앙상블(Ensemble)
앙상블은 여러 개의 분류기를 생성하고 그 예측을 결합함으로써 보다 정확한 최종 예측을 도출하는 기법이다. 앙상블 학습의 유형은 보팅(Voting), 배깅(Bagging), 부스팅(Boosting) 이 있고 이외에도 스태깅을 포함한 다양한 앙상블 방식이 있다.
- 보팅(Voting)
- 배깅(Bagging)
- 부스팅(Boosting)
보팅과 배깅은 여러 개의 분류기가 투표를 통해 최종 예측 결과를 결정하는 방식인데, 차이점은 보팅은 서로 다른 알고리즘을 가진 분류기를 결합하는 것이고, 배깅은 각각의 분류기가 모두 같은 유형의 알고리즘 기반이지만, 데이터 샘플링을 서로 다르게 가져가면서 학습을 수행해 보팅을 수행한다. 대표적인 배깅은 랜덤 포레스트 알고리즘이다.
부스팅은 여러 개의 분류기가 순차적으로 학습을 수행하되, 예측이 틀린 데이터에 대해 올바르게 예측하도록 가중치를 부여하면서 학습과 예측을 진행하는 것이다.
보팅 - Hard vs Soft
하드 보팅(Hard Voting)은 다수결 원칙과 유사하다. 즉, 예측한 결괏값들중 다수의 분류기가 결정한 예측값을 최종 보팅 결괏값으로 선정한다.
소프트 보팅(Soft Voting)은 분류기들의 레이블 값 결정 확률을 모두 더해 이를 평균내서 확률이 가장 높은 레이블 값을 최종 보팅 결괏값을 선정한다.
Hard Voting
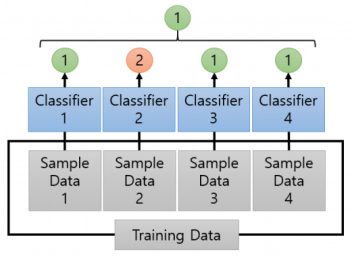
Soft Voting
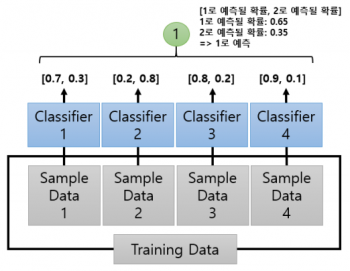
Source: http://itwiki.kr/w/앙상블_기법
보팅 분류기(Voting Classifier)
사이킷런에서 제공하는 Voting Classifier 를 이용해서 위스콘신 유방암 데이터 세트를 예측 분석해보자. 이 데이터 세트는 load_breast_cancer() 함수로 생성할 수 있다. 로지스틱 회귀와 KNN을 기반으로 보팅 분류기를 만들어보자.
import pandas as pd
import numpy as np
from sklearn.ensemble import VotingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import warnings
warnings.filterwarnings('ignore')
cancer = load_breast_cancer()
data_df = pd.DataFrame(cancer.data, columns=cancer.feature_names)
data_df.head(3)| mean radius | mean texture | mean perimeter | mean area | mean smoothness | mean compactness | mean concavity | mean concave points | mean symmetry | mean fractal dimension | ... | worst radius | worst texture | worst perimeter | worst area | worst smoothness | worst compactness | worst concavity | worst concave points | worst symmetry | worst fractal dimension | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 17.99 | 10.38 | 122.8 | 1001.0 | 0.11840 | 0.27760 | 0.3001 | 0.14710 | 0.2419 | 0.07871 | ... | 25.38 | 17.33 | 184.6 | 2019.0 | 0.1622 | 0.6656 | 0.7119 | 0.2654 | 0.4601 | 0.11890 |
| 1 | 20.57 | 17.77 | 132.9 | 1326.0 | 0.08474 | 0.07864 | 0.0869 | 0.07017 | 0.1812 | 0.05667 | ... | 24.99 | 23.41 | 158.8 | 1956.0 | 0.1238 | 0.1866 | 0.2416 | 0.1860 | 0.2750 | 0.08902 |
| 2 | 19.69 | 21.25 | 130.0 | 1203.0 | 0.10960 | 0.15990 | 0.1974 | 0.12790 | 0.2069 | 0.05999 | ... | 23.57 | 25.53 | 152.5 | 1709.0 | 0.1444 | 0.4245 | 0.4504 | 0.2430 | 0.3613 | 0.08758 |
3 rows × 30 columns
lr_clf = LogisticRegression()
knn_clf = KNeighborsClassifier(n_neighbors=8)
vo_clf = VotingClassifier(estimators=[('LR', lr_clf), ('KNN', knn_clf)], voting='soft')
X_train, X_test, y_train, y_test = train_test_split(cancer.data, cancer.target, test_size=0.2, random_state=156)
vo_clf.fit(X_train, y_train)
pred = vo_clf.predict(X_test)
print(f'보팅 분류기 정확도: {np.round(accuracy_score(y_test, pred), 4)}')
classifiers = [lr_clf, knn_clf]
for classifier in classifiers:
classifier.fit(X_train, y_train)
pred = classifier.predict(X_test)
class_name = classifier.__class__.__name__
print('{0} 정확도: {1:.4f}'.format(class_name, accuracy_score(y_test, pred)))보팅 분류기 정확도: 0.9474
LogisticRegression 정확도: 0.9386
KNeighborsClassifier 정확도: 0.9386여기선 보팅 분류기의 정확도가 조금 높게 나타났는데, 보팅으로 여러 개의 분류기를 결합한다고 무조건 분류기보다 예측 성능이 향상되는 것은 아니다.
랜덤 포레스트(Random Forest)
랜덤 포레스트는 여러 개의 결정 트리 분류기가 전체 데이터에서 배깅 방식으로 각자의 데이터를 샘플링해 개별적으로 학습을 수행한 뒤 최종적으로 모든 분류기가 보팅을 통해 예측 결정을 한다.
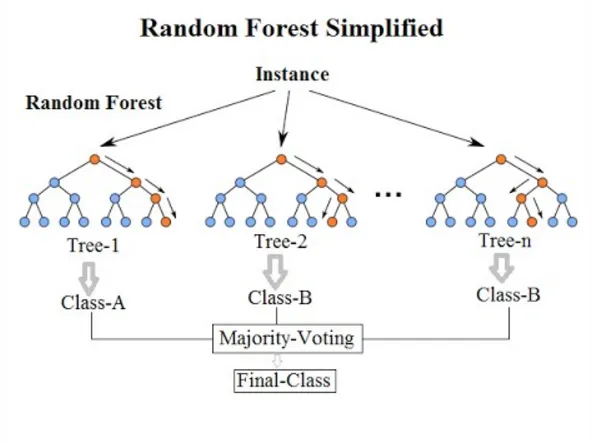
Source: https://hugrypiggykim.com/2019/04/07/bagging-boosting-and-stacking/
랜덤 포레스트에서 전체 데이터에서 일부가 중첩되게 샘플링해서 데이터 세트를 만드는데 이를 부트스트래핑(bootstrapping) 분할 방식이라 한다. 파라미터 n_estimators= 에 넣는 숫자만큼 데이터 세트를 만든다.
from sklearn.ensemble import RandomForestClassifier
rf_clf = RandomForestClassifier(random_state=0)
rf_clf.fit(X_train, y_train)
pred = rf_clf.predict(X_test)
accuracy = accuracy_score(y_test, pred)
print(f'랜덤 포레스트 정확도: {np.round(accuracy, 4)}')랜덤 포레스트 정확도: 0.9561랜덤 포레스트는 위스콘신 유방암 데이터 세트에 대해 약 95.61% 의 정확도를 보여준다.
랜덤 포레스트 하이퍼 파라미터 및 튜닝
- n_estimators: 랜덤 포레스트에서 결정 트리의 갯수를 지정한다. 디폴트는 10개
- max_features: 결정 트리에 사용된 max_features 파라미터와 같지만, RandomForestClassifier의 기본 max_features는 None이 아닌 auto, 즉 sqrt와 같다. 예를 들어 전체 피처가 16개라면 4개 참조
- max_depth 나 min_samples_leaf 와 같이 결정 트리에서 과적합을 개선하기 위해 사용되는 파라미터가 랜덤 포레스트에서도 똑같이 적용될 수 있다.
from sklearn.model_selection import GridSearchCV
params = {'n_estimators': [100],
'max_depth': [6, 8, 10, 12],
'min_samples_leaf': [8, 12, 18],
'min_samples_split': [8, 16, 20]}
# n_jobs=-1 파라미터를 추가하면 모든 CPU 코어를 이용하여 학습할 수 있다.
rf_clf = RandomForestClassifier(random_state=0, n_jobs=-1)
grid_cv = GridSearchCV(rf_clf, param_grid=params, cv=2, n_jobs=-1)
grid_cv.fit(X_train, y_train)
print(f'최적 하이퍼 파라미터:\n{grid_cv.best_params_}')
print(f'최고 예측 정확도:{np.round(grid_cv.best_score_)}')최적 하이퍼 파라미터:
{'max_depth': 6, 'min_samples_leaf': 8, 'min_samples_split': 8, 'n_estimators': 100}
최고 예측 정확도:1.0rf_clf1 = RandomForestClassifier(n_estimators=300, max_depth=6, min_samples_leaf=8, min_samples_split=8, random_state=0)
rf_clf1.fit(X_train, y_train)
pred = rf_clf1.predict(X_test)
print(f'예측 정확도: {np.round(accuracy_score(y_test, pred), 4)}')예측 정확도: 0.9474GMB(Gradient Boosting Machine)
부스팅 알고리즘은 위에서도 언급했듯이 여러 개의 약한 학습기를 순차적으로 학습/예측을 하면서 잘못 예측한 데이터에 가중치를 부여해서 오류를 개선해나가는 학습방식이다. 대표적인 부시팅 알고리즘으로는 AdaBoost 와 그래디언트 부스트 가 있다. 둘의 가장 큰 차이점은 그래디언트 부스트의 가중치 업데이트를 경사 하강법 을 이용해서 한다는 것이다.
from sklearn.ensemble import GradientBoostingClassifier
import time
X_train, X_test, y_train, y_test = train_test_split(cancer.data, cancer.target, test_size=0.2, random_state=156)
start_time = time.time()
gb_clf = GradientBoostingClassifier(random_state=0)
gb_clf.fit(X_train, y_train)
gb_pred = gb_clf.predict(X_test)
gb_accuracy = accuracy_score(y_test, gb_pred)
print(f'GBM 정확도: {np.round(gb_accuracy, 4)}')
print(f'GBM 수행 시간: {np.round((time.time() - start_time), 1)} 초')GBM 정확도: 0.9561
GBM 수행 시간: 0.3 초기본 하이퍼 파라미터만으로도 95.61% 의 예측 정확도로 앞의 랜덤 포레스트(94.74%)보다 더 나은 예측 성능을 보였다. 일반적으로 GBM이 랜덤 포레스트보다는 예측 성능이 뛰어난 경우가 많지만 수행시간이 오래 걸리고, 하이퍼 파라미터 튜닝 노력도 더 필요하다.
원래 책의 예제로는 랜덤 포레스트와 GBM 알고리즘에서 저번에 사용한 사용자 행동 데이터 세트를 예측 분류하는데 내 컴퓨터에 있는 판다스 버전과 책의 버전이 달라 중복된 피처 이름때문에 오류가 나서 간단하게 위스콘신 유방암 데이터를 사용했다. 그러면서 GBM의 수행시간이 0.3초밖에 걸리지 않았다.
GBM 하이퍼 파라미터 및 튜닝
max_depth, max_features 와 같은 트리 기반 자체의 파라미터는 결정 트리, 랜덤 포레스트에서 소개했으므로 생략한다.
- loss: 경사 하강법에서 사용할 비용 함수를 지정한다. 디폴트는 deviance 이고 일반적으로 디폴트를 그대로 사용한다.
- learning_rate: GBM이 학습을 진행할 때마다 적용하는 함수이다. 0~1 사이의 값을 지정할 수 있으며, 디폴트는 0.1이다. 너무 작은 값을 설정하면 예측 성능이 높아지지만 수행 시간이 오래걸린다. 반대로 너무 높은 값을 설정하면 예측 성능이 낮아질 가능성이 높지만 수행 시간이 짧아진다.
- n_estimators: weak learner의 갯수이다. 개수가 많을수록 예측 성능이 일정 수준까지는 좋아지지만 수행시간이 오래걸린다. 디폴트는 100이다.
- subsample: weak learner가 학습에 사용하는 데이터 샘플링 비율이다. 디폴트는 1이고, 예를 들어 0.5로 설정하면 학습데이터의 50%를 기반으로 학습한다는 뜻이다. 과적합이 염려되는 경우 1보다 작은 값으로 설정한다.
params = {'n_estimators': [100, 500],
'learning_rate': [0.05, 0.1]}
grid_cv = GridSearchCV(gb_clf, param_grid=params, cv=2, verbose=1)
grid_cv.fit(X_train, y_train)
print(f'최적 하이퍼 파라미터:\n{grid_cv.best_params_}')
print(f'최고 예측 정확도: {np.round(grid_cv.best_score_, 4)}')Fitting 2 folds for each of 4 candidates, totalling 8 fits
[Parallel(n_jobs=1)]: Using backend SequentialBackend with 1 concurrent workers.
[Parallel(n_jobs=1)]: Done 8 out of 8 | elapsed: 3.8s finished
최적 하이퍼 파라미터:
{'learning_rate': 0.1, 'n_estimators': 500}
최고 예측 정확도: 0.9517learning_rate=0.1, n_estimators=500 일 때 95.17% 의 정확도를 보였다. 이를 테스트 데이터 세트에 적용해보자.
gb_pred = grid_cv.best_estimator_.predict(X_test)
gb_accuracy = accuracy_score(y_test, gb_pred)
print(f'GBM 정확도: {np.round(gb_accuracy, 4)}')GBM 정확도: 0.973797.37%의 높은 정확도가 나왔다.
이번에는 머신러닝 세계에서 가장 각광 받고 있는 두 개의 그래디언트 부스팅 기반 ML 패키지 XGBoost 와 LightGBM에 대해 알아보자.
XGBoost
XGBoost 는 분류에서 일반적으로 다른 머신러닝보다 뛰어난 예측 성능을 보이며 GBM의 단점인 느린 수행 시간과 과적합 규제 부재 등의 문제를 해결해서 각광받고 있는 패키지이다. XGBoost 는 초기의 독자적인 XGBoost 프레임 워크 기반의 XGBoost를 파이썬 래퍼 XGBoost 모듈, 사이킷런과 연동되는 모듈을 사이킷런 래퍼 XGBoost 모듈이 있다. 사이킷런 래퍼 XGBoost 모듈은 사이킷런의 다른 Estimator와 사용법이 같은데, 파이썬 래퍼 XGBoost 모듈은 고유의 API와 하이퍼 파라미터를 사용한다.
파이썬 래퍼 XGBoost 하이퍼 파라미터
-
일반 파라미터: 일반적으로 실행 시 스레드의 개수나 silent 모드 등의 선택을 위한 파라미터, 디폴트 파라미터 값을 바꾸는 경우가 거의 없다.
- booster: gbtree(트리 베이스 모델), gblinear(선형 모델) 중 선택, 디폴트는 gbtree
- silent: 디폴트는 0, 출력 메시지를 나타내고 싶지 않을 때 1로 설정
- nthread: CPU의 실행 스레드 개수를 조정, 디폴트는 CPU의 전체 스레드를 다 사용하는 것
-
주요 부스터 파라미터: 트리 최적화, 부스팅, regularization 등과 관련 파라미터 등을 지칭한다.
- eta[default=0.3, alias: learning_rate]: GBM의 학습률(learning_rate) 와 같은 파라미터로 0-1 사이의 값을 지정하고 부스팅 스텝을 반복적으로 수행할 때 업데이트되는 학습률 값.
- num_boost_rounds: GBM의 n_estimators 와 같은 파라미터
- min_child_weight[default=1]: 트리에서 추가적으로 가지를 나눌지를 결정하기 위해 필요한 데이터의 weight 총합, 값이 클수록 분할을 자제하며 과적합을 조절하기 위해 사용
- gamma[default=0, alias: min_split_loss]: 트리의 리프 노드를 추가로 나눌지를 결정할 최소 손실 감소 값, 해당 값보다 큰 손실이 감소된 경우 리프를 분리하며, 값이 클수록 과적합 감소 효과가 있다.
- max_depth[default=6]: 트리 기반 알고리즘의 max_depth 와 같다. 0을 지정하면 깊이에 제한이 없고, max_depth 가 높으면 특정 피처 조건에 특화되어 과적합 가능성이 높아지므로 3~10 사이의 값을 적용한다.
- sub_sample[default=1]: GBM의 subsample 과 동일하다. 트리가 커져서 과적합되는 것을 제어하기위해 데이터를 샘플링하는 비율을 지정한다. 0에서 1사이의 값이 가능하나 일반적으로 0.5에서 1사이의 값을 사용한다.
- colsample_bytree[default=1]: GBM의 max_features 와 유사하다. 트리 생성에 필요한 피처를 임의로 샘플링 하는데 사용되며, 매우 많은 피처가 있을때 과적합을 조정하는데 적용한다.
- lambda[default=1, alias: reg_lambda]: L2 Regularizaion 적용 값으로, 피처 개수가 많을 경우 적용을 검토하고, 값이 클수록 과적합 감소 효과가 있다.
- alpha[default=0, alias: reg_alpha]: L1 Regularizaion 적용 값으로, 위 lambda 와 동일하다.
- scale_pos_weight[default=1]: 특정 값으로 치우친 비대칭한 클래스로 구성된 데이터 세트의 균형을 유지하기 위한 파라미터이다.
-
학습 태스크 파라미터: 학습 수행시의 객체 함수, 평가를 위한 지표 등을 설정하는 파라미터
- objective: 최솟값을 가져야할 손실 함수를 정의, 이진 분류인지 다중 분류인지에 따라 달라짐.
- binary:logistic: 이진 분류일 때 적용
- multi:softmax: 다중 분류일 때 적용, 손실 함수가 multi:softmax 면 레이블 클래스의 개수인 num_class 파라미터를 지정해야한다.
- multi:softprob: multi:softmax 와 유사하나 개별 레이블 클래스의 해당하는 예측 확률을 반환한다.
- eval_metric: 검증에 사용되는 함수를 정의하며, 기본값은 회귀인 경우 rmse, 분류는 error 이다.
- rmse: Root Mean Square Error
- mae: Mean Absolute Error
- logloss: Negative log-likelihood
- error: Binary classification error rate(0.5 threshold)
- merror: Multiclass classification error rate
- mlogloss: Multiclass logloss
- auc: Area under the curve
만약 과적합 문제가 심각하다면 아래를 고려해 볼 수 있다.
- eta 값 낮추기 + num_round(또는 n_estimators) 높이기
- max_depth 값 낮추기
- min_child_weight 값 높이기
- gamma 값 높이기
- subsample, colsample_bytree 값 조정하기
파이썬 래퍼 XGBoost로 위스콘신 유방암 예측
import xgboost as xgb
from xgboost import plot_importance
dataset = load_breast_cancer()
X_features = dataset.data
y_label = dataset.target
cancer_df = pd.DataFrame(data=X_features, columns=dataset.feature_names)
cancer_df['target'] = y_label
cancer_df.head(3)| mean radius | mean texture | mean perimeter | mean area | mean smoothness | mean compactness | mean concavity | mean concave points | mean symmetry | mean fractal dimension | ... | worst texture | worst perimeter | worst area | worst smoothness | worst compactness | worst concavity | worst concave points | worst symmetry | worst fractal dimension | target | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 17.99 | 10.38 | 122.8 | 1001.0 | 0.11840 | 0.27760 | 0.3001 | 0.14710 | 0.2419 | 0.07871 | ... | 17.33 | 184.6 | 2019.0 | 0.1622 | 0.6656 | 0.7119 | 0.2654 | 0.4601 | 0.11890 | 0 |
| 1 | 20.57 | 17.77 | 132.9 | 1326.0 | 0.08474 | 0.07864 | 0.0869 | 0.07017 | 0.1812 | 0.05667 | ... | 23.41 | 158.8 | 1956.0 | 0.1238 | 0.1866 | 0.2416 | 0.1860 | 0.2750 | 0.08902 | 0 |
| 2 | 19.69 | 21.25 | 130.0 | 1203.0 | 0.10960 | 0.15990 | 0.1974 | 0.12790 | 0.2069 | 0.05999 | ... | 25.53 | 152.5 | 1709.0 | 0.1444 | 0.4245 | 0.4504 | 0.2430 | 0.3613 | 0.08758 | 0 |
3 rows × 31 columns
종양의 크기와 모양에 관련된 피처가 숫자형 값으로 되어 있고, target이 0이면 악성인 malignant, target이 1이면 양성인 benign이다.
print(dataset.target_names)
print(cancer_df['target'].value_counts())['malignant' 'benign']
1 357
0 212
Name: target, dtype: int64X_train, X_test, y_train, y_test = train_test_split(X_features, y_label, test_size=0.2, random_state=156)
print(X_train.shape, X_test.shape)(455, 30) (114, 30)파이썬 래퍼 XGBoost와 사이킷런의 차이는 학습용과 테스트용 데이터 세트를 위해 별도의 객체인 DMatrix 를 생성한다는 것이다.
dtrain = xgb.DMatrix(data=X_train, label=y_train)
dtest = xgb.DMatrix(data=X_test, label=y_test)트리 최대 깊이=3, 학습률=0.1, 이진 로지스틱, 오류 함수의 평가 성능 지표=logloss, 예측 오류가 개선되지 않으면 조기 중단 실행=100, 부스팅 반복 횟수=400 으로 파라미터 설정
params = {'max_depth': 3,
'eta': 0.1,
'objective': 'binary:logistic',
'eval_metric': 'logloss',
'early_stoppings': 100}
num_rounds = 400# train 데이터 세트는 train, test 데이터 세트는 eval로 표기
wlist = [(dtrain, 'train'), (dtest, 'eval')]
xgb_model = xgb.train(params=params, dtrain=dtrain, num_boost_round=num_rounds, early_stopping_rounds=100, evals=wlist)[0] train-logloss:0.60969 eval-logloss:0.61352
[1] train-logloss:0.54080 eval-logloss:0.54784
[2] train-logloss:0.48375 eval-logloss:0.49425
[3] train-logloss:0.43446 eval-logloss:0.44799
[4] train-logloss:0.39055 eval-logloss:0.40911
[5] train-logloss:0.35414 eval-logloss:0.37498
[6] train-logloss:0.32122 eval-logloss:0.34571
[7] train-logloss:0.29259 eval-logloss:0.32053
[8] train-logloss:0.26747 eval-logloss:0.29721
[9] train-logloss:0.24515 eval-logloss:0.27799
[10] train-logloss:0.22569 eval-logloss:0.26030
[11] train-logloss:0.20794 eval-logloss:0.24604
[12] train-logloss:0.19218 eval-logloss:0.23156
[13] train-logloss:0.17792 eval-logloss:0.22005
[14] train-logloss:0.16522 eval-logloss:0.20857
[15] train-logloss:0.15362 eval-logloss:0.19999
[16] train-logloss:0.14333 eval-logloss:0.19012
[17] train-logloss:0.13398 eval-logloss:0.18182
[18] train-logloss:0.12560 eval-logloss:0.17473
[19] train-logloss:0.11729 eval-logloss:0.16766
[20] train-logloss:0.10969 eval-logloss:0.15820
[21] train-logloss:0.10297 eval-logloss:0.15473
[22] train-logloss:0.09707 eval-logloss:0.14895
[23] train-logloss:0.09143 eval-logloss:0.14331
[24] train-logloss:0.08633 eval-logloss:0.13634
[25] train-logloss:0.08131 eval-logloss:0.13278
[26] train-logloss:0.07686 eval-logloss:0.12791
[27] train-logloss:0.07284 eval-logloss:0.12526
[28] train-logloss:0.06925 eval-logloss:0.11998
[29] train-logloss:0.06555 eval-logloss:0.11641
[30] train-logloss:0.06241 eval-logloss:0.11450
[31] train-logloss:0.05959 eval-logloss:0.11257
[32] train-logloss:0.05710 eval-logloss:0.11154
[33] train-logloss:0.05441 eval-logloss:0.10868
[34] train-logloss:0.05204 eval-logloss:0.10668
[35] train-logloss:0.04975 eval-logloss:0.10421
[36] train-logloss:0.04775 eval-logloss:0.10296
[37] train-logloss:0.04585 eval-logloss:0.10058
[38] train-logloss:0.04401 eval-logloss:0.09868
[39] train-logloss:0.04226 eval-logloss:0.09644
[40] train-logloss:0.04065 eval-logloss:0.09587
[41] train-logloss:0.03913 eval-logloss:0.09424
[42] train-logloss:0.03738 eval-logloss:0.09471
[43] train-logloss:0.03611 eval-logloss:0.09427
[44] train-logloss:0.03494 eval-logloss:0.09389
[45] train-logloss:0.03365 eval-logloss:0.09418
[46] train-logloss:0.03253 eval-logloss:0.09402
[47] train-logloss:0.03148 eval-logloss:0.09236
[48] train-logloss:0.03039 eval-logloss:0.09301
[49] train-logloss:0.02947 eval-logloss:0.09127
[50] train-logloss:0.02855 eval-logloss:0.09005
[51] train-logloss:0.02753 eval-logloss:0.08961
[52] train-logloss:0.02655 eval-logloss:0.08958
[53] train-logloss:0.02568 eval-logloss:0.09070
[54] train-logloss:0.02500 eval-logloss:0.08958
[55] train-logloss:0.02430 eval-logloss:0.09036
[56] train-logloss:0.02357 eval-logloss:0.09159
[57] train-logloss:0.02296 eval-logloss:0.09153
[58] train-logloss:0.02249 eval-logloss:0.09199
[59] train-logloss:0.02185 eval-logloss:0.09195
[60] train-logloss:0.02132 eval-logloss:0.09194
[61] train-logloss:0.02079 eval-logloss:0.09146
[62] train-logloss:0.02022 eval-logloss:0.09031
[63] train-logloss:0.01970 eval-logloss:0.08941
[64] train-logloss:0.01918 eval-logloss:0.08972
[65] train-logloss:0.01872 eval-logloss:0.08974
[66] train-logloss:0.01833 eval-logloss:0.08962
[67] train-logloss:0.01787 eval-logloss:0.08873
[68] train-logloss:0.01760 eval-logloss:0.08862
[69] train-logloss:0.01724 eval-logloss:0.08974
[70] train-logloss:0.01688 eval-logloss:0.08998
[71] train-logloss:0.01664 eval-logloss:0.08978
[72] train-logloss:0.01629 eval-logloss:0.08958
[73] train-logloss:0.01598 eval-logloss:0.08953
[74] train-logloss:0.01566 eval-logloss:0.08875
[75] train-logloss:0.01539 eval-logloss:0.08860
[76] train-logloss:0.01515 eval-logloss:0.08812
[77] train-logloss:0.01488 eval-logloss:0.08840
[78] train-logloss:0.01464 eval-logloss:0.08874
[79] train-logloss:0.01449 eval-logloss:0.08815
[80] train-logloss:0.01418 eval-logloss:0.08758
[81] train-logloss:0.01401 eval-logloss:0.08741
[82] train-logloss:0.01377 eval-logloss:0.08849
[83] train-logloss:0.01357 eval-logloss:0.08858
[84] train-logloss:0.01341 eval-logloss:0.08807
[85] train-logloss:0.01325 eval-logloss:0.08764
[86] train-logloss:0.01311 eval-logloss:0.08742
[87] train-logloss:0.01293 eval-logloss:0.08761
[88] train-logloss:0.01271 eval-logloss:0.08707
[89] train-logloss:0.01254 eval-logloss:0.08727
[90] train-logloss:0.01235 eval-logloss:0.08716
[91] train-logloss:0.01223 eval-logloss:0.08696
[92] train-logloss:0.01206 eval-logloss:0.08717
[93] train-logloss:0.01193 eval-logloss:0.08707
[94] train-logloss:0.01182 eval-logloss:0.08659
[95] train-logloss:0.01165 eval-logloss:0.08612
[96] train-logloss:0.01148 eval-logloss:0.08714
[97] train-logloss:0.01136 eval-logloss:0.08677
[98] train-logloss:0.01124 eval-logloss:0.08669
[99] train-logloss:0.01113 eval-logloss:0.08655
[100] train-logloss:0.01100 eval-logloss:0.08650
[101] train-logloss:0.01085 eval-logloss:0.08641
[102] train-logloss:0.01076 eval-logloss:0.08629
[103] train-logloss:0.01064 eval-logloss:0.08626
[104] train-logloss:0.01050 eval-logloss:0.08683
[105] train-logloss:0.01039 eval-logloss:0.08677
[106] train-logloss:0.01030 eval-logloss:0.08732
[107] train-logloss:0.01020 eval-logloss:0.08730
[108] train-logloss:0.01007 eval-logloss:0.08728
[109] train-logloss:0.01000 eval-logloss:0.08730
[110] train-logloss:0.00991 eval-logloss:0.08729
[111] train-logloss:0.00980 eval-logloss:0.08800
[112] train-logloss:0.00971 eval-logloss:0.08794
[113] train-logloss:0.00963 eval-logloss:0.08784
[114] train-logloss:0.00956 eval-logloss:0.08807
[115] train-logloss:0.00948 eval-logloss:0.08765
[116] train-logloss:0.00942 eval-logloss:0.08730
[117] train-logloss:0.00931 eval-logloss:0.08780
[118] train-logloss:0.00923 eval-logloss:0.08775
[119] train-logloss:0.00915 eval-logloss:0.08768
[120] train-logloss:0.00912 eval-logloss:0.08763
[121] train-logloss:0.00902 eval-logloss:0.08757
[122] train-logloss:0.00897 eval-logloss:0.08755
[123] train-logloss:0.00890 eval-logloss:0.08716
[124] train-logloss:0.00884 eval-logloss:0.08767
[125] train-logloss:0.00880 eval-logloss:0.08774
[126] train-logloss:0.00871 eval-logloss:0.08828
[127] train-logloss:0.00864 eval-logloss:0.08831
[128] train-logloss:0.00861 eval-logloss:0.08827
[129] train-logloss:0.00856 eval-logloss:0.08789
[130] train-logloss:0.00846 eval-logloss:0.08886
[131] train-logloss:0.00842 eval-logloss:0.08868
[132] train-logloss:0.00839 eval-logloss:0.08874
[133] train-logloss:0.00830 eval-logloss:0.08922
[134] train-logloss:0.00827 eval-logloss:0.08918
[135] train-logloss:0.00822 eval-logloss:0.08882
[136] train-logloss:0.00816 eval-logloss:0.08851
[137] train-logloss:0.00808 eval-logloss:0.08848
[138] train-logloss:0.00805 eval-logloss:0.08839
[139] train-logloss:0.00797 eval-logloss:0.08915
[140] train-logloss:0.00795 eval-logloss:0.08911
[141] train-logloss:0.00790 eval-logloss:0.08876
[142] train-logloss:0.00787 eval-logloss:0.08868
[143] train-logloss:0.00785 eval-logloss:0.08839
[144] train-logloss:0.00778 eval-logloss:0.08927
[145] train-logloss:0.00775 eval-logloss:0.08924
[146] train-logloss:0.00773 eval-logloss:0.08914
[147] train-logloss:0.00769 eval-logloss:0.08891
[148] train-logloss:0.00762 eval-logloss:0.08942
[149] train-logloss:0.00760 eval-logloss:0.08939
[150] train-logloss:0.00758 eval-logloss:0.08911
[151] train-logloss:0.00752 eval-logloss:0.08873
[152] train-logloss:0.00750 eval-logloss:0.08872
[153] train-logloss:0.00746 eval-logloss:0.08848
[154] train-logloss:0.00741 eval-logloss:0.08847
[155] train-logloss:0.00739 eval-logloss:0.08854
[156] train-logloss:0.00737 eval-logloss:0.08852
[157] train-logloss:0.00734 eval-logloss:0.08855
[158] train-logloss:0.00732 eval-logloss:0.08828
[159] train-logloss:0.00730 eval-logloss:0.08830
[160] train-logloss:0.00728 eval-logloss:0.08828
[161] train-logloss:0.00726 eval-logloss:0.08801
[162] train-logloss:0.00724 eval-logloss:0.08776
[163] train-logloss:0.00722 eval-logloss:0.08778
[164] train-logloss:0.00720 eval-logloss:0.08778
[165] train-logloss:0.00718 eval-logloss:0.08752
[166] train-logloss:0.00716 eval-logloss:0.08754
[167] train-logloss:0.00714 eval-logloss:0.08764
[168] train-logloss:0.00712 eval-logloss:0.08739
[169] train-logloss:0.00710 eval-logloss:0.08738
[170] train-logloss:0.00708 eval-logloss:0.08730
[171] train-logloss:0.00707 eval-logloss:0.08737
[172] train-logloss:0.00705 eval-logloss:0.08740
[173] train-logloss:0.00703 eval-logloss:0.08739
[174] train-logloss:0.00701 eval-logloss:0.08713
[175] train-logloss:0.00699 eval-logloss:0.08716
[176] train-logloss:0.00697 eval-logloss:0.08696
[177] train-logloss:0.00696 eval-logloss:0.08705
[178] train-logloss:0.00694 eval-logloss:0.08697
[179] train-logloss:0.00692 eval-logloss:0.08697
[180] train-logloss:0.00690 eval-logloss:0.08704
[181] train-logloss:0.00688 eval-logloss:0.08680
[182] train-logloss:0.00687 eval-logloss:0.08683
[183] train-logloss:0.00685 eval-logloss:0.08658
[184] train-logloss:0.00683 eval-logloss:0.08659
[185] train-logloss:0.00681 eval-logloss:0.08661
[186] train-logloss:0.00680 eval-logloss:0.08637
[187] train-logloss:0.00678 eval-logloss:0.08637
[188] train-logloss:0.00676 eval-logloss:0.08630
[189] train-logloss:0.00675 eval-logloss:0.08610
[190] train-logloss:0.00673 eval-logloss:0.08602
[191] train-logloss:0.00671 eval-logloss:0.08605
[192] train-logloss:0.00670 eval-logloss:0.08615
[193] train-logloss:0.00668 eval-logloss:0.08592
[194] train-logloss:0.00667 eval-logloss:0.08592
[195] train-logloss:0.00665 eval-logloss:0.08598
[196] train-logloss:0.00663 eval-logloss:0.08601
[197] train-logloss:0.00662 eval-logloss:0.08592
[198] train-logloss:0.00660 eval-logloss:0.08585
[199] train-logloss:0.00659 eval-logloss:0.08587
[200] train-logloss:0.00657 eval-logloss:0.08589
[201] train-logloss:0.00656 eval-logloss:0.08595
[202] train-logloss:0.00654 eval-logloss:0.08573
[203] train-logloss:0.00653 eval-logloss:0.08573
[204] train-logloss:0.00651 eval-logloss:0.08575
[205] train-logloss:0.00650 eval-logloss:0.08582
[206] train-logloss:0.00648 eval-logloss:0.08584
[207] train-logloss:0.00647 eval-logloss:0.08578
[208] train-logloss:0.00645 eval-logloss:0.08569
[209] train-logloss:0.00644 eval-logloss:0.08571
[210] train-logloss:0.00643 eval-logloss:0.08581
[211] train-logloss:0.00641 eval-logloss:0.08559
[212] train-logloss:0.00640 eval-logloss:0.08580
[213] train-logloss:0.00639 eval-logloss:0.08581
[214] train-logloss:0.00637 eval-logloss:0.08574
[215] train-logloss:0.00636 eval-logloss:0.08566
[216] train-logloss:0.00634 eval-logloss:0.08584
[217] train-logloss:0.00633 eval-logloss:0.08563
[218] train-logloss:0.00632 eval-logloss:0.08573
[219] train-logloss:0.00631 eval-logloss:0.08578
[220] train-logloss:0.00629 eval-logloss:0.08579
[221] train-logloss:0.00628 eval-logloss:0.08582
[222] train-logloss:0.00627 eval-logloss:0.08576
[223] train-logloss:0.00626 eval-logloss:0.08567
[224] train-logloss:0.00624 eval-logloss:0.08586
[225] train-logloss:0.00623 eval-logloss:0.08587
[226] train-logloss:0.00622 eval-logloss:0.08593
[227] train-logloss:0.00621 eval-logloss:0.08595
[228] train-logloss:0.00619 eval-logloss:0.08587
[229] train-logloss:0.00618 eval-logloss:0.08606
[230] train-logloss:0.00617 eval-logloss:0.08600
[231] train-logloss:0.00616 eval-logloss:0.08592
[232] train-logloss:0.00615 eval-logloss:0.08610
[233] train-logloss:0.00613 eval-logloss:0.08611
[234] train-logloss:0.00612 eval-logloss:0.08617
[235] train-logloss:0.00611 eval-logloss:0.08626
[236] train-logloss:0.00610 eval-logloss:0.08629
[237] train-logloss:0.00609 eval-logloss:0.08622
[238] train-logloss:0.00608 eval-logloss:0.08639
[239] train-logloss:0.00607 eval-logloss:0.08634
[240] train-logloss:0.00606 eval-logloss:0.08618
[241] train-logloss:0.00605 eval-logloss:0.08619
[242] train-logloss:0.00604 eval-logloss:0.08625
[243] train-logloss:0.00602 eval-logloss:0.08626
[244] train-logloss:0.00601 eval-logloss:0.08629
[245] train-logloss:0.00600 eval-logloss:0.08622
[246] train-logloss:0.00599 eval-logloss:0.08640
[247] train-logloss:0.00598 eval-logloss:0.08635
[248] train-logloss:0.00597 eval-logloss:0.08628
[249] train-logloss:0.00596 eval-logloss:0.08645
[250] train-logloss:0.00595 eval-logloss:0.08629
[251] train-logloss:0.00594 eval-logloss:0.08631
[252] train-logloss:0.00593 eval-logloss:0.08636
[253] train-logloss:0.00592 eval-logloss:0.08639
[254] train-logloss:0.00591 eval-logloss:0.08649
[255] train-logloss:0.00590 eval-logloss:0.08644
[256] train-logloss:0.00589 eval-logloss:0.08629
[257] train-logloss:0.00588 eval-logloss:0.08646
[258] train-logloss:0.00587 eval-logloss:0.08639
[259] train-logloss:0.00586 eval-logloss:0.08644
[260] train-logloss:0.00585 eval-logloss:0.08646
[261] train-logloss:0.00585 eval-logloss:0.08649
[262] train-logloss:0.00584 eval-logloss:0.08644
[263] train-logloss:0.00583 eval-logloss:0.08647
[264] train-logloss:0.00582 eval-logloss:0.08632
[265] train-logloss:0.00581 eval-logloss:0.08649
[266] train-logloss:0.00580 eval-logloss:0.08654
[267] train-logloss:0.00579 eval-logloss:0.08647
[268] train-logloss:0.00578 eval-logloss:0.08650
[269] train-logloss:0.00577 eval-logloss:0.08652
[270] train-logloss:0.00576 eval-logloss:0.08669
[271] train-logloss:0.00575 eval-logloss:0.08674
[272] train-logloss:0.00575 eval-logloss:0.08683
[273] train-logloss:0.00574 eval-logloss:0.08668
[274] train-logloss:0.00573 eval-logloss:0.08664
[275] train-logloss:0.00572 eval-logloss:0.08650
[276] train-logloss:0.00571 eval-logloss:0.08636
[277] train-logloss:0.00570 eval-logloss:0.08652
[278] train-logloss:0.00570 eval-logloss:0.08657
[279] train-logloss:0.00569 eval-logloss:0.08659
[280] train-logloss:0.00568 eval-logloss:0.08668
[281] train-logloss:0.00567 eval-logloss:0.08664
[282] train-logloss:0.00566 eval-logloss:0.08650
[283] train-logloss:0.00566 eval-logloss:0.08636
[284] train-logloss:0.00565 eval-logloss:0.08640
[285] train-logloss:0.00564 eval-logloss:0.08643
[286] train-logloss:0.00563 eval-logloss:0.08646
[287] train-logloss:0.00562 eval-logloss:0.08650
[288] train-logloss:0.00562 eval-logloss:0.08637
[289] train-logloss:0.00561 eval-logloss:0.08646
[290] train-logloss:0.00560 eval-logloss:0.08645
[291] train-logloss:0.00559 eval-logloss:0.08632
[292] train-logloss:0.00558 eval-logloss:0.08628
[293] train-logloss:0.00558 eval-logloss:0.08615
[294] train-logloss:0.00557 eval-logloss:0.08620
[295] train-logloss:0.00556 eval-logloss:0.08622
[296] train-logloss:0.00556 eval-logloss:0.08631
[297] train-logloss:0.00555 eval-logloss:0.08618
[298] train-logloss:0.00554 eval-logloss:0.08626
[299] train-logloss:0.00553 eval-logloss:0.08613
[300] train-logloss:0.00553 eval-logloss:0.08618
[301] train-logloss:0.00552 eval-logloss:0.08605
[302] train-logloss:0.00551 eval-logloss:0.08602
[303] train-logloss:0.00551 eval-logloss:0.08610
[304] train-logloss:0.00550 eval-logloss:0.08598
[305] train-logloss:0.00549 eval-logloss:0.08606
[306] train-logloss:0.00548 eval-logloss:0.08597
[307] train-logloss:0.00548 eval-logloss:0.08600
[308] train-logloss:0.00547 eval-logloss:0.08600
[309] train-logloss:0.00546 eval-logloss:0.08588
[310] train-logloss:0.00546 eval-logloss:0.08592
[311] train-logloss:0.00545 eval-logloss:0.08595학습하면서 train-error 와 eval-logloss 가 지속적으로 감소한다.
예측을 위해 predict() 메서드를 사용하는데 여기서 사이킷런의 메서드와 차이가 있다. 사이킷런의 메서드는 0, 1을 반환하는데 xgboost의 predict() 는 확률 값을 반환한다. 이진 분류 문제이므로 예측 확률이 0.5보다 크면 1, 작으면 0으로 결정하는 로직을 추가하면 된다.
pred_probs = xgb_model.predict(dtest)
print('predict() 수행 결과값을 10개만 표시')
print(np.round(pred_probs[:10], 3))
preds = [1 if x > 0.5 else 0 for x in pred_probs]
print(f'예측값 10개만 표시: {preds[:10]}')predict() 수행 결과값을 10개만 표시
[0.934 0.003 0.91 0.094 0.993 1. 1. 0.999 0.997 0. ]
예측값 10개만 표시: [1, 0, 1, 0, 1, 1, 1, 1, 1, 0]# 저번에 생성한 get_clf_eval() 함수
def get_clf_eval(y_test, pred=None, pred_proba=None):
confusion = confusion_matrix(y_test, pred)
accuracy = accuracy_score(y_test, pred)
precision = precision_score(y_test, pred)
recall = recall_score(y_test, pred)
f1 = f1_score(y_test, pred)
roc_auc = roc_auc_score(y_test, pred)
print('오차행렬')
print(confusion)
print('정확도: {0:.4f}, 정밀도: {1:.4f}, 재현율: {2:.4f}, F1: {3:.4f}, AUC:{4:.4f}'
.format(accuracy, precision, recall, f1, roc_auc))from sklearn.metrics import accuracy_score, precision_score, recall_score, roc_auc_score
from sklearn.metrics import f1_score, confusion_matrix, precision_recall_curve, roc_curve
get_clf_eval(y_test, preds, pred_probs)오차행렬
[[35 2]
[ 1 76]]
정확도: 0.9737, 정밀도: 0.9744, 재현율: 0.9870, F1: 0.9806, AUC:0.9665xgboost의 plot_importance() API는 피처의 중요도를 막대 그래프 형식으로 나타내며, 기본 평가 지표로 f1 스코어 를 기반으로 한다. 이 API는 xgboost 넘파이 기반의 피처 데이터로 학습 시에 피처명을 제대로 알 수 없다.(eg. f0은 첫 번째 피처, f1은 두 번째 피처)
import matplotlib.pyplot as plt
%matplotlib inline
fig, ax = plt.subplots(figsize=(10, 12))
plot_importance(xgb_model, ax=ax)<matplotlib.axes._subplots.AxesSubplot at 0x7fa35b413e20>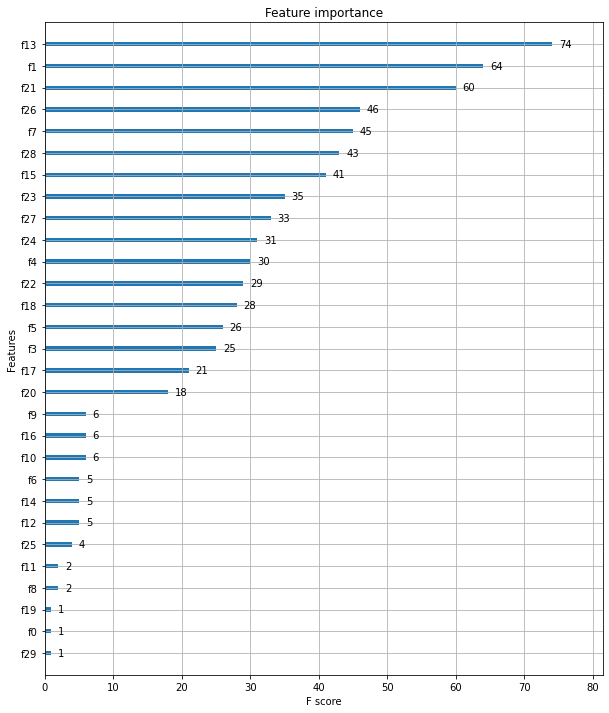
사이킷런 래퍼 XGBoost로 위스콘신 유방암 예측
사실 사이킷런 전용의 XGBoost를 앞으로 더 사용할 거 같다. 파이썬 래퍼 XGBoost와 사이킷런 래퍼 XGBoost는 파라미터 부분에서 약간의 차이가 있다.
- eta -> learning_rate
- sub_sample -> subsample
- lambda -> reg_lambda
- alpha -> reg_alpha
하이퍼 파라미터를 앞에서와 동일하게 설정하고 학습과 예측을 수행해보자.
from xgboost import XGBClassifier
xgb_wrapper = XGBClassifier(n_estimators=400, learning_rate=0.1, max_depth=3)
xgb_wrapper.fit(X_train, y_train)
w_preds = xgb_wrapper.predict(X_test)
w_pred_proba = xgb_wrapper.predict_proba(X_test)[:, 1][15:18:04] WARNING: /Users/travis/build/dmlc/xgboost/src/learner.cc:1061: Starting in XGBoost 1.3.0, the default evaluation metric used with the objective 'binary:logistic' was changed from 'error' to 'logloss'. Explicitly set eval_metric if you'd like to restore the old behavior.get_clf_eval(y_test, w_preds, w_pred_proba)오차행렬
[[35 2]
[ 1 76]]
정확도: 0.9737, 정밀도: 0.9744, 재현율: 0.9870, F1: 0.9806, AUC:0.9665위에서와 동일한 결과가 나옴을 알 수 있다.
데이터 세트의 크기가 작아 테스트 데이터를 평가용으로 사용해서 확인해보자. 사실 이 방법은 평가에 테스트 데이터 세트를 사용하면 학습 시에 미리 참고하게 되어 과적합할 수 있어서 바람직한 부분은 아니다.
evals = [(X_test, y_test)]
xgb_wrapper.fit(X_train, y_train, early_stopping_rounds=100, eval_metric="logloss", eval_set=evals, verbose=True)
ws100_preds = xgb_wrapper.predict(X_test)
ws100_pred_proba = xgb_wrapper.predict_proba(X_test)[:, 1][0] validation_0-logloss:0.61352
[1] validation_0-logloss:0.54784
[2] validation_0-logloss:0.49425
[3] validation_0-logloss:0.44799
[4] validation_0-logloss:0.40911
[5] validation_0-logloss:0.37498
[6] validation_0-logloss:0.34571
[7] validation_0-logloss:0.32053
[8] validation_0-logloss:0.29721
[9] validation_0-logloss:0.27799
[10] validation_0-logloss:0.26030
[11] validation_0-logloss:0.24604
[12] validation_0-logloss:0.23156
[13] validation_0-logloss:0.22005
[14] validation_0-logloss:0.20857
[15] validation_0-logloss:0.19999
[16] validation_0-logloss:0.19012
[17] validation_0-logloss:0.18182
[18] validation_0-logloss:0.17473
[19] validation_0-logloss:0.16766
[20] validation_0-logloss:0.15820
[21] validation_0-logloss:0.15473
[22] validation_0-logloss:0.14895
[23] validation_0-logloss:0.14331
[24] validation_0-logloss:0.13634
[25] validation_0-logloss:0.13278
[26] validation_0-logloss:0.12791
[27] validation_0-logloss:0.12526
[28] validation_0-logloss:0.11998
[29] validation_0-logloss:0.11641
[30] validation_0-logloss:0.11450
[31] validation_0-logloss:0.11257
[32] validation_0-logloss:0.11154
[33] validation_0-logloss:0.10868
[34] validation_0-logloss:0.10668
[35] validation_0-logloss:0.10421
[36] validation_0-logloss:0.10296
[37] validation_0-logloss:0.10058
[38] validation_0-logloss:0.09868
[39] validation_0-logloss:0.09644
[40] validation_0-logloss:0.09587
[41] validation_0-logloss:0.09424
[42] validation_0-logloss:0.09471
[43] validation_0-logloss:0.09427
[44] validation_0-logloss:0.09389
[45] validation_0-logloss:0.09418
[46] validation_0-logloss:0.09402
[47] validation_0-logloss:0.09236
[48] validation_0-logloss:0.09301
[49] validation_0-logloss:0.09127
[50] validation_0-logloss:0.09005
[51] validation_0-logloss:0.08961
[52] validation_0-logloss:0.08958
[53] validation_0-logloss:0.09070
[54] validation_0-logloss:0.08958
[55] validation_0-logloss:0.09036
[56] validation_0-logloss:0.09159
[57] validation_0-logloss:0.09153
[58] validation_0-logloss:0.09199
[59] validation_0-logloss:0.09195
[60] validation_0-logloss:0.09194
[61] validation_0-logloss:0.09146
[62] validation_0-logloss:0.09031
[63] validation_0-logloss:0.08941
[64] validation_0-logloss:0.08972
[65] validation_0-logloss:0.08974
[66] validation_0-logloss:0.08962
[67] validation_0-logloss:0.08873
[68] validation_0-logloss:0.08862
[69] validation_0-logloss:0.08974
[70] validation_0-logloss:0.08998
[71] validation_0-logloss:0.08978
[72] validation_0-logloss:0.08958
[73] validation_0-logloss:0.08953
[74] validation_0-logloss:0.08875
[75] validation_0-logloss:0.08860
[76] validation_0-logloss:0.08812
[77] validation_0-logloss:0.08840
[78] validation_0-logloss:0.08874
[79] validation_0-logloss:0.08815
[80] validation_0-logloss:0.08758
[81] validation_0-logloss:0.08741
[82] validation_0-logloss:0.08849
[83] validation_0-logloss:0.08858
[84] validation_0-logloss:0.08807
[85] validation_0-logloss:0.08764
[86] validation_0-logloss:0.08742
[87] validation_0-logloss:0.08761
[88] validation_0-logloss:0.08707
[89] validation_0-logloss:0.08727
[90] validation_0-logloss:0.08716
[91] validation_0-logloss:0.08696
[92] validation_0-logloss:0.08717
[93] validation_0-logloss:0.08707
[94] validation_0-logloss:0.08659
[95] validation_0-logloss:0.08612
[96] validation_0-logloss:0.08714
[97] validation_0-logloss:0.08677
[98] validation_0-logloss:0.08669
[99] validation_0-logloss:0.08655
[100] validation_0-logloss:0.08650
[101] validation_0-logloss:0.08641
[102] validation_0-logloss:0.08629
[103] validation_0-logloss:0.08626
[104] validation_0-logloss:0.08683
[105] validation_0-logloss:0.08677
[106] validation_0-logloss:0.08732
[107] validation_0-logloss:0.08730
[108] validation_0-logloss:0.08728
[109] validation_0-logloss:0.08730
[110] validation_0-logloss:0.08729
[111] validation_0-logloss:0.08800
[112] validation_0-logloss:0.08794
[113] validation_0-logloss:0.08784
[114] validation_0-logloss:0.08807
[115] validation_0-logloss:0.08765
[116] validation_0-logloss:0.08730
[117] validation_0-logloss:0.08780
[118] validation_0-logloss:0.08775
[119] validation_0-logloss:0.08768
[120] validation_0-logloss:0.08763
[121] validation_0-logloss:0.08757
[122] validation_0-logloss:0.08755
[123] validation_0-logloss:0.08716
[124] validation_0-logloss:0.08767
[125] validation_0-logloss:0.08774
[126] validation_0-logloss:0.08828
[127] validation_0-logloss:0.08831
[128] validation_0-logloss:0.08827
[129] validation_0-logloss:0.08789
[130] validation_0-logloss:0.08886
[131] validation_0-logloss:0.08868
[132] validation_0-logloss:0.08874
[133] validation_0-logloss:0.08922
[134] validation_0-logloss:0.08918
[135] validation_0-logloss:0.08882
[136] validation_0-logloss:0.08851
[137] validation_0-logloss:0.08848
[138] validation_0-logloss:0.08839
[139] validation_0-logloss:0.08915
[140] validation_0-logloss:0.08911
[141] validation_0-logloss:0.08876
[142] validation_0-logloss:0.08868
[143] validation_0-logloss:0.08839
[144] validation_0-logloss:0.08927
[145] validation_0-logloss:0.08924
[146] validation_0-logloss:0.08914
[147] validation_0-logloss:0.08891
[148] validation_0-logloss:0.08942
[149] validation_0-logloss:0.08939
[150] validation_0-logloss:0.08911
[151] validation_0-logloss:0.08873
[152] validation_0-logloss:0.08872
[153] validation_0-logloss:0.08848
[154] validation_0-logloss:0.08847
[155] validation_0-logloss:0.08854
[156] validation_0-logloss:0.08852
[157] validation_0-logloss:0.08855
[158] validation_0-logloss:0.08828
[159] validation_0-logloss:0.08830
[160] validation_0-logloss:0.08828
[161] validation_0-logloss:0.08801
[162] validation_0-logloss:0.08776
[163] validation_0-logloss:0.08778
[164] validation_0-logloss:0.08778
[165] validation_0-logloss:0.08752
[166] validation_0-logloss:0.08754
[167] validation_0-logloss:0.08764
[168] validation_0-logloss:0.08739
[169] validation_0-logloss:0.08738
[170] validation_0-logloss:0.08730
[171] validation_0-logloss:0.08737
[172] validation_0-logloss:0.08740
[173] validation_0-logloss:0.08739
[174] validation_0-logloss:0.08713
[175] validation_0-logloss:0.08716
[176] validation_0-logloss:0.08696
[177] validation_0-logloss:0.08705
[178] validation_0-logloss:0.08697
[179] validation_0-logloss:0.08697
[180] validation_0-logloss:0.08704
[181] validation_0-logloss:0.08680
[182] validation_0-logloss:0.08683
[183] validation_0-logloss:0.08658
[184] validation_0-logloss:0.08659
[185] validation_0-logloss:0.08661
[186] validation_0-logloss:0.08637
[187] validation_0-logloss:0.08637
[188] validation_0-logloss:0.08630
[189] validation_0-logloss:0.08610
[190] validation_0-logloss:0.08602
[191] validation_0-logloss:0.08605
[192] validation_0-logloss:0.08615
[193] validation_0-logloss:0.08592
[194] validation_0-logloss:0.08592
[195] validation_0-logloss:0.08598
[196] validation_0-logloss:0.08601
[197] validation_0-logloss:0.08592
[198] validation_0-logloss:0.08585
[199] validation_0-logloss:0.08587
[200] validation_0-logloss:0.08589
[201] validation_0-logloss:0.08595
[202] validation_0-logloss:0.08573
[203] validation_0-logloss:0.08573
[204] validation_0-logloss:0.08575
[205] validation_0-logloss:0.08582
[206] validation_0-logloss:0.08584
[207] validation_0-logloss:0.08578
[208] validation_0-logloss:0.08569
[209] validation_0-logloss:0.08571
[210] validation_0-logloss:0.08581
[211] validation_0-logloss:0.08559
[212] validation_0-logloss:0.08580
[213] validation_0-logloss:0.08581
[214] validation_0-logloss:0.08574
[215] validation_0-logloss:0.08566
[216] validation_0-logloss:0.08584
[217] validation_0-logloss:0.08563
[218] validation_0-logloss:0.08573
[219] validation_0-logloss:0.08578
[220] validation_0-logloss:0.08579
[221] validation_0-logloss:0.08582
[222] validation_0-logloss:0.08576
[223] validation_0-logloss:0.08567
[224] validation_0-logloss:0.08586
[225] validation_0-logloss:0.08587
[226] validation_0-logloss:0.08593
[227] validation_0-logloss:0.08595
[228] validation_0-logloss:0.08587
[229] validation_0-logloss:0.08606
[230] validation_0-logloss:0.08600
[231] validation_0-logloss:0.08592
[232] validation_0-logloss:0.08610
[233] validation_0-logloss:0.08611
[234] validation_0-logloss:0.08617
[235] validation_0-logloss:0.08626
[236] validation_0-logloss:0.08629
[237] validation_0-logloss:0.08622
[238] validation_0-logloss:0.08639
[239] validation_0-logloss:0.08634
[240] validation_0-logloss:0.08618
[241] validation_0-logloss:0.08619
[242] validation_0-logloss:0.08625
[243] validation_0-logloss:0.08626
[244] validation_0-logloss:0.08629
[245] validation_0-logloss:0.08622
[246] validation_0-logloss:0.08640
[247] validation_0-logloss:0.08635
[248] validation_0-logloss:0.08628
[249] validation_0-logloss:0.08645
[250] validation_0-logloss:0.08629
[251] validation_0-logloss:0.08631
[252] validation_0-logloss:0.08636
[253] validation_0-logloss:0.08639
[254] validation_0-logloss:0.08649
[255] validation_0-logloss:0.08644
[256] validation_0-logloss:0.08629
[257] validation_0-logloss:0.08646
[258] validation_0-logloss:0.08639
[259] validation_0-logloss:0.08644
[260] validation_0-logloss:0.08646
[261] validation_0-logloss:0.08649
[262] validation_0-logloss:0.08644
[263] validation_0-logloss:0.08647
[264] validation_0-logloss:0.08632
[265] validation_0-logloss:0.08649
[266] validation_0-logloss:0.08654
[267] validation_0-logloss:0.08647
[268] validation_0-logloss:0.08650
[269] validation_0-logloss:0.08652
[270] validation_0-logloss:0.08669
[271] validation_0-logloss:0.08674
[272] validation_0-logloss:0.08683
[273] validation_0-logloss:0.08668
[274] validation_0-logloss:0.08664
[275] validation_0-logloss:0.08650
[276] validation_0-logloss:0.08636
[277] validation_0-logloss:0.08652
[278] validation_0-logloss:0.08657
[279] validation_0-logloss:0.08659
[280] validation_0-logloss:0.08668
[281] validation_0-logloss:0.08664
[282] validation_0-logloss:0.08650
[283] validation_0-logloss:0.08636
[284] validation_0-logloss:0.08640
[285] validation_0-logloss:0.08643
[286] validation_0-logloss:0.08646
[287] validation_0-logloss:0.08650
[288] validation_0-logloss:0.08637
[289] validation_0-logloss:0.08646
[290] validation_0-logloss:0.08645
[291] validation_0-logloss:0.08632
[292] validation_0-logloss:0.08628
[293] validation_0-logloss:0.08615
[294] validation_0-logloss:0.08620
[295] validation_0-logloss:0.08622
[296] validation_0-logloss:0.08631
[297] validation_0-logloss:0.08618
[298] validation_0-logloss:0.08626
[299] validation_0-logloss:0.08613
[300] validation_0-logloss:0.08618
[301] validation_0-logloss:0.08605
[302] validation_0-logloss:0.08602
[303] validation_0-logloss:0.08610
[304] validation_0-logloss:0.08598
[305] validation_0-logloss:0.08606
[306] validation_0-logloss:0.08597
[307] validation_0-logloss:0.08600
[308] validation_0-logloss:0.08600
[309] validation_0-logloss:0.08588
[310] validation_0-logloss:0.08592n_estimators=400 으로 설정해도 311번 수행하고 학습을 완료한 이유는 211번에서 311번까지 logloss가 0.08581에서 0.08592로 성능 평가 지수가 향상되지 않아서 이다.
get_clf_eval(y_test, ws100_preds, ws100_pred_proba)오차행렬
[[34 3]
[ 1 76]]
정확도: 0.9649, 정밀도: 0.9620, 재현율: 0.9870, F1: 0.9744, AUC:0.9530정확도: 0.9737, 정밀도: 0.9744, 재현율: 0.9870, F1: 0.9806, AUC:0.9665 에서 정확도: 0.9649, 정밀도: 0.9620, 재현율: 0.9870, F1: 0.9744, AUC:0.9530 로 약간 저조한 성능을 나타냈지만 큰 차이는 아니다.
이번에는 early_stopping_rounds 를 10으로 설정하고 예측 성능을 측정해보자.
xgb_wrapper.fit(X_train, y_train, early_stopping_rounds=10, eval_metric="logloss", eval_set=evals, verbose=True)
ws10_preds = xgb_wrapper.predict(X_test)
ws10_pred_proba = xgb_wrapper.predict_proba(X_test)[:, 1]
get_clf_eval(y_test, ws10_preds, ws10_pred_proba)[0] validation_0-logloss:0.61352
[1] validation_0-logloss:0.54784
[2] validation_0-logloss:0.49425
[3] validation_0-logloss:0.44799
[4] validation_0-logloss:0.40911
[5] validation_0-logloss:0.37498
[6] validation_0-logloss:0.34571
[7] validation_0-logloss:0.32053
[8] validation_0-logloss:0.29721
[9] validation_0-logloss:0.27799
[10] validation_0-logloss:0.26030
[11] validation_0-logloss:0.24604
[12] validation_0-logloss:0.23156
[13] validation_0-logloss:0.22005
[14] validation_0-logloss:0.20857
[15] validation_0-logloss:0.19999
[16] validation_0-logloss:0.19012
[17] validation_0-logloss:0.18182
[18] validation_0-logloss:0.17473
[19] validation_0-logloss:0.16766
[20] validation_0-logloss:0.15820
[21] validation_0-logloss:0.15473
[22] validation_0-logloss:0.14895
[23] validation_0-logloss:0.14331
[24] validation_0-logloss:0.13634
[25] validation_0-logloss:0.13278
[26] validation_0-logloss:0.12791
[27] validation_0-logloss:0.12526
[28] validation_0-logloss:0.11998
[29] validation_0-logloss:0.11641
[30] validation_0-logloss:0.11450
[31] validation_0-logloss:0.11257
[32] validation_0-logloss:0.11154
[33] validation_0-logloss:0.10868
[34] validation_0-logloss:0.10668
[35] validation_0-logloss:0.10421
[36] validation_0-logloss:0.10296
[37] validation_0-logloss:0.10058
[38] validation_0-logloss:0.09868
[39] validation_0-logloss:0.09644
[40] validation_0-logloss:0.09587
[41] validation_0-logloss:0.09424
[42] validation_0-logloss:0.09471
[43] validation_0-logloss:0.09427
[44] validation_0-logloss:0.09389
[45] validation_0-logloss:0.09418
[46] validation_0-logloss:0.09402
[47] validation_0-logloss:0.09236
[48] validation_0-logloss:0.09301
[49] validation_0-logloss:0.09127
[50] validation_0-logloss:0.09005
[51] validation_0-logloss:0.08961
[52] validation_0-logloss:0.08958
[53] validation_0-logloss:0.09070
[54] validation_0-logloss:0.08958
[55] validation_0-logloss:0.09036
[56] validation_0-logloss:0.09159
[57] validation_0-logloss:0.09153
[58] validation_0-logloss:0.09199
[59] validation_0-logloss:0.09195
[60] validation_0-logloss:0.09194
[61] validation_0-logloss:0.09146
오차행렬
[[34 3]
[ 2 75]]
정확도: 0.9561, 정밀도: 0.9615, 재현율: 0.9740, F1: 0.9677, AUC:0.9465조기 중단 값을 급격히 줄이면 향상될 여지가 있어도 10번 반복하는 동안 성능 평가 지표가 향상되지 않으면 반복이 멈춰버려 예측 성능이 나빠질 수 있다. 정확도: 0.9649, 정밀도: 0.9620, 재현율: 0.9870, F1: 0.9744, AUC:0.9530 에서 정확도: 0.9561, 정밀도: 0.9615, 재현율: 0.9740, F1: 0.9677, AUC:0.9465 로 정확도가 낮아진 것을 알 수 있다.
# 사이킷런 래퍼 클래스를 입력해도 동일하게 시각화 할 수 있다.
fig, ax = plt.subplots(figsize=(10, 12))
plot_importance(xgb_wrapper, ax=ax)<matplotlib.axes._subplots.AxesSubplot at 0x7fa35b786f10>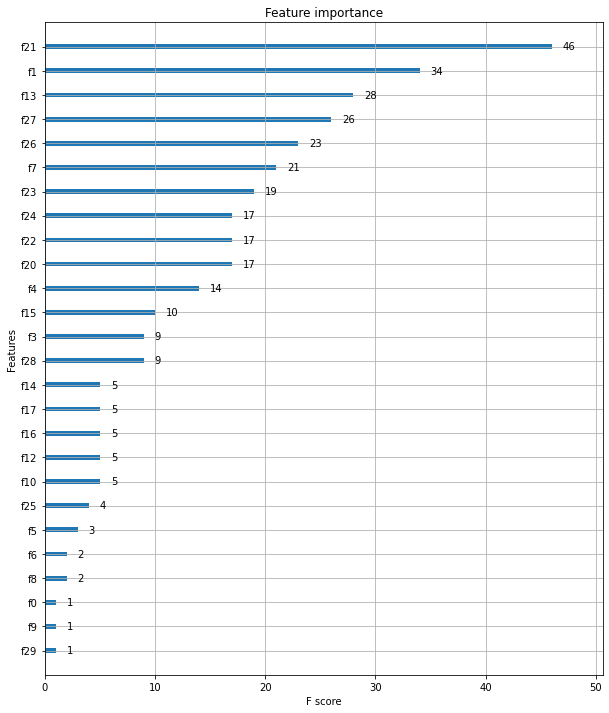
LightGBM
LightGBM은 XGBoost보다 학습에 걸리는 시간이 적고, 메모리 사용량도 적지만 예측 성능은 큰 차이가 없다. 즉 Light가 성능이 약하거나 그런 것을 뜻하는 것이 아니다. 하지만 LightGBM의 유일한 단점은 적은 데이터 세트(10,000건 이하)를 적용하면 과적합이 발생하기 쉽다.
LightGBM은 일반 GBM 계열의 트리 분할 방법과 다르게 리프 중심 트리 분할 방식을 사용한다.
LightGBM 하이퍼 파라미터
-
주요 파라미터
- n_estimators[default=100]: 반복 수행하려는 트리의 개수를 지정, 크게 지정할수록 예측 성능이 높아질 수 있으나 너무 크면 과적합으로 성능 저하될 수 있다.
- learning_rate[default=0.1]: 0-1 사이의 값을 지정하고 부스팅 스텝을 반복적으로 수행할 때 업데이트되는 학습률 값.
- max_depth[default=-1]: 트리 기반 알고리즘의 max_depth 와 같다. 0보다 작은 값을 지정하면 깊이에 제한이 없고, Depth wise 방식이 아닌 Leaf wise 기반이므로 상대적으로 더 깊다.
- min_child_samples[default=20]: 결정 트리의 min_samples_leaf 와 같은 파라미터로 최종 결정 클래스인 리프 노드가 되기위해 최소한으로 필요한 레코드 수이며, 과적합을 제어하기 위한 파라미터이다.
- num_leaves[default=31]: 하나의 트리가 가질 수 있는 최대 리프 개수이다. 개수를 높이면 정확도가 높아지지만, 트리의 깊이가 깊어지고 모델의 복잡도가 커져 과적합 영향도가 커진다.
- boosting[default=gbdt]: 부스팅의 트리를 생성하는 알고리즘
- gbdt: 일반적인 그래디언트 부스팅 결정 트리
- rf: 랜덤 포레스트
- subsample[default=1.0]: 트리가 커져서 과적합되는 것을 제어하기 위해서 데이터를 샘플링하는 비율을 지정.
- colsample_bytree[default=1.0]: 개별 트리를 학습할 때마다 무작위로 선택하는 피처의 비율
- reg_lambda[default=0.0]: L2 Regularizaion 적용 값으로, 피처 개수가 많을 경우 적용을 검토하고, 값이 클수록 과적합 감소 효과가 있다.
- reg_alpha[default=0.0]: L1 Regularizaion 적용 값으로, 위 lambda 와 동일하다.
-
학습 태스크 파라미터
- objective: 최솟값을 가져야할 손실 함수를 정의, 이진 분류인지 다중 분류인지에 따라 달라짐.
LightGBM으로 위스콘신 유방암 예측
from lightgbm import LGBMClassifier
ftr = dataset.data
target = dataset.target
X_train, X_test, y_train, y_test = train_test_split(ftr, target, test_size=0.2, random_state=156)
# XGBoost와 동일하게 n_estimators=400 설정, 조기 중단 설정
lgbm_wrapper = LGBMClassifier(n_estimators=400)
evals = [(X_test, y_test)]
lgbm_wrapper.fit(X_train, y_train, early_stopping_rounds=100, eval_metric="logloss", eval_set=evals, verbose=True)
preds = lgbm_wrapper.predict(X_test)
pred_proba = lgbm_wrapper.predict_proba(X_test)[:, 1][1] valid_0's binary_logloss: 0.565079
Training until validation scores don't improve for 100 rounds
[2] valid_0's binary_logloss: 0.507451
[3] valid_0's binary_logloss: 0.458489
[4] valid_0's binary_logloss: 0.417481
[5] valid_0's binary_logloss: 0.385507
[6] valid_0's binary_logloss: 0.355773
[7] valid_0's binary_logloss: 0.329587
[8] valid_0's binary_logloss: 0.308478
[9] valid_0's binary_logloss: 0.285395
[10] valid_0's binary_logloss: 0.267055
[11] valid_0's binary_logloss: 0.252013
[12] valid_0's binary_logloss: 0.237018
[13] valid_0's binary_logloss: 0.224756
[14] valid_0's binary_logloss: 0.213383
[15] valid_0's binary_logloss: 0.203058
[16] valid_0's binary_logloss: 0.194015
[17] valid_0's binary_logloss: 0.186412
[18] valid_0's binary_logloss: 0.179108
[19] valid_0's binary_logloss: 0.174004
[20] valid_0's binary_logloss: 0.167155
[21] valid_0's binary_logloss: 0.162494
[22] valid_0's binary_logloss: 0.156886
[23] valid_0's binary_logloss: 0.152855
[24] valid_0's binary_logloss: 0.151113
[25] valid_0's binary_logloss: 0.148395
[26] valid_0's binary_logloss: 0.145869
[27] valid_0's binary_logloss: 0.143036
[28] valid_0's binary_logloss: 0.14033
[29] valid_0's binary_logloss: 0.139609
[30] valid_0's binary_logloss: 0.136109
[31] valid_0's binary_logloss: 0.134867
[32] valid_0's binary_logloss: 0.134729
[33] valid_0's binary_logloss: 0.1311
[34] valid_0's binary_logloss: 0.131143
[35] valid_0's binary_logloss: 0.129435
[36] valid_0's binary_logloss: 0.128474
[37] valid_0's binary_logloss: 0.126683
[38] valid_0's binary_logloss: 0.126112
[39] valid_0's binary_logloss: 0.122831
[40] valid_0's binary_logloss: 0.123162
[41] valid_0's binary_logloss: 0.125592
[42] valid_0's binary_logloss: 0.128293
[43] valid_0's binary_logloss: 0.128123
[44] valid_0's binary_logloss: 0.12789
[45] valid_0's binary_logloss: 0.122818
[46] valid_0's binary_logloss: 0.12496
[47] valid_0's binary_logloss: 0.125578
[48] valid_0's binary_logloss: 0.127381
[49] valid_0's binary_logloss: 0.128349
[50] valid_0's binary_logloss: 0.127004
[51] valid_0's binary_logloss: 0.130288
[52] valid_0's binary_logloss: 0.131362
[53] valid_0's binary_logloss: 0.133363
[54] valid_0's binary_logloss: 0.1332
[55] valid_0's binary_logloss: 0.134543
[56] valid_0's binary_logloss: 0.130803
[57] valid_0's binary_logloss: 0.130306
[58] valid_0's binary_logloss: 0.132514
[59] valid_0's binary_logloss: 0.133278
[60] valid_0's binary_logloss: 0.134804
[61] valid_0's binary_logloss: 0.136888
[62] valid_0's binary_logloss: 0.138745
[63] valid_0's binary_logloss: 0.140497
[64] valid_0's binary_logloss: 0.141368
[65] valid_0's binary_logloss: 0.140764
[66] valid_0's binary_logloss: 0.14348
[67] valid_0's binary_logloss: 0.143418
[68] valid_0's binary_logloss: 0.143682
[69] valid_0's binary_logloss: 0.145076
[70] valid_0's binary_logloss: 0.14686
[71] valid_0's binary_logloss: 0.148051
[72] valid_0's binary_logloss: 0.147664
[73] valid_0's binary_logloss: 0.149478
[74] valid_0's binary_logloss: 0.14708
[75] valid_0's binary_logloss: 0.14545
[76] valid_0's binary_logloss: 0.148767
[77] valid_0's binary_logloss: 0.149959
[78] valid_0's binary_logloss: 0.146083
[79] valid_0's binary_logloss: 0.14638
[80] valid_0's binary_logloss: 0.148461
[81] valid_0's binary_logloss: 0.15091
[82] valid_0's binary_logloss: 0.153011
[83] valid_0's binary_logloss: 0.154807
[84] valid_0's binary_logloss: 0.156501
[85] valid_0's binary_logloss: 0.158586
[86] valid_0's binary_logloss: 0.159819
[87] valid_0's binary_logloss: 0.161745
[88] valid_0's binary_logloss: 0.162829
[89] valid_0's binary_logloss: 0.159142
[90] valid_0's binary_logloss: 0.156765
[91] valid_0's binary_logloss: 0.158625
[92] valid_0's binary_logloss: 0.156832
[93] valid_0's binary_logloss: 0.154616
[94] valid_0's binary_logloss: 0.154263
[95] valid_0's binary_logloss: 0.157156
[96] valid_0's binary_logloss: 0.158617
[97] valid_0's binary_logloss: 0.157495
[98] valid_0's binary_logloss: 0.159413
[99] valid_0's binary_logloss: 0.15847
[100] valid_0's binary_logloss: 0.160746
[101] valid_0's binary_logloss: 0.16217
[102] valid_0's binary_logloss: 0.165293
[103] valid_0's binary_logloss: 0.164749
[104] valid_0's binary_logloss: 0.167097
[105] valid_0's binary_logloss: 0.167697
[106] valid_0's binary_logloss: 0.169462
[107] valid_0's binary_logloss: 0.169947
[108] valid_0's binary_logloss: 0.171
[109] valid_0's binary_logloss: 0.16907
[110] valid_0's binary_logloss: 0.169521
[111] valid_0's binary_logloss: 0.167719
[112] valid_0's binary_logloss: 0.166648
[113] valid_0's binary_logloss: 0.169053
[114] valid_0's binary_logloss: 0.169613
[115] valid_0's binary_logloss: 0.170059
[116] valid_0's binary_logloss: 0.1723
[117] valid_0's binary_logloss: 0.174733
[118] valid_0's binary_logloss: 0.173526
[119] valid_0's binary_logloss: 0.1751
[120] valid_0's binary_logloss: 0.178254
[121] valid_0's binary_logloss: 0.182968
[122] valid_0's binary_logloss: 0.179017
[123] valid_0's binary_logloss: 0.178326
[124] valid_0's binary_logloss: 0.177149
[125] valid_0's binary_logloss: 0.179171
[126] valid_0's binary_logloss: 0.180948
[127] valid_0's binary_logloss: 0.183861
[128] valid_0's binary_logloss: 0.187579
[129] valid_0's binary_logloss: 0.188122
[130] valid_0's binary_logloss: 0.1857
[131] valid_0's binary_logloss: 0.187442
[132] valid_0's binary_logloss: 0.188578
[133] valid_0's binary_logloss: 0.189729
[134] valid_0's binary_logloss: 0.187313
[135] valid_0's binary_logloss: 0.189279
[136] valid_0's binary_logloss: 0.191068
[137] valid_0's binary_logloss: 0.192414
[138] valid_0's binary_logloss: 0.191255
[139] valid_0's binary_logloss: 0.193453
[140] valid_0's binary_logloss: 0.196969
[141] valid_0's binary_logloss: 0.196378
[142] valid_0's binary_logloss: 0.196367
[143] valid_0's binary_logloss: 0.19869
[144] valid_0's binary_logloss: 0.200352
[145] valid_0's binary_logloss: 0.19712
Early stopping, best iteration is:
[45] valid_0's binary_logloss: 0.122818get_clf_eval(y_test, preds, pred_proba)오차행렬
[[33 4]
[ 1 76]]
정확도: 0.9561, 정밀도: 0.9500, 재현율: 0.9870, F1: 0.9682, AUC:0.9395XGBoost의 결과: 정확도: 0.9737, 정밀도: 0.9744, 재현율: 0.9870, F1: 0.9806, AUC:0.9665
LightGBM의 결과: 정확도: 0.9561, 정밀도: 0.9500, 재현율: 0.9870, F1: 0.9682, AUC:0.9395
정확도가 XGBoost보다 낮지만 학습 데이터 세트와 테스트 데이터 세트 크기가 작아서 성능 비교는 큰 의미가 없다.
from lightgbm import plot_importance
fig, ax = plt.subplots(figsize=(10, 12))
plot_importance(lgbm_wrapper, ax=ax)<matplotlib.axes._subplots.AxesSubplot at 0x7fa33df71c70>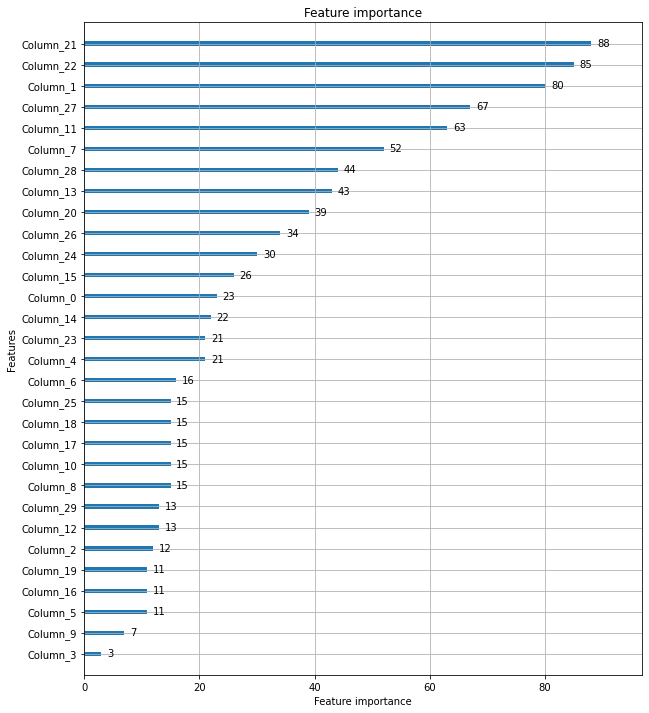
lightgbm에 내장된 plot_importance() 역시 넘파이로 피처 데이터를 학습할 경우 피처명을 알 수 없기에 Column_ 뒤에 숫자를 붙여서 나열한다.
파이썬 머신러닝 완벽 가이드 / 위키북스
