[논문스터디] KPConv: Flexible and Deformable Convolution for Point Clouds
ClassificationPoint Cloudlidat classificationlidat semantic segmentationpoint cloud encodersegmentationsemantic논문스터디라이다분류세그멘테이션인코더포인트클라우드
Study
목록 보기
4/8
Bibtex 인용
@InProceedings{Thomas_2019_ICCV,
author = {Thomas, Hugues and Qi, Charles R. and Deschaud, Jean-Emmanuel and Marcotegui, Beatriz and Goulette, Francois and Guibas, Leonidas J.},
title = {KPConv: Flexible and Deformable Convolution for Point Clouds},
booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)},
month = {October},
year = {2019}
}요약
- intermediate representation이 없는 kernel point convolution을 제안
- convolution weight는 유클리드 공간에서 kernel point로 위치가 지정
- kernel point 변경 가능 → 유연성 제공
- local grometry에 kernel point를 adapt하기 위해 deformable convolution으로 확장 가능
- 규칙적인 sub-sampling을 통해 밀도에 대해서 robust, efficient
- SOTA임
인트로
- discrete convolution에서는 효율적인 계산 가능 but 공간에서는 불가능
- 비정형 데이터(non-grid) like 3d point cloud같은 데이터 사용하는 application 증가
- 포인트 클라우드는 순서도 없고 그리드랑 다르고 spatially localized되어있음
- 이러한 데이터를 처리하기 위해 여러 방법이 제안되어옴
- MLP이용 직접 처리
- point에 직접 convolution
- KPConv
- local 3D filter로 구성
- kernel pixel이 아닌 point기반 weight 영역 정의
- kernel point의 수에 제한이 없음 → 설계가 유연함
- deformable
- 각 convolution location에 대해 다른 shift를 생성
- 입력 포인트 클라우드에 대해서 kernel을 adapt한다는 의미임
- 각 convolution location에 대해 다른 shift를 생성
- radius neighborhood 방식 + regular sub-sampling → density에 robust함
기여
- 3d point cloud를 위한 새로운 kernel 제시
- deformable한 kernel제시
- 새로운 네트워크 아키텍쳐 제시
Related Work
- Projection networks
- graph convolution network
- pointwise MLP network
- point convolution network
Kernel Point Convolution
A Kernel Function Defined by Point
- KPConv는 local 3d filter로 구성
- kernel point를 사용하여 kernel의 weight 영역을 정의
- 포인트의 수에 제한이 없어 flexible한 설계 가능
- 밀도가 다른 데이터 처리시 robust
- 일반적 point kernel 함수는 아래와 같음
- - neighbor point of
- - point in radius
- 일관된 구형 영역을 갖는 것이 네트워크 학습에 의미있다 생각함
- point를 이용해서 3D Space에서 area를 어떻게 정의
- 가장 intuitive
- localized feature
- kernel function for any point ← this paper propose
- g(y_i) = \sum_{k < K} h(y_i, \~x_{k}) W_k
- h(y_i, \~x_{k}) = \max \left( 0, 1 - \frac{\|y_i - \~x_{k}\|}{\sigma} \right)
- 는 influence distance of kernel point인데, input density에 따라 결정됨
- 가우시안 correlation이 아니라 선형 correlation사용해서 심플하고 back-propagation이 쉬움
Rigid or Deformable Kernel
-
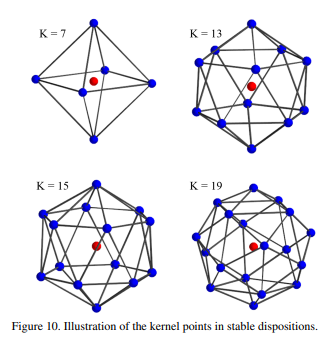
각 점이 다른 점에 repulsive한 force를 가지는 최적의 위치로 kernel point 배치
-
sphere안에 있고 atrractive force를 가지는 점들로 제한을 두고 한개의 점은 center에 위치해야함
-
모든 점들은 평균 반지름이 가 되도록 re-scale
- other kernel들과 small overlap을 ensure
- space coverage를 보장
-
K가 충분히 커서 g의 area를 커버가능할 경우 좋음
-
kernel point position을 학습시켜서 효율성을 확장시킬수도있음
-
가 \~x_k 에 대해 미분가능하므로 학습가능한 매개변수임
-
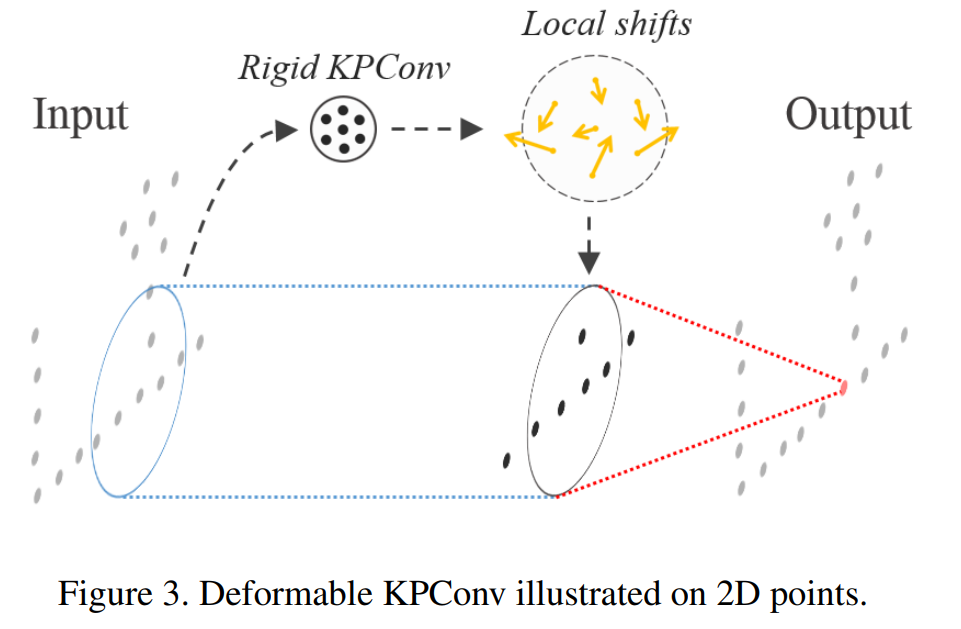
deformable KPConv는 아래와 같은 g를 가짐
-
local shift는 rigid KPConv가 입력 feature를 3K로 매핑하는 의 출력으로 정의됨
-
global nerwork의 lr의 0.1로 학습
- rigid kernel → shift
- deformable kernel → output
-
image convolution 에서 derive된 이런 방식을 사용하면, kernel point가 input point와 멀어지는 방향으로 학습될 수 있음
- 이러면 네트워크에서 소실됨 bcz. shift의 gradient가 influence range안에 없으면 null 이 됨
- fitting regularization loss를 제안함
-
regularization loss
-
fitting loss는 kernel point와 그 점의 가장 가까운 점과의 거리에 대한 loss
-
repulsive loss는 kernel들 사이에 overlap에 대한 loss → 완전히 겹치지 않도록

-
잘되는거 봐라 ㅇㅇ
Kernel Point Network Layers
- Subsampling to deal with varying densities
- grid subsampling → 위치에 대한 일관성 보장
- 각 non-empty한 cell에 대해서 질량 중심이 되는 위치를 feature의 location으로 사용
- Pooling Layer
- 이미 그리드 기반으로 subsampling했으니까 그냥 그리드 크기를 두배씩 키워가면서 pooling layer구성함
- 새로운 위치에 대한 feature는 max pooling혹은 KPConv를 활용하여 얻음
- 여기에서는 KPConv를 활용하여 얻고 이거를 stride KPConv라 부름
- KPConv layer
- convolution 층의 입력
- point, feature, matrix of neighbourhood indices
- matrix of neighborhood size는 가장 큰거 따라감
- 안쓰이는 애들 포함되는데 convolution 계산에서는 무시됨
- convolution 층의 입력
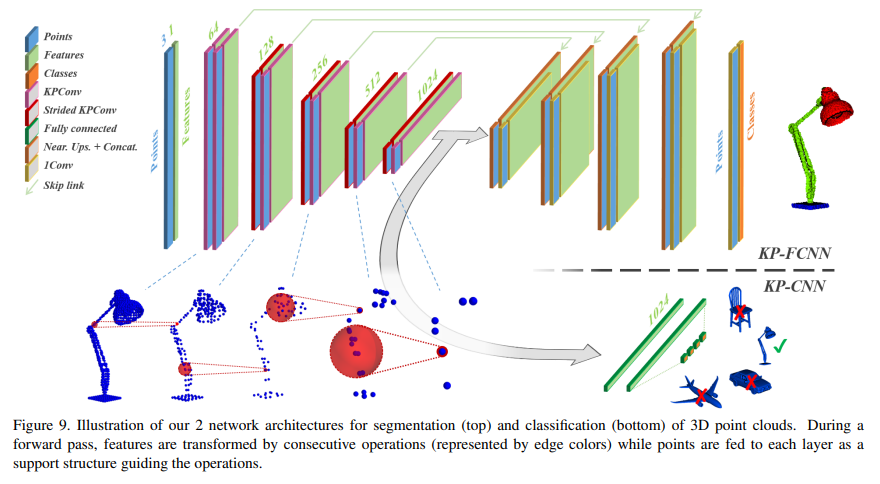
Kernel Point Network Architecture
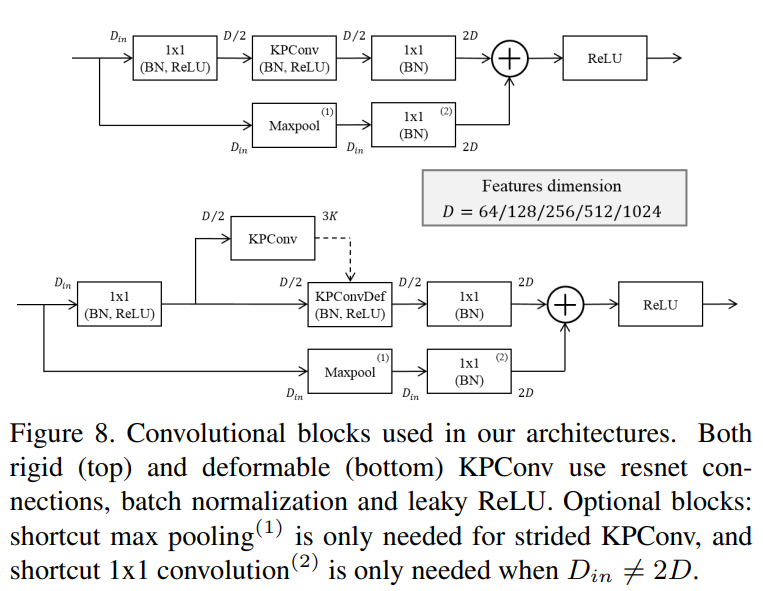
-
empirically 두개로 만듬 → classification and segmentation
-
KP-CNN
- 5 layer classification convolution network
- 각 layer 에 2 conv layer
- resnet처럼 디자인됐다
- image convolution대신 batch norm and leaky ReLu를 사용했다
- last layerdㅔ서는 global average pooling으로 feature aggregation을 하고 fully connected layer랑 softmax로 처리
- deformable KPConv에서는 마지막 5개 KPConv에 대해서만 deformable사용
-
KP-FCNN
- fully convolution layer for segmentation
- encoder는 위랑 같음
- decoder는 nearest upsampling을 사용
- skip connection으로 encoder decoder사이 연결 있음
- unary convolution을 활용해서 feature concatenate
- nearest upsampling을 KPConv로 대체해도 되지만 성능에 별차이없음

Studying