1. Multiclass classification
2개 이상의 class 분류 (multinomial classifiers)
<다중 분류 모델> Random Forest classifier, naive Bayes classifier
<이진 분류 모델> Support Vector Machine classifier, Linear classifier(Logistic regression)
1.1 이진 분류기를 여러개 사용한 다중 분류
-
OvR (One-versus-the-Rest) / OvA (One-versus-All)
특정 숫자 하나만 분류하는 숫자별 이진 분류기 10개 훈련
각 분류기의 decision score 중 가장 높은 것을 선택
✔ 대부분의 binary classifier 에서 OvR을 선호함ex. n-detector
하나의 샘플에 대하여 class 0~9에 대해 10번의 분류를 진행(0~9-detector)하고, 가장 높은 점수를 얻은 detector를 class로 선택한다.
만약 5-detetor의 score가 가장 높았다면 새로 들어온 샘플은 class 5 라고 정의한다.
-
OvO (One-versus-One)
각 숫자의 조합(0과1, 0과 2, ...)마다 이진 분류기를 훈련
✔ N class > N(N-1)/2 개의 분류기 필요
모든 분류기를 통과시켜서 가장 많이 positive로 분류된 class를 선택각 분류기의 훈련에, 구별할 두 클래스에 해당되는 샘플만 필요하다.
- ex. SVM / MNIST (N=10) : 45개 분류기 필요 (10*9/2)
- SVM : 훈련 세트의 크기에 민감함
큰 훈련 세트에서 적은 분류기를 훈련시키는 것보다,
작은 훈련 세트에서 많은 분류기를 훈련시키는게 더 빠르다.
-
사이킷런에서는 이진 분류 알고리즘을 선택하면 자동으로 OvR 또는 OvO를 실행한다.
from sklearn.svm import SVC
#OvO 자동 선택 : 45번 이진 분류
svm_clf = SVC(random_state=42)
# 2000개씩 훈련, '5'만이 아닌 모든 분류기를 훈련
svm_clf.fit(X_train[:2000], y_train[:2000]) # y_train_5가 아니고 y_train을 사용
# 1:1 대결에서 가장 많이 이긴 클래스 선택해 예측
svm_clf.predict([some_digit])
>> array(['5'], dtype=object)decision_function : 클래스당 1개의 점수를 반환한다.
➡ (mnist의 경우) 샘플당 10개의 점수가 반환된다.
some_digit_scores = svm_clf.decision_function([some_digit])
some_digit_scores.round(2)
>> array([[ 3.79, 0.73, 6.06, 8.3 , -0.29, 9.3 ,
1.75, 2.77, 7.21, 4.82]]) # class 5의 점수가 가장 높음
np.argmax(some_digit_scores)
>> 5
svm_clf.classes_ #classes_ : 타깃 클래스의 리스트
>> array(['0', '1', '2', '3', '4', '5', '6', '7', '8', '9'], dtype=object)
svm_clf.classes_[5]
>>'5'- 직접 지정하려면
OneVsRestClassifierOneVsOneClassifier사용
from sklearn.multiclass import OneVsRestClassifier
ovr_clf = OneVsRestClassifier(SVC()) #OvR로 강제
ovr_clf.fit(X_train, y_train)
ovr_clf.predict([some_digit])
>> array(['5'], dtype='<U1') #5로 예측
len(ovr_clf.estimators_) #학습시킨 분류기의 개수
>> 10- SGD는 OvR, OvO등을 사용하지 않고 바로 다중 분류가 가능하다.
- fit() 으로 훈련
sgd_clf = SGDClassifier(random_state=42)
sgd_clf.fit(X_train, y_train)
sgd_clf.predict([some_digit])
>> array(['3'], dtype='<U1')
sgd_clf.decision_function([some_digit]).round()
>> array([[-31893., -34420., -9531., 1824., -22320., -1386., -26189.,
-16148., -4604., -12051.]])- CV를 통한 성능 체크
cross_val_score(sgd_clf, X_train, y_train, cv=3, scoring="accuracy")
>> array([0.87365, 0.85835, 0.8689 ])- 성능 향상 방법 시도
<데이터 스케일링>
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train.astype("float64"))
#CV로 성능 측정
cross_val_score(sgd_clf, X_train_scaled, y_train, cv=3, scoring="accuracy")
>> array([0.8983, 0.891 , 0.9018]) #성능 향상됨2. Error Analysis
promising model을 찾았을 때, 성능을 높이는 방법
2.1 Confusion Matrix
우선 예측이 필요하고, 이후 confusion_matrix() 호출
from sklearn.metrics import ConfusionMatrixDisplay
#예측 생성, 스케일링된 데이터 사용, 3-fold
y_train_pred = cross_val_predict(sgd_clf, X_train_scaled, y_train, cv=3)
ConfusionMatrixDisplay.from_predictions(y_train, y_train_pred)
plt.show()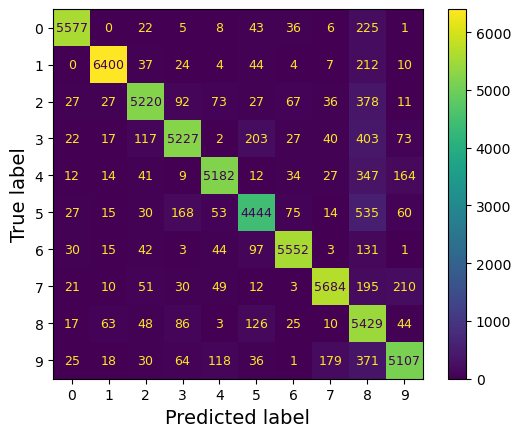
ConfusionMatrixDisplay.from_predictions(y_train, y_train_pred,
normalize="true", values_format=".0%")
plt.show()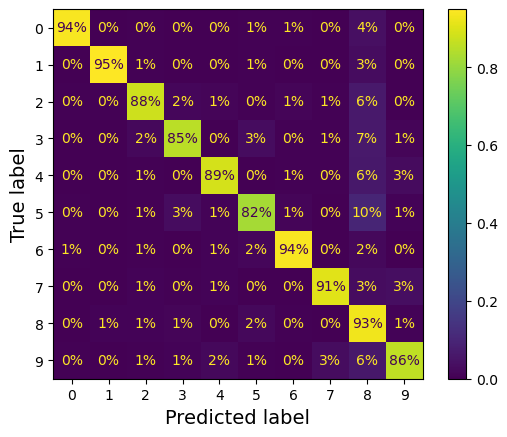
가장 큰 값은 흰색으로, 가장 작은 값은 검은색으로 표시
✔ 어두울수록 확률(성능)이 낮다.
- 5 에서 약간 어둡게 나타남 = poor performance
데이터셋에서 5의 이미지 자체가 적거나, 다른 숫자만큼 잘 분류하지 못한다.
- 주대각선을 0으로 만들어 잘못 분류된 비율을 나타낸다.
sample_weight = (y_train_pred != y_train) #잘못 분류된 비율
ConfusionMatrixDisplay.from_predictions(y_train, y_train_pred,
sample_weight=sample_weight,
normalize="true", values_format=".0%")
plt.show()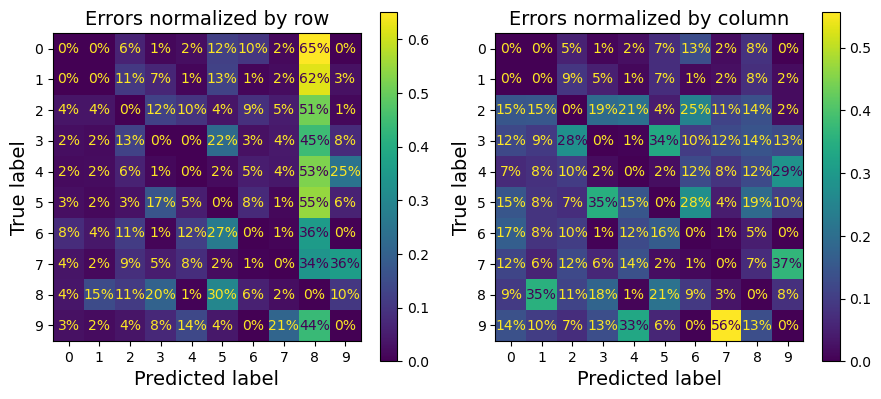
✔ 행(row) : 실제값, 열(column) : 예측값
✔ CM은 반드시 대칭인 것은 아님
(좌) 8의 열이 상당히 밝음
➡ 실제로는 아니지만, 8로 분류된 샘플이 많음.
(우) 1은 대체로 옳게 분류되며, 3과 5가 자주 혼동됨
-
CM 분석으로 성능 향상 방향에 대한 통찰insight을 얻을 수 있다.
-
Improving classifier
▶ 8과 9의 분류 성능 향상, 3/5 혼동의 개선 필요- 훈련 데이터를 더 모은다
- 새로운 특성을 추가한다. ex) 동심원(closed loop)의 개수 세는 알고리즘
- 특정한 패턴이 더 잘 드러나도록 전처리Preprocess
- 개개의 에러 분석 : 분류기가 무슨 일을 하고, 왜 잘못되었는지에 대한 통찰을 얻을 수 있지만 더 어렵고 시간이 오래 걸림
ex. 3과 5에 대한 분석

- 대부분의 경우 '확실히 에러'임
- 원인 : SGDClassifier 사용했기 때문
➡ 선형 분류기는 클래스마다 픽셀에 가중치를 할당하고, 단순히 픽셀 강도의 가중치 합을 클래스의 점수로 계산함. 3과 5는 몇 개의 픽셀만 다르기 때문에 모델이 쉽게 혼동 가능 - 이미지의 위치나 회전 방향에 민감 ▶ 일정하게 전처리하기
참고한 사이트 (감사합니다 💜)
[핸즈온 머신러닝 2/E] 3장. 분류
[핸즈온 머신러닝] 3. 분류
