[]연산자
[]연산자를 이용해서 데이터 셀렉션을 할 수 있다.
print('단일 칼럼 데이터 추출:\n', titanic_df['Pclass'].head(3))
print('\n여러 칼럼의 데이터 추출:\n', titanic_df[['Survived', 'Pclass']].head(3))[Output]
단일 칼럼 데이터 추출:
0 3
1 1
2 3
Name: Pclass, dtype: int64
여러 칼럼의 데이터 추출:
Survived Pclass
0 0 3
1 1 1
2 1 3numpy에서 공부했던 불린 인덱싱도 사용 가능하다.
# 불린 인덱싱 사용
titanic_df[titanic_df['Pclass'] == 3].head(5)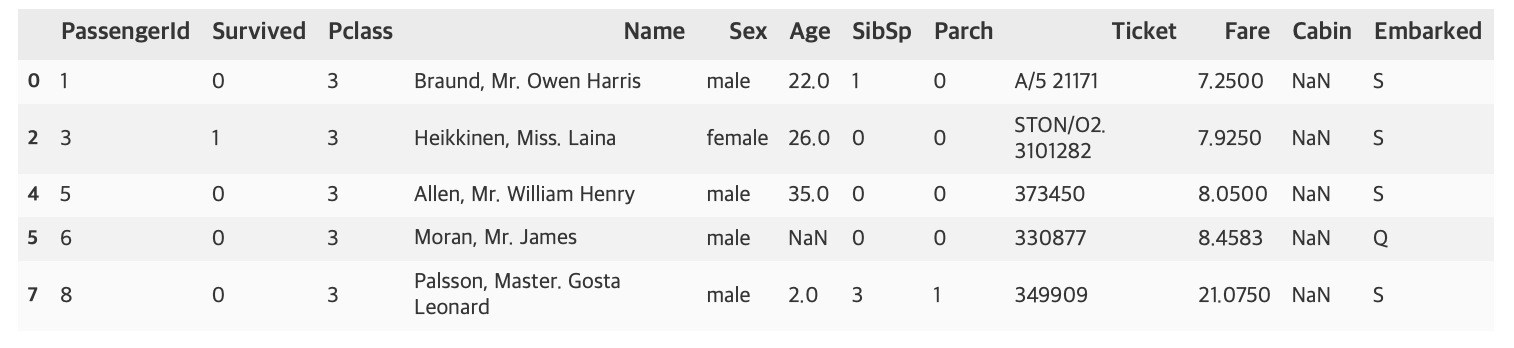
정리해보면
- DataFrame 바로 뒤의 [] 연산자는 넘파이의 []나 Series의 []와 다르다.
- DataFrame 바로 뒤의 [] 내 입력 값은 칼럼명을 지정해 칼럼 지정 연산에 사용하거나 불린 인덱스 용도로만 사용해야 한다.
- DataFrame[0:2] 같은 슬라이싱 연상으로 데이터를 추출하는 방법은 사용하지 않는 것이 좋다.
DataFrame iloc[] 연산자
위치 기반 인덱싱만 허용하기 때문에 행과 열 값으로 integer 또는 integer형의 슬라이싱, 팬시 리스트 값을 입력해줘야한다.
data = {'Name': ['Chulmin', 'Eunkyung', 'Jinwoong', 'Soobeom'],
'Year': [2011, 2016, 2015, 2015],
'Gender': ['Male', 'Female', 'Male', 'Male']
}
data_df = pd.DataFrame(data, index=['one', 'two', 'three', 'four'])
data_df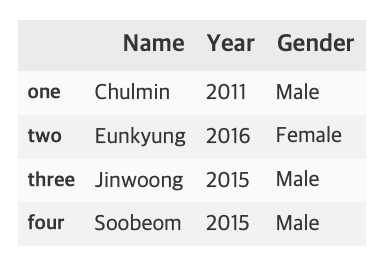
data_df.iloc[0, 0][Output]
'Chulmin'
iloc[]는 슬라이싱과 팬시 인덱싱은 제공하나 명확한 위치 기반 인덱싱이 사용되어야 하는 제약으로 인해 불린 인덱싱은 제공하지 않는다.
print('위치 기반 iloc slicing\n', data_df.iloc[0:1, 0], '\n')
print('명칭 기반 loc slicing\n', data_df.loc['one': 'two', 'Name'])[Output]
위치 기반 iloc slicing
one Chulmin
Name: Name, dtype: object
명칭 기반 loc slicing
one Chulmin
two Eunkyung
Name: Name, dtype: object불린 인덱싱
titanic_boolean = titanic_df[titanic_df['Age'] > 65]
titanic_boolean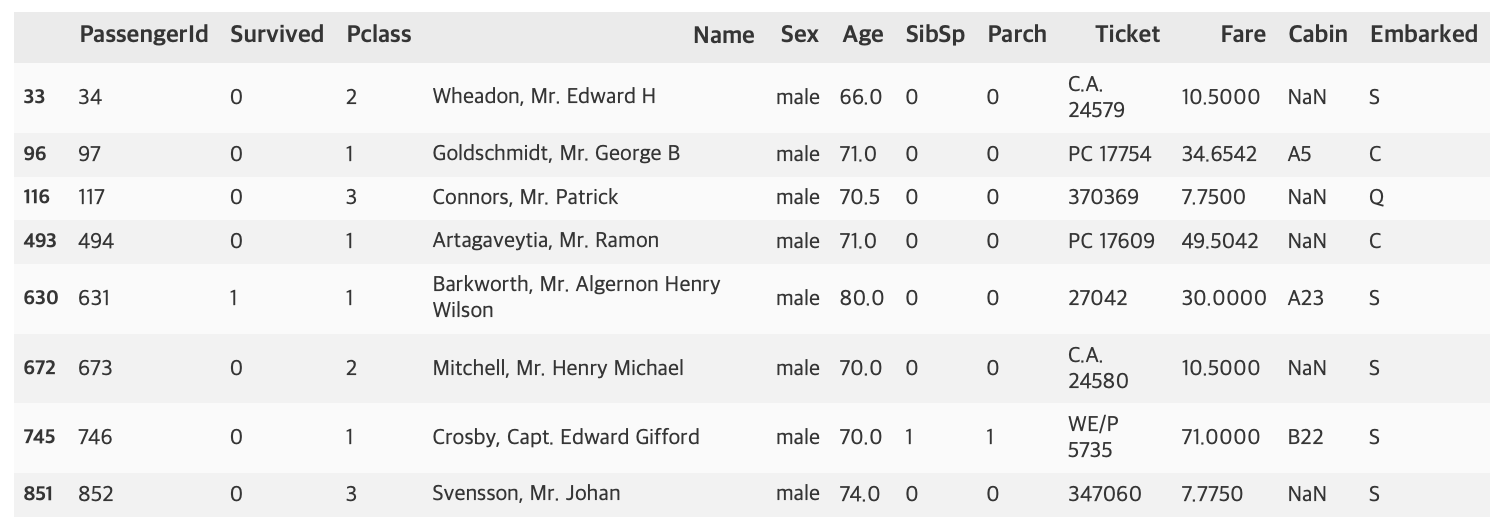
이렇게 dataframe[조건식]의 형태로 데이터 셀렉션이 가능하다.
titanic_df[(titanic_df['Age'] > 60) & (titanic_df['Pclass'] == 1) & (titanic_df['Sex'] == 'female')]cond1 = titanic_df['Age'] > 60
cond2 = titanic_df['Pclass'] == 1
cond3 = titanic_df['Sex'] == 'female'
titanic_df[cond1 & cond2 & cond3]위 두가지 방식을 이용해서 아래와 같은 결과도 얻을 수 있다.

Source: 파이썬 머신러닝 완벽 가이드 / 위키북스

데이터 분석 공부용 벨로그