산탄데르 고객 만족(Santander Customer Satisfaction)
캐글의 산탄데르 고객 만족 데이터 세트에 대해 고객 만족 여부를 XGBoost 와 LightGBM 으로 예측해보자. 이 데이터 세트는 370개의 피처로 주어진 데이터 세트 기반으로 고객 만족 여부를 예측하는 것인데, 피처 이름이 모두 익명으로 처리돼 이름만으로는 어떤 속성인지는 추정할 수 없다. TARGET 레이블이 1이면 불만, 0이면 만족한 고객이다.
대부분이 만족이고 일부가 불만족일 것이기에 정확도 수치보다 ROC-AUC로 평가하는 것이 더 적합할 것이다.
데이터 전처리
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib
import warnings
warnings.filterwarnings('ignore')
cust_df = pd.read_csv('./santander-customer-satisfaction/train.csv', encoding='latin-1')
print(f'dataset shape: {cust_df.shape}')
cust_df.head(3)dataset shape: (76020, 371)| ID | var3 | var15 | imp_ent_var16_ult1 | imp_op_var39_comer_ult1 | imp_op_var39_comer_ult3 | imp_op_var40_comer_ult1 | imp_op_var40_comer_ult3 | imp_op_var40_efect_ult1 | imp_op_var40_efect_ult3 | imp_op_var40_ult1 | imp_op_var41_comer_ult1 | imp_op_var41_comer_ult3 | imp_op_var41_efect_ult1 | imp_op_var41_efect_ult3 | imp_op_var41_ult1 | imp_op_var39_efect_ult1 | imp_op_var39_efect_ult3 | imp_op_var39_ult1 | imp_sal_var16_ult1 | ind_var1_0 | ind_var1 | ind_var2_0 | ind_var2 | ind_var5_0 | ind_var5 | ind_var6_0 | ind_var6 | ind_var8_0 | ind_var8 | ind_var12_0 | ind_var12 | ind_var13_0 | ind_var13_corto_0 | ind_var13_corto | ind_var13_largo_0 | ind_var13_largo | ind_var13_medio_0 | ind_var13_medio | ind_var13 | ... | saldo_medio_var5_ult1 | saldo_medio_var5_ult3 | saldo_medio_var8_hace2 | saldo_medio_var8_hace3 | saldo_medio_var8_ult1 | saldo_medio_var8_ult3 | saldo_medio_var12_hace2 | saldo_medio_var12_hace3 | saldo_medio_var12_ult1 | saldo_medio_var12_ult3 | saldo_medio_var13_corto_hace2 | saldo_medio_var13_corto_hace3 | saldo_medio_var13_corto_ult1 | saldo_medio_var13_corto_ult3 | saldo_medio_var13_largo_hace2 | saldo_medio_var13_largo_hace3 | saldo_medio_var13_largo_ult1 | saldo_medio_var13_largo_ult3 | saldo_medio_var13_medio_hace2 | saldo_medio_var13_medio_hace3 | saldo_medio_var13_medio_ult1 | saldo_medio_var13_medio_ult3 | saldo_medio_var17_hace2 | saldo_medio_var17_hace3 | saldo_medio_var17_ult1 | saldo_medio_var17_ult3 | saldo_medio_var29_hace2 | saldo_medio_var29_hace3 | saldo_medio_var29_ult1 | saldo_medio_var29_ult3 | saldo_medio_var33_hace2 | saldo_medio_var33_hace3 | saldo_medio_var33_ult1 | saldo_medio_var33_ult3 | saldo_medio_var44_hace2 | saldo_medio_var44_hace3 | saldo_medio_var44_ult1 | saldo_medio_var44_ult3 | var38 | TARGET | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 23 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0.0 | 0.00 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.00 | 0.0 | 0.00 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0 | 0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 39205.17 | 0 |
| 1 | 3 | 2 | 34 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | ... | 0.0 | 0.00 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 300.0 | 122.22 | 300.0 | 240.75 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0 | 0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 49278.03 | 0 |
| 2 | 4 | 2 | 23 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 3.0 | 2.07 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.00 | 0.0 | 0.00 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0 | 0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 67333.77 | 0 |
3 rows × 371 columns
cust_df.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 76020 entries, 0 to 76019
Columns: 371 entries, ID to TARGET
dtypes: float64(111), int64(260)
memory usage: 215.2 MB111개의 float63형과 260개의 int64형으로 모든 피처가 숫자형이며, Null 값은 없다.
print(cust_df['TARGET'].value_counts())
unstisfied_cnt = cust_df[cust_df['TARGET']==1].TARGET.count()
total_cnt = cust_df.TARGET.count()
print(f'불만족 비율: {np.round((unstisfied_cnt/total_cnt*100), 2)}%')0 73012
1 3008
Name: TARGET, dtype: int64
불만족 비율: 3.96%서론에서 예상한대로 불만족비율은 3.96% 밖에 되지 않는다.
cust_df.describe()| ID | var3 | var15 | imp_ent_var16_ult1 | imp_op_var39_comer_ult1 | imp_op_var39_comer_ult3 | imp_op_var40_comer_ult1 | imp_op_var40_comer_ult3 | imp_op_var40_efect_ult1 | imp_op_var40_efect_ult3 | ... | saldo_medio_var33_hace2 | saldo_medio_var33_hace3 | saldo_medio_var33_ult1 | saldo_medio_var33_ult3 | saldo_medio_var44_hace2 | saldo_medio_var44_hace3 | saldo_medio_var44_ult1 | saldo_medio_var44_ult3 | var38 | TARGET | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 76020.000000 | 76020.000000 | 76020.000000 | 76020.000000 | 76020.000000 | 76020.000000 | 76020.000000 | 76020.000000 | 76020.000000 | 76020.000000 | ... | 76020.000000 | 76020.000000 | 76020.000000 | 76020.000000 | 76020.000000 | 76020.000000 | 76020.000000 | 76020.000000 | 7.602000e+04 | 76020.000000 |
| mean | 75964.050723 | -1523.199277 | 33.212865 | 86.208265 | 72.363067 | 119.529632 | 3.559130 | 6.472698 | 0.412946 | 0.567352 | ... | 7.935824 | 1.365146 | 12.215580 | 8.784074 | 31.505324 | 1.858575 | 76.026165 | 56.614351 | 1.172358e+05 | 0.039569 |
| std | 43781.947379 | 39033.462364 | 12.956486 | 1614.757313 | 339.315831 | 546.266294 | 93.155749 | 153.737066 | 30.604864 | 36.513513 | ... | 455.887218 | 113.959637 | 783.207399 | 538.439211 | 2013.125393 | 147.786584 | 4040.337842 | 2852.579397 | 1.826646e+05 | 0.194945 |
| min | 1.000000 | -999999.000000 | 5.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | ... | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 5.163750e+03 | 0.000000 |
| 25% | 38104.750000 | 2.000000 | 23.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | ... | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 6.787061e+04 | 0.000000 |
| 50% | 76043.000000 | 2.000000 | 28.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | ... | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 1.064092e+05 | 0.000000 |
| 75% | 113748.750000 | 2.000000 | 40.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | ... | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 1.187563e+05 | 0.000000 |
| max | 151838.000000 | 238.000000 | 105.000000 | 210000.000000 | 12888.030000 | 21024.810000 | 8237.820000 | 11073.570000 | 6600.000000 | 6600.000000 | ... | 50003.880000 | 20385.720000 | 138831.630000 | 91778.730000 | 438329.220000 | 24650.010000 | 681462.900000 | 397884.300000 | 2.203474e+07 | 1.000000 |
8 rows × 371 columns
var3의 최솟값이 -999999인데 아마 NaN이나 특정값을 변환한 것으로 예측할 수 있다.
print(cust_df.var3.value_counts()[:10]) 2 74165
8 138
-999999 116
9 110
3 108
1 105
13 98
7 97
4 86
12 85
Name: var3, dtype: int64-999999가 116개가 있는데 var3는 숫자형이고 다른 값에 비해 -999999는 편차가 너무 심하므로 가장 많은 수인 2로 대체하자. 그리고 ID 피처는 단순 식별자이므로 드롭하고 클래스 데이터 세트와 피처 데이터 세트를 분리해 별도의 데이터 세트로 저장하자.
cust_df['var3'].replace(-999999, 2, inplace=True)
cust_df.drop('ID', axis=1, inplace=True)
# 피처 세트와 레이블 세트 분리. 레이블 칼럼은 DataFrame의 맨 마지막에 위치해 칼럼 위치 -1로 분리
X_features = cust_df.iloc[:, :-1]
y_labels = cust_df.iloc[:, -1]
print(f'피처 데이터 shape: {X_features.shape}')피처 데이터 shape: (76020, 369)from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X_features, y_labels, test_size=0.2, random_state=0)
train_cnt = y_train.count()
test_cnt = y_test.count()
print(f'학습 세트 shape: {X_train.shape}, 테스트 세트 shape: {X_test.shape}')
print('학습 세트 레이블 값 분포 비율')
print(y_train.value_counts()/train_cnt)
print('\n테스트 데이터 세트 레이블 값 분포 비율')
print(y_test.value_counts()/test_cnt)학습 세트 shape: (60816, 369), 테스트 세트 shape: (15204, 369)
학습 세트 레이블 값 분포 비율
0 0.960964
1 0.039036
Name: TARGET, dtype: float64
테스트 데이터 세트 레이블 값 분포 비율
0 0.9583
1 0.0417
Name: TARGET, dtype: float64학습 데이터와 테스트 데이터 세트 모두 불만족 비율이 4% 정도로 만들어졌다.
XGBoost 모델 학습과 하이퍼 파라미터 튜닝
from xgboost import XGBClassifier
from sklearn.metrics import roc_auc_score
xgb_clf = XGBClassifier(n_estimator=500, random_state=156)
xgb_clf.fit(X_train, y_train, early_stopping_rounds=100, eval_metric='auc', eval_set=[(X_train, y_train), (X_test, y_test)])
xgb_roc_score = roc_auc_score(y_test, xgb_clf.predict_proba(X_test)[:, 1], average='macro')
print(f'ROC AUC: {np.round(xgb_roc_score, 4)}')[0] validation_0-auc:0.82005 validation_1-auc:0.81157
[1] validation_0-auc:0.83400 validation_1-auc:0.82452
[2] validation_0-auc:0.83870 validation_1-auc:0.82746
[3] validation_0-auc:0.84419 validation_1-auc:0.82922
[4] validation_0-auc:0.84783 validation_1-auc:0.83298
[5] validation_0-auc:0.85125 validation_1-auc:0.83500
[6] validation_0-auc:0.85501 validation_1-auc:0.83653
[7] validation_0-auc:0.85830 validation_1-auc:0.83782
[8] validation_0-auc:0.86143 validation_1-auc:0.83802
[9] validation_0-auc:0.86452 validation_1-auc:0.83914
[10] validation_0-auc:0.86717 validation_1-auc:0.83954
[11] validation_0-auc:0.87013 validation_1-auc:0.83983
[12] validation_0-auc:0.87369 validation_1-auc:0.84033
[13] validation_0-auc:0.87620 validation_1-auc:0.84054
[14] validation_0-auc:0.87799 validation_1-auc:0.84135
[15] validation_0-auc:0.88072 validation_1-auc:0.84117
[16] validation_0-auc:0.88237 validation_1-auc:0.84101
[17] validation_0-auc:0.88352 validation_1-auc:0.84071
[18] validation_0-auc:0.88457 validation_1-auc:0.84052
[19] validation_0-auc:0.88592 validation_1-auc:0.84023
[20] validation_0-auc:0.88788 validation_1-auc:0.84012
[21] validation_0-auc:0.88845 validation_1-auc:0.84022
[22] validation_0-auc:0.88980 validation_1-auc:0.84007
[23] validation_0-auc:0.89019 validation_1-auc:0.84009
[24] validation_0-auc:0.89193 validation_1-auc:0.83974
[25] validation_0-auc:0.89253 validation_1-auc:0.84015
[26] validation_0-auc:0.89329 validation_1-auc:0.84101
[27] validation_0-auc:0.89386 validation_1-auc:0.84088
[28] validation_0-auc:0.89416 validation_1-auc:0.84074
[29] validation_0-auc:0.89660 validation_1-auc:0.83999
[30] validation_0-auc:0.89738 validation_1-auc:0.83959
[31] validation_0-auc:0.89911 validation_1-auc:0.83952
[32] validation_0-auc:0.90103 validation_1-auc:0.83901
[33] validation_0-auc:0.90250 validation_1-auc:0.83885
[34] validation_0-auc:0.90275 validation_1-auc:0.83887
[35] validation_0-auc:0.90290 validation_1-auc:0.83864
[36] validation_0-auc:0.90460 validation_1-auc:0.83834
[37] validation_0-auc:0.90497 validation_1-auc:0.83810
[38] validation_0-auc:0.90515 validation_1-auc:0.83810
[39] validation_0-auc:0.90533 validation_1-auc:0.83813
[40] validation_0-auc:0.90574 validation_1-auc:0.83776
[41] validation_0-auc:0.90690 validation_1-auc:0.83720
[42] validation_0-auc:0.90715 validation_1-auc:0.83684
[43] validation_0-auc:0.90736 validation_1-auc:0.83672
[44] validation_0-auc:0.90758 validation_1-auc:0.83674
[45] validation_0-auc:0.90767 validation_1-auc:0.83693
[46] validation_0-auc:0.90777 validation_1-auc:0.83686
[47] validation_0-auc:0.90791 validation_1-auc:0.83678
[48] validation_0-auc:0.90829 validation_1-auc:0.83694
[49] validation_0-auc:0.90869 validation_1-auc:0.83676
[50] validation_0-auc:0.90890 validation_1-auc:0.83655
[51] validation_0-auc:0.91067 validation_1-auc:0.83669
[52] validation_0-auc:0.91238 validation_1-auc:0.83641
[53] validation_0-auc:0.91352 validation_1-auc:0.83690
[54] validation_0-auc:0.91386 validation_1-auc:0.83693
[55] validation_0-auc:0.91406 validation_1-auc:0.83681
[56] validation_0-auc:0.91545 validation_1-auc:0.83680
[57] validation_0-auc:0.91556 validation_1-auc:0.83667
[58] validation_0-auc:0.91628 validation_1-auc:0.83664
[59] validation_0-auc:0.91725 validation_1-auc:0.83591
[60] validation_0-auc:0.91762 validation_1-auc:0.83576
[61] validation_0-auc:0.91784 validation_1-auc:0.83534
[62] validation_0-auc:0.91872 validation_1-auc:0.83513
[63] validation_0-auc:0.91892 validation_1-auc:0.83510
[64] validation_0-auc:0.91896 validation_1-auc:0.83508
[65] validation_0-auc:0.91907 validation_1-auc:0.83518
[66] validation_0-auc:0.91970 validation_1-auc:0.83510
[67] validation_0-auc:0.91982 validation_1-auc:0.83523
[68] validation_0-auc:0.92007 validation_1-auc:0.83457
[69] validation_0-auc:0.92015 validation_1-auc:0.83460
[70] validation_0-auc:0.92024 validation_1-auc:0.83446
[71] validation_0-auc:0.92037 validation_1-auc:0.83462
[72] validation_0-auc:0.92087 validation_1-auc:0.83394
[73] validation_0-auc:0.92094 validation_1-auc:0.83410
[74] validation_0-auc:0.92133 validation_1-auc:0.83394
[75] validation_0-auc:0.92141 validation_1-auc:0.83368
[76] validation_0-auc:0.92321 validation_1-auc:0.83413
[77] validation_0-auc:0.92415 validation_1-auc:0.83359
[78] validation_0-auc:0.92503 validation_1-auc:0.83353
[79] validation_0-auc:0.92539 validation_1-auc:0.83293
[80] validation_0-auc:0.92577 validation_1-auc:0.83253
[81] validation_0-auc:0.92677 validation_1-auc:0.83187
[82] validation_0-auc:0.92706 validation_1-auc:0.83230
[83] validation_0-auc:0.92800 validation_1-auc:0.83216
[84] validation_0-auc:0.92822 validation_1-auc:0.83206
[85] validation_0-auc:0.92870 validation_1-auc:0.83196
[86] validation_0-auc:0.92875 validation_1-auc:0.83200
[87] validation_0-auc:0.92881 validation_1-auc:0.83208
[88] validation_0-auc:0.92919 validation_1-auc:0.83174
[89] validation_0-auc:0.92940 validation_1-auc:0.83160
[90] validation_0-auc:0.92948 validation_1-auc:0.83155
[91] validation_0-auc:0.92959 validation_1-auc:0.83165
[92] validation_0-auc:0.92964 validation_1-auc:0.83172
[93] validation_0-auc:0.93031 validation_1-auc:0.83160
[94] validation_0-auc:0.93032 validation_1-auc:0.83150
[95] validation_0-auc:0.93037 validation_1-auc:0.83132
[96] validation_0-auc:0.93083 validation_1-auc:0.83090
[97] validation_0-auc:0.93091 validation_1-auc:0.83091
[98] validation_0-auc:0.93168 validation_1-auc:0.83066
[99] validation_0-auc:0.93245 validation_1-auc:0.83058
ROC AUC: 0.8413테스트 데이터 세트로 예측시 ROC AUC는 0.8413 이다.
이번엔 하이퍼 파라미터 튜닝을 수행하는데, 칼럼의 개수가 많으므로 과적합 가능성을 가정하고, max_depth, min_child_weight, colsample_bytree 하이퍼 파라미터만 일차 튜닝 대상으로 한다.
from sklearn.model_selection import GridSearchCV
# 하이퍼 파라미터 테스트의 수행 속도를 향상시키기위해 100으로 감소
xgb_clf = XGBClassifier(n_estimators=100)
params = {'max_depth': [5, 7],
'min_child_weight': [1, 3],
'colsample_bytree': [0.5, 0.75]}
gridcv = GridSearchCV(xgb_clf, param_grid=params, cv=3)
gridcv.fit(X_train, y_train, early_stopping_rounds=30, eval_metric="auc", eval_set=[(X_train, y_train), (X_test, y_test)])
print(f'GridSearchCV 최적 파라미터: {gridcv.best_params_}')
xgb_roc_score = roc_auc_score(y_test, gridcv.predict_proba(X_test)[:, 1], average='macro')
print(f'ROC AUC: {np.round(xgb_roc_score, 4)}')GridSearchCV 최적 파라미터: {'colsample_bytree': 0.5, 'max_depth': 7, 'min_child_weight': 3}
ROC AUC: 0.843하이퍼 파라미터 'colsample_bytree': 0.5, 'max_depth': 7, 'min_child_weight': 3 를 적용한후 ROC-AUC가 0.8413 에서 0.843 으로 조금 개선되었다.
최적 파라미터를 추가/변경하고 다시 학습/예측을 해보자.
# n_estimators는 1000으로 증가시키고, learning_rate=0.02로 감소, reg_alpha=0.03으로 추가
xgb_clf = XGBClassifier(n_estimators=1000, random_state=156, learning_rate=0.02, max_depth=7, min_child_weight=1, colsample_bytree=0.75, reg_alpha=0.03)
# 조기 중단 파라미터 값은 200으로 설정
xgb_clf.fit(X_train, y_train, early_stopping_rounds=200, eval_metric="auc", eval_set=[(X_train, y_train), (X_test, y_test)])
xgb_roc_score = roc_auc_score(y_test, xgb_clf.predict_proba(X_test)[:, 1], average='macro')
print(f'ROC-AUC: {np.round(xgb_roc_score, 4)}')ROC-AUC: 0.8463ROC-AUC가 0.8463 으로 살짝 향상된 것을 알 수 있다. 하지만... 너무 느리다.. 너무 오래걸려..
from xgboost import plot_importance
import matplotlib.pyplot as plt
%matplotlib inline
fig, ax = plt.subplots(figsize=(10, 8))
plot_importance(xgb_clf, ax=ax, max_num_features=20, height=0.4)<matplotlib.axes._subplots.AxesSubplot at 0x7ff85550a370>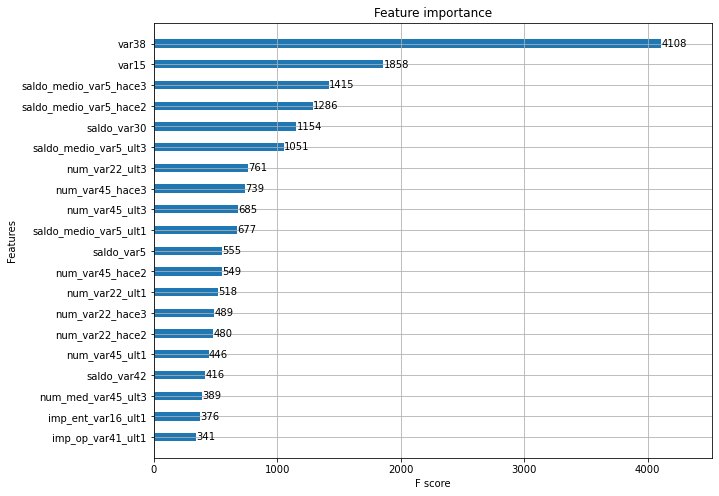
XGBoost의 예측 성능을 좌우하는 가장 중요한 피처는 var38, var15 순이다.
LightGBM 모델 학습과 하이퍼 파라미터 튜닝
from lightgbm import LGBMClassifier
lgbm_clf = LGBMClassifier(n_estimators=500)
evals = [(X_test, y_test)]
lgbm_clf.fit(X_train, y_train, early_stopping_rounds=100, eval_metric='auc', eval_set=evals, verbose=True)
lgbm_roc_score = roc_auc_score(y_test, lgbm_clf.predict_proba(X_test)[:, 1], average='macro')
print(f'ROC-AUC: {np.round(lgbm_roc_score, 4)}')[1] valid_0's auc: 0.817384 valid_0's binary_logloss: 0.165046
Training until validation scores don't improve for 100 rounds
[2] valid_0's auc: 0.818903 valid_0's binary_logloss: 0.160006
[3] valid_0's auc: 0.827707 valid_0's binary_logloss: 0.156323
[4] valid_0's auc: 0.832155 valid_0's binary_logloss: 0.153463
[5] valid_0's auc: 0.834677 valid_0's binary_logloss: 0.151256
[6] valid_0's auc: 0.834093 valid_0's binary_logloss: 0.149427
[7] valid_0's auc: 0.837046 valid_0's binary_logloss: 0.147961
[8] valid_0's auc: 0.837838 valid_0's binary_logloss: 0.146591
[9] valid_0's auc: 0.839435 valid_0's binary_logloss: 0.145455
[10] valid_0's auc: 0.83973 valid_0's binary_logloss: 0.144486
[11] valid_0's auc: 0.839799 valid_0's binary_logloss: 0.143769
[12] valid_0's auc: 0.840034 valid_0's binary_logloss: 0.143146
[13] valid_0's auc: 0.840271 valid_0's binary_logloss: 0.142533
[14] valid_0's auc: 0.840342 valid_0's binary_logloss: 0.142036
[15] valid_0's auc: 0.840928 valid_0's binary_logloss: 0.14161
[16] valid_0's auc: 0.840337 valid_0's binary_logloss: 0.141307
[17] valid_0's auc: 0.839901 valid_0's binary_logloss: 0.141152
[18] valid_0's auc: 0.839742 valid_0's binary_logloss: 0.141018
[19] valid_0's auc: 0.839818 valid_0's binary_logloss: 0.14068
[20] valid_0's auc: 0.839307 valid_0's binary_logloss: 0.140562
[21] valid_0's auc: 0.839662 valid_0's binary_logloss: 0.140353
[22] valid_0's auc: 0.840411 valid_0's binary_logloss: 0.140144
[23] valid_0's auc: 0.840522 valid_0's binary_logloss: 0.139983
[24] valid_0's auc: 0.840208 valid_0's binary_logloss: 0.139943
[25] valid_0's auc: 0.839578 valid_0's binary_logloss: 0.139898
[26] valid_0's auc: 0.83975 valid_0's binary_logloss: 0.139814
[27] valid_0's auc: 0.83988 valid_0's binary_logloss: 0.139711
[28] valid_0's auc: 0.839704 valid_0's binary_logloss: 0.139681
[29] valid_0's auc: 0.839432 valid_0's binary_logloss: 0.139662
[30] valid_0's auc: 0.839196 valid_0's binary_logloss: 0.139641
[31] valid_0's auc: 0.838891 valid_0's binary_logloss: 0.139654
[32] valid_0's auc: 0.838943 valid_0's binary_logloss: 0.1396
[33] valid_0's auc: 0.838632 valid_0's binary_logloss: 0.139642
[34] valid_0's auc: 0.838314 valid_0's binary_logloss: 0.139687
[35] valid_0's auc: 0.83844 valid_0's binary_logloss: 0.139668
[36] valid_0's auc: 0.839074 valid_0's binary_logloss: 0.139562
[37] valid_0's auc: 0.838806 valid_0's binary_logloss: 0.139594
[38] valid_0's auc: 0.839041 valid_0's binary_logloss: 0.139574
[39] valid_0's auc: 0.839081 valid_0's binary_logloss: 0.139587
[40] valid_0's auc: 0.839276 valid_0's binary_logloss: 0.139504
[41] valid_0's auc: 0.83951 valid_0's binary_logloss: 0.139481
[42] valid_0's auc: 0.839544 valid_0's binary_logloss: 0.139487
[43] valid_0's auc: 0.839673 valid_0's binary_logloss: 0.139478
[44] valid_0's auc: 0.839677 valid_0's binary_logloss: 0.139453
[45] valid_0's auc: 0.839703 valid_0's binary_logloss: 0.139445
[46] valid_0's auc: 0.839601 valid_0's binary_logloss: 0.139468
[47] valid_0's auc: 0.839318 valid_0's binary_logloss: 0.139529
[48] valid_0's auc: 0.839462 valid_0's binary_logloss: 0.139486
[49] valid_0's auc: 0.839288 valid_0's binary_logloss: 0.139492
[50] valid_0's auc: 0.838987 valid_0's binary_logloss: 0.139572
[51] valid_0's auc: 0.838845 valid_0's binary_logloss: 0.139603
[52] valid_0's auc: 0.838655 valid_0's binary_logloss: 0.139623
[53] valid_0's auc: 0.838783 valid_0's binary_logloss: 0.139609
[54] valid_0's auc: 0.838695 valid_0's binary_logloss: 0.139638
[55] valid_0's auc: 0.838868 valid_0's binary_logloss: 0.139625
[56] valid_0's auc: 0.838653 valid_0's binary_logloss: 0.139645
[57] valid_0's auc: 0.83856 valid_0's binary_logloss: 0.139688
[58] valid_0's auc: 0.838475 valid_0's binary_logloss: 0.139694
[59] valid_0's auc: 0.8384 valid_0's binary_logloss: 0.139682
[60] valid_0's auc: 0.838319 valid_0's binary_logloss: 0.13969
[61] valid_0's auc: 0.838209 valid_0's binary_logloss: 0.13973
[62] valid_0's auc: 0.83806 valid_0's binary_logloss: 0.139765
[63] valid_0's auc: 0.838096 valid_0's binary_logloss: 0.139749
[64] valid_0's auc: 0.838163 valid_0's binary_logloss: 0.139746
[65] valid_0's auc: 0.838183 valid_0's binary_logloss: 0.139805
[66] valid_0's auc: 0.838215 valid_0's binary_logloss: 0.139815
[67] valid_0's auc: 0.838268 valid_0's binary_logloss: 0.139822
[68] valid_0's auc: 0.83836 valid_0's binary_logloss: 0.139816
[69] valid_0's auc: 0.838114 valid_0's binary_logloss: 0.139874
[70] valid_0's auc: 0.83832 valid_0's binary_logloss: 0.139816
[71] valid_0's auc: 0.838256 valid_0's binary_logloss: 0.139818
[72] valid_0's auc: 0.838231 valid_0's binary_logloss: 0.139845
[73] valid_0's auc: 0.838028 valid_0's binary_logloss: 0.139888
[74] valid_0's auc: 0.837912 valid_0's binary_logloss: 0.139905
[75] valid_0's auc: 0.83772 valid_0's binary_logloss: 0.13992
[76] valid_0's auc: 0.837606 valid_0's binary_logloss: 0.139899
[77] valid_0's auc: 0.837521 valid_0's binary_logloss: 0.139925
[78] valid_0's auc: 0.837462 valid_0's binary_logloss: 0.139957
[79] valid_0's auc: 0.837541 valid_0's binary_logloss: 0.139944
[80] valid_0's auc: 0.838013 valid_0's binary_logloss: 0.13983
[81] valid_0's auc: 0.83789 valid_0's binary_logloss: 0.139874
[82] valid_0's auc: 0.837671 valid_0's binary_logloss: 0.139975
[83] valid_0's auc: 0.837707 valid_0's binary_logloss: 0.139972
[84] valid_0's auc: 0.837631 valid_0's binary_logloss: 0.140011
[85] valid_0's auc: 0.837496 valid_0's binary_logloss: 0.140023
[86] valid_0's auc: 0.83757 valid_0's binary_logloss: 0.140021
[87] valid_0's auc: 0.837284 valid_0's binary_logloss: 0.140099
[88] valid_0's auc: 0.837228 valid_0's binary_logloss: 0.140115
[89] valid_0's auc: 0.836964 valid_0's binary_logloss: 0.140172
[90] valid_0's auc: 0.836752 valid_0's binary_logloss: 0.140225
[91] valid_0's auc: 0.836833 valid_0's binary_logloss: 0.140221
[92] valid_0's auc: 0.836648 valid_0's binary_logloss: 0.140277
[93] valid_0's auc: 0.836648 valid_0's binary_logloss: 0.140315
[94] valid_0's auc: 0.836677 valid_0's binary_logloss: 0.140321
[95] valid_0's auc: 0.836729 valid_0's binary_logloss: 0.140307
[96] valid_0's auc: 0.8368 valid_0's binary_logloss: 0.140313
[97] valid_0's auc: 0.836797 valid_0's binary_logloss: 0.140331
[98] valid_0's auc: 0.836675 valid_0's binary_logloss: 0.140361
[99] valid_0's auc: 0.83655 valid_0's binary_logloss: 0.14039
[100] valid_0's auc: 0.836518 valid_0's binary_logloss: 0.1404
[101] valid_0's auc: 0.836998 valid_0's binary_logloss: 0.140294
[102] valid_0's auc: 0.836778 valid_0's binary_logloss: 0.140366
[103] valid_0's auc: 0.83694 valid_0's binary_logloss: 0.140333
[104] valid_0's auc: 0.836749 valid_0's binary_logloss: 0.14039
[105] valid_0's auc: 0.836752 valid_0's binary_logloss: 0.140391
[106] valid_0's auc: 0.837197 valid_0's binary_logloss: 0.140305
[107] valid_0's auc: 0.837141 valid_0's binary_logloss: 0.140329
[108] valid_0's auc: 0.8371 valid_0's binary_logloss: 0.140344
[109] valid_0's auc: 0.837136 valid_0's binary_logloss: 0.14033
[110] valid_0's auc: 0.837102 valid_0's binary_logloss: 0.140388
[111] valid_0's auc: 0.836957 valid_0's binary_logloss: 0.140426
[112] valid_0's auc: 0.836779 valid_0's binary_logloss: 0.14051
[113] valid_0's auc: 0.836831 valid_0's binary_logloss: 0.140526
[114] valid_0's auc: 0.836783 valid_0's binary_logloss: 0.14055
[115] valid_0's auc: 0.836672 valid_0's binary_logloss: 0.140585
Early stopping, best iteration is:
[15] valid_0's auc: 0.840928 valid_0's binary_logloss: 0.14161
ROC-AUC: 0.8409ROC-AUC가 0.8409 이며, 확실히 XGBoost보다 학습 시간이 단축된 것을 알 수 있다. 이번엔 하이퍼 파라미터 튜닝을 수행해보자.
from sklearn.model_selection import GridSearchCV
# 하이퍼 파라미터 테스트의 수행 속도를 향상시키기위해 n_estimators=200 으로 설정
lgbm_clf = LGBMClassifier(n_estimators=200)
params = {'num_leaves': [32, 64],
'max_depth': [128, 160],
'min_child_samples': [60, 100],
'subsample': [0.8, 1]}
gridcv = GridSearchCV(lgbm_clf, param_grid=params, cv=3)
gridcv.fit(X_train, y_train, early_stopping_rounds=30, eval_metric='auc', eval_set=[(X_train, y_train), (X_test, y_test)])
print(f'GridSearchCV 최적 파라미터: {gridcv.best_params_}')
lgbm_roc_score = roc_auc_score(y_test, gridcv.predict_proba(X_test)[:, 1], average='macro')
print(f'ROC-AUC: {np.round(lgbm_roc_score, 4)}')GridSearchCV 최적 파라미터: {'max_depth': 128, 'min_child_samples': 100, 'num_leaves': 32, 'subsample': 0.8}
ROC-AUC: 0.8417lgbm_clf = LGBMClassifier(n_estimators=1000,max_depth=128, min_child_samples=100, num_leaves=32, subsample=0.8)
evals = [(X_test, y_test)]
lgbm_clf.fit(X_train, y_train, early_stopping_rounds=100, eval_metric='auc', eval_set=evals, verbose=True)
lgbm_roc_score = roc_auc_score(y_test, lgbm_clf.predict_proba(X_test)[:, 1], average='macro')
print(f'ROC-AUC: {np.round(lgbm_roc_score, 4)}')ROC-AUC: 0.84170.8417로 측정됐다.
파이썬 머신러닝 완벽 가이드 / 위키북스
