#GemmaSprint
gemma-sprint
math with me 라고 이름짓고 수학을 풀이해주는 프로젝트를 하기로 했다.
(intelliJ code with me 에서 영감을 받은 프로젝트명임 ㅋㅋ)
gemma2 2b fine-tuning
GSM8K 데이터셋 사용
추후 더 많은 데이터셋 사용 예정
gemma2-2b 모델을 불러오려면 huggingface 에서 토큰을 발급받아야 한다.
발급받고 토큰을 입력하면 위 처럼 로그인 완료된다.
이제 토크나이저와 모델을 불러오고
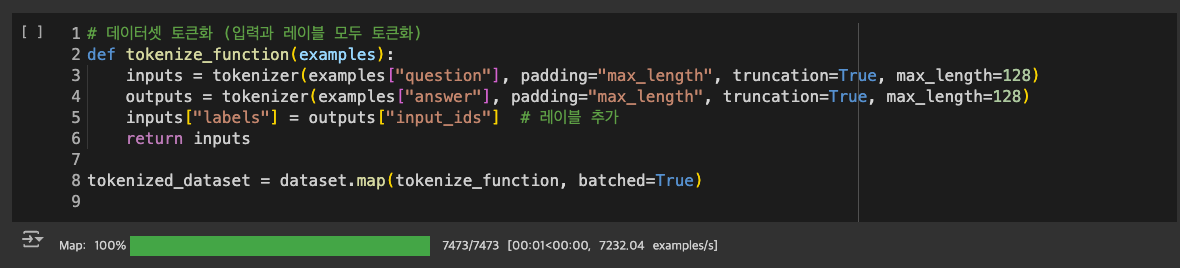
데이터셋을 토큰화 해준다.
모델이 입출력을 이해할 수 있는 형태로 변환해주는 작업이다.
대충 토큰화를 왜 하는지 어떤 이유인지 적어보자면
(일단 텍스트를 숫자 형태인 토큰으로 변환해줌)
(입력이 서로 다른 길이를 가지니까 패딩 작업도 해줘야함)
(모델이 학습할 수 있도록 레이블로 처리해서 입출력 관계를 학습해야함)
나중에 다른 더 자세히 다뤄보겠음
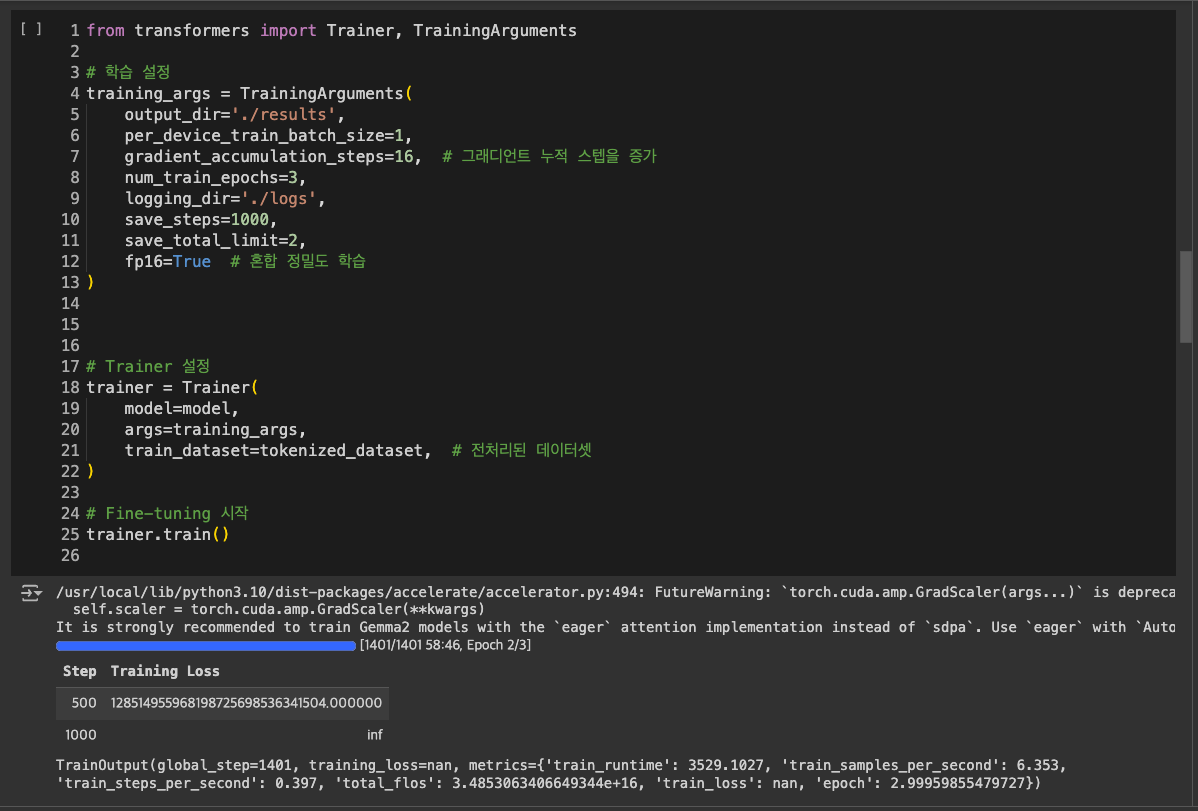
드디어 학습과 관련된 단계
fine tuning 과정을 위한 설정들이 많다.
작은 배치랑 그래디언트 누적으로 GPU를 좀 아껴보려고 했다.
학습 시간이 많이 줄어들었고 효과는 굉장했다~
GPU 가 또 뻗기전에 얼른 모델을 저장하고 업로드 했다.
(사실 colab GPU를 유료로 사용하고 나서는 한번도 뻗은적이 없긴하다. 돈이 좋음)
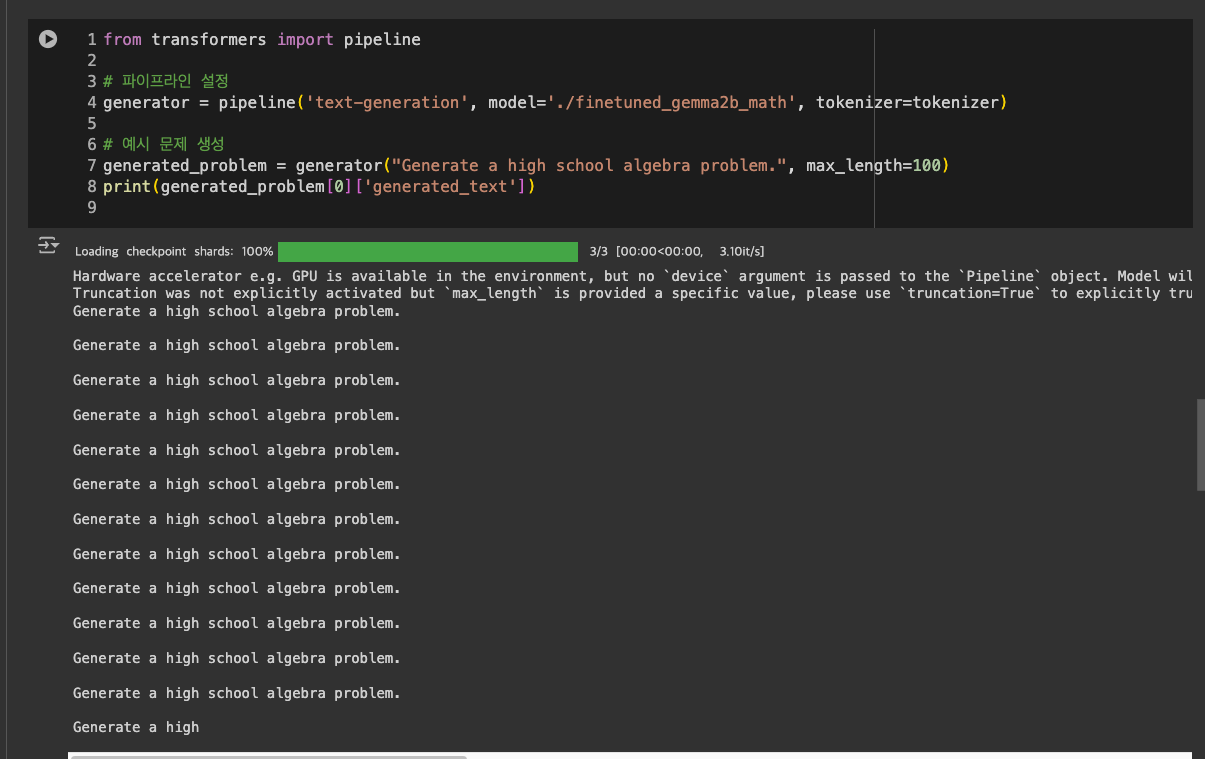
이제 학습시킨 모델을 불러오고, 파이프라인 설정해서 텍스트 처리를 효율적으로 진행해보도록 하자.
근데 내가 적은 프롬프트가 결과로 계속 반복만 되는 것을 볼 수 있다.
내가 고등 문제를 만들어 달라는 명령어가 너무 일반적이고, 일단 문제 조건 파라미터도 설정해 주지 않았어서 출력이 동일한 내용을 반복하는 오류가 생긴 듯 했다.
그리고 학습 데이터를 추가하고 더 세밀한 파인튜닝을 하면 이 격차들이 줄어든다고 한다..
그래서 내가 할 수 있는 부분은
일단 좀 더 구체적인 프롬프트 작성 , 모델 추가 훈련 , 데이터셋 추가 등등.. 할게 많다.
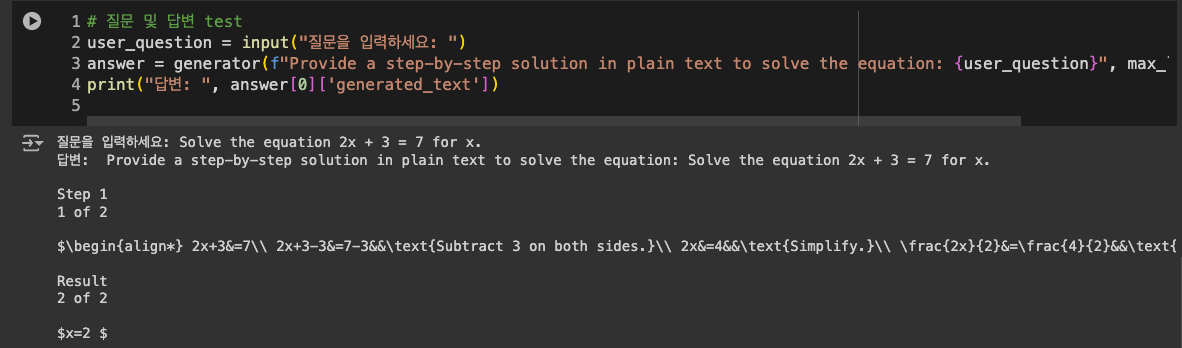
일단 대충 기능 test 를 해봤다.
프롬프트에 내가 질문한 것에 대해서 단계별 설명을 달라고 일단 요청해두었다.
그리고 질문 입력란에 2x + 3 = 7 일때 x 값을 구해달라고 해봤다. (한국어 파인튜닝은 해두지 않아 영문으로만 가능)
답변은 나름 step 별로 잘 해주었는데 결과물에 수식 기호가 그대로 포함되서 출력되니까 사용자 입장에서는 불편하다.
수식을 제거하고 자연어로 변경하는 후처리도 해주어야 한다.
사실 수학 문제 랜덤 생성기를 먼저 만들고 싶었는데, 지속적인 에러 이슈로 일단은 질문을 받아주는 답변 생성기라고 할 수 있겠다 ㅠㅠ
좀 더 시간을 투자해서 더 완성도 높은 프로젝트로 마무리할 예정이다.
