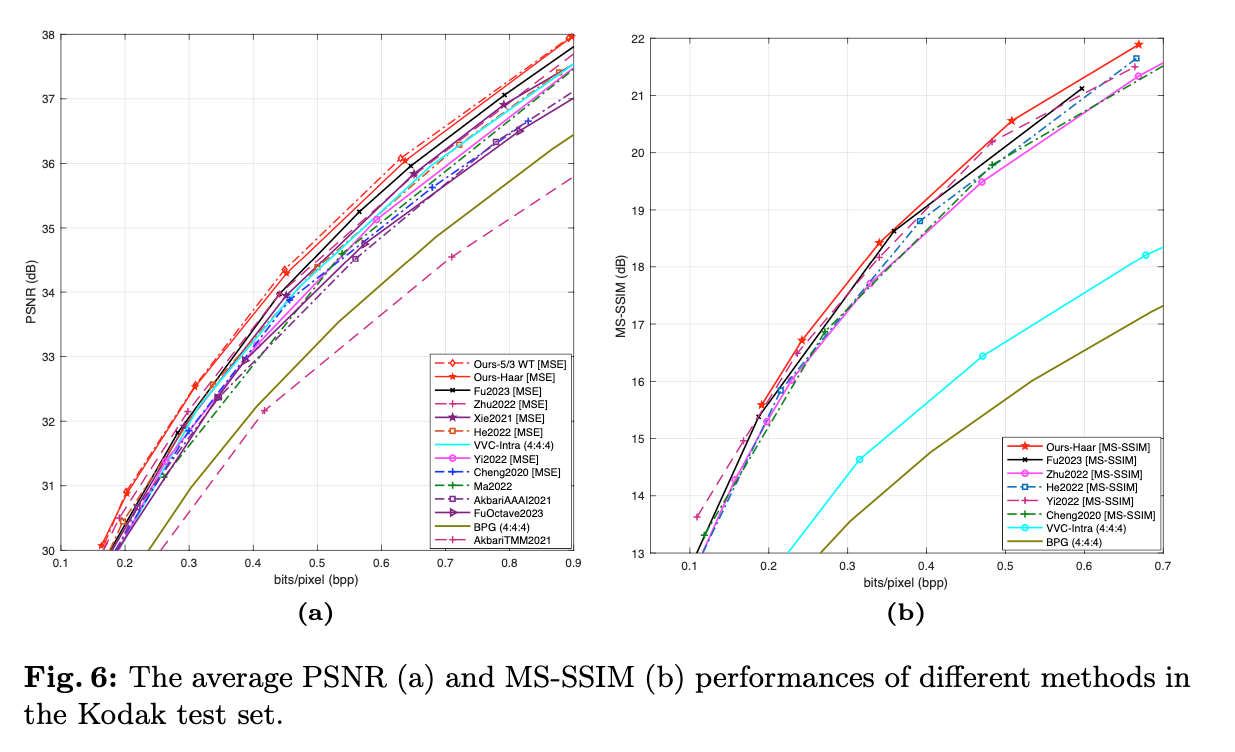
제안된 WeConvene는 두 종류의 DWT를 사용하여 성능 비교를 진행했고, RD-Curve에서 PSNR, MS-SSIM 두 이미지 정량 지표에서 비교 모델들 보다 좋은 성능을 보였다.
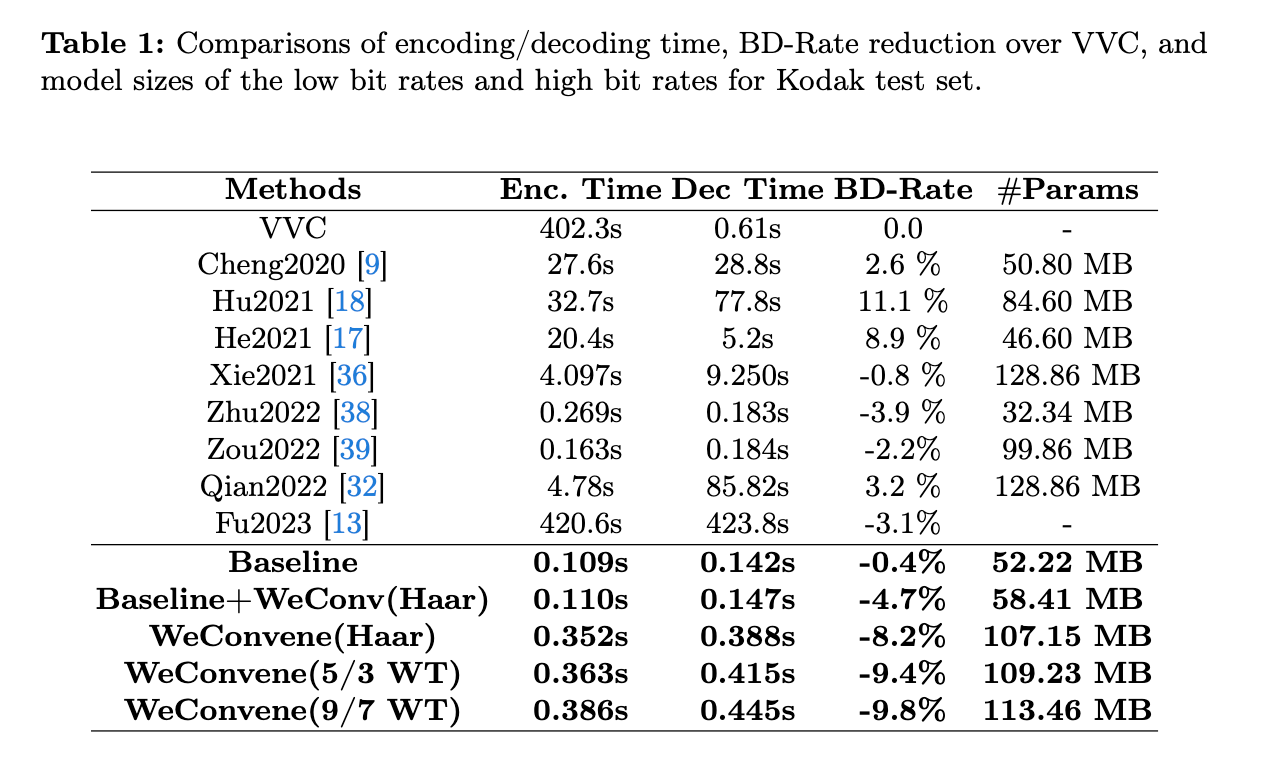
인코딩-디코딩 시간을 살펴보면 WeChARM을 사용하지 않고, WeConv만 사용했을 때는 Baseline과 큰 차이가 없었지만 성능은 향상되었다.
추가로 WeChARM을 사용한다면 인코딩 디코딩 시간은 크게 늘어나지만 압축 성능(BD-Rate)는 증가하는 것을 확인할 수 있다.
Conclusions
- LIC의 컨볼루션과 엔트로피 코딩에 DWT를 적용한 방식을 제안. 이를 통해 웨이블릿 도메인에서 더 sparse해져서 R-D performancerㅏ 향상됨.
- WeConv만 적용해도 성능의 향상을 보였으며, WeConv + WeChARM을 사용한다면 모델의 복잡도는 향상되나 압축 성능은 더 향상됨.
- 향후 multiple level 웨이블릿 변환도 적용해면 좋을 것 같다고함. (입력 크기가 클 때는 긴 웨이블릿을, 작은 경우에는 짧은 웨이블릿을 사용)
