논문 제목
YOLOv12: Attention-Centric Real-Time Object Detectors
URL: https://www.arxiv.org/abs/2502.12524
인용수 : 0회 (25.2.21 기준)
Docs : https://docs.ultralytics.com/ko/models/yolo12/
Code : https://github.com/sunsmarterjie/yolov12.
YOLO는 One-Stage Detector의 대표적인 모델로, real-time detection을 가능케해준 모델이다. v11에 대해 다룬적이 있었는데 근래 v12가 릴리즈되었습니다.
그래서 또 어떤 매커니즘을 사용해서 속도와 성능을 둘다 잡았는지 알아보려합니다.
YOLOv12: A Breakdown of the Key Architectural Features
https://arxiv.org/abs/2502.14740
YOLOv12 to Its Genesis: A Decadal and Comprehensive Review of The You Only Look Once (YOLO) Series
https://arxiv.org/abs/2406.19407
YOLOv12 아키텍쳐
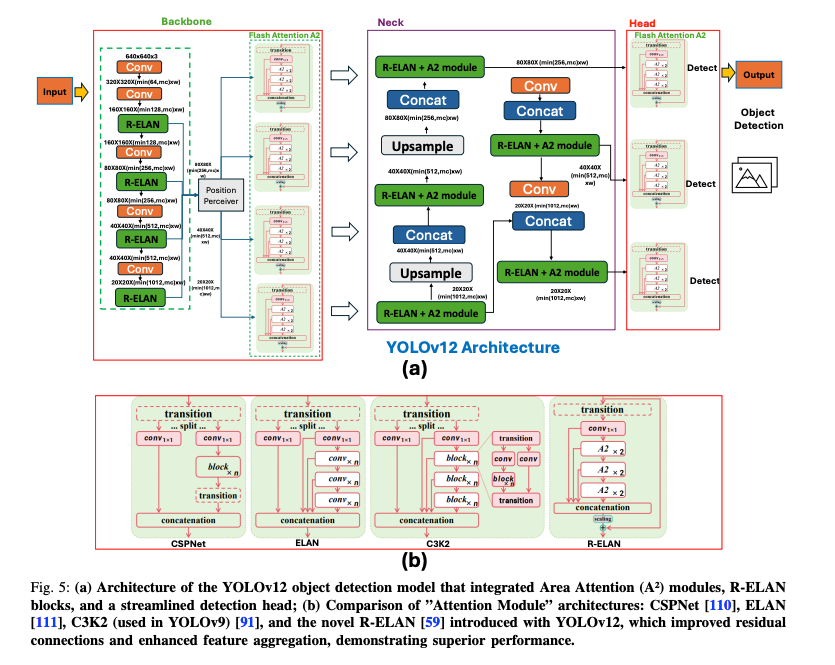
해당 논문도 참고해보시면 좋을 것 같습니다.
요약
- YOLO 프레임워크의 네트워크 아키텍처를 향상시키는 것은 오랫동안 중요한 과제였으며, CNN 기반의 개선에 집중되어 왔다.
- 하지만 어텐션 매커니즘이 모델링 성능에서 우수성이 입증되었음에도 불구하고, YOLO 프레임워크에서는 적극적으로 사용하지 않았음. -> 어텐션 기반 모델이 느려서 CNN 기반 모델의 속도를 따라잡지 못하기 때문...
- 본 논문에서는 어텐션 메커니즘의 성능 이점을 활용하면서도 기존 CNN 기반 YOLO 모델과 동등한 속도를 갖춘 attention-centric YOLO 프레임워크 (YOLOv12)를 제안함.
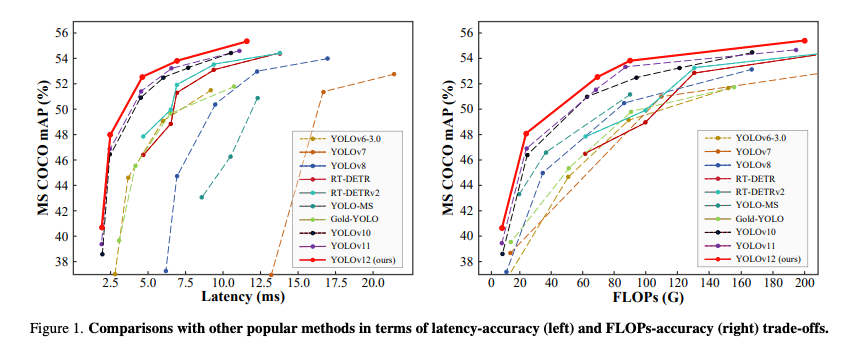
Introduction
YOLO의 발전은 loss functions이나 label assignment등의 영역에서 이루어졌지만, network architecture design이 중요한 연구 우선순위로 남아있다.
Attention-centric vision transformer (ViT)는 강력한 모델링 능력을 갖췄으나 대부분의 아키텍쳐 설계는 여전히 CNN 중심으로 설계된다.
이 상황이 지속되는 주요 원인은 어텐션 메커니즘의 비효율성이며, 두 가지 원인이 있다.
- self-attention의 연산 복잡도가 시퀀스 길이가 L이라고 하면 로 이차 복잡도라는 점이다.
- 메모리 접근이 비효율적이다.
결과적으로 동일한 연산 예산 내에서 CNN 기반 아키텍처는 어텐션 기반 아키텍처보다 약 3배 높은 성능을 보인다. 이로 인해 YOLO 시스템과 같이 높은 추론 속도가 필수적인 환경에서 어텐션 메커니즘의 도입이 제한됨.
본 논문은 이런 문제를 해결하고 Attention-Centric YOLO 프레임워크인 YOLOv12를 제안함.
본 논문에서는 세 가지 주요 개선 사항을 도입했다고 한다.
- Area Attention module (A2)
- Residual Efficient Layer Aggregation Networks (R-ELAN)
- FlashAttention
이를 통해 YOLOv12의 Contribution은 두 가지로 정리할 수 있다.
- CNN 중심 YOLO 모델의 한계를 넘어서, 단순하지만 효율적인 attention-centric YOLO 프레임워크를 확립.
- 추가적인 사전 학습 없이도 YOLOv12는 빠른 추론 속도와 높은 탐지 정확도를 달성하며, 기존 모델을 능가하는 성능을 보임.
Approach
Efficiency Analysis
어텐션 메커니즘은 global dependencies을 포착하는 데 매우 효과적이며, 자연어 처리 및 컴퓨터 비전과 같은 작업에서 중요한 역할을 한다. 하지만 CNN보다 느리다. 어텐션이 CNN보다 느린 이유는 크게 두 가지이다.
Complexity
어텐션 연산의 계산 복잡도는 입력 시퀀스 길이 L에 대해 이차복잡도를 가진다.
예를 들어서 입력 시퀀스의 길이가 L이고 특징 차원이 d일 때, 어텐션 행렬을 계산하는 데 𝒪(L²d) 연산이 필요하다. 왜냐면 각 토큰이 모든 다른 토큰에 어텐션을 적용하기 때문이다. 반면에 CNN의 합성곱 연산은 𝒪(kLd)의 선형 복잡도를 가지며, 여기서 k는 커널 크기로 보통 L보다 훨씬 작다.
결과적으로 self-attention은 고해상도 이미지나 긴 시퀀스 입력을 처리할 때 계산량이 급격히 증가하여 연산 부담이 커진다.
또한, 대부분의 attention-based vision transformers는 복잡한 디자인 (window partitioning/reversing)과 추가 모듈 (positional encoding)로 인해 점차 speed overhead가 누적되어 CNN 구조에 비해 속도가 느려진다.
Computation
어텐션 연산 과정에서 메모리 접근 패턴이 CNN보다 비효율적임.
self-attention을 계산하는 동안 attention map 및 softmax map 과 같은 중간 데이터를 GPU SRAM (실제 연산이 수행되는 위치)에서 고대역복 GPU메모리 (HBM)으로 저장한 후 다시 불러와야한다고 한다.
하지만 GPU SRAM의 읽기 및 쓰기 속도는 GPU 메모리보다 10배 이상 빠르므로, 이러한 반복적인 메모리 이동으로 인해 큰 memory access overhead가 발생하고, wall-clock time이 증가한다고 한다.
또한, 어텐션의 irregular memory access 방식은 CNN보다 더 높은 지연 시간을 유발한다고 한다. 반면, CNN은 fixed receptive fields과 sliding-window 연산을 사용하여 공간적으로 제한된 커널을 적용하므로, 메모리 캐싱이 최적화되고 지연 시간이 감소함.
위 이유로 어텐션 매커니즘은 CNN보다 속도가 느리고, 실시간 또는 자원이 제한된 환경에서는 실행이 어렵다.
본 논문에서는 이를 해결하기 위해 FlashAttention을 직접 활용하여 어텐션 메커니즘의 비효율성을 보완했다고함.
Area Attention
Vanilla Attention의 계산 비용을 줄이는 간단한 방법은 linear attention 메커니즘을 활용하는 것이다. linear attention은 어텐션의 복잡도를 이차복잡도에서 선형복잡도로 감소시킨다.
하지만 linear attention은 global dependency degradation가 발생하며, instability하고, distribution sensitivity한 문제점이 있다고함.
그리고 low-rank bottleneck 문제로 인해 YOLO와 같이 640×640 해상도 입력을 처리할 때 속도 이점이 크지 않다고 한다.
이러한 문제를 해결하는 또 다른 방법은 local attention 메커니즘을 적용하는 것이다. Shifted Window Attention, Criss-Cross Attention, Axial Attention등과 같은 어텐션 기법들은 global attention을 local로 변환하여 연산 비용을 줄였다.
그러나 Feature Map을 window로 분할하면 연산 오버헤드가 증가하거나 receptive field가 감소하여 속도 및 정확도에 영향을 줄 수 있다.

본 연구에서는 보다 단순하면서도 효율적인 Area Attention을 제안함.
위 그림처럼 Feature Map(H,W)를 수직 또는 수평으로 I개 영역으로 분할함.
각 영역의 크기는 (H/I, W) 또는 (H,W/I)가 된다. 이렇게 하면 명시적인 윈도우 분할 없이 단순한 reshape 연산만으로 어텐션을 수행할 수 있다고 한다.
이 방법은 연산 속도를 빠르게 유지하면서도 큰 수용 영역을 유지할 수 있도록 함.
실험에서는 기본적으로 I=4로 설정하였으며, 이를 통해 전체 수용 영역의 1/4을 유지하면서도 연산 효율을 높일 수 있었다고 함.
이 방식은 attention의 계산 복잡도를 𝒪(2n²hd)에서 𝒪(1/2 n²hd)로 줄인다. 비록 복잡도가 여전히 𝒪(n²)이지만, YOLO 시스템에서 입력 해상도를 640으로 고정하면 충분한 실시간 성능을 유지할 수 있음.
흥미롭게도, 이 방식은 성능 저하를 거의 유발하지 않으면서도 속도를 크게 향상시킨다고 한다.
Residual Efficient Layer Aggregation Networks
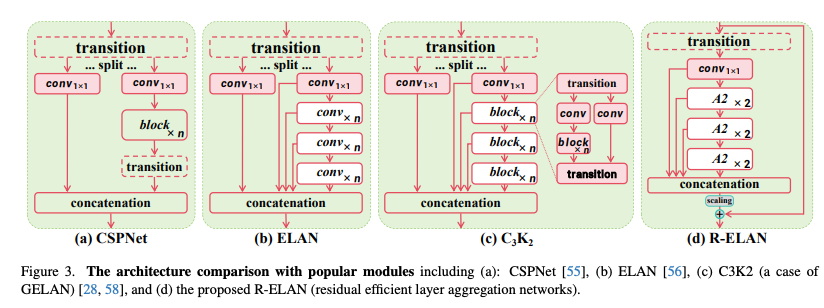
Efficient layer aggregation networks (ELAN)은 feature aggregation을 향상시키도록 설계되었다.
위 그림처럼 ELAN은 transition layer(1×1 convolution)의 출력을 여러 모듈을 통해 두 개의 경로로 분할한 후, 모든 출력을 concatenate하고 차원을 정렬하기 위해 또 다른 transition layer(1×1 convolution)을 적용한다. 하지만 이러한 아키텍쳐는 불안정성을 유발한다고 한다.
본 논문에서는 이 설가 gradient blocking을 발생시키며, 입력에서 출력까지의 residual connection이 부족하다고 주장.
네트워크를 attention 메커니즘을 중심으로 구축하면서 추가적인 최적화 문제를 일으킨다고 한다. 실험적으로 L- 및 X- 규모의 모델들은 Adam 또는 AdamW 옵티마이저를 사용하더라도 수렴하지 않거나 불안정한 상태로 남아 있는 경향을 보였다고함.
이 문제를 해결하기 위해 Residual Efficient Layer Aggregation Networks (R-ELAN)을 제안. 기존 방식과 달리 입력에서 출력까지 잔차(shortcut) 연결을 추가하고, 블록 전체에서 scaling factor (default= 0.01)를 적용.
이 설계는 layer scaling과 유사하고 깊은 vision transformer를 구축하는 데 사용된다고 한다. 그러나 각 attention 영역에 대해 layer scaling을 적용하면 최적화 문제를 해결하지 못하며 latency가 증가하는 문제가 발생. 이는 attention 메커니즘의 도입만으로는 수렴을 보장하기 어렵다는 점을 의미하며, ELAN 아키텍처 자체의 한계가 존재함을 보여줌과 동시에 R-ELAN 설계를 뒷받침하는 근거가된다.
기존 ELAN 레이어는 모듈의 입력을 먼저 transition layer를 통과시킨 후, 이를 두 부분으로 분할하여 처리한다. 한 부분은 이후 블록을 통해 추가적으로 처리되며, 마지막으로 두 부분이 concatenation되어 출력을 생성한다.
R-ELAN의 경우 채널 차원을 조정하기 위해 transition layer를 적용한 후, 단일 특징 맵을 생성한다. 이 특징 맵은 후속 블록을 거쳐 처리된 후 concatenation 과정을 거쳐 bottleneck structure를 형성한다. 이 접근 방식은 기존의 feature integration 능력을 유지하면서도, 연산 비용과 파라미터/메모리 사용량을 모두 감소시킨다.
Architectural Improvements
본 섹션에서는 전체 아키텍처 및 기존 어텐션 메커니즘에 대한 몇 가지 개선 사항을 소개한다. 이들 중 일부는 처음으로 제안한 것이 아님.
기존 어텐션 메커니즘의 여러 기본 구성을 YOLO 시스템에 보다 적합하도록 조정한다. 이러한 조정에는 다음이 포함된다.
- MLP 비율을 4에서 1.2 (N- / S- / M- 규모 모델의 경우 2)로 조정하여 계산 자원을 보다 효율적으로 배분하고 성능을 향상시킴.
- nn.Linear+LN 대신 nn.Conv2d+BN을 채택하여 합성곱 연산자의 효율성을 최대한 활용.
- positional encoding 제거
- large separable convolution (7 × 7) (position
perceiver)을 도입하여 area attention이 위치 정보를 인식하도록 지원.
Experiment
Experimental Setup
모델 검증은 MSCOCO 2017 데이터셋을 사용했다고 함.
모든 모델은 SGD 옵티마이저를 사용하여 600 에포크 동안 학습되며, learning rate은 0.01로 설정되어 있으며, 이는 YOLOv11과 동일하다.
Baseline은 이전 버전인 YOLOv11을 선택했다고 한다.
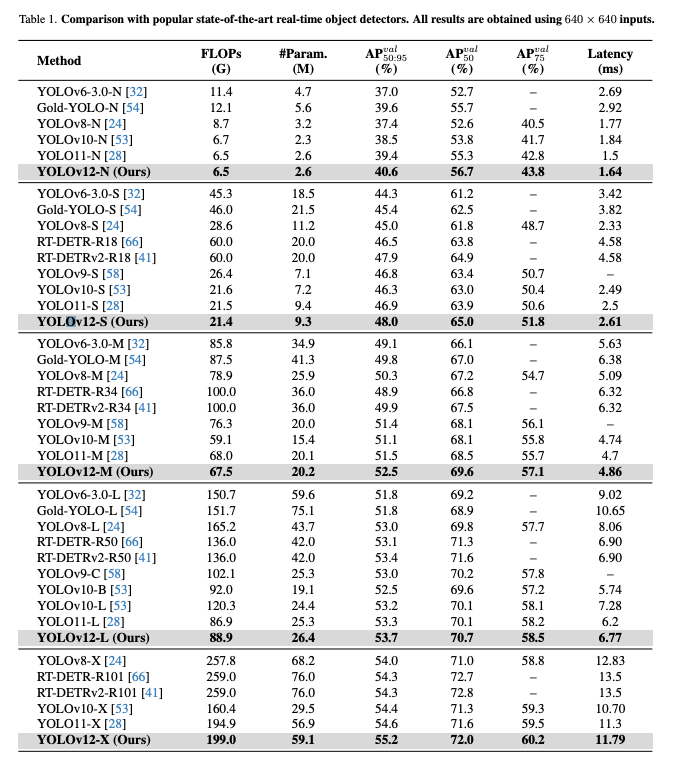
Comparison with State-of-the-arts
비교모델은 이전 YOLO 시리즈들 (v6~v11)과 RT-DETR 시리즈를 사용했다고 한다.
Conclusion
- 본 연구에서는 YOLOv12를 제안했고, 기존에 실시간 처리에 비효율적이라고 여겨졌던 attention-centric design를 YOLO 프레임워크에 성공적으로 적용함.
- 효율적인 추론을 위해 area attention을 도입하여 계산 복잡도를 줄이고, Residual Efficient Layer Aggregation Networks (R-ELAN)을 도입하여 Feature Aggregation를 향상 시킴.
- 실험결과 YOLOv12는 area attention, R-ELAN, 그리고 아키텍처 최적화를 효과적으로 결합하여 state-of-the-art performance를 달성.
본 연구는 기존의 CNN 기반 설계가 YOLO 시스템에서 지배적이었던 것을 뒤집고, 실시간 객체 탐지를 위한 어텐션 메커니즘의 통합을 발전시킴으로써, 보다 효율적이고 강력한 YOLO 시스템을 구축하는 길을 열었다.
Limitations
YOLOv12는 FlashAttention이 필요하며 특정 GPU에서만 지원된다고 한다.
