머신러닝은 데이터 가공/변환, 모델 학습/예측 그리고 평가의 프로세서로 구성된다. 성능 평가 지표는 일반적으로 모델이 분류냐 회귀냐에 따라 여러 종류로 나뉘는데, 먼저 분류의 성능 평가 지표는 아래와 같다.
- 정확도(Accuracy)
- 오차행렬(Confusion Matrix)
- 정밀도(Precision)
- 재현율(Recall)
- F1 스코어
- ROC AUC
1. 정확도(Accuracy)
정확도는 실제 데이터에서 예측 데이터가 얼마나 같은지를 판단하는 지표
타이타닉 예제 수행 결과를 보면 ML 알고리즘 적용 후 예측 정확도가 80%대였지만, 성별이 여자인 경우의 생존률이 높았기에 별다른 알고리즘 적용 없이 남자는 사망, 여자는 생존으로 예측해도 비슷한 수치가 나올 수 있다.
다음 예제에서는 사이킷런의 BaseEstimator클래스를 상속받아 아무런 학습을 하지 않고 성별에 따라 생존자를 예측하는 단순한 classifier를 생성한다.
from sklearn.base import BaseEstimator
import numpy as np
class MyDummyClassifier(BaseEstimator):
# fit() 메서드는 아무것도 학습하지 않음
def fit(self, X, y=None):
pass
# predict() 메서드는 단순히 Sex 피처가 1이면 0, 그렇지 않으면 1로 예측함.
def predict(self, X):
pred = np.zeros((X.shape[0], 1))
for i in range(X.shape[0]):
if X['Sex'].iloc[i] == 1:
pred[i] = 0
else:
pred[i] = 1
return pred방금 생성한 MyDummyClassifier와 저번에 생성한 적 있는 transform_features함수로 타이타닉 생존자 예측을 수행해보자.
import pandas as pd
from sklearn.preprocessing import LabelEncoder
# Null 처리 함수
def fillna(df):
df['Age'].fillna(df['Age'].mean(),inplace=True)
df['Cabin'].fillna('N',inplace=True)
df['Embarked'].fillna('N',inplace=True)
df['Fare'].fillna(0,inplace=True)
return df
# 머신러닝 알고리즘에 불필요한 속성 제거
def drop_features(df):
df.drop(['PassengerId','Name','Ticket'],axis=1,inplace=True)
return df
# 레이블 인코딩 수행.
def format_features(df):
df['Cabin'] = df['Cabin'].str[:1]
features = ['Cabin','Sex','Embarked']
for feature in features:
le = LabelEncoder()
le = le.fit(df[feature])
df[feature] = le.transform(df[feature])
return df
# 앞에서 설정한 Data Preprocessing 함수 호출
def transform_features(df):
df = fillna(df)
df = drop_features(df)
df = format_features(df)
return dffrom sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
titanic_df = pd.read_csv('train.csv')
y_titanic_df = titanic_df['Survived']
X_titanic_df = titanic_df.drop('Survived', axis=1)
X_titanic_df = transform_features(X_titanic_df)
X_train, X_test, y_train, y_test = train_test_split(X_titanic_df, y_titanic_df, test_size=0.2, random_state=0)
# 위에서 생성한 MyDummyClassifier로 학습/예측/평가 수행
myclf = MyDummyClassifier()
myclf.fit(X_train, y_train)
mypredictions = myclf.predict(X_test)
print('Dummy Classifier의 정확도는: {0:.4f}'.format(accuracy_score(y_test, mypredictions)))Dummy Classifier의 정확도는: 0.7877
이렇기에 정확도를 평가 지표로 사용할 때는 신중해야 한다. 예를 들어 100개의 데이터가 있고 이 중 90개의 데이터 레이블이 0, 단 10개의 데이터 레이블이 1일때, 무조건 0으로 예측해도 90%의 정확도가 나온다.
이번엔 유명한 MNIST 데이터 세트를 변환해 불균형한 데이터 세트로 만든 뒤에 정확도 지표 적용시 어떤 문제가 있는지 확인해보자. 원래 MNIST 데이터 세트는 레이블 값이 0부터 9까지 있는 멀티 레이블 분류를 위한 것이다. 이를 이진 분류 문제로 바꿔보려한다. 즉 전체 데이터의 10%만 True, 나머지는 False인 불균형한 데이터 세트로 변형한다.
from sklearn.datasets import load_digits
class MyFakeClassifier(BaseEstimator):
def fit(self, X, y):
pass
# 입력값으로 들어오는 X 데이터 세트의 크기만큼 모두 0값으로 만들어서 반환
def predict(self, X):
return np.zeros((len(X), 1), dtype=bool)
# 사이킷런의 내장 데이터 세트인 load_digits()를 이용해 MNIST 데이터 로딩
digits = load_digits()
# digits 번호가 7번이면 True이고 이를 astype(int)를 사용해서 1로 변환, 7번이 아니면 False이고 0으로 변환
y = (digits.target==7).astype(int)
X_train, X_test, y_train, y_test = train_test_split(digits.data, y, random_state=11)불균형한 데이터로 생성한 y_test의 데이터 분포도를 확인하고 MyFakeClassifier를 이용해 예측과 평가 수행
# 불균형한 레이블 데이터 분포도 확인
print(f'레이블 테스트 세트 크기: {y_test.shape}')
print(f'테스트 세트 레이블 0과 1의 분포도:\n {pd.Series(y_test).value_counts()}')
# Dummy Classifier로 학습/예측/평가
fakeclf = MyFakeClassifier()
fakeclf.fit(X_train, y_train)
fakepred = fakeclf.predict(X_test)
print('모든 예측을 0으로 하여도 정확도는: {:.3f}'.format(accuracy_score(y_test, fakepred)))
이처럼 정확도 평가 지표는 불균형한 레이블 데이터 세트에서는 성능 수치로 사용되어서는 안된다.
2. 오차행렬
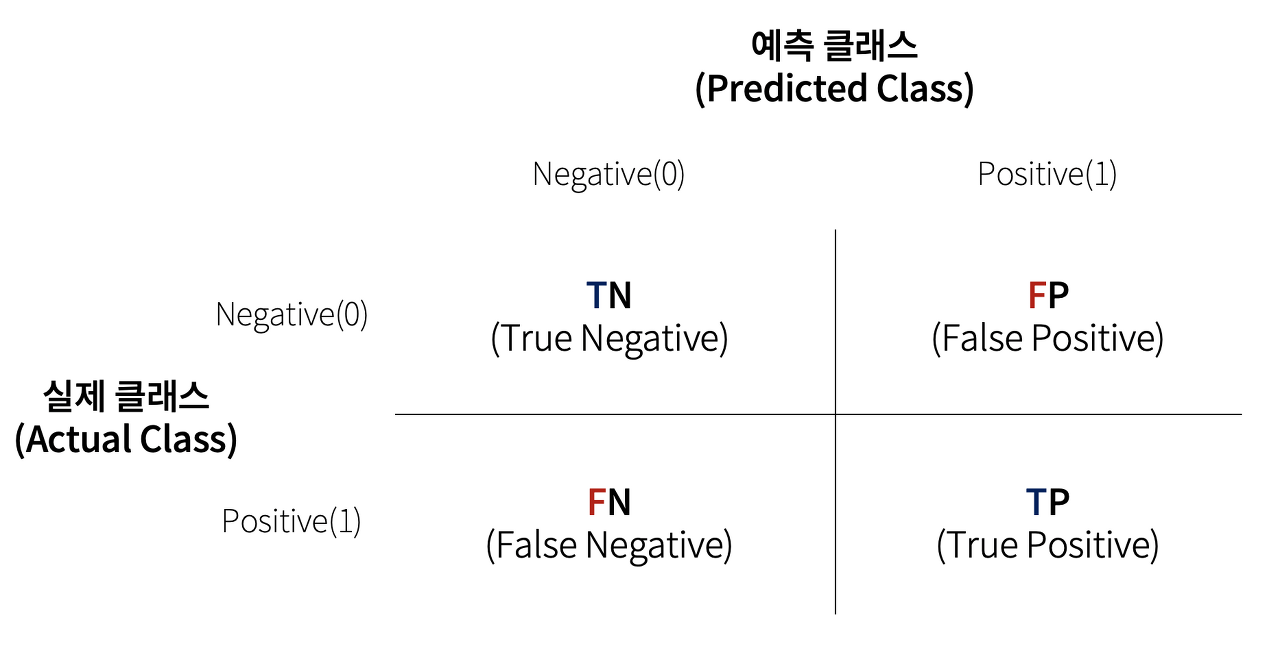
picture source: https://rueki.tistory.com/66
- TN: 예측값을 Negative 값 0으로 예측했고 실제 값 역시 Negative 값 0
- FP: 예측값을 Positive 값 1로 예측했는데 실제 값은 Negative 값 0
- FN: 예측값을 Negative 값 0으로 예측했는데 실제 값은 Positive 값 1
- TP: 예측값을 Positive 값 1로 예측했고 실제 값 역시 Positive 값 1
사이킷런은 오차 행렬을 구하기 위해 confusion_matrix() API를 제공
from sklearn.metrics import confusion_matrix
import seaborn as sns
sns.heatmap(confusion_matrix(y_test, fakepred), annot=True, fmt='2.0f', cmap='summer_r')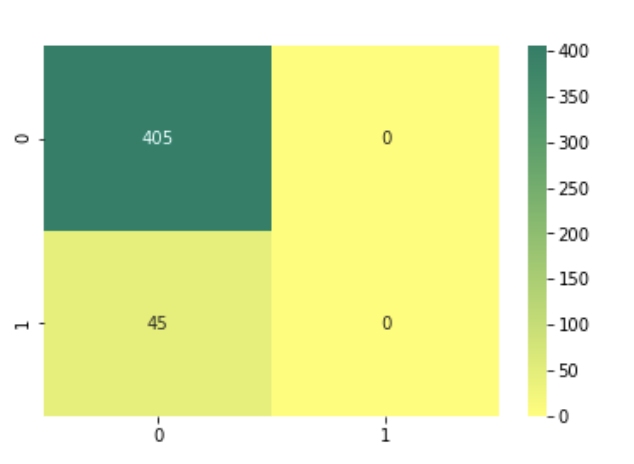
TP, TN, FP, FN 값으로 classifier 성능을 측정할 수 있는 주요 지표인 정확도, 정밀도, 재현율 값을 알 수 있다.(드디어 사회조사분석사 공부하면서 배웠던 것을 써먹을 차례)
3. 정밀도와 재현율
위에서 분균형한 데이터 세트에서 정확도만으로는 모델 신뢰도가 떨어질 수 있는 사례를 확인했다. 정밀도와 재현율은 Positive 데이터 세트의 예측 성능에 좀 더 초점을 맞춘 평가 지표이다. 앞서 만든 MyFakeClassifier는 Positive로 예측한 TP 값이 하나도 없기에 정밀도와 재현율이 모두 0 이다. 재현율은 민감도라고도 한다.
- 재현율이 상대적으로 더 중요한 지표인 경우는 실제 Positive 양성인 데이터 예측을 Negative로 잘못 판단하게 되면 업무상 큰 영향이 발생하는 경우 ex) 암 판단 모델, 보험 사기등의 금융 사기 적발 모델
- 정밀도가 상대적으로 더 중요한 지표인 경우는 실제 Negative 음성인 데이터 예측을 Positive로 잘못 판단하게 되면 업무상 큰 영향이 발생하는 경우 ex) 스팸 메일 여부를 판단하는 모델
재현율과 정밀도 모두 TP를 높이는데 초점을 맞추지만, 재현율은 FN을 낮추는데, 정밀도는 FP를 낮추는데 초점을 맞춘다.
사이킷런은 정밀도 계산을 위해 precision_score(), 재현율 계산을 위해 recall_score()를 API로 제공한다.
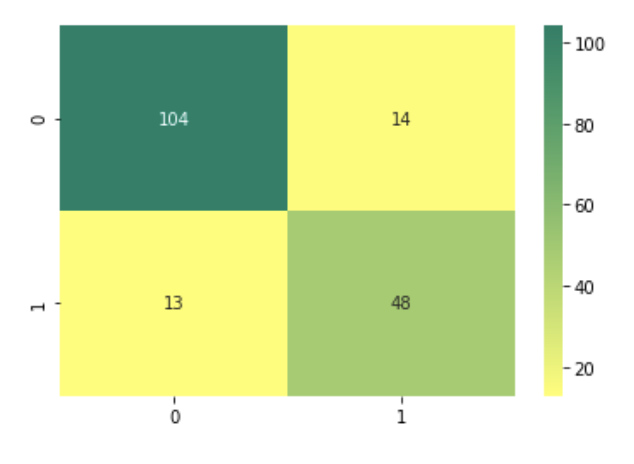
평가를 간편하게 적용하기 위해서 confusion matrix, accuracy, precision, recall등의 평가를 한번에 호출하는 get_clf_eval()함수를 만들고 타이타닉 데이터를 가공해 로지스틱 회귀로 분류를 수행해보자.
from sklearn.metrics import precision_score, recall_score
def get_clf_eval(y_test, pred):
confusion = confusion_matrix(y_test, pred)
accuracy = accuracy_score(y_test, pred)
precision = precision_score(y_test, pred)
recall = recall_score(y_test, pred)
# 원래 책에 있는 print(confusion)인데 안예뻐서 seaborn의 heatmap 사용
sns.heatmap(confusion, annot=True, fmt='2.0f', cmap='summer_r')
print('정확도: {0:.4f}, 정밀도: {1:.4f}, 재현율: {2:.4f}'.format(accuracy, precision, recall))from sklearn.linear_model import LogisticRegression
titanic_df = pd.read_csv('train.csv')
y_titanic_df = titanic_df['Survived']
X_titanic_df = titanic_df.drop('Survived', axis=1)
X_titanic_df = transform_features(X_titanic_df)
X_train, X_test, y_train, y_test = train_test_split(X_titanic_df, y_titanic_df, test_size=0.20, random_state=11)
lr_clf = LogisticRegression()
lr_clf.fit(X_train, y_train)
pred = lr_clf.predict(X_test)
get_clf_eval(y_test, pred)정확도: 0.8492, 정밀도: 0.7742, 재현율: 0.7869
정밀도/재현율 트레이드오프
분류의 결정 임곗값(Threshold)을 조정해 정밀도 또는 재현율의 수치를 높일 수 있다. 하지만 정밀도와 재현율은 상호 보완적인 평가 지표이기에 어느 한쪽을 강제로 높이면 다른 하나의 수치는 떨어지기 쉽다. 이를 정밀도/재현율 트레이드오프(Trade-off)라고 한다.
사이킷런은 개별 데이터별로 예측 확률을 반환하는 메서드인 predict_proba()를 제공한다. 이는 학습이 완료된 사이킷런 Classifier 객체에서 호출이 가능하며 테스트 피처 데이터 세트를 파라미터로 입력해주면 테스트 피처 레코드의 개별 클래스 예측 확률을 반환한다. predict()메서드와 유사하지만 단지 반환 결과가 예측 결과 클래스값이 아닌 예측 확률 결과이다. 각 열은 개별 클래스의 예측 확률로 이진 분류에서 첫 번째 칼럼은 0 Negative의 확률, 두 번째 칼럼은 1 Positive의 확률
pred_proba = lr_clf.predict_proba(X_test)
pred = lr_clf.predict(X_test)
print(f'pred_proba() 결과 shape: {pred_proba.shape}')
print(f'pred_proba array에서 앞 3개만 샘플로 추출:\n{pred_proba[:3]}')
# 예측 확률 array와 예측 결괏값 array를 병합해 예측 확률과 결과값을 한눈에 확인
pred_proba_result = np.concatenate([pred_proba, pred.reshape(-1, 1)], axis=1)
print(f'두 개의 class중에서 더 큰 확률을 클래스 값으로 예측:\n{pred_proba_result[:3]}')
사이킷런의 predict()는 predict_proba() 메서드가 반환하는 확률 값을 가진 ndarray에서 정해진 임곗값(위의 예제는 0.5)을 만족하는 ndarray의 칼럼 위치를 최종 예측 클래스로 결정한다. 사이킷런의 Binarizer 클래스를 이용해서 이 로직을 구현해 보려한다.
# 이해를 돕기위한 Binarizer 예제
from sklearn.preprocessing import Binarizer
X = [[1, -1, 2],
[2, 0 , 0],
[0, 1.1, 1.2]]
# X의 개별 원소들이 threshold 값보다 같거나 작으면 0, 크면 1
binarizer = Binarizer(threshold=1.1)
print(binarizer.fit_transform(X))
custom_threshold = 0.5
# predict_proba() 반환값의 두 번째 칼럼, 즉 positive 클래스 칼럼 하나만 추출해 Binarizer를 적용
pred_proba_1 = pred_proba[:, 1].reshape(-1, 1)
binarizer = Binarizer(threshold=custom_threshold).fit(pred_proba_1)
custom_predict = binarizer.transform(pred_proba_1)
get_clf_eval(y_test, custom_predict)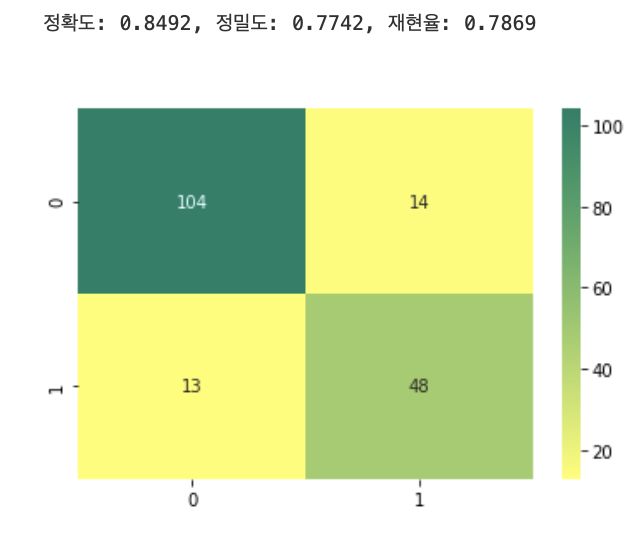
custom_threshold_2 = 0.4
pred_proba_2 = pred_proba[:, 1].reshape(-1, 1)
binarizer_2 = Binarizer(threshold=custom_threshold_2).fit(pred_proba_2)
custom_predict_2 = binarizer_2.transform(pred_proba_2)
get_clf_eval(y_test, custom_predict_2)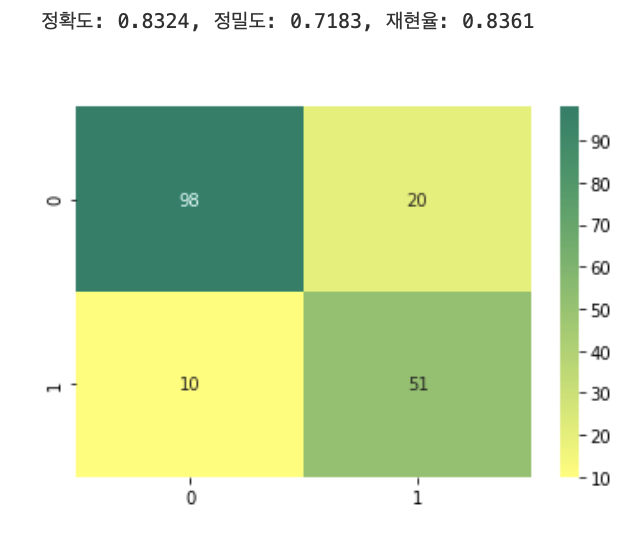
임곗값이 0.5에서 0.4로 낮아지면서 TP가 48에서 51로 늘고 FN이 13에서 10으로 줄었다. 그에따라 재현율이 0.7869에서 0.8361로 좋아졌다. 하지만 FP는 14에서 20으로 늘면서 정밀도가 0.7742에서 0.7183으로 나빠졌고 정확도도 0.8492에서 0.8324로 나빠졌다.
이번에는 임곗값을 0.4에서부터 0.6까지 0.05씩 증가시키면서 평가 지표를 조사해보자.
thresholds = [0.4, 0.45, 0.5, 0.55, 0.6]
def get_clf_eval(y_test, pred):
confusion = confusion_matrix(y_test, pred)
accuracy = accuracy_score(y_test, pred)
precision = precision_score(y_test, pred)
recall = recall_score(y_test, pred)
print('정확도: {0:.4f}, 정밀도: {1:.4f}, 재현율: {2:.4f}'.format(accuracy, precision, recall))
def get_eval_by_threshold(y_test, pred_proba_c1, thresholds):
# thresholds list 객체 내의 값을 차례로 iteration하면서 evaluation 수행
for custom_threshold in thresholds:
binarizer = Binarizer(threshold=custom_threshold).fit(pred_proba_c1)
custom_predict = binarizer.transform(pred_proba_c1)
print(f'임곗값: {custom_threshold}')
get_clf_eval(y_test, custom_predict)
get_eval_by_threshold(y_test, pred_proba[:, 1].reshape(-1, 1), thresholds)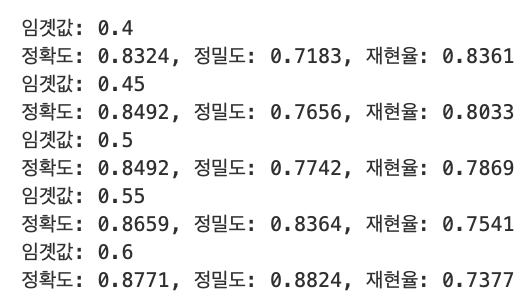
임곗값이 0.45일 경우 디폴트 0.5인 경우와 비교해서 정확도는 0.8492로 동일하고 정밀도는 0.7742에서 0.7656으로 약간 떨어졌으나, 재현율은 0.7869에서 0.8033으로 올랐다. 그래서 재현율을 향상시키면서 다른 수치의 감소를 희생해야한다면 임곗값 0.45가 가장 적당해 보인다.
사이킷런은 이와 유사한 precision_recall_curve() API를 제공한다.
- 입력 파라미터:
- y_true: 실제 클래스 값 배열(배열 크기 = [데이터 건수])
- probas_pred: Positive 칼럼의 예측 확률 배열(배열크기 = [데이터 건수])
- 반환 값:
- 정밀도: 임곗값별 정밀도 값을 배열로 반환
- 재현율: 임곗값별 재현율 값을 배열로 반환
from sklearn.metrics import precision_recall_curve
# 레이블 값이 1일 때의 예측 확률 추출
pred_proba_class1 = lr_clf.predict_proba(X_test)[:, 1]
# 실제값 데이터 세트와 레이블 값이 1일 때의 예측 확률을 precision_recall_curve 인자로 입력
precision, recalls, thresholds = precision_recall_curve(y_test, pred_proba_class1)
print(f'반환된 분류 결정 임곗값 배열의 shape: {thresholds.shape}')
# 반환된 임곗값 배열 로우가 147건이므로 샘플로 10건만 추출하되, 임곗값을 15 step으로 추출
thr_index = np.arange(0, thresholds.shape[0], 15)
print(f'샘플 추출을 위한 임곗값 배열의 index 10개: {thr_index}')
print(f'샘플용 10개의 임곗값: {np.round(thresholds[thr_index], 2)}')
# 15 step 단위로 추출된 임곗값에 따른 정밀도와 재현율 값
print(f'샘플 임곗값별 정밀도: {np.round(precision[thr_index], 3)}')
print(f'샘플 임곗값별 재현율: {np.round(recalls[thr_index], 3)}')
import matplotlib.pyplot as plt
import matplotlib.ticker as ticker
%matplotlib inline
def precision_recall_curve_plot(y_test, pred_proba_c1):
# threshold ndarray와 이 threshold에 따른 정밀도, 재현율 ndarray 추출
precisions, recalls, thresholds = precision_recall_curve(y_test, pred_proba_c1)
# X축을 threshold값으로, Y축은 정밀도, 재현율 값으로 각각 Plot 수행, 정밀도는 점선으로 표시
plt.figure(figsize=(8, 6))
threshold_boundary = thresholds.shape[0]
plt.plot(thresholds, precisions[0:threshold_boundary], linestyle='--', label='precision')
plt.plot(thresholds, recalls[0:threshold_boundary], label='recall')
# threshold 값 X축의 scale을 0.1 단위로 변경
start, end = plt.xlim()
plt.xticks(np.round(np.arange(start, end, 0.1), 2))
# X, Y축 label과 legend, grid 설정
plt.xlabel('Threshold value')
plt.ylabel('Precision and Recall value')
plt.legend()
plt.grid()
precision_recall_curve_plot(y_test, lr_clf.predict_proba(X_test)[:, 1])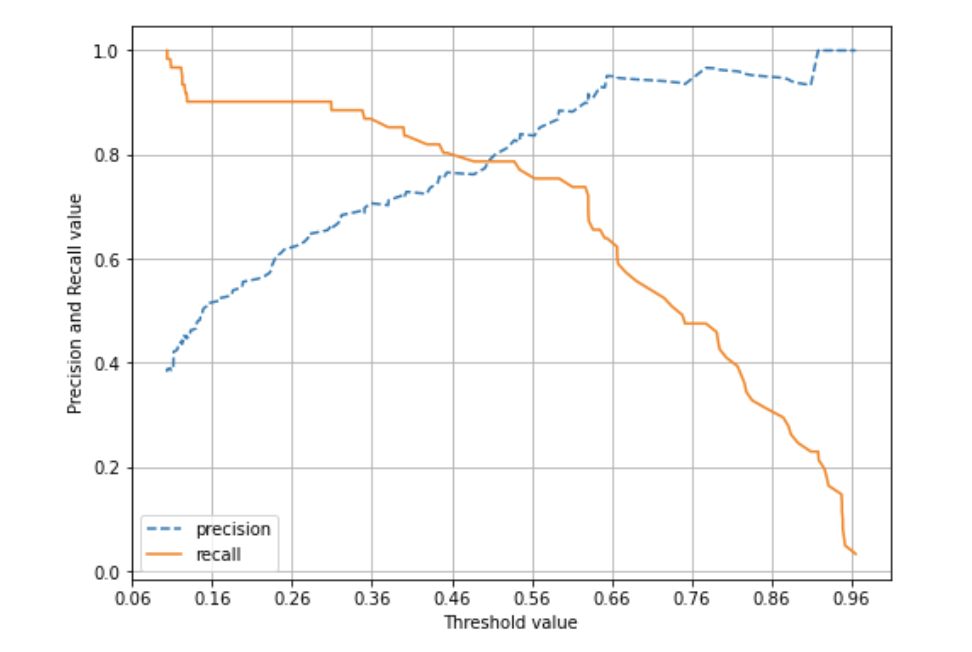
앞의 예제의 로지스틱 회귀 기반의 타이타닉 생존자 예측 모델의 경우 임곗값이 약 0.45 지점에서 재현율과 정밀도가 비슷해지는 모습을 보인다.
4. F1 스코어
F1 스코어는 정밀도와 재현율을 결합한 지표이다. F1 스코어는 정밀도와 재현율이 어느 한 쪽으로 치우치지 않는 수치를 나타낼 때 상대적으로 높은 값을 가진다.
사이킷런에서 F1 스코어를 구하기 위해 f1_score()라는 API를 제공한다.
from sklearn.metrics import f1_score
f1 = f1_score(y_test, pred)
print(f'F1 스코어: {np.round(f1, 4)}')F1 스코어: 0.7805
이번에는 타이타닉 생존자 예측에서 임곗값을 변화시키면서 F1 스코어를 포함한 평가 지표를 구해보자.
def get_clf_eval(y_test, pred):
confusion = confusion_matrix(y_test, pred)
accuracy = accuracy_score(y_test, pred)
precision = precision_score(y_test, pred)
recall = recall_score(y_test, pred)
f1 = f1_score(y_test, pred)
print('오차행렬')
print(confusion)
print('정확도: {0:.4f}, 정밀도: {1:.4f}, 재현율: {2:.4f}, F1: {3:.4f}'
.format(accuracy, precision, recall, f1))
thresholds = [0.4, 0.45, 0.5, 0.55, 0.6]
pred_proba = lr_clf.predict_proba(X_test)
get_eval_by_threshold(y_test, pred_proba[:, 1].reshape(-1, 1), thresholds)
5. ROC 곡선과 AUC
ROC 곡선은 FPR(False Positive Rate)이 변할 때 TPR(True Positive Rate)이 어떻게 변하는지를 나타내는 곡선으로, FPR을 X 축으로, TPR을 Y 축으로 잡으면 FPR의 변화에 따른 TPR의 변화가 곡선 형태로 나타난다. TPR은 재현율을 나타내고 이에 대응하는 지표인 TNR은 특이성을 나타낸다.
$$ FPR = \frac{FP}{(FP + TN)} = 1 - TNR = 1 - 특이성 $$
ROC 곡선이 가운데 직선에 가까울수록 성능이 떨어지는 것이며, 멀어질수록 성능이 뛰어난 것이다. 사이킷런은 ROC 곡선을 구하기 위해 roc_curve() API를 제공하며, 사용법은 precision_recall_curve()와 유사하다.
- 입력파라미터
- y_true: 실제 클래스 값 array(array shape = [데이터 건수])
- y_score: predict_proba()의 반환 값 array에서 Positive 칼럼의 예측 확률이 보통 사용
- 반환값
- fpr: fpr 값을 array로 반환
- tpr: tpr 값을 array로 반환
- thresholds: thresholds 값 array
from sklearn.metrics import roc_curve
# 레이블 값이 1일때의 예측 확률을 추출
pred_proba_class1 = lr_clf.predict_proba(X_test)[:, 1]
fprs, tprs, thresholds = roc_curve(y_test, pred_proba_class1)
# 반환된 임곗값 배열에서 샘플로 데이터를 추출하되, 임곗값을 5 step으로 추출
# thresholds[0]은 max(예측확률) + 1 로 임의 설정됨, 이를 제외하기 위해 np.arange는 1부터 시작
thr_index = np.arange(1, thresholds.shape[0], 5)
print(f'샘플 추출을 위한 임곗값 배열의 index: {thr_index}')
print(f'샘플 index로 추출한 임곗값: {np.round(thresholds[thr_index], 2)}')
# 5 step 단위로 추출된 임곗값에 따른 FPR, TPR 값
print(f'샘플 임곗값별 FPR: {np.round(fprs[thr_index], 3)}')
print(f'샘플 임곗값별 TPR: {np.round(tprs[thr_index], 3)}')
위의 결과로 임곗값이 1에서부터 점점 작아지면서 FPR이 점점 커지고 TPR은 가파르게 커짐을 알 수 있다.
def roc_curve_plot(y_test, pred_proba_c1):
fprs, tprs, thresholds = roc_curve(y_test, pred_proba_c1)
plt.plot(fprs, tprs, label='ROC')
# 가운데 대각선 직선을 그림
plt.plot([0, 1], [0, 1], 'k--', label='Random')
start, end = plt.xlim()
plt.xticks(np.round(np.arange(start, end, 0.1), 2))
plt.xlim(0, 1)
plt.ylim(0, 1)
plt.xlabel('FPR( 1- Sensitivity )')
plt.ylabel('TPR( Recall )')
plt.legend()
roc_curve_plot(y_test, pred_proba[:, 1])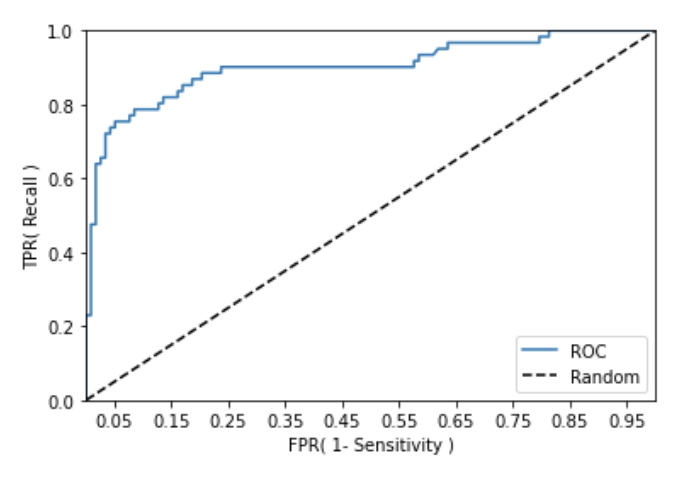
일반적으로 ROC 곡선 자체는 FPR과 TPR의 변화 값을 보는 데 이용하며 분류의 성능 지표로 사용되는 것은 ROC 곡선 면적에 기반한 AUC 값으로 결정한다. AUC(Area Under Curve) 값은 곡선 밑의 면적을 구한 것으로 일반적으로 1에 가까울수록 좋은 수치이다.
Source: 파이썬 머신러닝 완벽 가이드 / 위키북스
