titanic의 DataFrame
Kaggle 코드를 공부하면서 dataframe에 대해 이해안되는 부분들이 있었는데 이번에 공부하면서 많이 알게된거 같습니다. 언제쯤 공부했던 대량의 kaggle notebook들을 올릴지 고민해봐야할 것 같습니다.
import pandas as pd
titanic_df = pd.read_csv(r'./kaggle/titanic/train.csv')
titanic_df.head()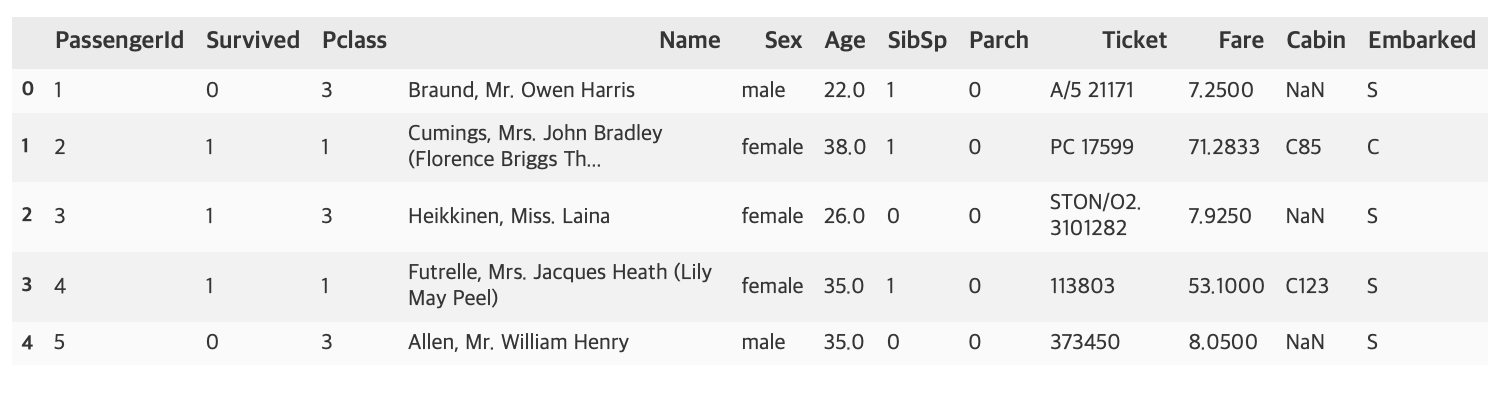
print(f'titanic_df의 형식: {type(titanic_df)}')
print(f'Dataframe의 크기: {titanic_df.shape}')[Output]
titanic_df의 형식: <class 'pandas.core.frame.DataFrame'>
Dataframe의 크기: (891, 12)titanic_df.info()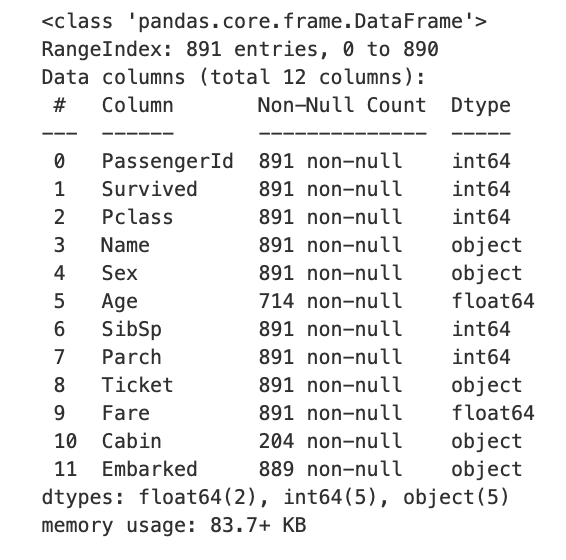
공부하면서 info() 메서드를 봤을때 891은 알겠고 non-null은 뭐지 하고 생각했는데, 알고보니... 같이보는거였네. 891 non-null, null값이 아닌게 891개라는 뜻이였다. 휴.. 참신한 나
titanic_df.describe()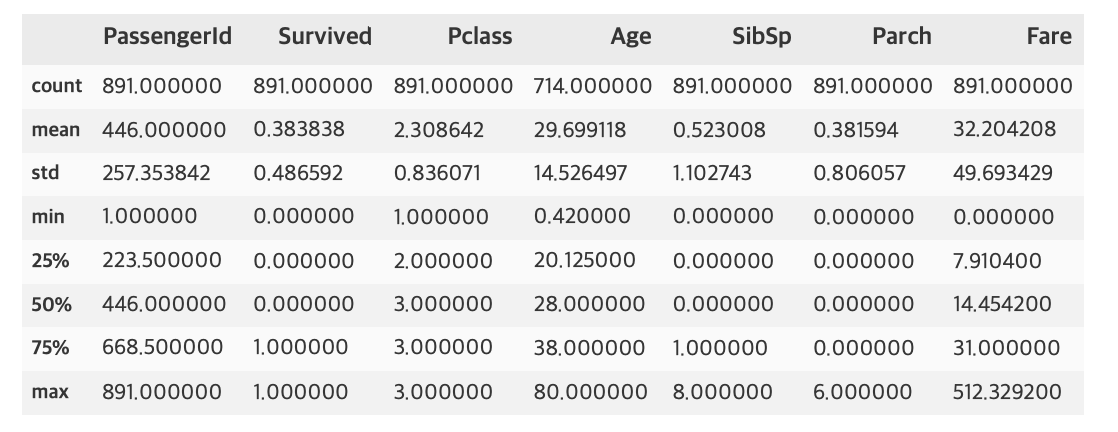
칼럼내 갯수들을 알고 싶으면 value_count()메서드를 사용할 수 있습니다.
Pclass_value = titanic_df['Pclass'].value_counts()
print(Pclass_value)
print(type(Pclass_value))[Output]
3 491
1 216
2 184
Name: Pclass, dtype: int64
<class 'pandas.core.series.Series'>DataFrame의 칼럼 변환하기
칼럼 생성과 수정하기
titanic_df['Age_0'] = 0
titanic_df.head(10)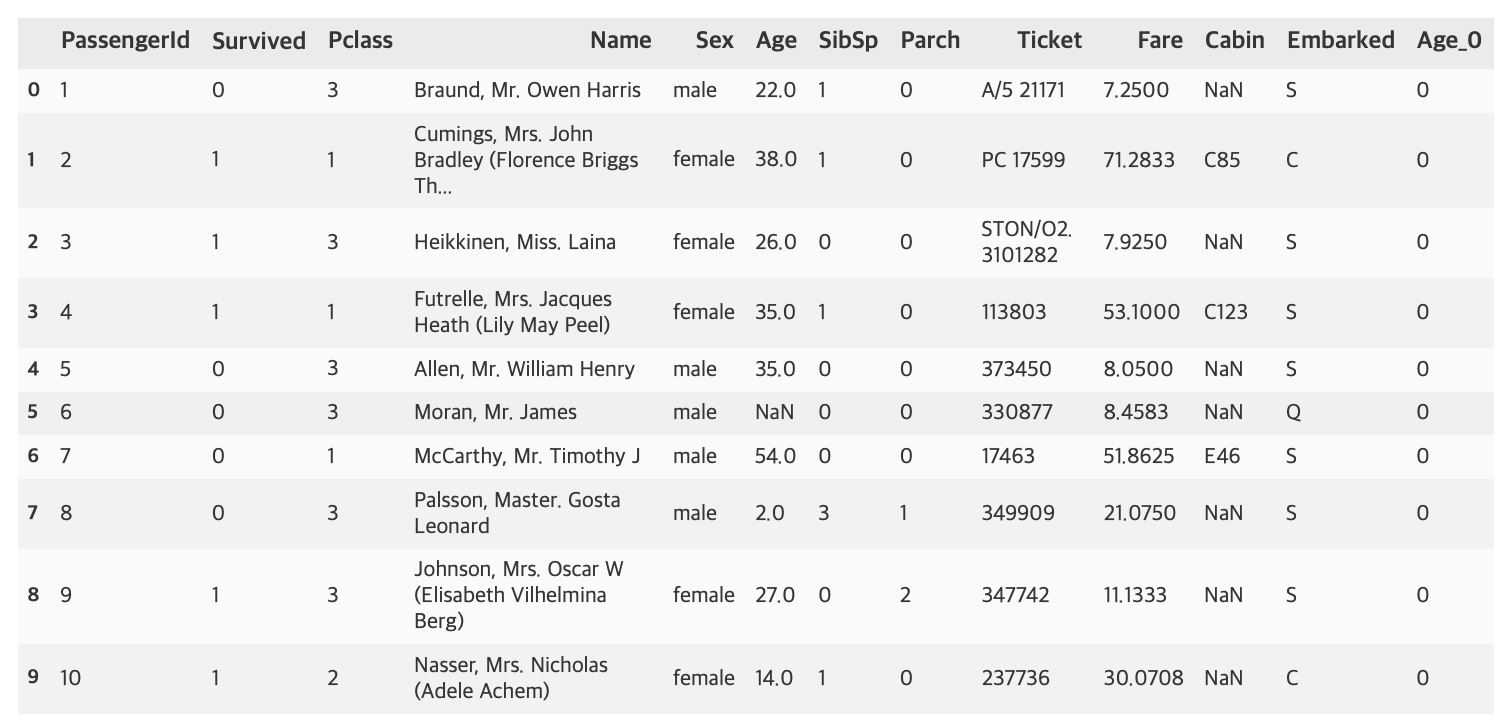
데이터프레임[생성할 칼럼명]으로 간단하게 생성할 수 있습니다.
titanic_df['Age_0'] = titanic_df['Age_0'] + 100
titanic_df.head(10)
이렇게 간단히 수정도 가능
칼럼 삭제하기
DataFrame.drop(labels=None, axis=0, index=None, columns=None, level=None, inplace=False, errors='raise)
axis 0은 칼럼 방향, axis 1은 로우 방향이므로 axis 0은 이상치를 삭제할때 많이 쓰고 axis 1은 기존 칼럼 삭제시 사용합니다.
titanic_df_drop = titanic_df.drop('Age_0', axis=1)
titanic_df_drop.head(10)이렇게하면 삭제가 가능합니다. 하지만 내가 드롭한 데이터를 저장한 데이터프레임은 titanic_df가 아닌 titanic_df_drop입니다. 그럼 여기서 titanic_df를 확인해보겠습니다.
titanic_df.head(3)
보다시피 아직도 칼럼이 존재하는 것을 알 수 있습니다.
여기서 필요한 파라미터가 inplace입니다.
drop_result = titanic_df.drop('Age_0', axis=1, inplace=True)
titanic_df.head(3)
보다시피 드롭을 한 후 drop_result에 저장을 하고 titanic_df에 상위 3개 데이터를 확인했을때 Age_0 칼럼이 드롭된 것을 알 수 있습니다. inplace=True를 파라미터에 넣으면 원래 데이터프레임에 덮어씌운다고 생각할 수 있습니다.
데이터프레임의 인덱스
데이터프레임을 만지다보면 인덱스를 설정해야 할 일이 생깁니다.
titanic_reset_df = titanic_df.reset_index(inplace=False)
titanic_reset_df.head(3)
그럴때 이렇게 reset_index메서드를 사용하면 인덱스를 생성할 수 있습니다. 일반적으로 인덱스가 연속된 int 숫자형 데이터가 아닐 경우에 다시 이를 연속 int 숫자형 데이터로 만들 때 주로 사용합니다.
value_counts = titanic_df['Pclass'].value_counts()
print(value_counts)
new_value_counts = value_counts.reset_index(inplace=False)
print(new_value_counts)[Output]
3 491
1 216
2 184
Name: Pclass, dtype: int64
index Pclass
0 3 491
1 1 216
2 2 184Source: 파이썬 머신러닝 완벽 가이드 / 위키북스
