[Object Tracking] SAMURAI: Adapting Segment Anything Model for Zero-Shot Visual Tracking with Motion-Aware Memory 리뷰
Object Detection
논문 제목
SAMURAI: Adapting Segment Anything Model for Zero-Shot Visual Tracking with Motion-Aware Memory
URL: https://arxiv.org/abs/2411.11922
인용수 : 1회 (24.12.04 기준)
Github : https://github.com/yangchris11/samurai
요약
- Segment Anything Model 2(SAM 2는 Segmentation Task에서 좋은 성능을 보였지만, 빠르게 움직이거나 가려지는 객체를 다루는 장면에서는 object tracking이 어렵다고 한다.
- 기존 모델에서 사용한 fixed-window memory 방식은 다음 프레임의 이미지 특징을 조절하기 위해 선택한 memory quality를 고려하지 않아 동영상에서 error propagation를 초래한다.
- 이 논문에서는 SAM 2를 visual object tracking에 특화된 형태로 개선한 SAMURAI를 제안.
- SAMURAI에서는 memory selection mechanism을 도입하여 재학습이나 finetuning 없이도 좋은 성능을 낸다고함.
- SAMURI는 실시간으로 동작, 다양한 벤치마크 데이터셋에서 강력한 zero-shot 성능을 보여줌.
Introduction
- SAM 2는 Video Object Segmentation(VOS) Task에서는 좋은 성능을 보였지만, Visual Object Tracking(VOT)에서는 어려움이 있음.
- VOT에서 주요 문제는 가림, 외형변화, 유사한 객체 존재에도 객체의 identity와 위치를 유지해야함.
- 하지만 SAM 2에서는 후속 프레임에서 mask를 예측할 때 motion cues를 종종 무시하여 빠른 객체 이동이나 복잡한 상호작용이 있는 상황에서는 성능이 좋지 않음.
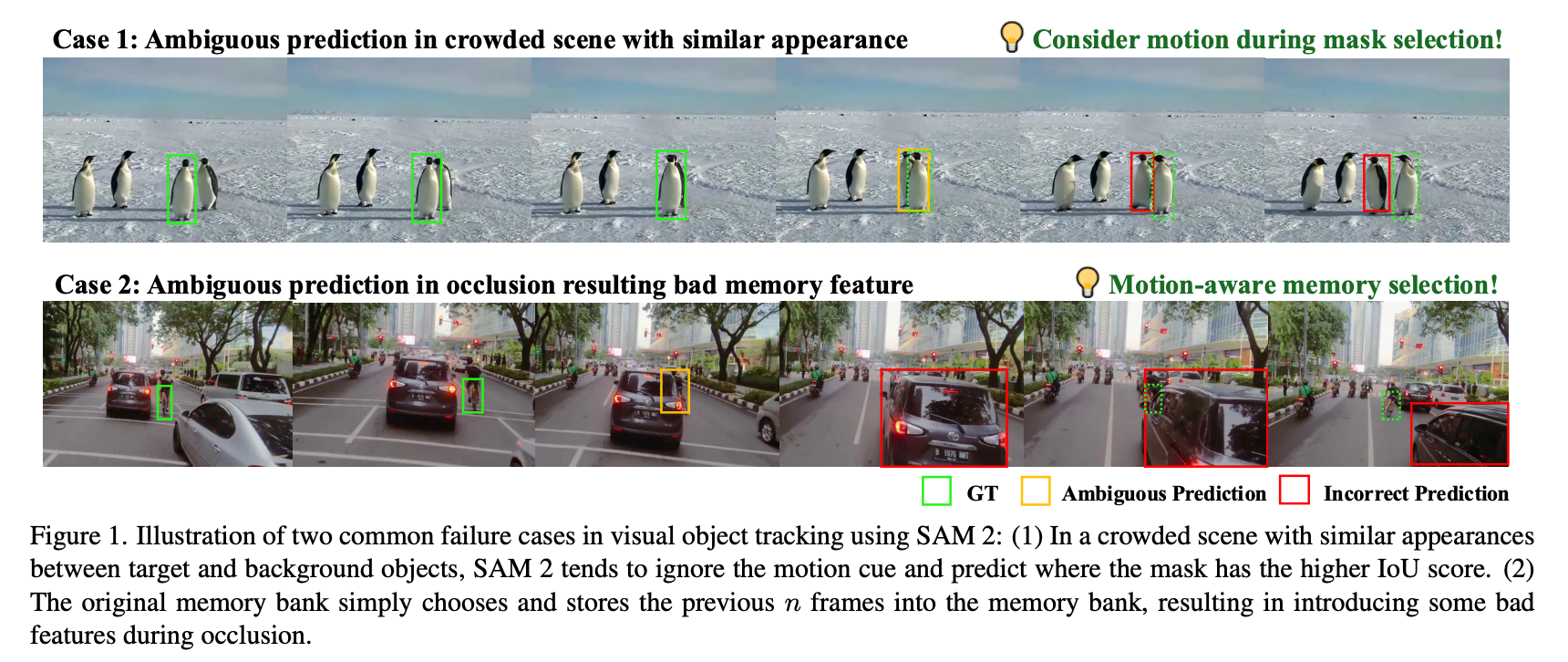
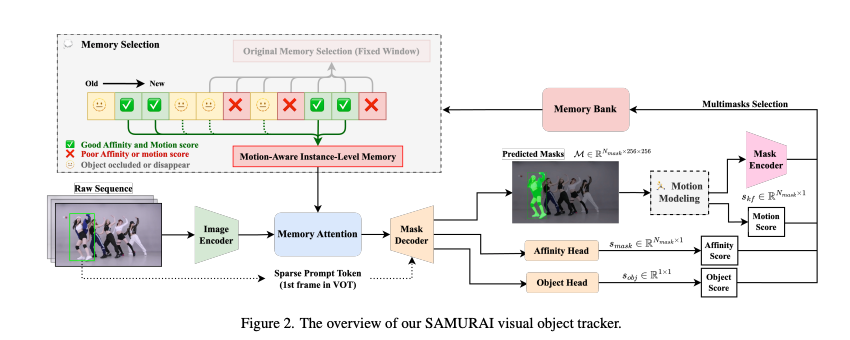
Figure 1는 SAM 2의 두 가지 실패 케이스를 보여준다.
Case 1: 혼잡한 장면에서의 모호한 예측
펭귄들 중 목표로 설정된 객체(녹색 박스)가 있음에도 불구하고, SAM 2는 다른 객체(빨간 박스)를 잘못 추적하고 있다.
Case 2: 가림(occlusion)으로 인해 발생하는 모호한 예측
차량이 다른 차량에 의해 부분적으로 가려지면서 SAM 2는 객체를 정확히 추적하지 못하고 잘못된 마스크(노란색 박스)를 생성하고 있다.
이러한 한계점을 극복한 것이 SAMURAI라고 한다.
SAMURAI의 풀네임은 다음과 같다.
SAMURAI = A SAM-based Unified and Robust zero-shot visual tracker with motion Aware Instance-level memory
이 모델은 두 가지 개선사항을 포함한다고 한다.
- motion modeling system - mask selection을 정제하여 복잡한 시나리오에서도 더 정확한 객체 위치 예측.
- optimized memory selection mechanism - mask affinity, object score, motion score를 결합한 하이브리드 점수 시스템 활용.
이러한 설계를 통해 모델의 contribution은 다음과 같다.
- SAM 2의 visual tracking accuruacy를 개선하기 위해 motion modeling를 통합하여 빠르게 이동하거나 가려지는 객체를 효과적으로 처리
- 혼잡한 장면에서의 오류를 줄이고 추적 신뢰성을 높이기 위해, motion과 affinity scores를 혼합하여 관련 프레임을 선택적으로 저장하는 motion-aware memory selection 메커니즘을 제안하여 에러를 줄임
- 추가적인 학습이나 finetuning 없이, LaSOT, GOT-10k, 등의 주요 벤치마크 데이터셋에서 기존의 SOTA 모델보다 뛰어난 일반화 성능을 보여줌
Method
SAM 2는 기본적인 시각 Visual Object Tracking(VOT) 및 Video Object Segmentation(VOS) 작업에서 우수한 성능을 보였다.
하지만 original model은 부정확하거나 신뢰도가 낮은 객체를 잘못 인코딩할 가능성이 있어, 긴 시퀀스의 VOT 작업에서 substantial error propagation를 초래할 수 있다.
이를 해결하기 위해 두 가지 방법을 제안했다고 한다.
- multi-masks selection -> Kalman 필터를 기반 motion modeling
- hybrid scoring system that combines affinity and motion scores -> enhanced memory selection
두 방법을 통해 복잡한 비디오 시나리오에서 객체를 정확하게 추적하는 능력 강화.
Motion Modeling
Motion modeling은 VOT와 MOT에서 association ambiguities을 해결하기 위한 효과적인 접근방식임.
이 VOT 프레임워크에서 Kalman 필터를 통합하여 바운딩 박스의 위치와 크기 예측을 향상했다고한다.
N개의 후보 마스크 집합 중에서 가장 신뢰할 수 있는 마스크를 선택하는데 도움을 준다고 한다.
상태 벡터 는 아래와 같이 정의된다.
여기서 x,y는 바운딩 박스 중심의 좌표를 나타내고, w,h는 너비와 높이를 나타낸다.
각 항목의 속도는 dot notation로 표시했다.
각 마스크 에 대한 바운딩 박스 는 마스크의 non-zero pixels의 최소와 최대 x,y좌표를 계산하여 나타낸다.
Kalman 필터는 predict-correct cycle에서 작동하고, 상태 벡터 는 아래 수식과 같이 예측함.
여기서 는 linear state transition matrix이다.
Kalman 필터의 KF-IoU 점수 는 칼만 필터의 예측된 상태와 마스크간의 IoU로 계산된다.
그러면 우리는 KF-IoU 점수와 original affinity 점수의 가중합을 최대화하는 마스크를 선택하면된다.
마지막으로 상태는 아래 식으로 업데이트 된다.
여기서 는 선택한 마스크로부터 나온 바운딩 박스 측정값이고, 는 Kalman gain, 는 observation matrix이다.
Motion-Aware Memory Selection
Original SAM 2는 conditioned visual feature를 준비하기 위해서 이전 프레임 중 개를 선택해서 사용한다.
하지만 이 접근법은 VOT에서 흔히 발생하는 longer occlusion과 deformation을 처리하기엔 약점이 있다.
이를 해결하기 위해 이전 시점의 프레임을 선택할 때, 세 가지 점수를 기반으로 한 선택 방식을 사용했다.
1. Mask Affinity Score ()
2. Object Occurrence Score ()
3. Motion Score ()
각 점수가 사전에 정의된 Thresholds (,,)을 충족하는 경우에만 프레임을 ideal candidate for memory로 선택한다.
현재 프레임에서 이전 프레임으로 돌아가면서 위의 방법을 반복적으로 검증하고, 개의 메모리를 선택하여 motion-aware memory bank 를 생성한다.
= 이전을 되돌아볼 수 있는 최대 프레임수
motion-aware memory bank 는 memory attention layer를 거쳐 마스크 디코더 로 전달되며, 현재 시점에서 마스크 디코딩을 수행한다.
SAM 2가 특정 메모리 뱅크 설정 ()에서 훈련되었기 때문에 해당 설정을 본 논문에서도 유지했다.
제안된 motion modeling & memory selection module은 추가 학습 필요없이 VOT 성능을 크게 향상시킬 수 있고, 기존 파이프라인에 computational overhead를 추가하지 않는다. 이 모듈은 model-agnostic해서 SAM 2 이외 다른 tracking framework에도 적용될 수 있다고 한다.
Experiments
SAMURAI 모델은 LaSOT, , GOT-10k, TrackingNet, NFS, OTB100 벤치마크 데이터셋에서 평가를 진행했다.
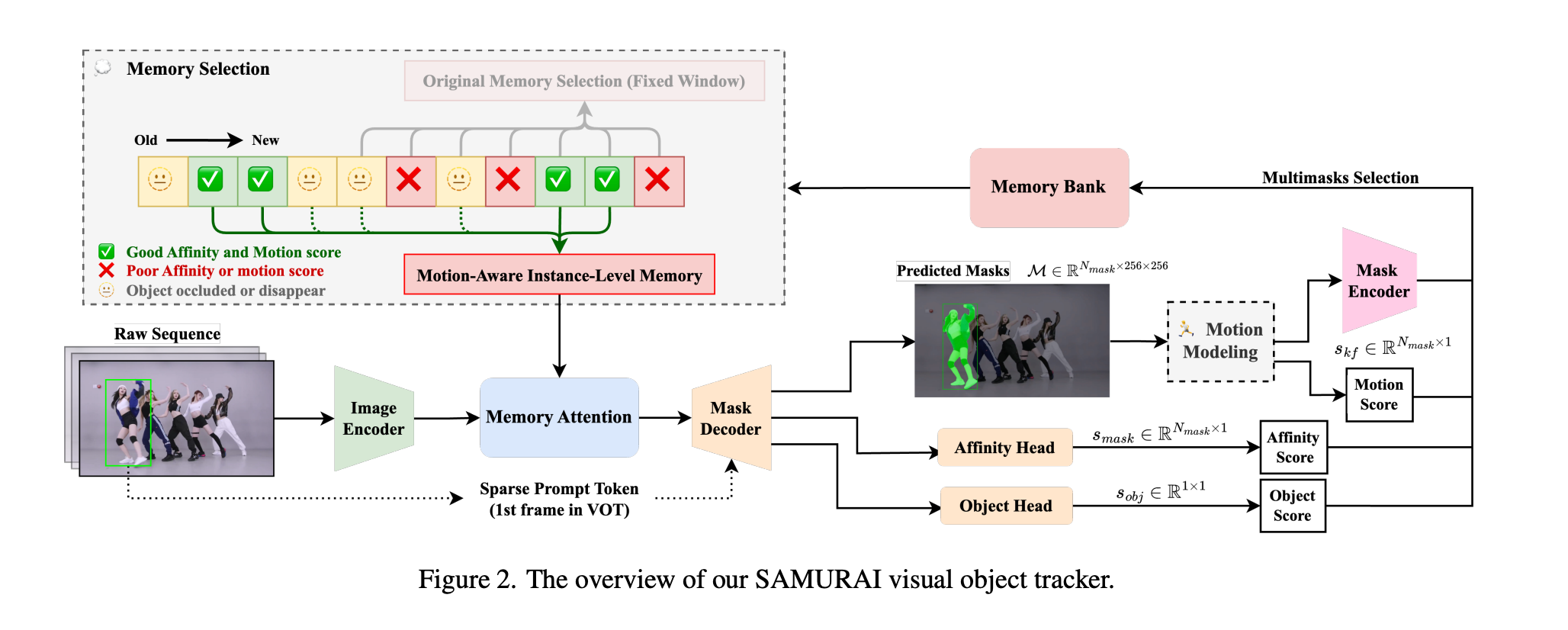
Table1은 LaSOT, 데이터셋에서 tracking 결과를 나타낸다.
지도학습 기반의 VOT 방법도 좋은 결과를 보여줬지만, zero-shot SAMURAI 또한 뛰어난 일반화 성능을 보였다.
모든 SAMURAI모델은 데이터셋에서 SOTA를 달성했다.
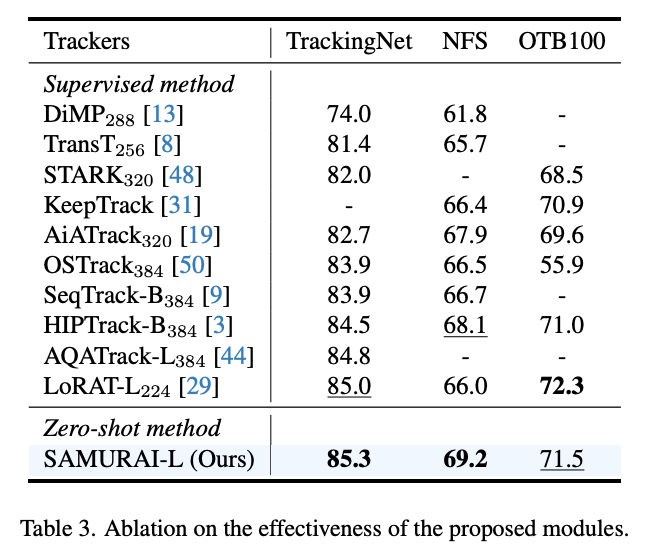
TrackingNet, NFS, OTB100에서도 zero-shot SAMURAI-L 모델은 AUC에서 최신 지도 학습 방법과 비슷하거나 이를 초과하는 성능을 보였고, 다양한 데이터셋에 대한 모델의 능력과 일반화 성능을 입증했다.

정성적인 평가에서도 SAMURAI는 비디오 장면에서 비슷한 외형을 가진 여러 객체가 존재하는 경우 우수한 visual object tracking 결과를 보였다.
기존의 VOT 방법들은 short-term occlusions 상황에서 동일한 객체를 시간에 따라 일관되게 예측하지 못한 케이스들이 보였다.
Conclusion
- SAMURAI 프레임워크는 SAM 기반으로 동작하고, mask prediction과 memory selection을 향상시키기 위해 motion-based score를 도입했다.
- 이를 통해 self-occlusion & abrupt motion in crowded scenes을 처리할 수 있다.
- 제안 방법은 VOT 벤치마크에서 SAM과 SAM 기반 변형 모델보다 향상된 성능을 보였다.
- 이 방법은 retraining이나 finetuning이 필요하지 않고, real-time online inference가 가능하다.
