결정 트리(Decision Tree)란?
결정트리는 데이터에 있는 규칙을 학습을 통해 자동으로 찾아내 트리(Tree) 기반의 분류 규칙을 만든다. 일반적으로 쉽게 표현하는 방법은 if/else 로 스무고개 게임을 한다고 생각하면 된다.
아래 그림에서 다이아몬드 모양은 규칙 노드를, 타원형은 리프 노드를 뜻한다. 데이터 세트에 피처가 있고 이러한 피처가 결합해 규칙 조건을 만들 때마다 규칙 노드가 만들어지지만, 많은 규칙이 있으면 분류를 결정하는 방식이 복잡해지고 이는 과적합으로 이어지기 쉽다. 즉 트리의 깊이(depth)가 깊어질수록 결정 트리의 예측 성능이 저하될 가능성이 높다.
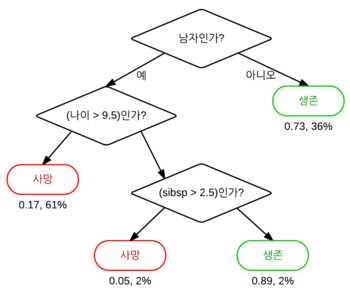
결정 노드는 정보 균일도가 높은 데이터 세트를 먼저 선택할 수 있도록 규칙 조건을 만든다. 정보의 균일도를 측정하는 대표적인 방법은 정보 이득 지수와 지니 계수가 있다.
- 정보 이득은 엔트로피 개념을 기반으로 한다. 엔트로피는 주어진 데이터 집합의 혼잡도를 의미하는데, 서로 다른 값이 섞여 있으면 엔트로피가 높고, 같은 값이 섞여 있으면 엔트로피가 낮다. 정보 이득 지수는 1 - 엔트로피 지수 이다.
- 지니 계수는 경제학에서 불평등 지수를 나타낼 때 사용하는 계수로, 0이 가장 평등하고 1로 갈수록 불평등하다. 머신러닝에서는 지니 계수가 낮을수록 데이터 균일도가 높은 것으로 해석한다.
결정 트리 파라미터
사이킷런에서 제공하는 결정 트리 클래스는 DecisionTreeClassifier 와 DecisionTreeRegressor 가 있다. DecisionTreeClassifier 는 분류를 위한 클래스, DecisionTreeRegressor 는 회귀를 위한 클래스이다.
- min_samples_split
- 노드를 분할하기 위한 최소한의 샘플 데이터 수, 과적합을 제어하는데 사용
- 디폴트는 2, 작게 설정할수록 분할하는 노드가 많아져서 과적합 가능성 증가
- min_samples_leaf
- 말단 노드가 되기 위한 최소한의 샘플 데이터 수
- 과적합 제어 용도
- 비대칭적 데이터의 경우 특정 클래스의 데이터가 극도로 작을 수 있으므로 이 경우는 작게 설정 필요
- max_features
- 최적의 분할을 위해 고려할 최대 피처 갯수
- 디폴트는 None으로 데이터 세트의 모든 피처를 사용해 분할 수행
- int 형으로 지정하면 대상 피처의 갯수, float 형으로 지정하면 전체 피처 중 대상 피처의 퍼센트임
- sqrt는 전체 피처의 제곱근수 만큼 선정, auto와 동일
- log는 전체 피처 수에 지수가 2인 로그를 씌움
- max_depth
- 트리의 최대 깊이를 규정
- 디폴트는 None, 완벽하게 클래스 결정 값이 될 때까지 깊이를 계속 키우며 분할하거나 노드가 가지는 데이터 개수가 min_samples_split 보다 작아질 때까지 계속 깊이를 증가시킴.
- 깊이가 깊어지면 min_sample_split 설정대로 최대 분할아여 과적합할 수 있으므로 적절한 값으로 제어 필요
- max_leaf_nodes
- 말단 노드의 최대 갯수
결정 트리 가시화를 위한 맥북에 graphviz 설치하기
-
Homebrew가 설치된 경우
터미널을 켜고 아래 명령어 입력
brew install graphviz
pip install pygraphviz -
Homebrew가 없는 경우
터미널에 붙여넣기
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
설치 후 1번을 실행하면 됩니다.
붓꽃 데이터 세트의 결정 트리 시각화하기
붓꽃 데이터 세트에 결정 트리를 적용해서 시각화해보자.
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
import warnings
warnings.filterwarnings('ignore')
dt_clf = DecisionTreeClassifier(random_state=156)
iris_data = load_iris()
X_train, X_test, y_train, y_test = train_test_split(iris_data.data, iris_data.target, test_size=0.2, random_state=11)
dt_clf.fit(X_train, y_train)DecisionTreeClassifier(random_state=156)from sklearn.tree import export_graphviz
# export_graphviz()의 결과로 out_file로 지정된 tree.dot 파일을 생성
export_graphviz(dt_clf, out_file="tree.dot", class_names=iris_data.target_names, feature_names=iris_data.feature_names, impurity=True, filled=True)import graphviz
with open("tree.dot") as f:
dot_graph = f.read()
graphviz.Source(dot_graph)
- petal length(cm): 피처의 조건이 있는 것은 자식 노드를 만들기 위한 규칙 조건, 조건이 없으면 리프 노드
- gini: 다음의 value=[]로 주어진 데이터 분포에서의 지니 계수
- samples: 현 규칙에 해당하는 데이터 건수
- value: 클래스 값 기반의 데이터 건수, [41, 40, 39]는 Setosa 41개, Vesicolor 40개, Virginica 39개
결정 트리의 피처 중요도 표현하기
feature_importance_를 사용해서 나타낼 수 있다.
import seaborn as sns
import numpy as np
%matplotlib inline
print('Feature importances:\n{0}'.format(np.round(dt_clf.feature_importances_, 3)))
# feature 별 importance 매핑
for name, value in zip(iris_data.feature_names, dt_clf.feature_importances_):
print('{0} : {1:.3f}'.format(name, value))
# feature importance를 column 별로 시각화하기
sns.barplot(x=dt_clf.feature_importances_, y=iris_data.feature_names)Feature importances:
[0.025 0. 0.555 0.42 ]
sepal length (cm) : 0.025
sepal width (cm) : 0.000
petal length (cm) : 0.555
petal width (cm) : 0.420
<matplotlib.axes._subplots.AxesSubplot at 0x7fba8b8b8e50>
4개의 피처들 중 petal length 가 가장 피처 중요도가 높은 것을 알 수 있다.
결정 트리 과적합(Overfitting)
결정 트리가 어떻게 학습 데이터를 분할해 예측을 수행하는지와 이로 인한 과적합 문제를 시각화해보자. 분류를 위한 데이터 세트를 임의로 만드는데 사이킷런은 make_classification() 함수를 제공한다.
from sklearn.datasets import make_classification
import matplotlib.pyplot as plt
%matplotlib inline
plt.title('3 Class Values with 2 Features Sample Data Creation')
# 2차원 시각화를 위해서 피처는 2개, 클래스는 3가지 유형의 분류 샘플 데이터 생성
X_feature, y_labels = make_classification(n_features=2, n_redundant=0, n_informative=2, n_classes=3, n_clusters_per_class=1, random_state=0)
# 그래프 형태로 2개의 피처로 2차원 좌표 시각화, 각 클래스 값은 다른 색깔로 표시
plt.scatter(X_feature[:, 0], X_feature[:, 1], marker='o', c=y_labels, s=25, edgecolors='k')<matplotlib.collections.PathCollection at 0x7fba8ba69ac0>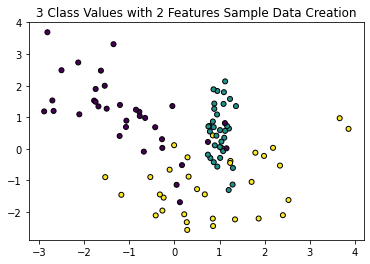
유틸리티 함수 visualize_boundary()를 만들어서 머신러닝 모델이 클래스 값을 예측하는 결정 기준을 색상과 경계로 나타내 모델이 어떻게 데이터 세트를 예측 분류하는지 이해하게 함.
import numpy as np
# Classifier의 Decision Boundary를 시각화 하는 함수
def visualize_boundary(model, X, y):
fig,ax = plt.subplots()
# 학습 데이타 scatter plot으로 나타내기
ax.scatter(X[:, 0], X[:, 1], c=y, s=25, cmap='rainbow', edgecolor='k',
clim=(y.min(), y.max()), zorder=3)
ax.axis('tight')
ax.axis('off')
xlim_start , xlim_end = ax.get_xlim()
ylim_start , ylim_end = ax.get_ylim()
# 호출 파라미터로 들어온 training 데이타로 model 학습 .
model.fit(X, y)
# meshgrid 형태인 모든 좌표값으로 예측 수행.
xx, yy = np.meshgrid(np.linspace(xlim_start,xlim_end, num=200),np.linspace(ylim_start,ylim_end, num=200))
Z = model.predict(np.c_[xx.ravel(), yy.ravel()]).reshape(xx.shape)
# contourf() 를 이용하여 class boundary 를 visualization 수행.
n_classes = len(np.unique(y))
contours = ax.contourf(xx, yy, Z, alpha=0.3,
levels=np.arange(n_classes + 1) - 0.5,
cmap='rainbow', clim=(y.min(), y.max()),
zorder=1)dt_clf = DecisionTreeClassifier().fit(X_feature, y_labels)
visualize_boundary(dt_clf, X_feature, y_labels)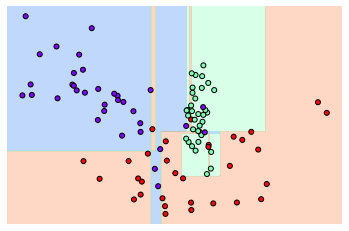
이상치 데이터까지 분류하기 위해 분할이 자주 일어나서 경계가 많아진 것을 알 수 있다. 이렇게되면 지나치게 학습데이터에만 최적화되기에 오히려 테스트 데이터 세트에서 정확도를 떨어뜨릴 수 있다. min_sample_leaf = 6 으로 설정해서 생성 규칙을 완화한 뒤 확인해보자.
dt_clf = DecisionTreeClassifier(min_samples_leaf=6).fit(X_feature, y_labels)
visualize_boundary(dt_clf, X_feature, y_labels)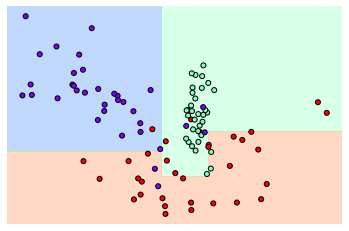
결정 트리 실습 - 사용자 행동 인식
결정 트리를 UCI 머신러닝 레포지토리에서 제공하는 사용자 행동 인식 데이터 세트에 대한 예측 분류를 수행해보자. 해당 데이터는 30명에게 스마트폰 센서를 장착한 뒤 동작에 관련된 여러 피처를 수집한 데이터이다. 아래 링크에서 데이터 셋을 다운받을 수 있다.
http://archive.ics.uci.edu/ml/datasets/Human+Activity+Recognition+Using+Smartphones
import pandas as pd
# features.txt 파일에는 피처 이름 index와 피처명이 공백으로 분리되어 있음
feature_name_df = pd.read_csv('./human_activity/features.txt', sep='\s+', header=None, names=['column_index', 'column_name'])
# 피처명 index를 제거하고, 피처명만 리스트 객체로 생성한 뒤 샘플로 10개만 추출
feature_name = feature_name_df.iloc[:, 1].values.tolist()
print(f'전체 피처명에서 10개만 추출: {feature_name[:10]}')전체 피처명에서 10개만 추출: ['tBodyAcc-mean()-X', 'tBodyAcc-mean()-Y', 'tBodyAcc-mean()-Z', 'tBodyAcc-std()-X', 'tBodyAcc-std()-Y', 'tBodyAcc-std()-Z', 'tBodyAcc-mad()-X', 'tBodyAcc-mad()-Y', 'tBodyAcc-mad()-Z', 'tBodyAcc-max()-X']인체의 움직임과 관련된 속성의 평균/표준편차가 X, Y, Z축 값으로 되어 있다. 현재 features_info.txt 파일에는 중복된 피처명이 있고 이를 그대로 사용하면 오류가 발생한다. 따라서 중복된 피처명이 얼마나 있는지 확인해보자.
feature_dup_df = feature_name_df.groupby('column_name').count()
print(feature_dup_df[feature_dup_df['column_index'] > 1].count())
feature_dup_df[feature_dup_df['column_index'] > 1].head()column_index 42
dtype: int64| column_index | |
|---|---|
| column_name | |
| fBodyAcc-bandsEnergy()-1,16 | 3 |
| fBodyAcc-bandsEnergy()-1,24 | 3 |
| fBodyAcc-bandsEnergy()-1,8 | 3 |
| fBodyAcc-bandsEnergy()-17,24 | 3 |
| fBodyAcc-bandsEnergy()-17,32 | 3 |
42개의 피처명이 중복되므로, 이에 _1, _2 등을 추가하는 함수를 생성한다.
cumcount 는 누적합
def get_new_feature_name_df(old_feature_name_df):
feature_dup_df = pd.DataFrame(data=old_feature_name_df.groupby('column_name').cumcount(),
columns=['dup_cnt'])
feature_dup_df = feature_dup_df.reset_index()
new_feature_name_df = pd.merge(old_feature_name_df.reset_index(), feature_dup_df, how='outer')
new_feature_name_df['column_name'] = new_feature_name_df[['column_name', 'dup_cnt']].apply(lambda x : x[0]+'_'+str(x[1])
if x[1] >0 else x[0] , axis=1)
new_feature_name_df = new_feature_name_df.drop(['index'], axis=1)
return new_feature_name_dfdef get_human_dataset( ):
# 각 데이터 파일들은 공백으로 분리되어 있으므로 read_csv에서 공백 문자를 sep으로 할당.
feature_name_df = pd.read_csv('./human_activity/features.txt',sep='\s+',
header=None,names=['column_index','column_name'])
# 중복된 피처명을 수정하는 get_new_feature_name_df()를 이용, 신규 피처명 DataFrame생성.
new_feature_name_df = get_new_feature_name_df(feature_name_df)
# DataFrame에 피처명을 컬럼으로 부여하기 위해 리스트 객체로 다시 변환
feature_name = new_feature_name_df.iloc[:, 1].values.tolist()
# 학습 피처 데이터 셋과 테스트 피처 데이터을 DataFrame으로 로딩. 컬럼명은 feature_name 적용
X_train = pd.read_csv('./human_activity/train/X_train.txt',sep='\s+', names=feature_name )
X_test = pd.read_csv('./human_activity/test/X_test.txt',sep='\s+', names=feature_name)
# 학습 레이블과 테스트 레이블 데이터을 DataFrame으로 로딩하고 컬럼명은 action으로 부여
y_train = pd.read_csv('./human_activity/train/y_train.txt',sep='\s+',header=None,names=['action'])
y_test = pd.read_csv('./human_activity/test/y_test.txt',sep='\s+',header=None,names=['action'])
# 로드된 학습/테스트용 DataFrame을 모두 반환
return X_train, X_test, y_train, y_test
X_train, X_test, y_train, y_test = get_human_dataset()print(X_train.info())<class 'pandas.core.frame.DataFrame'>
RangeIndex: 7352 entries, 0 to 7351
Columns: 561 entries, tBodyAcc-mean()-X to angle(Z,gravityMean)
dtypes: float64(561)
memory usage: 31.5 MB
None학습 데이터 세트는 7352개의 레코드로 561개의 피처를 가지고 있고 전부 float 형이므로 카테고리 인코딩을 수행하지 않아도 된다.
from sklearn.metrics import accuracy_score
dt_clf = DecisionTreeClassifier(random_state=156)
dt_clf.fit(X_train, y_train)
pred = dt_clf.predict(X_test)
accuracy = accuracy_score(y_test, pred)
print(f'결정 트리 예측 정확도: {np.round(accuracy, 4)}')
print(f'DecisionTreeClassifier 기본 하이퍼 파라미터:\n{dt_clf.get_params()}')결정 트리 예측 정확도: 0.8548
DecisionTreeClassifier 기본 하이퍼 파라미터:
{'ccp_alpha': 0.0, 'class_weight': None, 'criterion': 'gini', 'max_depth': None, 'max_features': None, 'max_leaf_nodes': None, 'min_impurity_decrease': 0.0, 'min_impurity_split': None, 'min_samples_leaf': 1, 'min_samples_split': 2, 'min_weight_fraction_leaf': 0.0, 'presort': 'deprecated', 'random_state': 156, 'splitter': 'best'}85.48%의 정확도를 나타내고 있다.
결정 트리의 트리 깊이가 예측 정확도에 주는 영향을 알아보기 위해 GridSearchCV 를 이용해 max_depth 값을 변화시키면서 확인해 보자.
from sklearn.model_selection import GridSearchCV
params = {'max_depth' : [6, 8, 10, 12, 16, 20, 24]}
grid_cv = GridSearchCV(dt_clf, param_grid=params, scoring='accuracy', cv=5, verbose=1)
grid_cv.fit(X_train, y_train)
print(f'GridSearchCV 최고 평균 정확도 수치: {np.round(grid_cv.best_score_, 4)}')
print(f'GridSearchCV 최적 하이퍼 파라미터: {grid_cv.best_params_}')Fitting 5 folds for each of 7 candidates, totalling 35 fits
[Parallel(n_jobs=1)]: Using backend SequentialBackend with 1 concurrent workers.
[Parallel(n_jobs=1)]: Done 35 out of 35 | elapsed: 1.3min finished
GridSearchCV 최고 평균 정확도 수치: 0.8513
GridSearchCV 최적 하이퍼 파라미터: {'max_depth': 16}max_depth = 16 일때 85.13% 의 정확도를 보였다.
cv_results_df = pd.DataFrame(grid_cv.cv_results_)
cv_results_df[['param_max_depth', 'mean_test_score']]| param_max_depth | mean_test_score | |
|---|---|---|
| 0 | 6 | 0.850791 |
| 1 | 8 | 0.851069 |
| 2 | 10 | 0.851209 |
| 3 | 12 | 0.844135 |
| 4 | 16 | 0.851344 |
| 5 | 20 | 0.850800 |
| 6 | 24 | 0.849440 |
이번에는 별도의 테스트 데이터 세트에서 결정 트리의 정확도를 측정해보자.
max_depths = [6, 8, 10, 12, 16, 20, 24]
for depth in max_depths:
dt_clf = DecisionTreeClassifier(max_depth=depth, random_state=156)
dt_clf.fit(X_train, y_train)
pred = dt_clf.predict(X_test)
accuracy = accuracy_score(y_test, pred)
print('max_depth = {0} 정확도: {1:.4f}'.format(depth, accuracy))max_depth = 6 정확도: 0.8558
max_depth = 8 정확도: 0.8707
max_depth = 10 정확도: 0.8673
max_depth = 12 정확도: 0.8646
max_depth = 16 정확도: 0.8575
max_depth = 20 정확도: 0.8548
max_depth = 24 정확도: 0.8548max_depth = 8 일때 87.07% 의 정확도를 보였고 max_depth 가 커지면서 정확도가 떨어진다.
이번에는 max_depth 와 min_samples_split 을 같이 변경하면서 정확도 성능을 튜닝해보자.
params = {'max_depth': [8, 12, 16, 20],
'min_samples_split': [16, 24]}
grid_cv = GridSearchCV(dt_clf, param_grid=params, scoring='accuracy', cv=5, verbose=1)
grid_cv.fit(X_train, y_train)
print(f'GridSearchCV 최고 평균 정확도 수치: {np.round(grid_cv.best_score_)}')
print(f'GridSearchCV 최적 하이퍼 파라미터: {grid_cv.best_params_}')Fitting 5 folds for each of 8 candidates, totalling 40 fits
[Parallel(n_jobs=1)]: Using backend SequentialBackend with 1 concurrent workers.
[Parallel(n_jobs=1)]: Done 40 out of 40 | elapsed: 1.6min finished
GridSearchCV 최고 평균 정확도 수치: 1.0
GridSearchCV 최적 하이퍼 파라미터: {'max_depth': 8, 'min_samples_split': 16}책이랑 똑같이 썼는데 책은 max_depth: 8, min_samples_split: 16 에서 정확도 85.5% 가 나왔다... 아무리 봐도 내가 뽑아낸 평균 정확도 1.0은 과적합 같은데 일단은 넘어가겠다. (고수님들 알려주세요... 뭐가 문제였는지..) 아래 결정 트리 예측 정확도도 책과 일치하는 87.17% 이다.... 뭐가 잘못된걸까....
best_df_clf = grid_cv.best_estimator_
pred1 = best_df_clf.predict(X_test)
accuracy = accuracy_score(y_test, pred1)
print(f'결정 트리 예측 정확도: {np.round(accuracy, 4)}')결정 트리 예측 정확도: 0.8717ftr_importances_values = best_df_clf.feature_importances_
# Top 중요도로 정렬을 쉽게 하고 Seaborn의 막대 그래프로 쉽게 표현하기 위해 Series 변환
ftr_importances = pd.Series(ftr_importances_values, index=X_train.columns)
# 중요도값 순으로 Series를 정렬
ftr_top20 = ftr_importances.sort_values(ascending=False)[:20]
plt.figure(figsize=(8, 6))
plt.title('Feature Importance Top 20')
sns.barplot(x=ftr_top20, y=ftr_top20.index)<matplotlib.axes._subplots.AxesSubplot at 0x7fba8be6a370>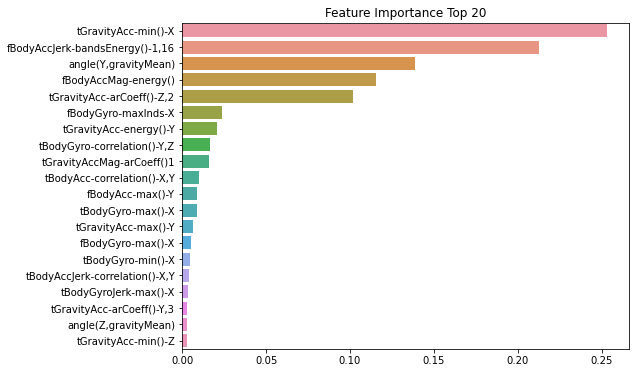
Top 5인 tFravityAcc-min()-X, fBodyAccJerk-bandsEnergy()-1,16, angle(Y,gravityMean), fBodyAccMag-energy(), tGravityAcc-arCoeff()-Z,2 가 매우 중요하게 규칙 생성에 영향을 미치는 것을 알 수 있다.
Source: 파이썬 머신러닝 완벽 가이드 / 위키북스
