[Object Detection] YOLOv11: An Overview of the Key Architectural Enhancements 리뷰
Object Detection
논문 제목
YOLOv11: An Overview of the Key Architectural Enhancements
URL: https://arxiv.org/abs/2410.17725
인용수 : 0회 (24.10.30 기준)
YOLO 모델을 처음 접하고 공부할 때만해도 버전이 v6였던 것 같은데 벌써 v11이 release되었다.
ultralytics의 코드를 전부 뜯어보기엔 한계가 있었고, 아직 공식적인 논문은 없었다.
현재까지는 주요 아키텍처와 성능을 정리한 논문만 있어서 우선 해당 논문을 읽고 정리해보려 합니다.
이 논문은 핵심 모듈에 대한 디테일한 설명은 없어보입니다,,
요약
- YOLOv11의 주요 아키텍쳐 개선사항은 C3k2 block, SPPF, C2PSA를 통해 모델의 특징 추출과 성능 개선을 이뤄냈다.
- YOLOv11은 object detection, instance segmentation, pose estimation, and oriented object detection (OBB)와 같은 다양한 비전 태스크 기능을 제공한다.
- YOLOv11은 성능적인 측면에서 mAP(mean Average Precision)와 이전 버전 대비 계산 효율성을 높였음.
C3k2 = Cross Stage Partial with kernel size 2
SPPF = Spatial Pyramid Pooling - Fast
C2PSA = Convolutional block with Parallel Spatial Attention
Introduction
- You Only Look Once (YOLO) 알고리즘은 전체 이미지를 한 번에 처리(single-pass)하여 물체와 그 위치를 감지한다.
- YOLO는 객체 검출을 회귀 문제로 설정함으로써 기존의 2-stage detection과 차별화하였다.
-> 단일 CNN 신경망을 사용하여 이미지 전체에서 bounding boxes 와 class probabilities를 동시에 예측하여 전통적인 방법에 비해 파이프라인을 간소화하였음. - YOLOv11은 YOLO Vision 2024 (YV24) 컨퍼런스에서 공개된 모델로 accuracy, speed, efficiency에서 상당한 개선을 이뤘다.
- YOLOv11은 더욱 세밀한 디테일을 캡쳐할 수 있는 advanced feature extraction 기법을 적용하면서도 파라미터 수를 줄여 경량화된 구조를 유지했다.
Evolution of YOLO models
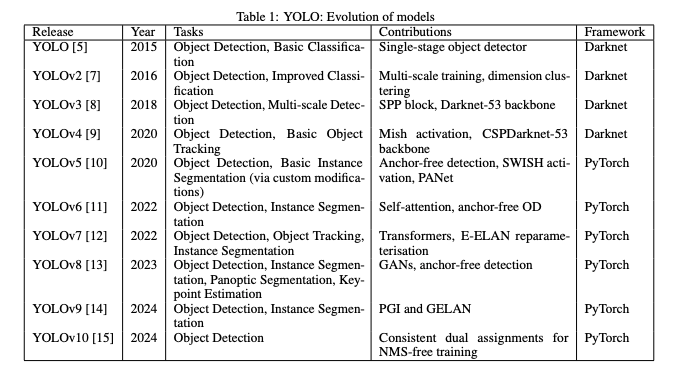
위 표는 YOLO 모델의 초기 버전부터 최신 버전까지의 발전 과정을 보여준다.
각 버전은 객체 검출 능력, 계산 효율성, 다양한 컴퓨터 비전 작업을 처리할 수 있는 범용성에서 개선을 이뤘다.
What is YOLOv11?
- YOLOv11은 이전 버전의 강점을 기반으로 하면서도 다양한 CV applications에서 활용도를 확장하는 새로운 기능을 도입했다.
- 특히 posture estimation과 instance segmentation과 같은 영역에서 모델의 적용 가능성을 넓혀주었음.
- YOLOv11의 디자인은 성능과 실용성의 균형을 맞추는 데 중점을 두고 설계되어 정확도와 효율성을 높여 다양한 산업 분야의 특정 과제를 해결하는 것을 목표로 한다.
Architectural footprint of YOLOv11
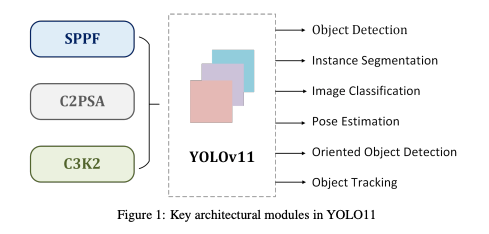
YOLO 아키텍쳐의 핵심 구성요소는 세 가지이다.
1. Backbone은 기본적인 특징 추출 역할을 하며, 원본 이미지 데이터를 multi-scale feature map으로 변환하기 위해 CNN을 사용함.
2. Neck은 중간처리단계로, 다양한 scale의 특징을 집계하고 강화하는 특수한 레이어들을 통해 특징 표현을 증대시킨다.
3. Head는 예측 메커니즘으로, 정제된 feature map을 바탕으로 최종 객체의 위치와 분류를 출력한다.
YOLOv11은 YOLOv8를 기반으로 발전시켰고, 향상된 검출 성능을 달성하기 위해 아키텍처 혁신과 파라미터 최적화를 도입했다.
아래는 YOLOv8의 아키텍쳐이다
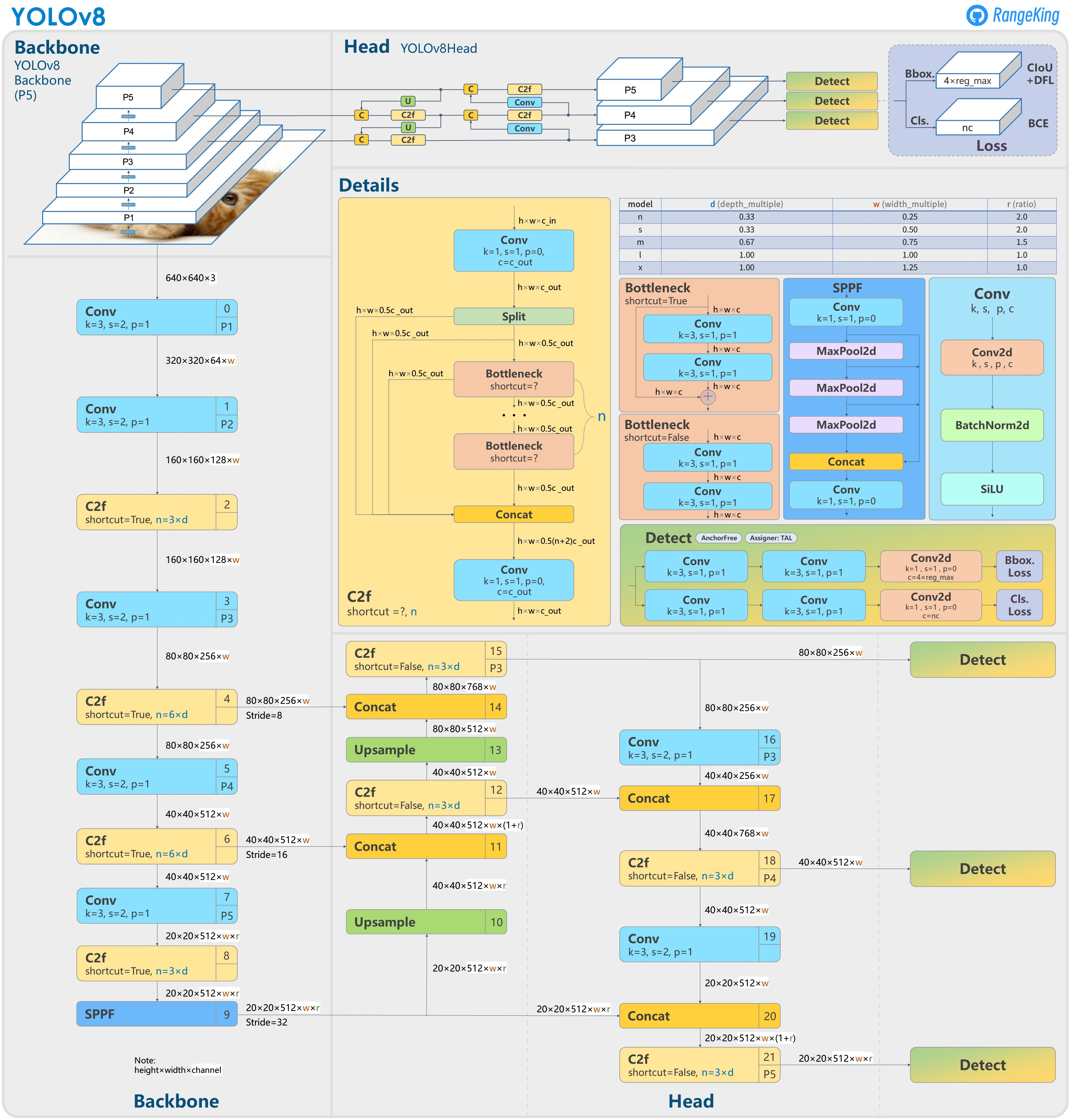
아래는 YOLOv11 레포 내 이슈에서 올려주신 unofficial YOLOv11의 아키텍쳐이다
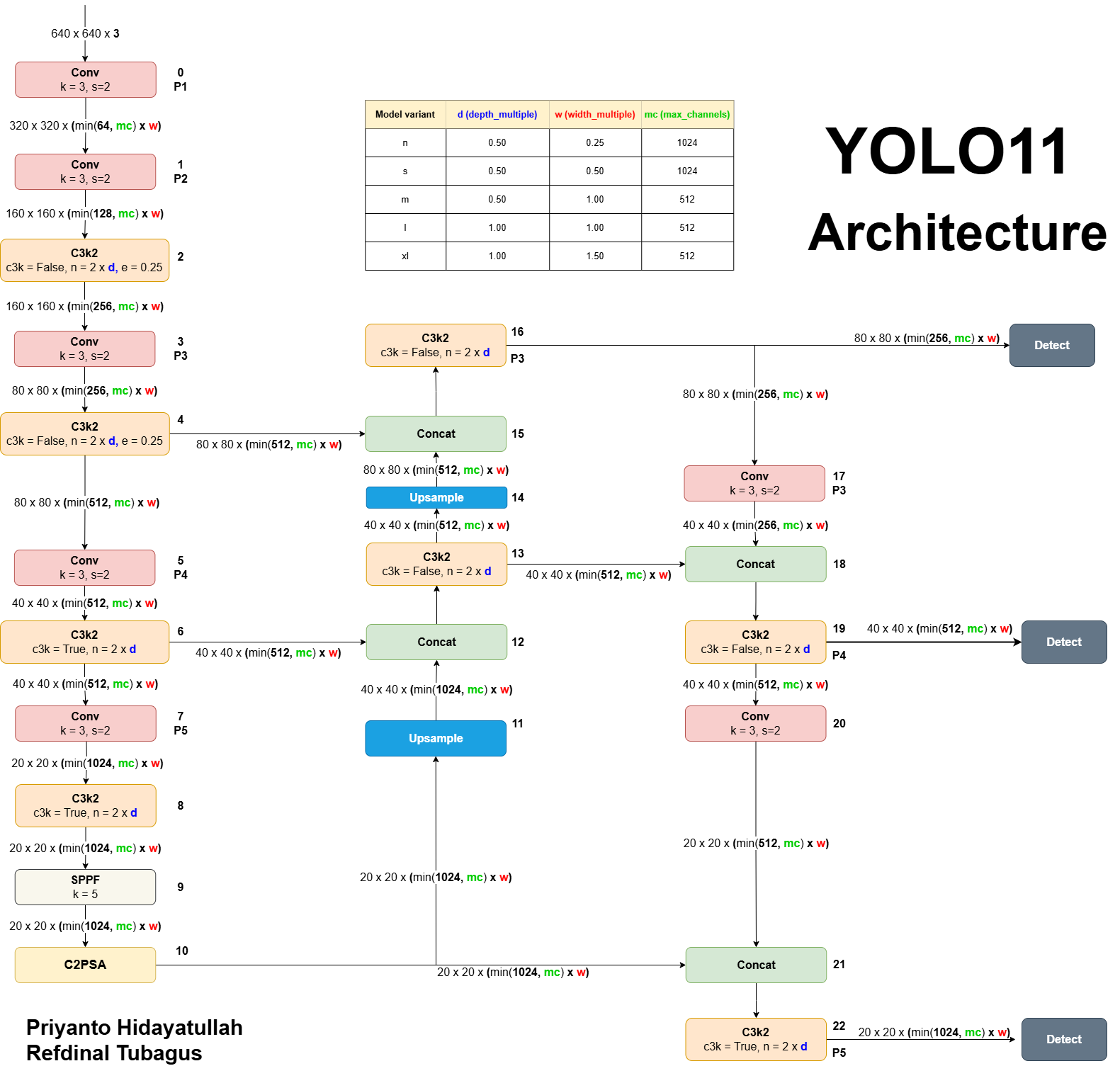
위 이미지를 만드신 분과 동일한 분의 Yolov11 Detail에 대한 설명 영상을 참고해도 좋을 듯합니다.
https://www.youtube.com/watch?v=L9Va7Y9UT8E
Backbone
백본은 multi-scale에서 입력 이미지의 특징을 추출하는 역할을 한다.
이 과정은 convolutional layer와 specialized blocks을 쌓아 다양한 resolution의 feature map을 생성하는 방식으로 이루어진다.
Convolutional Layers
YOLOv11은 이전 버전과 유사한 구조를 유지하며, 컨볼루션 레이어를 사용하여 이미지를 다운샘플링한다.
이 레이어들을 통해 공간적 차원은 점차 줄이고 채널 수를 증가시킨다.
YOLOv11에서의 주요 개선사항은 이전 버전에서 사용된 C2f 블록을 대체하는 C3k2 블록의 도입이다.
C3k2 블록은 Cross Stage Partial (CSP) Bottleneck의 더 효율적인 구현으로, YOLOv8에서의 one large convolution 대신 두 개의 smaller convolutions을 사용한다.
C3k2의 "k2"는 작은 커널 크기를 나타내며, 성능을 유지하면서도 처리 속도를 향상시킨다.
SPPF and C2PSA
YOLO11은 이전 버전에서 사용된 Spatial Pyramid Pooling - Fast (SPPF) 블록을 유지하였다.
하지만 위 이미지를 비교해보면 SPPF 블록 다음에 Cross Stage Partial with Spatial Attention (C2PSA) 블록을 추가한 것을 알 수 있다.
C2PSA 블록은 feature map에서 spatial attention을 강화하는 중요한 추가 요소라고 한다.
spatial attention을 통해 모델이 이미지 내에서 중요한 영역에 더욱 효과적으로 집중할 수 있게 한다.
features를 spatial하게 pooling하여, C2PSA 블록은 YOLO11이 특정 관심 영역에 집중하도록 하여 다양한 크기와 위치의 객체에 대한 검출 정확도를 높일 수 있습니다.
Neck
Neck은 다양한 스케일에서 feature를 결합하여 예측을 위해 head로 전달하는 역할을 한다.
이 과정은 주로 다양한 level의 feature map을 업샘플링하고 concat해서 멀티스케일 정보를 효과적으로 캡쳐하는 방식으로 이루어진다.
C3k2 Block
YOLOv11은 Neck또한 Backbone과 동일하게 C2f 블록을 C3k2 블록으로 대체했다.
C3k2 블록은 더 빠르고 효율적인 방식으로 설계되어 전체적인 특징 집계 프로세스의 성능을 향상시킨다고 한다.
업샘플링과 연결 후, YOLOv11의 neck에 이 개선된 블록이 포함되어 속도와 성능을 증대시킨다고 한다.
Head
YOLOv11의 헤드는 객체 검출과 분류에 대한 최종 예측을 생성하는 역할을 한다.
Neck에서 전달된 feature map을 처리하여, 이미지 내 객체에 대한 경계 상자와 클래스 레이블을 최종 출력으로 생성한다.
C3k2 Block
Head 부분에서 YOLOv11은 Feature map을 효율적으로 처리하고 정제하기 위해 여러 C3k2 블록을 활용함.
C3k2 블록은 헤드의 여러 경로에 배치되어 다양한 depth에서 multi-scale feature를 처리하는 역할을 한다.
C3k2 블록은 c3k 매개변수 값에 따라 다음과 같은 유연성을 보임.
c3k = False일 때, C3k2 모듈은 standard bottleneck structure를 활용하는 C2f 블록과 유사하게 작동.c3k = True일 때, 병목 구조는 C3 모듈로 대체되어 더 깊고 복잡한 특징 추출을 허용
C3k2 블록의 주요 특징은 다음과 같다.
Faster processing: 두 개의 smaller convolutions을 사용하여 single large convolution에 비해 computational overhead를 줄이며, 더 빠른 특징 추출을 가능하게 한다.Parameter efficiency: C3k2는 CSP 병목 구조의 더 컴팩트한 버전으로, trainable parameters를 줄여 아키텍쳐의 효율성을 높임.
또한 C3k 블록이라는 유연한 블록이 추가되어 커널 크기를 customizable하게 할 수 있는 기능을 제공함.
C3k의 adaptability은 이미지에서 더 세밀한 특징을 추출할 수 있어 검출 정확도 향상에 기여한다고 한다.
CBS Blocks
YOLOv11의 헤드에는 C3k2 블록 이후 여러 CBS (Convolution-BatchNorm-SiLU) layer가 포함되어 있다.
- 정확한 객체 탐지를 위한 relevant features 추출
- batch normalization을 통해 데이터 흐름의 안정화 및 정규화
- 비선형성을 위한 Sigmoid Linear Unit (SiLU) 활성화 함수 사용으로 모델 성능 향상
CBS 블록은 특징 추출과 검출 과정 모두에서 중요한 구성 요소로 작용하며, 정제된 feature map을 bounding box와 classification predictions를 위한 후속 레이어에 전달하도록 한다.
Final Convolutional Layers and Detect Layer
각각의 detection branch는 Conv2D layer 세트를 통해 종료된다.
이를 통해 feature를 bounding box coordinate와 class prediction을 위해 필요한 output 수로 줄인다.
최종 Detect 레이어는 이러한 예측을 통합하며 다음을 포함한다
- 이미지 내 객체 위치를 localizing하기 위한 bounding box coordinates
- 객체 존재 여부를 나타내는 objectness scores
- 탐지된 객체의 클래스를 결정하는 Class scores
Advancements and Key Features of YOLOv11
이전 버전과 비교하여 YOLOv11의 개선 사항을 정리하면 다음과 같다고 한다.
1. Enhanced precision with reduced complexity
YOLOv11m 모델은 COCO 데이터셋에서 더 높은 mAP 점수를 기록함.
YOLOv8m과 비교해 22% 적은 파라미터를 사용하여 정확도 하락없이 계산 효율성을 높였음.
2. Versatility in CV tasks:
YOLOv11은 pose estimation, object recognition, image classification, instance segmentation, oriented bounding box(OBB) detection등 다양한 CV application에서 뛰어난 성능을 보임.
3. Optimized speed and performance
개선된 아키텍처 설계와 간소화된 학습 파이프라인 덕분에 YOLOv11은 처리 속도가 빨라졌고, 정확도와 계산 효율성 간의 밸런스를 유지했음.
4. Streamlined parameter count
파라미터 수 감소를 통해 모델의 속도를 높였으나, YOLOv11의 전체 정확도에 큰 영향을 미치지 않았다.
5. Advanced feature extraction
YOLOv11은 backbone과 neck 아키텍처 모두에서 개선된 모듈을 적용하여 강화된 특징 추출을 가능하게 하며, 그 결과 더 정밀한 객체 검출이 가능하였다.
6. Contextual adaptability
YOLOv11은 cloud platforms, edge devices, systems optimized for NVIDIA GPU에서 다양한 배포 시나리오에서 versatility를 보여줌.
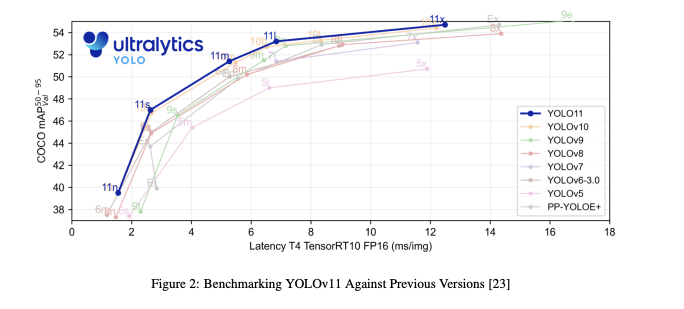
위 성능 그래프를 보면 모든 YOLOv11 버전에서 모든 이전 YOLO 버전을 능가한 것을 알 수 있다.
Conclusion
- YOLOv11 아키텍처는 정확도와 처리 속도에서 두드러진 향상을 보여주었고, 필요한 파라미터 수를 줄였다.
- C3k2 블록과 C2PSA의 도입으로 특징 추출 능력과 효율성을 강화시켰다.
블록의 디테일한 figure가 없어서 아쉬웠지만, YOLOv11의 전반적인 구조와 핵심 모듈에 대해서는 간략하게 알 수 있었습니다. 깃허브를 살펴보니 페이퍼로 쓸 계획이 아직까진 없다고 언급한거보면,,,깃허브 레포 이슈에서 다른분이 정리한 figure를 보거나 직접 코드를 뜯어서 모듈의 구조를 이해하는게 더 빠를 것 같아 보입니다.
