
PyTorch를 이용한 실습 흐름
◾️ 1. 간단한 CNN 모델을 구축 및 이미지 분류 모델 학습
◾️ 2. 모델 학습 이후 이미지 특성맵을 활용하여 이미지 간 유사도 계산
CIFAR-10 이미지 데이터셋 전처리 및 유사도 계산
◾️ 1. 이미지 데이터 전처리
◾️ 2. 이미지 간 유사도 계산
📂 CIFAR-10 데이터셋 준비

🔖 CIFAR-10
- CIFAR-10은 10개의 클래스(비행기, 자동차, 새, 고양이, 사슴, 개, 개구리, 말, 배, 트럭)로 구성
- 총 6만 개의 이미지 데이터셋
- 각 이미지는 32 × 32 크기의 작은 컬러 이미지
CIFAR-10 and CIFAR-100 datasets
torchvision 패키지를 이용해 이미지 불러오기
import matplotlib.pyplot as plt
import numpy as np
import torch
import torchvision
from torchvision import datasets, transforms
# CIFAR-10 데이터셋에 대한 전처리 설정
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
# CIFAR-10 training dataset 불러오기
train_dataset = datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
# CIFAR-10 test dataset 불러오기
test_dataset = datasets.CIFAR10(root='./data', train=False, download=True, transform=transform)
# CIFAR-10 데이터셋으로부터 클래스 레이블 가져오기
class_labels = train_dataset.classes
🔖 CIFAR-10 데이터 살펴보기
데이터가 어떤 환경에서 만들어졌고, 각 카테고리별로 주요 특징이 무엇인지 파악하는 과정은 중요함
- bird 레이블을 가진 이미지는 머리 부분만 포함하지만, ship 레이블을 가진 이미지는 배의 전체 이미지를 포함하고 있음을 알 수 있음
- 이는 각 이미지는 서로 다른 환경에서 촬영됐고 같은 레이블을 가지고 있다 하더라도 그 환경은 완전히 다를 수 있음을 의미함

# 이미지와 레이블을 함께 출력하는 함수
def imshow(images, labels):
batch_size = images.shape[0]
fig, axarr = plt.subplots(1, batch_size, figsize=(10, 4))
for i in range(batch_size):
img = images[i] / 2 + 0.5 # 정규화 복원
npimg = img.numpy()
axarr[i].imshow(np.transpose(npimg, (1, 2, 0)))
axarr[i].set_title(class_labels[labels[i].item()])
axarr[i].axis('off')
plt.show()
# 학습 데이터의 일부를 가져옴
dataloader = torch.utils.data.DataLoader(train_dataset, batch_size=4, shuffle=True)
images, labels = next(iter(dataloader))
# 이미지와 레이블을 함께 출력
imshow(images, labels)
📂 CNN 모델 정의
👩🏻💻 전체 코드 예시
# 필요한 라이브러리 불러오기
import torch
from torch import nn
import torch.optim as optim
from torch.nn import functional as F
from sklearn.metrics.pairwise import cosine_similarity
import numpy as np
from tqdm.auto import tqdm
# 간단한 CNN 모델 정의하기
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv1 = nn.Conv2d(3, 32, 3, padding=1) # 3개의 입력 채널, 32개의 출력 채널, 3x3 커널 크기, 패딩=1
self.relu1 = nn.ReLU() # ReLU 활성화 함수
self.conv2 = nn.Conv2d(32, 64, 3, padding=1) # 32개의 입력 채널, 64개의 출력 채널, 3x3 커널 크기, 패딩=1
self.relu2 = nn.ReLU()
self.pool = nn.MaxPool2d(2, 2) # 2x2 커널 크기와 2의 스트라이드를 사용하는 Max Pooling
self.flatten = nn.Flatten() # 완전 연결 계층(FC Layer)을 통과하기 위한 텐서 평탄화
self.fc1 = nn.Linear(64 * 8 * 8, 512) # 64x8x8의 입력 특성, 512개의 출력 특성을 가지는 완전 연결층
# 64: 두 번째 합성곱 레이어에서 출력된 채널 수입니다. 즉, 각 위치에서 64개의 특성 맵이 생성되었습니다.
# 8x8: 두 번째 합성곱 레이어의 출력 특성맵의 공간 크기입니다. 이는 입력 이미지의 공간 해상도가 합성곱과 풀링 연산을 거치면서 감소한 결과입니다.
self.relu3 = nn.ReLU() # ReLU 활성화 함수
self.fc2 = nn.Linear(512, 10) # 512개의 입력 특성, 10개(레이블 개수) 출력 특성을 가지는 완전 연결층
def forward(self, x):
x = self.conv1(x) # 입력: (N, 3, 32, 32), 출력: (N, 32, 32, 32) N은 배치 사이즈
x = self.relu1(x)
x = self.pool(x) # 입력: (N, 32, 32, 32), 출력: (N, 32, 16, 16)
x = self.conv2(x) # 입력: (N, 32, 16, 16), 출력: (N, 64, 16, 16)
x = self.relu2(x)
x = self.pool(x) # 입력: (N, 64, 16, 16), 출력: (N, 64, 8, 8)
x = self.flatten(x) # 2D 텐서로 평탄화, 입력: (N, 64, 8, 8), 출력: (N, 64*8*8)
x = self.fc1(x) # 입력: (N, 64*8*8), 출력: (N, 512)
x = self.relu3(x)
x = self.fc2(x) # 입력: (N, 512), 출력: (N, 10)
return x
🔖 모델 정의 및 합성곱 계층
- 필요한 라이브러리를 불러옴
nn.Module을 활용하여 모델을 정의함nn.Conv2d()에 들어가는 인자값들의 의미에 주목
self.conv1 = nn.Conv2d(3, 32, 3, padding=1)
# 3개의 입력 채널, 32개의 출력 채널, 3x3 커널 크기, 패딩=1
(1) 3개의 입력 채널: 컬러 이미지의 RGB(3차원) 채널
(2) 32개의 출력 채널: 3개의 출력 채널을 32차원으로 확장하겠다는 의미
(3) 3x3 커널크기, 패딩=1"커널"은 행렬 형태의 작은 필터
커널의 크기가 3, 패딩이 1, 보폭(Stride)가 1인 경우 입력과 출력의 사이즈가 달라지지 않습니다. 커널의 크기, 패딩, 보폭에 따라 출력 사이즈를 계산하는 식은 다음과 같습니다.
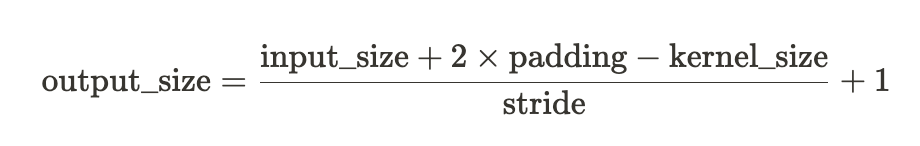
그래서 해당 층을 통과하게 되면 입력된 이미지 크기와 동일한 특성맵이 생성되고 (N, 32, 32, 32) 사이즈로 출력되게 됩니다. 순서대로 살펴보면, N은 배치 사이즈로 이후 지정할 값입니다. 두 번째 값 32는 출력 채널을 의미합니다. 세 번째와 네 번째는 이미지의 특성맵 사이즈를 의미합니다.
🔖 MaxPooling 계층
이번에는 nn.MaxPool2d에 대해 살펴보겠습니다.
# 간단한 CNN 모델 정의하기
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv1 = nn.Conv2d(3, 32, 3, padding=1) # 3개의 입력 채널, 32개의 출력 채널, 3x3 커널 크기, 패딩=1
self.relu1 = nn.ReLU() # ReLU 활성화 함수
self.conv2 = nn.Conv2d(32, 64, 3, padding=1) # 32개의 입력 채널, 64개의 출력 채널, 3x3 커널 크기, 패딩=1
self.relu2 = nn.ReLU()
self.pool = nn.MaxPool2d(2, 2) # 2x2 커널 크기와 2의 스트라이드를 사용하는 Max Pooling
...
def forward(self, x):
x = self.conv1(x) # 입력: (N, 3, 32, 32), 출력: (N, 32, 32, 32) N은 배치 사이즈
x = self.relu1(x)
x = self.pool(x) # 입력: (N, 32, 32, 32), 출력: (N, 32, 16, 16)
...
첫 번째 인자값 2는 2 × 2의 커널 크기를 의미합니다. 두 번째는 2의 보폭(Stride)을 의미합니다.
해당 층을 통과하면서 특성맵의 사이즈는 입력 사이즈의 절반인 (16, 16)으로 줄어듭니다.
이를 계산하는 공식은 아래와 같습니다.

그래서 이 MaxPooling 층을 통과하면 (N, 32, 16, 16)의 사이즈를 갖게 됩니다.
🔖 평탄화(Flatten) 및 완전 연결 계층
# 간단한 CNN 모델 정의하기
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
...
self.flatten = nn.Flatten() # 완전 연결 계층(FC Layer)을 통과하기 위한 텐서 평탄화
self.fc1 = nn.Linear(64 * 8 * 8, 512) # 64x8x8의 입력 특성, 512개의 출력 특성을 가지는 완전 연결층
...
def forward(self, x):
x = self.conv1(x) # 입력: (N, 3, 32, 32), 출력: (N, 32, 32, 32) N은 배치 사이즈
x = self.relu1(x)
x = self.pool(x) # 입력: (N, 32, 32, 32), 출력: (N, 32, 16, 16)
x = self.conv2(x) # 입력: (N, 32, 16, 16), 출력: (N, 64, 16, 16)
x = self.relu2(x)
x = self.pool(x) # 입력: (N, 64, 16, 16), 출력: (N, 64, 8, 8)
x = self.flatten(x) # 2D 텐서로 평탄화, 입력: (N, 64, 8, 8), 출력: (N, 64*8*8)
...
이와 같은 식으로 도달하게 되면 평탄화 계층 직전까지 (N, 64, 8, 8) 사이즈를 가지게 됩니다. 평탄화는 배치 사이즈를 제외한 나머지 3개의 차원을 모두 1차원으로 변환하는 작업입니다. 이때 각 채널, 이미지 가로, 세로 사이즈를 모두 곱한 만큼의 크기로 바뀝니다. 결과적으로 입력 크기는 64 ✕ 8 ✕ 8만큼의 값을 갖게 됩니다.
self.fc2 = nn.Linear(512, 10) # 512개의 입력 특성, 10개(레이블 개수) 출력 특성을 가지는 완전 연결층
마무리 단계에서 클래스의 개수만큼의 값을 지정합니다.
CIFAR-10 데이터셋에는 총 10개의 클래스가 있으므로 10으로 지정합니다.
📂 CNN 모델 학습
🔖 손실 함수와 옵티마이저 정의
분류 문제에서 자주 활용되는 손실 함수 중 하나가 Cross Entropy입니다. nn.CrossEntropyLoss()에는 softmax 함수가 내장되어 있습니다.
그리고 성능이 준수한 옵티마이저 Adam을 설정합니다.
# CNN 모델의 인스턴스 생성
model = CNN()
# 손실 함수와 옵티마이저 정의
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
🔖 훈련 및 테스트
이후 에폭(Epoch)과 배치 사이즈를 지정하여 학습을 진행합니다.
# 훈련 루프
num_epochs = 10
batch_size = 64
train_dataloader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
for epoch in range(num_epochs):
running_loss = 0.0
for i, data in enumerate(train_dataloader):
inputs, labels = data
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
if i % 100 == 99:
print(f'Epoch {epoch+1}, Batch {i+1}/{len(train_dataloader)}, Loss: {running_loss/100:.4f}')
running_loss = 0.0
Colab의 CPU를 활용하여 약 20분이 소요됐습니다.
훈련 후 최종 손실값은 약 0.07 정도로 낮게 나왔습니다.
# 테스트 루프
test_dataloader = torch.utils.data.DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
total_correct = 0
total_samples = 0
with torch.no_grad():
for data in test_dataloader:
inputs, labels = data
outputs = model(inputs)
_, predicted = torch.max(outputs.data, 1)
total_samples += labels.size(0)
total_correct += (predicted == labels).sum().item()
accuracy = 100 * total_correct / total_samples
print(f'Test Accuracy: {accuracy:.2f}%')
>>> Test Accuracy: 71.39%
그러나 테스트 데이터의 정확도는 71% 정도를 기록했습니다.
약간의 과적합이 의심됩니다. 일단 시간을 들여 훈련을 진행한 만큼 모델을 저장하겠습니다.
모델 저장
# 모델 저장하기
torch.save(model.state_dict(), 'model.pth')
# 모델 불러오기
model = CNN()
model.load_state_dict(torch.load('model.pth'))
📂 이미지 유사도 계산
🔖 쿼리이미지
쿼리 이미지는 주로 유사한 이미지를 찾거나 패턴을 식별하기 위한 기준 이미지를 말함
1. 쿼리 이미지 불러오기
2. 학습한 모델을 활용하여 쿼리 이미지의 특성 추론
3. 다른 이미지 특성 추론 후 코사인 유사도계산코사인 유사도: 0이 아닌 두 벡터(Vector) 간의 유사도를 측정하는 척도, 벡터 사이 각도의 코사인 값
import matplotlib.pyplot as plt
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
# 모델을 평가 모드로 설정
model.eval()
# 테스트 데이터셋에서 쿼리 이미지 선택
query_image_index = 1
query_image, query_label = test_dataset[query_image_index]
# 쿼리 이미지에 대해 추론 수행
with torch.no_grad():
query_image = query_image.unsqueeze(0)
query_features = model(query_image)
# 데이터셋 내 다른 이미지들과의 코사인 유사도 계산
similarities = []
for i in range(len(test_dataset)):
# 데이터셋으로부터 다른 이미지와 해당 레이블 가져오기
image, _ = test_dataset[i]
# 이미지 텐서에 배치 차원 추가
image = image.unsqueeze(0)
# 모델을 통과하여 특성 추출
features = model(image)
# 쿼리 이미지와의 코사인 유사도 계산
similarity = cosine_similarity(query_features.detach().numpy(), features.detach().numpy())
# 코사인 유사도와 해당 이미지 인덱스를 similarities 리스트에 저장
similarities.append((i, similarity.item()))
🔖 쿼리이미지와 유사한 이미지 시각화
계산한 코사인 유사도 값에 따라 내림차순으로 정렬하고 시각화 합니다.
유사도가 1로 나오는 것은 완전히 동일한 이미지 즉, 쿼리 이미지를 의미합니다.
# 유사도 값 내림차순 정렬
similarities.sort(key=lambda x: x[1], reverse=True)
# 상위 K개의 이미지 시각화
top_k = 5
fig, axes = plt.subplots(1, top_k, figsize=(6, 3))
for i, (image_index, similarity) in enumerate(similarities[:top_k]):
image, _ = test_dataset[image_index]
# 넘파이로 변환
image_np = image.permute(1, 2, 0).detach().numpy()
# 이미지 픽셀값 [0, 1]로 스케일링
image_np = (image_np - np.min(image_np)) / (np.max(image_np) - np.min(image_np))
# imshow를 위해서 RGB data ([0..1] for floats or [0..255] for integers) 사이의 값으로 정의해야 합니다.
# subplot으로 시각화
axes[i].imshow(image_np)
axes[i].axis('off')
axes[i].set_title(f'Similarity: {similarity:.4f}', fontsize=8)
plt.tight_layout()
plt.show()
📂 사전 훈련 모델 ResNet 활용하기
- 직접 모델을 구축하고 활용하기보다는 이미 학습된 모델을 불러와 활용하는 경우가 많음
- ResNet 모델 예시
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision.models import resnet18
from torchvision.datasets import CIFAR10
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
from tqdm.auto import tqdm
# 디바이스 설정 (GPU 사용 가능하면 GPU, 아니면 CPU)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# CIFAR-10 데이터셋에 대한 전처리 설정
transform = transforms.Compose([
transforms.RandomHorizontalFlip(), # 무작위로 이미지 좌우 반전
transforms.RandomCrop(32, padding=4), # 무작위로 이미지 자르기 (32x32 크기로 자르고 패딩은 4로 설정)
transforms.ToTensor(), # 이미지를 텐서로 변환
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) # 이미지를 정규화
])
# CIFAR-10 데이터셋 로드
train_dataset = CIFAR10(root='./data', train=True, download=True, transform=transform)
test_dataset = CIFAR10(root='./data', train=False, download=True, transform=transform)
# 데이터 로더 정의
train_loader = DataLoader(train_dataset, batch_size=128, shuffle=True, num_workers=4)
test_loader = DataLoader(test_dataset, batch_size=128, shuffle=False, num_workers=4)
# 사전 훈련된 ResNet 모델 불러오기
model = resnet18(pretrained=True)
num_features = model.fc.in_features
model.fc = nn.Linear(num_features, 10) # CIFAR-10 분류를 위해 마지막의 fully connected layer 수정
model = model.to(device)
# 손실 함수와 옵티마이저 정의
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.01)
# 훈련 루프
num_epochs = 50
model.train()
for epoch in tqdm(range(num_epochs)):
running_loss = 0.0
correct = 0
total = 0
for batch_idx, (inputs, targets) in enumerate(train_loader):
inputs, targets = inputs.to(device), targets.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, targets)
loss.backward()
optimizer.step()
running_loss += loss.item()
_, predicted = outputs.max(1)
total += targets.size(0)
correct += predicted.eq(targets).sum().item()
if batch_idx % 100 == 99:
print(f"Epoch [{epoch+1}/{num_epochs}], Batch [{batch_idx+1}/{len(train_loader)}], "
f"Loss: {running_loss / 100:.4f}, Accuracy: {100 * correct / total:.2f}%")
running_loss = 0.0
# 테스트 루프
model.eval()
correct = 0
total = 0
with torch.no_grad():
for inputs, targets in test_loader:
inputs, targets = inputs.to(device), targets.to(device)
outputs = model(inputs)
_, predicted = outputs.max(1)
total += targets.size(0)
correct += predicted.eq(targets).sum().item()
# 테스트셋의 정확도 출력
print(f"테스트 정확도: {100 * correct / total:.2f}%")
[출처 | 딥다이브 Code.zip 매거진]
