[Compression] Region-Adaptive Transform with Segmentation Prior for Image Compression (SegPIC) 리뷰
Image Compression
논문 제목
Region-Adaptive Transform with Segmentation Prior for Image Compression (ECCV 2024)
URL: https://arxiv.org/abs/2403.00628
인용수 : 2회 (24.12.07 기준)
Github : https://github.com/GityuxiLiu/SegPIC-for-Image-Compression
요약
- Learned Image Compression은 CNN 기반 혹은 Self-Attention 기반 모듈을 사용했다.
- 하지만 특정 영역을 집중적으로 다루는 연구는 없었다.
- 본 연구는 class-agnostic segmentation masks (범주 레이블이 없는 마스크)를 활용하여 region-adaptive contextual information을 추출한다.
- 제안된 모듈인 Region-Adaptive Transform(RAT)는 마스크를 기반으로 각기 다른 영역에 adaptive convolutions을 적용한다.
- 또한, 다양한 영역에서 풍부한 contexts 정보를 통합하기 위해 Scale Affine Layer(SAL)이라는 plug-and-play module을 제안.
- 기존 압축 연구는 segmentation masks를 추가적인 입력값으로 사용했지만, 본 연구는 훈련에서만 마스크를 privilege information로 활용하고 inference에서는 사용하지 않는다.
Introductioin
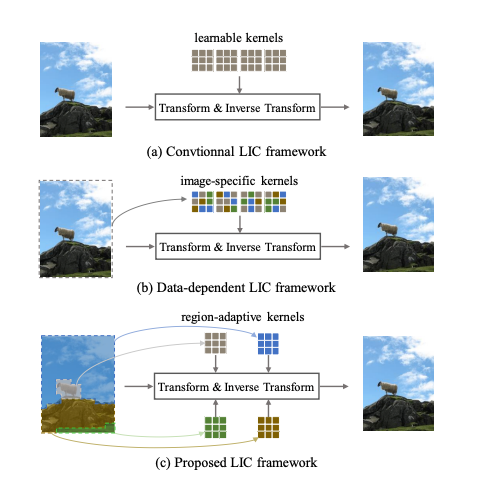
이전 연구에서는 모델 훈련을 통해 커널 파라미터는 고정된다는 한계가 있었다.
하지만 이미지 전체의 context를 기반으로 동적 컨볼루션 커널을 추출하는 data-dependent transform을 도입하여 더 (b)처럼 적응적인 변환을 가능하게 했다.
하지만 단일 이미지 내에서도 그림1처럼 region마다 context가 크게 다를 수 있고, 이미지 수준의 transform만으로는 fine-grained한 signals를 설명하는데는 한계가 있다.
이를 해결하기 위해 본 논문에서는 region-adaptive transform을 통해 다양한 region에서 mapping regularity을 포착하려했다.
디테일하게 설명하면 class-agnostic segmentation masks를 활용하여 tranform에 필요한 region-specific information을 그림1 (c)처럼 추출한다고 한다.
이 연구는 다른 segmentation 기반 이미지 압축 연구들과 두 가지 차별점을 가진다.
-
마스크를 privilege information로 활용하여 inference에서는 마스크 정보를 사용하지 않는다. - 다른 연구에서는 마스크가 필수적으로 사용된다. "class-agnostic" 마스크를 사용하여 semantic labels을 사용하지 않고 데이터 기반 방식으로 모델이 더 effective compression-driven semantic prior을 학습하게 한다.
-
bit-rate와 computational resource 모두에서 추가 비용이 발생하지 않도록 마스크를 privilege information로 처리하여 학습 중에는 사용하지만 inference 단계에서는 inaccessible하게 하였음.
=> 두 차별점을 통해 coarse partition regions(i.e given uniform grid partitions)에서도 contextual information을 잘 다룰 수 있다고함.
이를 바탕으로 본 연구에서는 Segmentation-Prior-Guided Image Compression(SegPIC)이라는 프레임워크를 제안했다.
주요 Contribution은 아래와 같다.
- SegPIC은 data-driven 방식으로 더 효과적인 region-adaptive transforms을 생성.
- Region-Adaptive Transform (RAT) 와 Scale Affine
Layer (SAL)을 통해 잠재표현의 semantic contexts을 더 잘 추출함. - class-agnostic masks를 SegPIC 훈련을 보조하기 위한 privilege information으로 활용한다.
privilege information란?
훈련(training) 단계에서는 사용되지만, 추론(inference) 단계에서는 사용되지 않는 추가적인 정보를 의미. 실제 추론 과정에서는 필요하지 않기 때문에, 추가적인 비용이나 복잡도를 발생시키지 않는다.
Proposed SegPIC
Motivation
기존의 transform(여기서는 인코더-디코더,Hyperprior을 의미하는 것 같다.)는 고정된 파라미터를 가진 컨볼루션 또는 image-specific 컨볼루션을 사용했다. 본 연구에서는 세 가지 컨셉을 통해 region-adaptive transform을 구성했다고 한다.
- Region-dependent (지역 의존)
- Class-Agnostic (클래스 비의존)
- Privilege Information (특권 정보)
위 세 가지에 기반해서 VAE 프레임워크에 두 가지 모듈(RAT & SAL)을 통합하여 SegPIC을 구축했다고 한다.
두 모듈은 인코더, 디코더 양쪽에서 사용이 가능하다고 함.
RAT(Region-Adaptive Transform)
Depth&Point-wise Separable Convolution(DPSConv)를 사용하여 마스크의 guide를 통해 prototype과 context of latent feature를 기반으로 가중치가 생성되는 novel convolution임. 훈련 중에는 RAT가 마스크를 사용해서 compression-friendly semantic priors를 더 잘학습하게 하지만, inference 단계에서는 이를 uniform grid
partitions로 대체함.
이 논문에서 prototype이란?
segmentation mask를 기반으로 특정 영역에서 추출된 잠재 표현(latent representation)을 의미
SAL(Scale Affine Layer)
더 풍부한 semantic과 context를 추출하여 인코더와 디코더에서 프로토타입을 강화하는 역할을 수행.
Formulation
대부분의 수식은 기존의 LIC 수식과 일맥상통하였고, 마지막 문단만 SegPIC만의 수식이다.
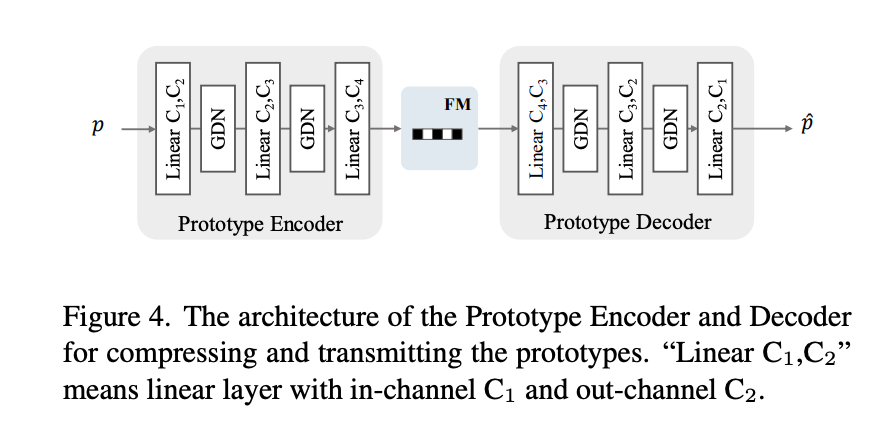
class-agnostic semantic masks()를 훈련 단계에서 인코더 의 추가 입력으로 사용한다. 또한, 인코더의 중간 층에서 각 region의 프로토타입을 추출 후 이를 압축하여 전송한다(=). inference 단계에서는 마스크 대신 uniform grid partition을 사용하여서 마스크에 대한 추가적인 비트스트림이 필요하지 않음. 단, 프로토타입의 비트스트림은 필요.
Network Design
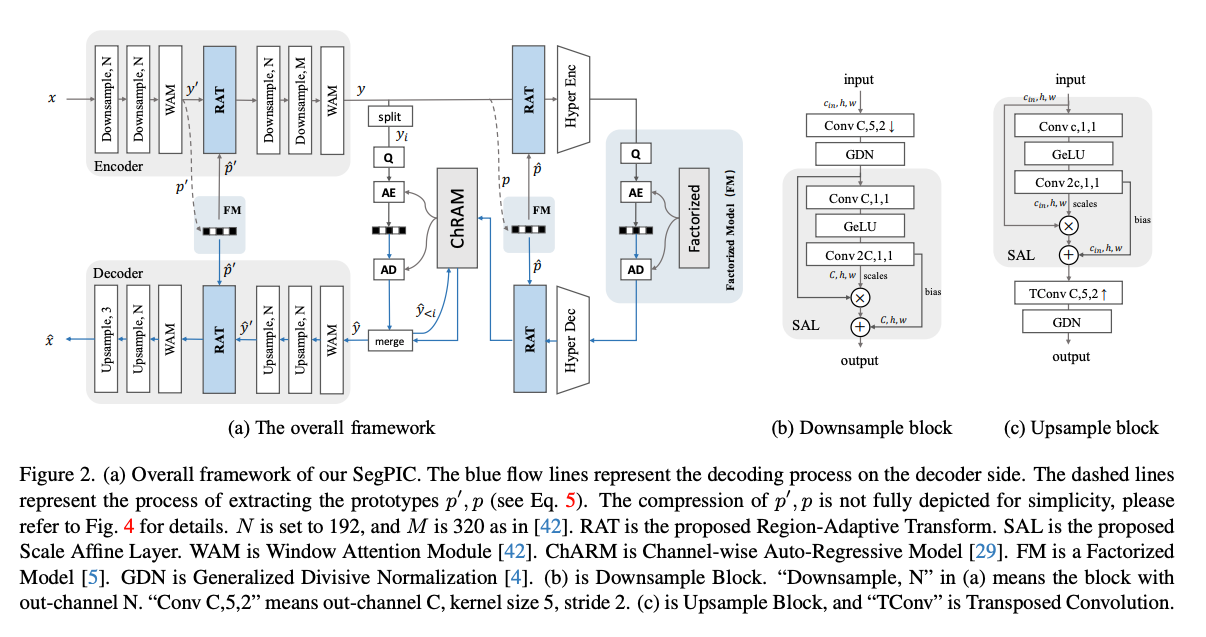
SegPIC의 백본은 "The devil is in the details: Window-based attention for image
compression." 논문에서 WACNN을 사용했다고 한다.
Scale Affine Layer
인코더와 디코더는 각각 4개의 다운샘플링 및 업샘플링 블록으로 구성되며, 이미지 변환 및 복원을 담당한다.
이전 연구들의 샘플링 블록은 데이터 크기를 변경하기 위한 단일 샘플의 컨볼루션 레이어로 구성되어 있다. 하지만 이는 충분한 semantics와 contexts를 추출하기엔 부족하다.
이 연구에서는 Spatial Feature Transform(SFT)에서 영감을 받아 두 개의 인접한 컨볼루션 레이어 사이에 Scale Affine Layer(SAL)을 추가했다.
AL은 두 개의 1x1 컨볼루션 레이어와 그 사이에 GELU 활성화 함수를 포함하며, 다음과 같이 수식으로 표현된다.
여기서 X,Y는 입력과 출력, 와 는 각각 scale과 bias를 나타낸다.는 element-wise product를 나타낸다.
이 모듈을 통해 latent feature를 더 풍부한 semantics와 contexts를 가지는 차원으로 affine해서 프로토타입을 효과적으로 추출할 수 있다고 한다.
Extract and Transmit the Prototypes
모델 figure를 살펴보면 이미지 x에서 다운샘플링 2번(middle layer)을 통해 에서 사이즈가 1/4로 변환된다. 그 후 class-agnostic masks 을 사용해서 Masked Average Pooling(MAP)을 수행한다. 이를 통해 프로토타입 $을 생성한다.
여기서 n은 마스크의 개수이다.
제안된 SAL을 통해 인코더는 더 깊어지고, 는 해당 마스크로부터 더 많은 semantic and context를 통합한다.
여기서
: middle layer에서 추출된 피쳐
: 각 마스크 i
: 각 마스크와 연결된 프로토타입
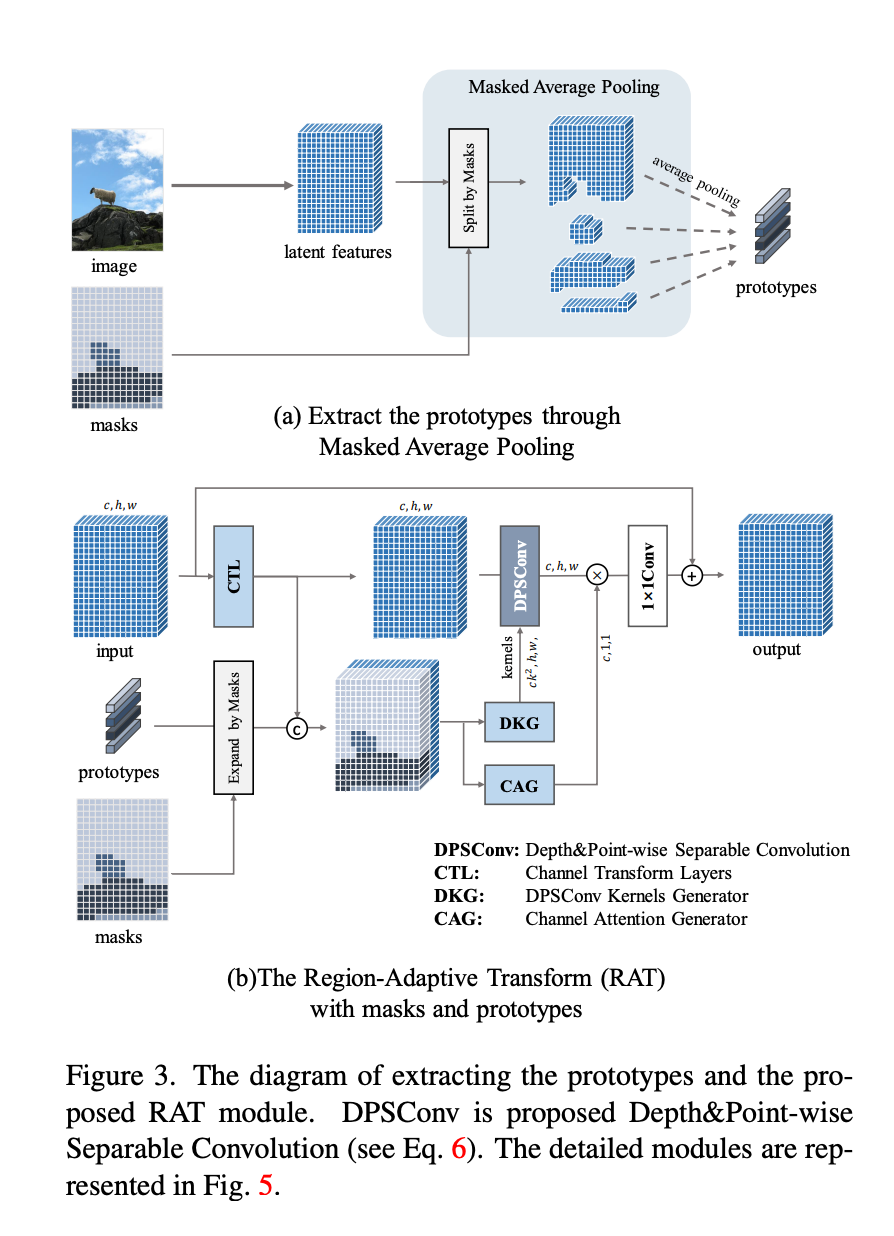
Region-Adaptive Transform
region-specific convolution은 object detection과 segmentation task에서 효과적임을 보였다. 이 논문에서는 해당 접근방식을 이미지 압축의 transform 과정에 최초로 도입했다고 한다.
연구에서는 Depth&Point-wise Separable Convolution(DPSConv)이라는 컨볼루션을 제안한다. 이 방식은 각 element가 독립적인 컨볼루션 커널을 가지고, 효율적인 계산을 위해 채널간 상호작용이 없다고 한다.
Standard Convolution
DPSConv
DPSConv는 Depthwise Separable Convolution(DWConv)와 Dynamic Convolution의 조합으로 이루어져있다. 각 element가 독립적인 컨볼루션 커널을 가지며 채널 간 상호작용이 없다.
DPSConv의 계산 복잡도는 다음과 같이 나타납니다
복잡도는 Depthwise Separable Convolution(DWConv)와 동일하다.
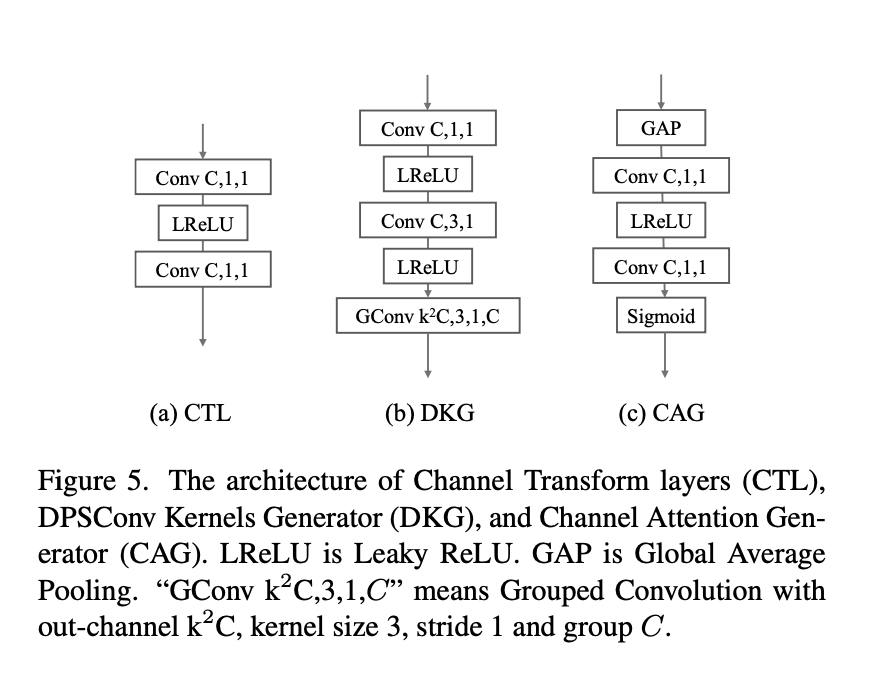
RAT의 Flow는 아래와 같다.
-
우선 마스크의 위치 정보를 기반으로 프로토타입을 확장하며, 각 픽셀 위치에 프로토타입 복사본을 채워 넣습니다.
-
입력을 Channel Transform Layers (CTL)통해 전달하고 확장된 특징과 결합. 이를 통해 sementic & context를 포함한 변수를 생성.
-
DPSConv Kernels Generator(DKG)는 필터를 생성하도록 설계됨. 첫 번째 레이어에서는 1×1 컨볼루션을 사용하여 프로토타입과 픽셀의 고유 속성을 추출. 마지막 레이어에서는 grouped convolution을 사용해 계산 복잡도와 파라미터 부담을 줄인다.
-
Channel Attention Generator(CAG)는 채널 차원별로 attention을 진행하여 DPSConv의 출력과 곱한다. 마지막으로 출력은 1×1 컨볼루션을 통과해 채널 정보를 통합함.
모델 아키텍쳐를 살펴보면 인코더와 디코더, entropy encoding module에도 모두 적용했다.
Entropy Encoding Module
엔트로피 추정 모듈에는 Channel-wise Auto-Regressive Model(ChARM)을 사용했고, 그룹 수는 Slice=10을 사용했다.
Gaussian prior distribution 은 자기회귀 방식으로 추정, 이 때 의 평균과 스케일은 이전 그룹 의 양자화된 잠재 변수에 의존.
SegPIC에서는 추정 능력을 향상시키기 위해 모듈에 RAT를 추가로 배치함. 여기서 RAT는 key region prototype을 별도의 비트스트림을 통해 전송하고 인코딩 및 디코딩 효율을 높이는 데 도움을 줌.
프로토타입 는 segmentation-prior information로 볼 수 있고, 하이퍼프라이어 정보를 보완하는데 사용된다.
Experiments
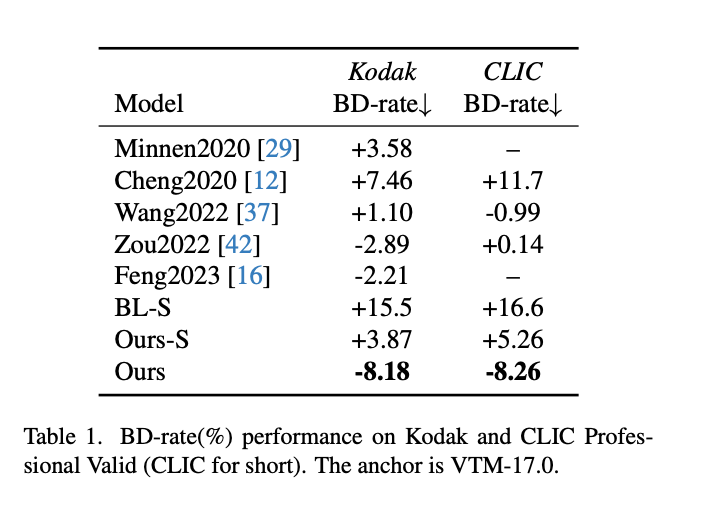
BD-rate를 살펴보면 백본 모델과 이전 Segmentation 기반 압축 모델보다 우수한 성능을 보였다.
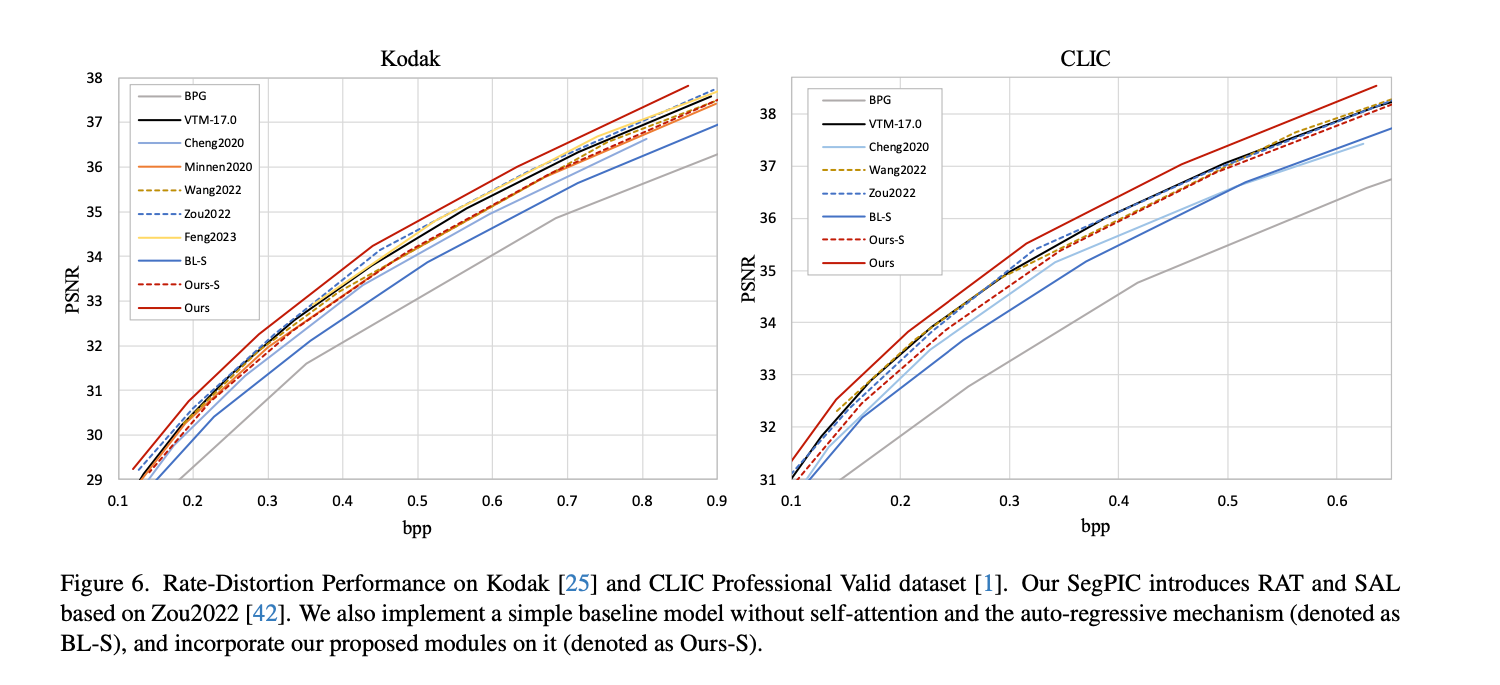
RD-Curve 그래프에서도 제안 방법이 BL(BaseLine)인 WACNN보다 뛰어난 것을 확인할 수 있다.
여기서 BL-S와 Ours-S는 어텐션 메커니즘과 Context 모델을 제거한 Ablation Study로 보인다.

이미지의 정성 & 정량적인 metric에 대해서도 비교 방법들보다 우수한 성능을 보였다.
여기서 드는 궁금증은 "훈련 데이터셋에 마스크가 없으면 어쩌지..." 였다. 보통 훈련데이터셋은 이미지만 사용하는 연구가 9할이 넘기 때문에 이 모델을 적용하려면 마스크를 추가적으로 만들어야하는 문제가 있었다.
프레임워크의 Ablation Study를 살펴보면 이 모델은 마스크가 없어도 사용할 수 있다, 하지만 성능은 다소 떨어질 수 있다가 결론이었다.
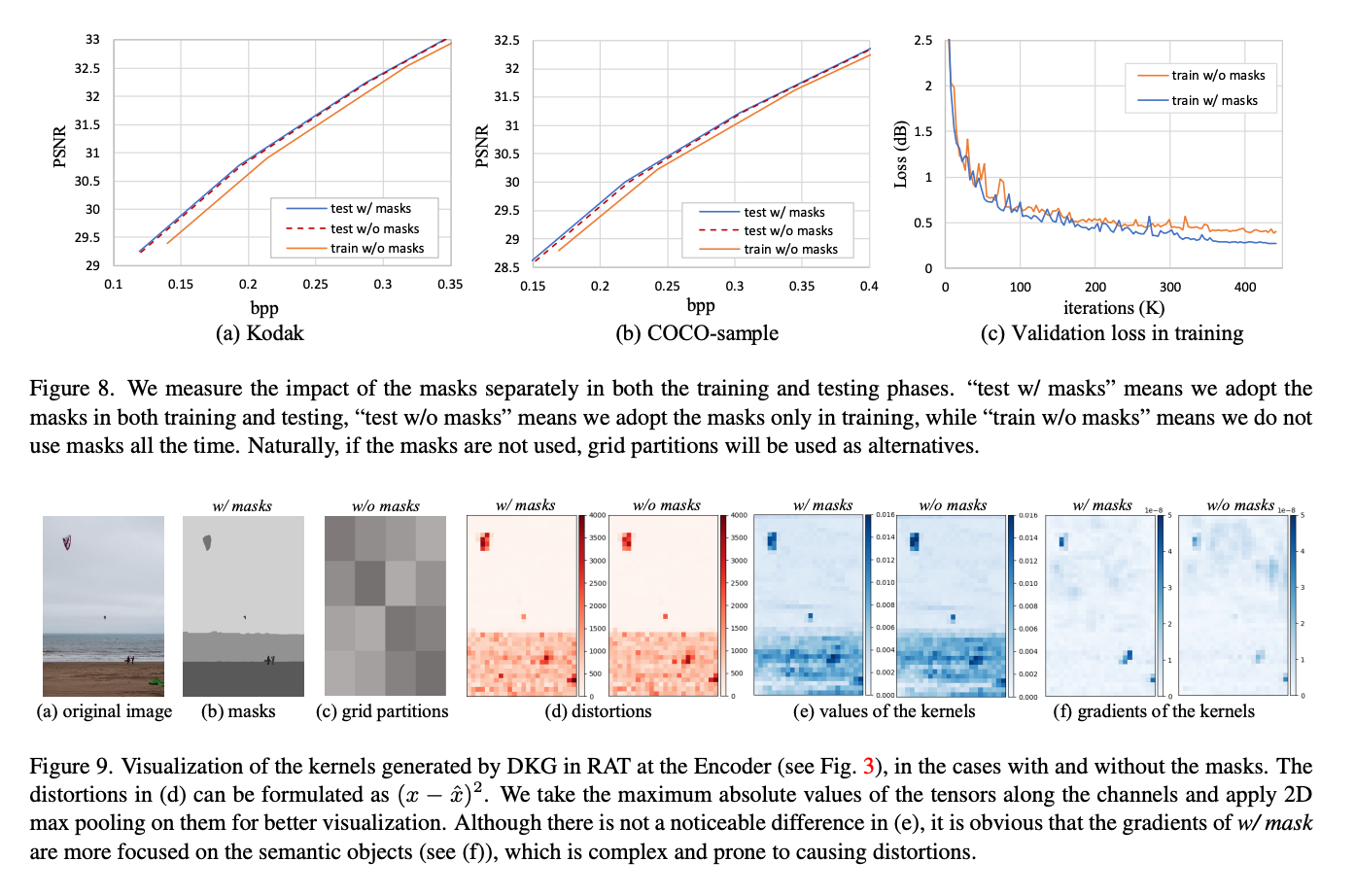
위 두 Figure를 살펴보면 mask가 있을 때와 없을 때의 Rd-Curve와 Loss 그래프이다. 마스크가 있는 경우가 성능적으로는 우수하나, 없는 경우에도 성능이 그렇게 많이 감소하진 않는 것을 확인할 수 있다.
Figure 9를 살펴보면 마스크가 없는 경우에는 mask대신 uniform grid partitions을 사용한다고 한다.
distortions과 gradients of the kernels을 살펴보면 mask가 있을 때 semantic objects에 더 집중되는 것을 확인할 수 있다.
Conclusion
- SegPIC은 RAT와 SAL이 핵심적인 모듈이다.
- SegPIC은 마스크를 훈련에만 활용하고 추론에서는 사용하지 않는다. 이 방법이 기존 방법들과의 핵심 차별점이다.
- Mask가 없는 데이터셋이라도 이 모델을 사용할 순 있다. 단, 성능은 하락할 수 있다.
코드에서는 "--useMask" 파라미터를 통해 mask 유무를 선택하면 된다.
