[Paper Review] An Image Is Worth 16x16 Words : Transformers for Image Recognition at Scale (Vision Transformer)

선정 이유
안녕하세요! 오늘 논문리뷰, 코드리뷰해볼 논문은 "An Image Is Worth 16x16 Words: Transformers for Image Recognition at Scale" 로, 컴퓨터 비전에서 Transformer와 Attention이 쓰이게 된 결정적 계기(?)가 된 논문입니다. 최근 이쪽 분야에 관심이 많다 보니 오늘은 이 논문을 리뷰하게 되었습니다.
논문리뷰
Background
(Self) Attention
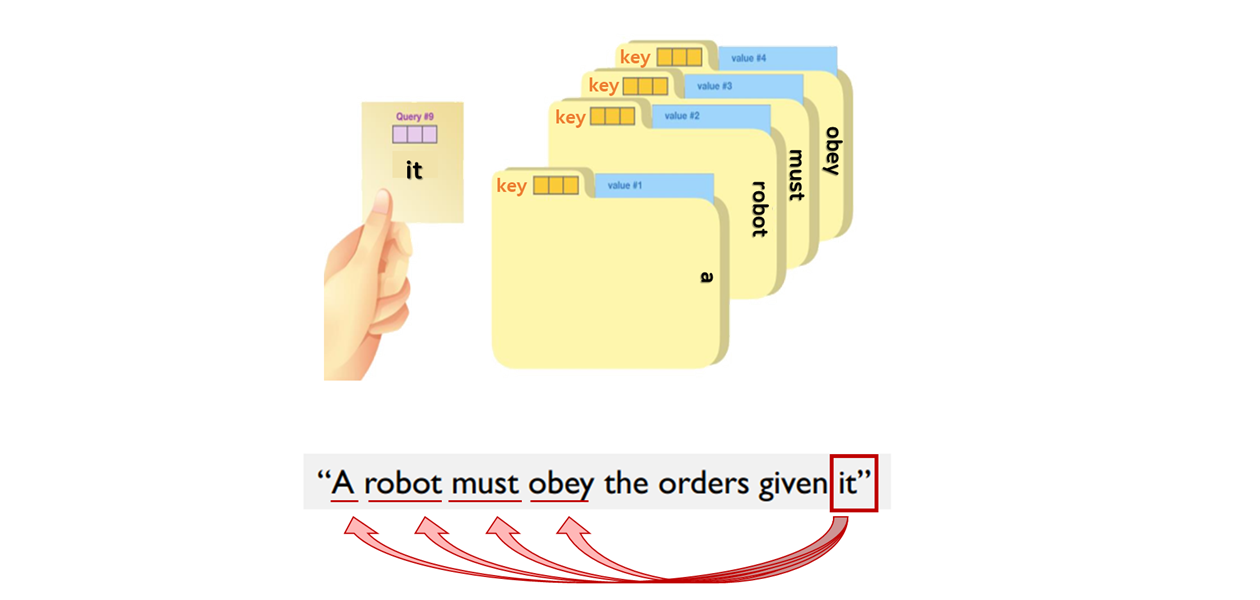
- Attention의 기본 아이디어는 디코더에서 출력 단어를 예측하는 매 시점(time step)마다, 인코더에서의 전체 입력 문장을 다시 한 번 참고합니다.
- 단, 전체 입력 문장을 전부 다 동일한 비율로 참고하는 것이 아니라, 해당 시점에서 예측해야 할 단어와 연관이 있는 입력 단어 부분을 좀 더 집중(attention)해서 보게 됩니다.
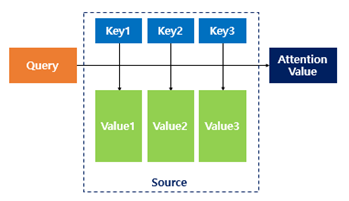
- 주어진 '쿼리(Query)'에 대해서 모든 '키(Key)'와의 유사도를 각각 구합니다. - 그리고 구해낸 유사도를 가중치로 하여 키와 맵핑되어 있는 각각의 '값(Value)'에 반영합니다. 그리고 유사도가 반영된 '값(Value)'을 모두 가중합하여 리턴하게 됩니다.
- '쿼리(Query)', '키(Key)', '값(Value)'의 정의는 영어로 다음과 같습니다.

Transformer
-
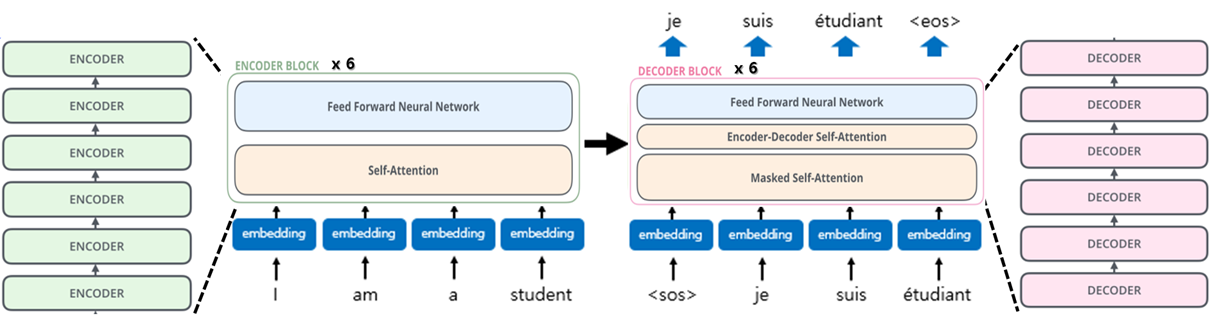
기존 RNN 기반 seq2seq 모델에서는 이전 시점의 연산이 끝나기 전에는 다음 시점의 연산이 불가능하여 병렬화(parallelize) 된 연산처리가 불가능했습니다.
-
RNN구조는 고질적 문제인 Long-term dependency 문제가 발생하였고, 이는 곧 타임 스텝(time step)이 길어질 수록 시퀀스 처리의 성능이 떨어짐을 의미합니다.
-
이러한 문제점들을 보완하기 위해 Attention만으로 Encoder, Decoder 구조를 만들어 시퀀스를 처리하는 모델을 제안함으로써 학습 속도가 매우 빠르며 성능도 우수한 Transformer가 제안되었습니다.
- 뿐만 아니라 여러개의 Head를 사용하는 Multi-head Attention을 통해 다양한 aspect에 대해서 모델이 학습할 수 있도록 하였습니다.
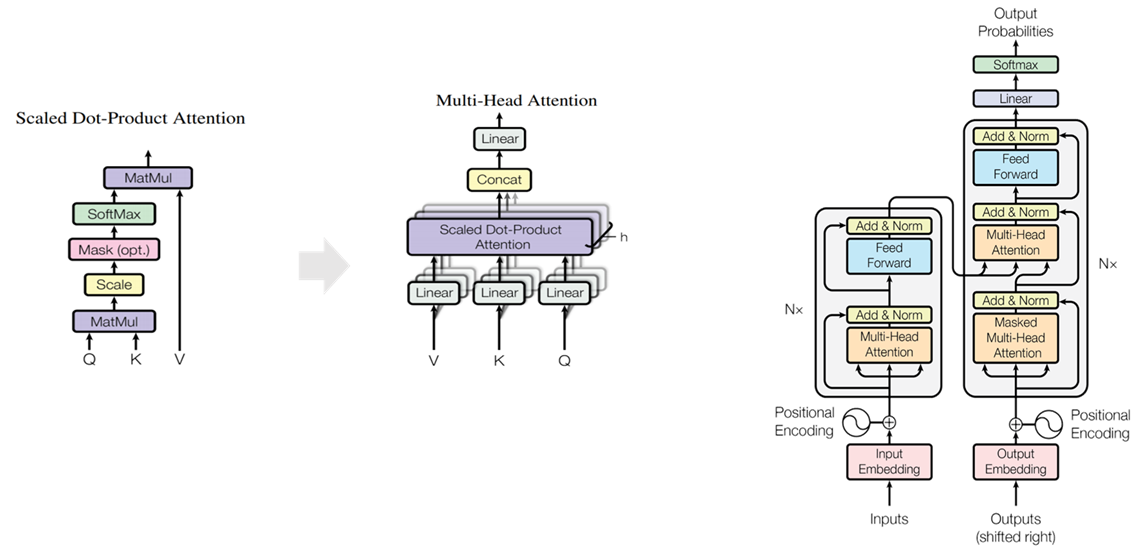
Image Recognition (Classification)
-
Image Recognition (Classification)은 이미지를 알고리즘에 입력(input)해주면, 그 이미지가 속하는 class lable을 출력(output)해주는 task를 의미합니다.
-
아래 그림 처럼 고양이 사진을 넣어주면 고양이 라고 인식(분류)해냅니다.
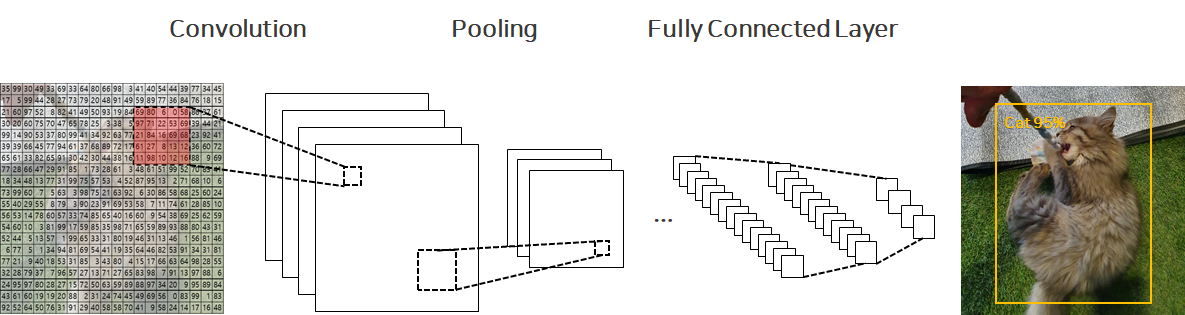
-
위에 그림처럼 여지껏 CV(Computer Vision) 도메인에서는 CNN(Convolutional Neural Network)를 사용한 모델들이 많이 사용되어 오고 있었습니다. (Ex. ResNet, UNet, EfficientNet 등)
-
하지만, NLP(Natural Language Processing) 도메인에서의 Self-Attention과 Transformer의 성장으로 인해 CNN과 Attention을 함께 이용하려는 추세가 증가하고 있습니다. 본 논문(연구) 역시 그러한 시도 중 하나입니다.
Vision Transformer
- Vision Transformer의 개념은 Transformer가 어떻게 작동하는지 아는 사람들이라면 쉽게 접근할 수 있습니다. 아래 그림이 솔직히 본 논문에 전부이기 때문이죠.
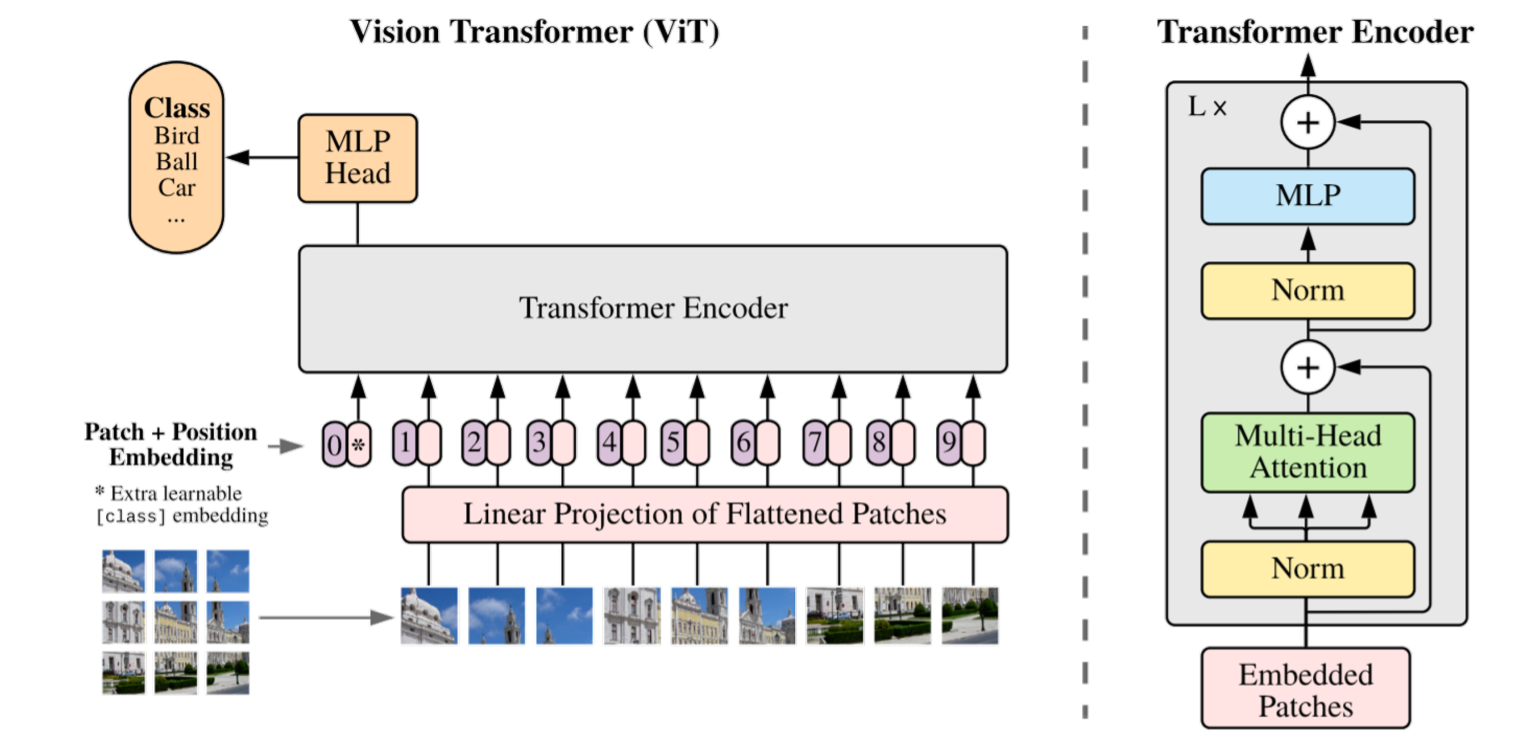
- Vision Transformer는 image recognition task에 있어서 Convolution을 아예 없애고, Transformer Encoder만을 사용하였습니다.
(추기) 아래 ViT 시각화 자료가 매우 유익해서 글 본문에 추가했습니다.
https://blog.mdturp.ch/posts/2024-04-05-visual_guide_to_vision_transformer.html?utm_source=pytorchkr&ref=pytorchkr
각각의 순서는 아래와 같습니다.
0. Prerequisites
- 필요 라이브러리 IMPORT
import torch
import torch.nn as nn
from torch import Tensor
from torchsummary import summary
import torch.optim as optim
from torch.optim import lr_scheduler
import torchvision.datasets as dset
import torchvision.transforms as T
from torchvision.transforms import Compose, Resize, ToTensor
from torch.utils.data import DataLoader
from torch.utils.data import sampler
import numpy as np
import os
import copy
import cv2
import matplotlib.pyplot as plt
from tqdm import tqdm
%pip install einops
from einops import rearrange, repeat, reduce
from einops.layers.torch import Rearrange, Reduce
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
dtype = torch.long- Define Helper Function
def pair(t):
return t if isinstance(t, tuple) else (t, t)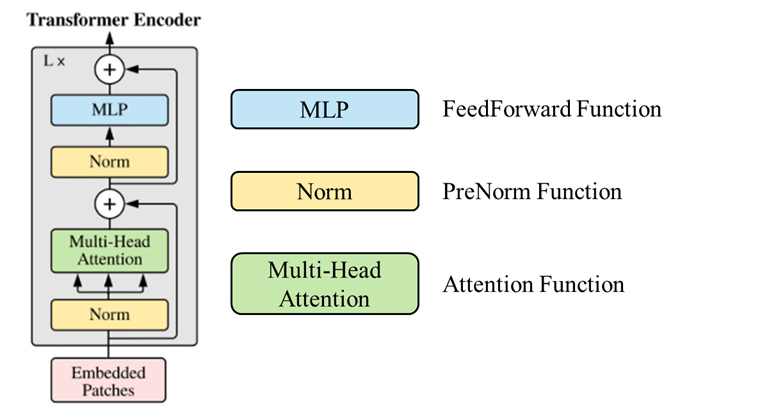
- Define
PreNormClass
# Define PreNorm
class PreNorm(nn.Module):
def __init__(self, dim, fn):
super().__init__()
self.norm = nn.LayerNorm(dim)
self.fn = fn
def forward(self, x, **kwargs):
return self.fn(self.norm(x), **kwargs)- Define
FeedForwardClass
# Define FeedForward
class FeedForward(nn.Module):
def __init__(self, dim, hidden_dim, dropout = 0.):
super().__init__()
self.net = nn.Sequential(
nn.Linear(dim, hidden_dim),
nn.GELU(),
nn.Dropout(dropout),
nn.Linear(hidden_dim, dim),
nn.Dropout(dropout)
)
def forward(self, x):
return self.net(x)- Define
AttentionClass
# Define Attention
class Attention(nn.Module):
def __init__(self, dim, heads = 8, dim_head = 64, dropout = 0.):
super().__init__()
inner_dim = dim_head * heads
project_out = not (heads == 1 and dim_head == dim)
self.heads = heads
self.scale = dim_head ** -0.5
self.attend = nn.Softmax(dim = -1)
self.to_qkv = nn.Linear(dim, inner_dim * 3, bias = False)
self.to_out = nn.Sequential(
nn.Linear(inner_dim, dim),
nn.Dropout(dropout)
) if project_out else nn.Identity()
def forward(self, x):
b, n, _, h = *x.shape, self.heads
qkv = self.to_qkv(x).chunk(3, dim = -1)
q, k, v = map(lambda t: rearrange(t, 'b n (h d) -> b h n d', h = h), qkv)
dots = einsum('b h i d, b h j d -> b h i j', q, k) * self.scale
attn = self.attend(dots)
out = einsum('b h i j, b h j d -> b h i d', attn, v)
out = rearrange(out, 'b h n d -> b n (h d)')
return self.to_out(out)- Define
TransformerClass
# Define Transformer
class Transformer(nn.Module):
def __init__(self, dim, depth, heads, dim_head, mlp_dim, dropout = 0.):
super().__init__()
self.layers = nn.ModuleList([])
for _ in range(depth):
self.layers.append(nn.ModuleList([
PreNorm(dim, Attention(dim, heads = heads, dim_head = dim_head, dropout = dropout)),
PreNorm(dim, FeedForward(dim, mlp_dim, dropout = dropout))
]))
def forward(self, x):
for attn, ff in self.layers:
x = attn(x) + x
x = ff(x) + x
return xSOURCE
all the images are from this awesome blog - blog.mdturp.ch, visual_guide_to_vision_transformer !!
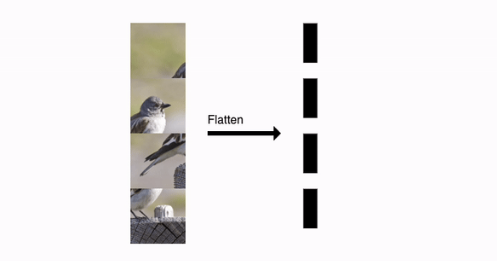
step 1. Splitting Image into fixed-size patches
- 가장 먼저 이미지를 고정된 사이즈의 패치들로 분할하여 모델에 넣어줍니다.
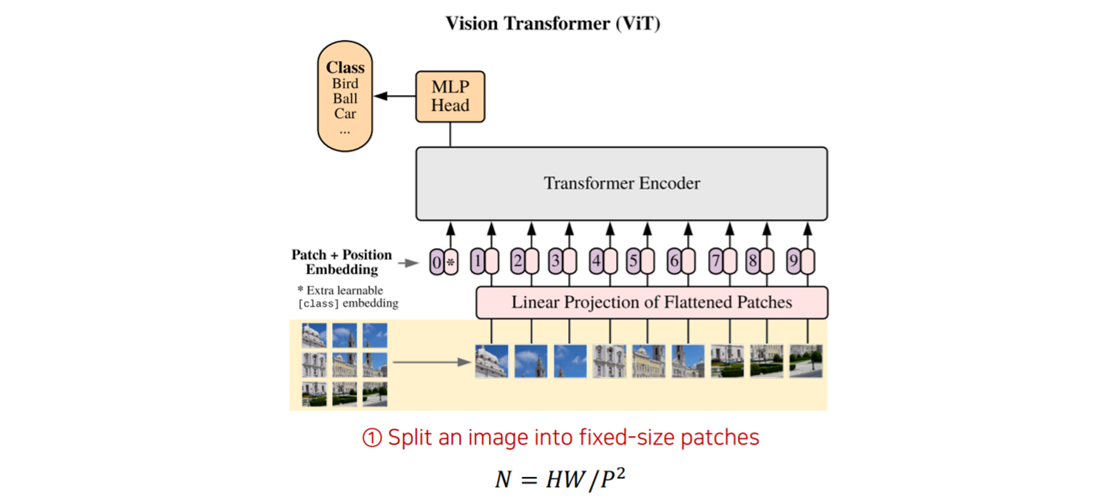

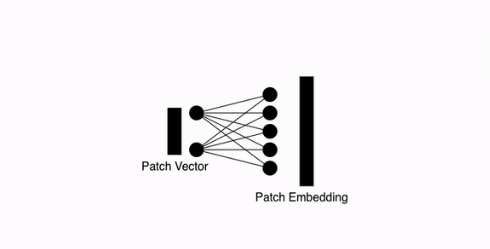
step 2. Linearly embed each patches
- 각각의 이미지 패치들에 대해 Linear Embedding을 수행해줍니다. (D차원으로)
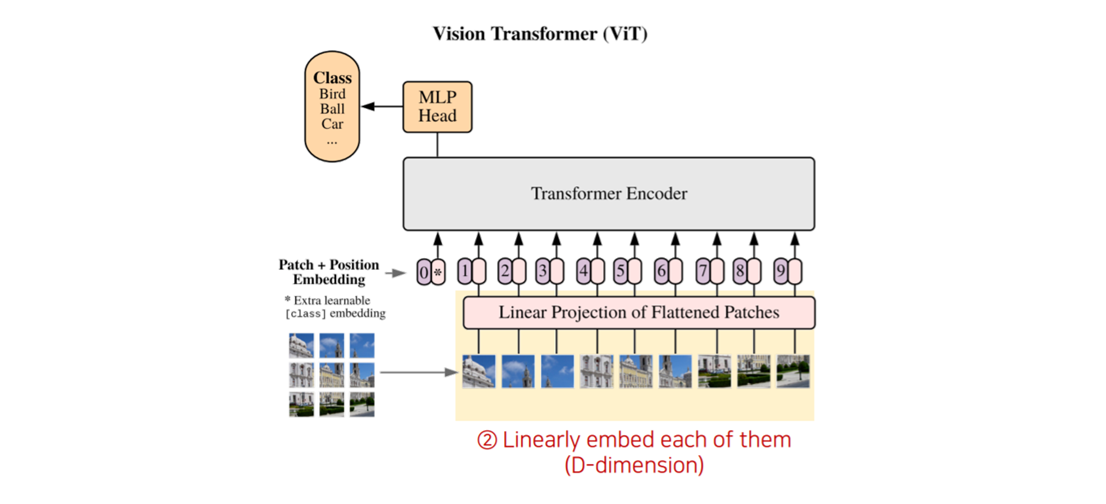

step 3. Add positional embedding
- 이제 각각의 이미지 패치들이 어떤 위치에 있는가에 대한 정보도 모델에 넣어주어야겠죠? 이런 위치에 대한 정보를 우리는 position embedding이라고 하며, 앞에서 구한 Embedding에 붙여주게 됩니다.
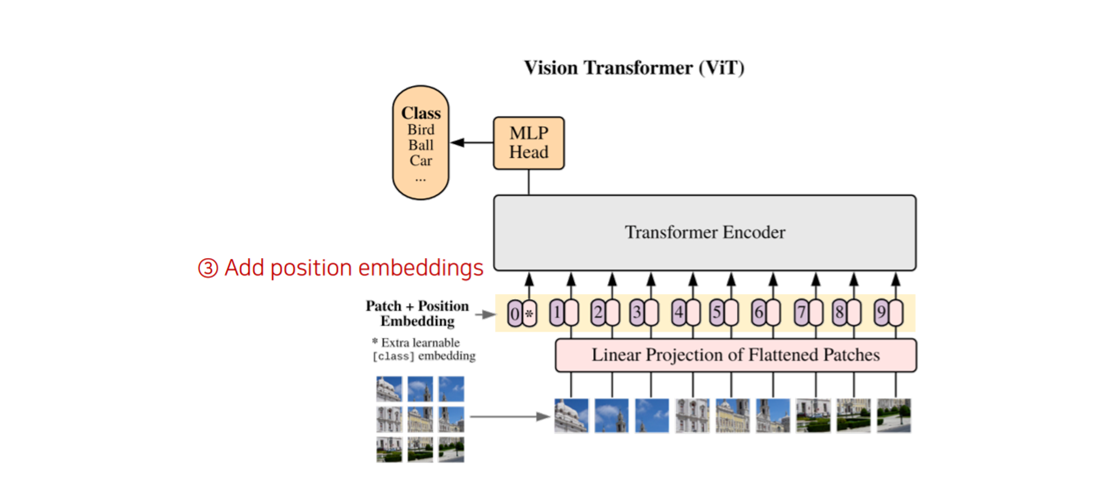
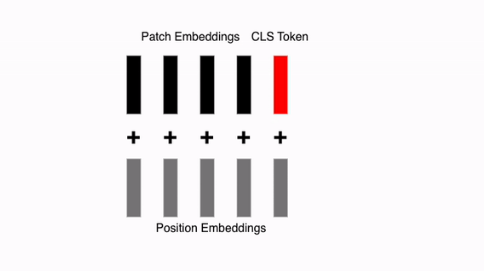
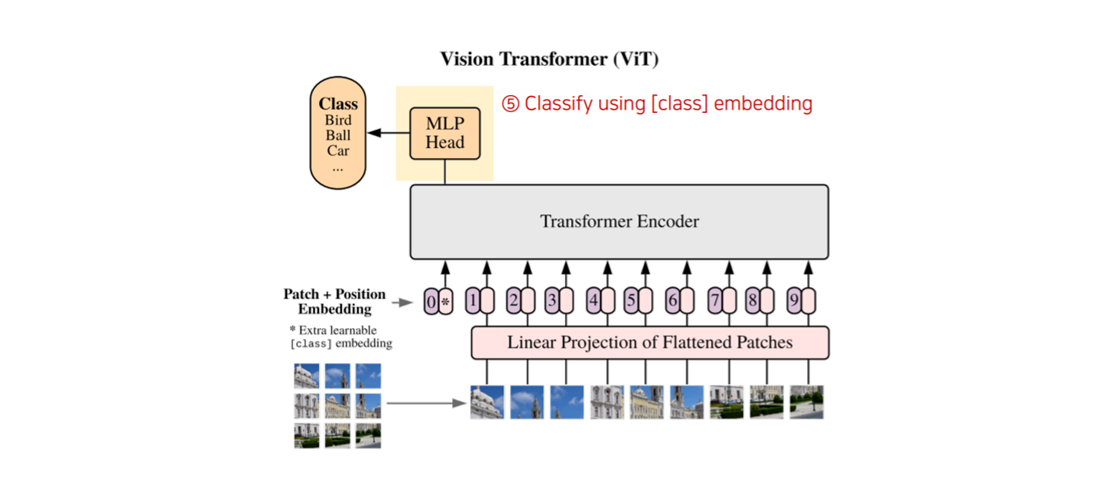
(참고) ViT(Vision Transformer)에서 입력 시퀀스의 구성과 작동 순서는 다음과 같습니다.
1. 입력 시퀀스 구성 순서 (step2)
ViT 모델은 [CLS] 토큰을 이미지 패치 임베딩 시퀀스의 가장 앞에 연결(Concatenate)합니다.
2. 위치 임베딩(Positional Embedding) 적용 (step3)
이후, 위에서 구성된 전체 시퀀스의 각 요소에 위치 임베딩이 더해집니다.
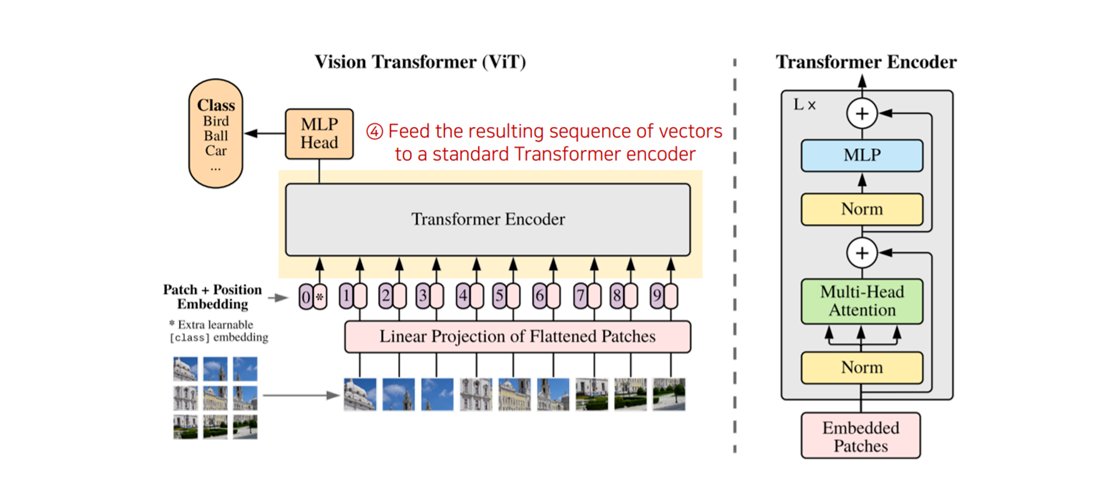
step 4. Feed embedding vector into Transformer Encoder
- 각각의 이미지 패치들에 대한 위치 정보와 임배딩 값을 Transformer Encoder로 넣어줍니다. Transformer Encoder는 아래 그림(우측)과 같이 구성되어 있습니다.
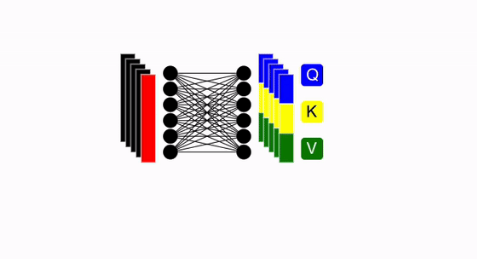
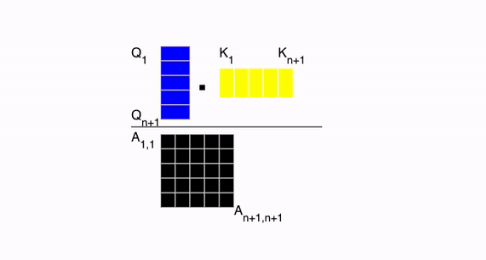
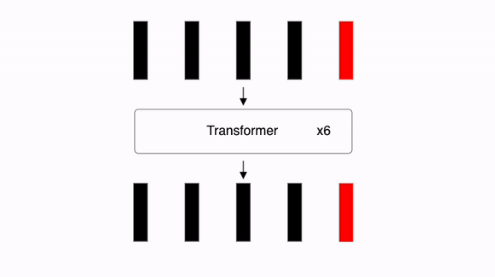
step 5. Use [CLS] token for Classification
- 이미 눈치 채신 분들도 있겠지만, Transformer Encoder에 들어간 각각의 이미지 패치들에 대한 위치 정보와 임배딩 값 외에도 앞에
[0,*]이 있는 것을 확인하실 수 있는 데 이는 전체 이미지의 모든 정보를 담고 있는 토큰이라고 볼 수 있습니다. (A.K.A.[CLS]토큰) 이번 단계에서는 이러한[CLS]토큰을 사용하여 MLP(Multi-layer Perceptron)에 태워 Classificatin을 수행하게 됩니다.
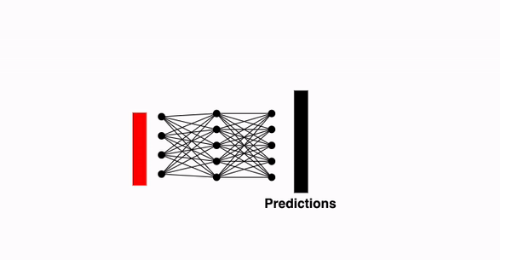
📌 여기서 잠깐!
einops라이브러리?
- Einstein notation 은 복잡한 텐서 연산을 표기하는 방법입니다. 딥러닝에서 쓰이는 많은 연산은 Einstein notation 으로 쉽게 표기할 수 있습니다.
- einops (https://github.com/arogozhnikov/einops)는 pytorch, tensorflow 등 여러 프레임워크를 동시에 지원하는 라이브러리로 이러한 Einstein notation을 사용할 수 있게합니다.
📌 여기서 잠깐!
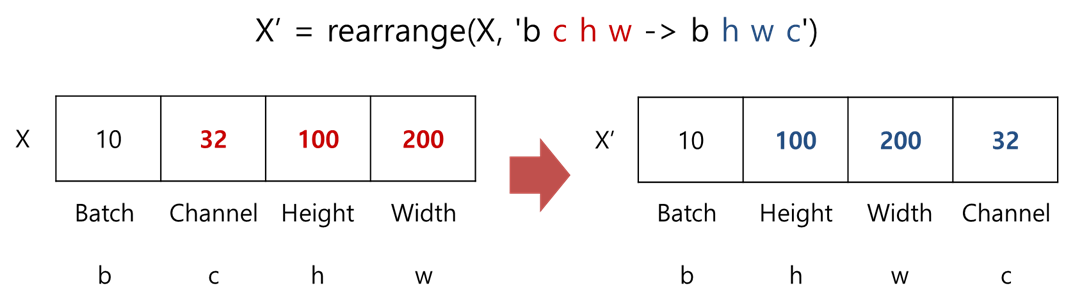
Rearrange함수?
- Rearrange 함수는 shape를 쉽게 변환해주는 함수라고 생각하면 됩니다.
- 밑에 그림으로 어떻게 작동하는지 직관적으로 확인해보시죠!
📌 여기서 잠깐!
einsum함수?
- Einsum 표기법은 특수한 Domain Specific Language를 이용해 이 모든 행렬, 연산을 표기하는 방법입니다.
- 쉽게 말해 우리가 구하고 싶은 행렬 연산을 직관적으로 정의해서 구하게 해주는 함수입니다.
- 몇 가지 예시로 살펴보시죠 (given X(matrix), Y(matrix))
- Transpose :np.einsum("ij->ji", X)
- Matrix sum :np.einsum("ij->", X)
- Matrix row sum :np.einsum("ij->i", X)
- Matrix col sum :np.einsum("ij->j", X)
- Matrix Multiplication :np.einsum('ij,j->i', X, Y)
- Batched Matrix Multiplication :np.einsum('bik,bkj->bij', X, Y)
Vision Transformer 코드
# ViT Class
class ViT(nn.Module):
def __init__(self, *, image_size, patch_size, num_classes, dim, depth, heads, mlp_dim, pool = 'cls', channels = 3, dim_head = 64, dropout = 0., emb_dropout = 0.):
super().__init__() # super()로 기반 클래스의 __init__ 메서드 호출
image_height, image_width = pair(image_size)
patch_height, patch_width = pair(patch_size)
# assert 문 : 뒤의 조건이 True가 아니면 AssertError를 발생
# patch size 조건
assert image_height % patch_height == 0 and image_width % patch_width == 0, 'Image dimensions must be divisible by the patch size.'
num_patches = (image_height // patch_height) * (image_width // patch_width)
patch_dim = channels * patch_height * patch_width
# pooling 조건
assert pool in {'cls', 'mean'}, 'pool type must be either cls (cls token) or mean (mean pooling)'
self.to_patch_embedding = nn.Sequential(
Rearrange('b c (h p1) (w p2) -> b (h w) (p1 p2 c)', p1 = patch_height, p2 = patch_width), # 3 -> 2
nn.Linear(patch_dim, dim), # Linear Projection
)
self.pos_embedding = nn.Parameter(torch.randn(1, num_patches + 1, dim)) # position embedding 초기화
self.cls_token = nn.Parameter(torch.randn(1, 1, dim)) # [CLS] 토큰 초기화
self.dropout = nn.Dropout(emb_dropout) # Dropout 정의
self.transformer = Transformer(dim, depth, heads, dim_head, mlp_dim, dropout) # Transformer 선언
self.pool = pool
self.to_latent = nn.Identity() # 랜덤성 제거
self.mlp_head = nn.Sequential(
nn.LayerNorm(dim),
nn.Linear(dim, num_classes)
)
def forward(self, img):
x = self.to_patch_embedding(img)
b, n, _ = x.shape
cls_tokens = repeat(self.cls_token, '() n d -> b n d', b = b)
x = torch.cat((cls_tokens, x), dim=1)
x += self.pos_embedding[:, :(n + 1)]
x = self.dropout(x)
x = self.transformer(x)
x = x.mean(dim = 1) if self.pool == 'mean' else x[:, 0]
x = self.to_latent(x)
return self.mlp_head(x)Reference
-
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale, ICLR 2019 - Alexey Dosovitskiy et. al.
-
딥 러닝을 이용한 자연어 처리 입문 - 유원준 외 1인 (https://wikidocs.net/book/2155)
-
The Illustrated Transformer -
Jay Alammar (https://jalammar.github.io/illustrated-transformer) -
ViT Source Code - lucidrains (https://github.com/lucidrains/vit-pytorch/blob/64a2ef6462bde61db4dd8f0887ee71192b273692/vit_pytorch/vit.py)
-
https://discuss.pytorch.kr/t/vision-transformer-a-visual-guide-to-vision-transformers/4158
