데이터는 과거 줄기차게 만들었으니 JSON 데이터로 수집하던 로직만 Text 데이터로 형식만 바꾸고 진행 했다
이제 적재할 벡터 DB를 만들고 넣는것 까지 해본다
오픈소스이자 무료인 Pinecone채택
Pinecoe홈페이지에서 회원가입하고 API KEY를 발급받는다
Pinecone API에 접근하기 위해 라이브러리는 langchain, pinecone, openai가 있다
import os
import time
from langchain_community.document_loaders import DirectoryLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from pinecone.grpc import PineconeGRPC as Pinecone
from pinecone import ServerlessSpec
from langchain_pinecone import PineconeVectorStore
from langchain_openai import OpenAIEmbeddingsapi키를 통해 db connection을 시도한다
pc = Pinecone(api_key='YOUR_API_KEY')
index_name = "YOUR_INDEX_NAME"
if index_name not in pc.list_indexes().names(): # 인덱스가 없으면 생성
pc.create_index(
name=index_name,
dimension=2,
metric="cosine",
spec=ServerlessSpec(
cloud='aws',
region='us-east-1'
)
)코드에서는 index_name을 기준으로 없다면 생성하고 존재하면 그대로 진행하고 있지만
Pinecone 대쉬보드에서 생성해서 진행해도 무관하다
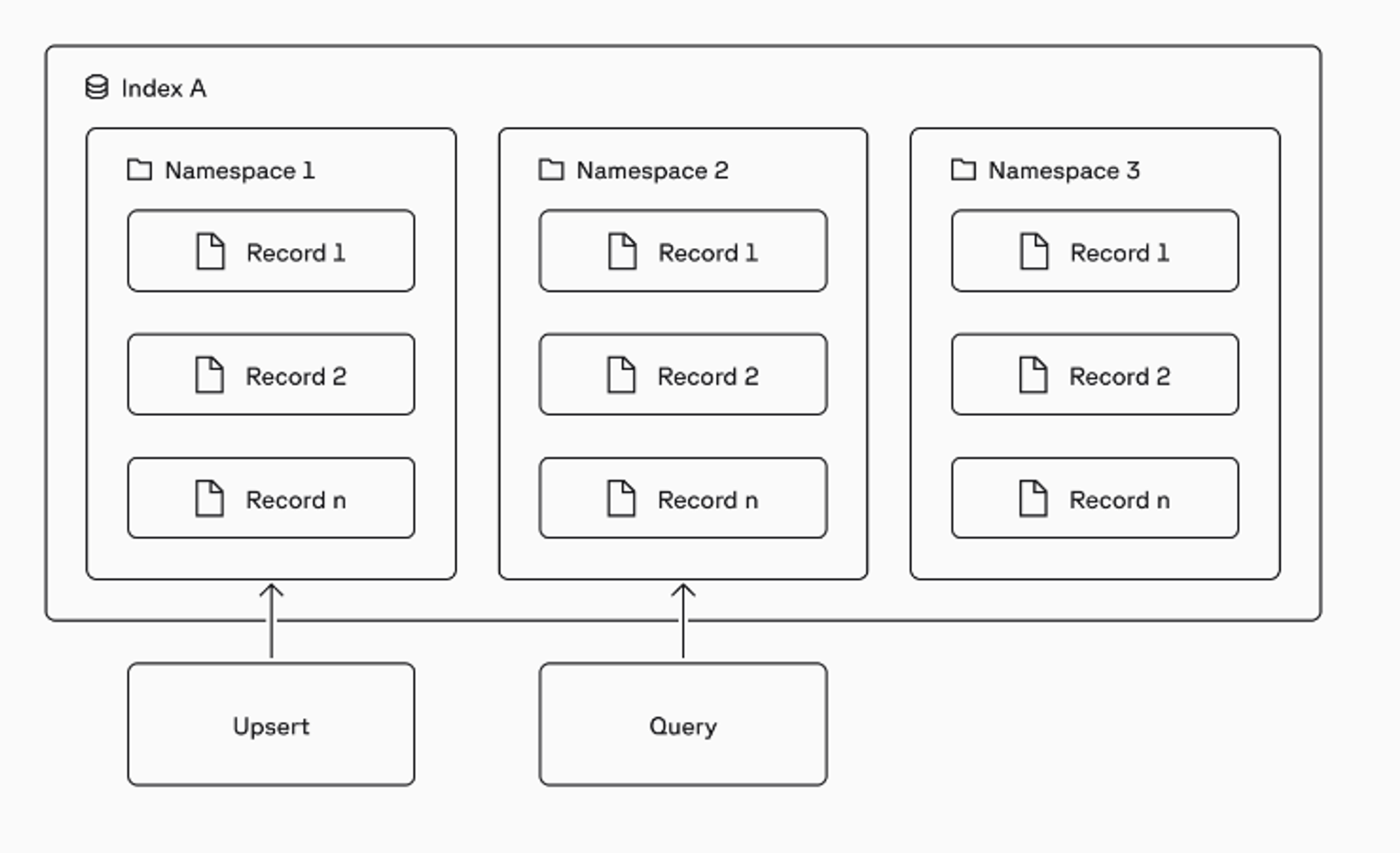
각각의 벡터는 namespaces에 저장되고 모든 upsert, query 기타 작업은 항상 하나의 namespace를대상으로 한다
간단한 2차원 벡터를 생성하여 네임스페이스에 저장해본다
index = pc.Index(index_name)
index.upsert(
vectors=[
{"id": "vec1", "values": [1.0, 1.5]},
{"id": "vec2", "values": [2.0, 1.0]},
{"id": "vec3", "values": [0.1, 3.0]},
],
namespace="ns1"
)저장된 결과는 두가지 방법으로 확인 가능
# 코드로 확인
print(index.describe_index_stats())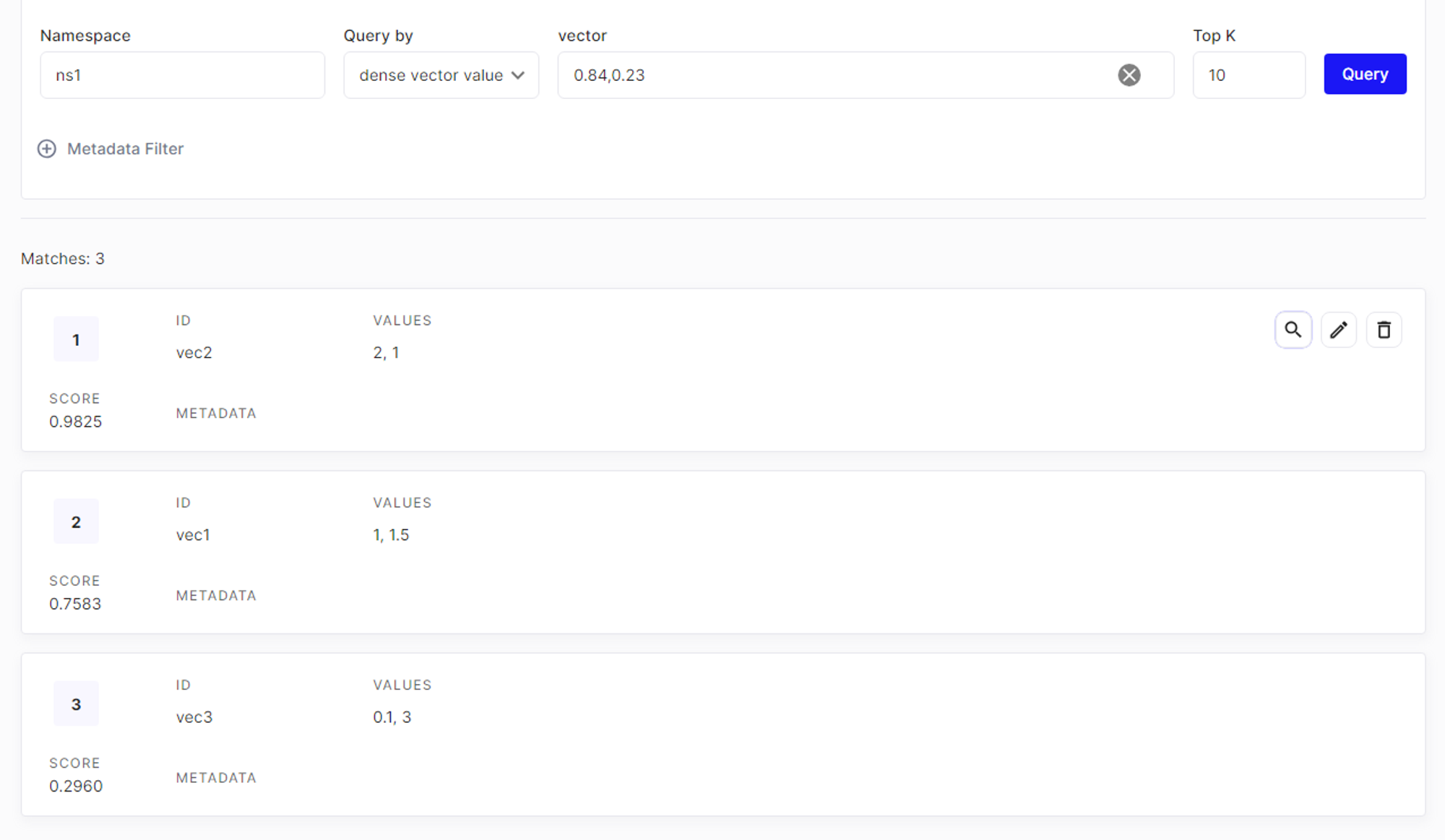
실제 데이터로 해본다.
# 데이터 로드 및 분할
loader = DirectoryLoader(".", glob="data/*.txt", show_progress=True) # (1)
docs = loader.load()
text_splitter = RecursiveCharacterTextSplitter( # (2)
chunk_size=300, # (3)
chunk_overlap=50, # (4)
length_function=len,
is_separator_regex=False
)
all_splits = text_splitter.split_documents(docs)(1) show_progress 옵션으로 파일 로드 현황파악 가능
(2) 재귀방식으로 청크 분리 사용
(3) chunk size : 벡터화 과정에서 문서를 나누는 단위의 크기 (200~500이 적당함)
(4) chunk overlap : 청크 간에 중복되는 부분을 설정
(1) 파일 로드 옵션
- 파일이 많을 땐 기다리면서 게이지 차는거 구경하면서 시간을 보내는것도 나쁘지 않다:)
(2) 재귀적 문자 텍스트 분할 (RecursiveCharacterTextSplitter)
- 이 텍스트 분할기는 일반적인 텍스트에 권장되는 방식 이 분할기는 문자 목록을 매개변수로 받아 동작함. 분할기는 청크가 충분히 작아질 때까지 주어진 문자 목록의 순서대로 텍스트를 분할하려고 시도 기본 문자 목록은
["\n\n", "\n", " ", ""]
(3) 청크 사이즈:
- 임베딩할 때
chunk_size의 크기는 벡터화 과정에서 문서를 나누는 단위의 크기를 결정합니다.chunk_size가 클 경우와 작은 경우의 각각의 장단점을 이해하면 보다 효율적인 벡터화 및 검색이 가능chunk_size크기에 따른 변화-
큰
chunk_size:장점:
- 문맥 유지: 큰 chunk는 더 많은 문맥을 포함하므로, 의미를 더 잘 유지할 수 있음
- 적은 요청 수: 큰 chunk를 사용하면 전체 문서를 처리하기 위해 필요한 요청 수가 줄 수 있음
단점:
- 과도한 정보: 너무 많은 정보를 포함하면, 불필요한 정보가 포함될 수 있음
- 비효율적인 검색: 검색의 정밀도가 떨어질 수 있습니다. 검색 시 관련 없는 정보도 함께 반환될 수 있음
-
작은
chunk_size:장점:
- 정밀한 검색: 작은 chunk는 특정 정보에 대한 검색 정밀도가 높아질 수 있습니다
- 적은 리소스 사용: 각 요청당 처리해야 할 데이터가 적어 리소스 사용이 줄 수 있음
단점:
- 문맥 손실: 너무 작은 chunk는 문맥을 잃기 쉬워, 의미를 제대로 파악하기 어려움
- 많은 요청 수: 전체 문서를 처리하기 위해 더 많은 요청이 필요할 수 있음
-
(4) 오버랩
- Overlap의 크기
-
작은
Overlap(예: 0-50 단어)장점:
- 효율성: 저장 공간과 검색 속도 면에서 효율적
- 명확성: 각 청크가 명확하게 구분되어 중복된 정보를 최소화
단점:
- 문맥 손실: 청크 간 문맥이 잘리지 않고 연결되도록 하기 어려울 수 있음
- 검색 정밀도: 중요한 정보를 놓칠 가능성이 있음
-
큰 Overlap (예: 50-150 단어)
장점:
- 문맥 유지: 각 청크에 문맥이 더 잘 유지되어 의미를 파악하기 쉬움
- 검색 정밀도 향상: 검색 시 더 많은 관련 정보를 포함할 수 있음
단점:
- 비효율성: 더 많은 저장 공간을 사용하고, 검색 속도가 느려질 수 있음
- 중복 정보: 각 청크에 중복된 정보가 포함되어 효율성이 떨어질 수 있음
-
설정을 모두 마치고 이제 DB로 임베딩하여 적재할 것인데 임베딩 모델로는 OpenAI를 사용하였다
위에서 청크 단위로 쪼갠 데이터를 벡터화 하여 데이터 베이스에 적재하고
이 데이터를 GPT가 꺼내서 읽을 때는 데이터의 차원간의 유사도 검색을 통해 인접 데이터 조각을 모아서 답변을 생성할 것 이다
embeddings_model = OpenAIEmbeddings()
namespace = "test1"
docsearch = PineconeVectorStore.from_documents(
documents=all_splits,
embedding=embeddings_model,
index_name=index_name,
namespace=namespace
)추후 임베딩 모델로 한글 데이터 높은 지표를 가지고 있다고 하는 HUGGINGFACE로 전환도 고려중
Referece
LangChain RAG 파헤치기: 문서 기반 QA 시스템 설계 방법 - 심화편
The vector database to build knowledgeable AI | Pinecone
