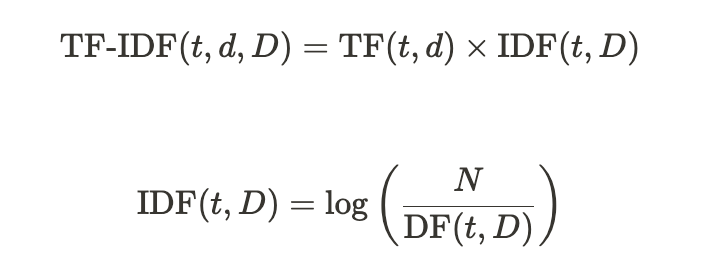
📂 TF-IDF
TF-IDF는 "다른 문서에서는 등장하지 않지만 특정 문서에서만 자주 등장하는 단어를 찾아내 문서 내 중요한 단어의 가중치를 계산하는 방법"
📚 TP-IDF 개념
- TF-IDF는 문서의 특징을
숫자화(벡터화)하고자 활용되는 방법 - 문서를 벡터화하고 나면 문서 분류, 문서 간 유사도 등 다양한 작업이 가능함
? TP : 빈도만 고려
- 빈도 ➡️ 특정 단어가 자주 사용되면 중요한 개념으로 인식
TF(Term Frequency): 특정 단어가 얼마나 자주 등장하는지TF는 단어의 빈도수 만 고려함 (단어의 중요성을 고려하지 X)- 불용어(Stopwords)를 포함하는 문제
? TP-IDF: 빈도, 중요성 동시 고려
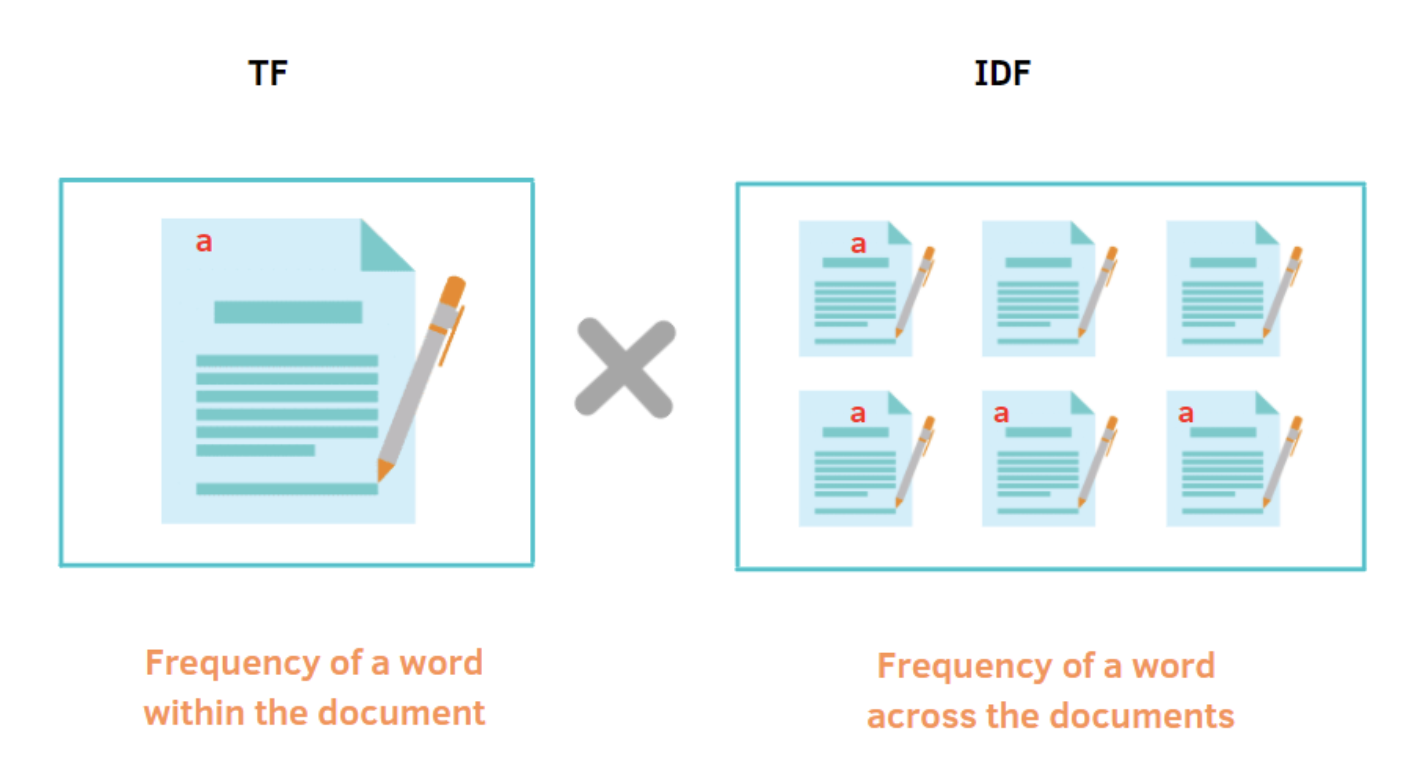
TF-IDF는 Term Frequency-Inverse Document Frequency의 약자로, TF와 다르게 단어의 중요성을 고려하는 방법임- TF-IDF는 TF 값에 IDF(Inverse Document Frequency) 값을 곱하는 방식으로 계산함
IDF: 특정 단어가 얼마나 많은 문서에 등장하는지를 반비례(Inverse)한 값- 흔하게 등장하는 불용어들은 IDF값이 작아져서 전체적으로 TF-IDF값이 작아짐
- 특정 문서에만 자주 등장하는 단어는 상대적으로 높은 IDF 값을 갖게 되어 전체적으로 TF-IDF값이 커짐
📚 TP-IDF 원리와 공식
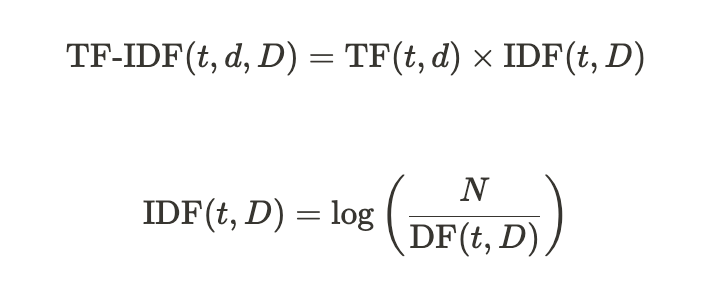
- t: 단어 (Term)
- d: 특정 문서 (Document)
- D: 전체 문서 집합 (Document Collection)
- TF(t, d): 특정 문서 d에서의 단어 t의 출현 빈도(Term Frequency)
- IDF(t, D): 전체 문서 집합 D에서의 단어 t의 역문서 빈도(Inverse Document Frequency)
🎈 TP-IDF 예시
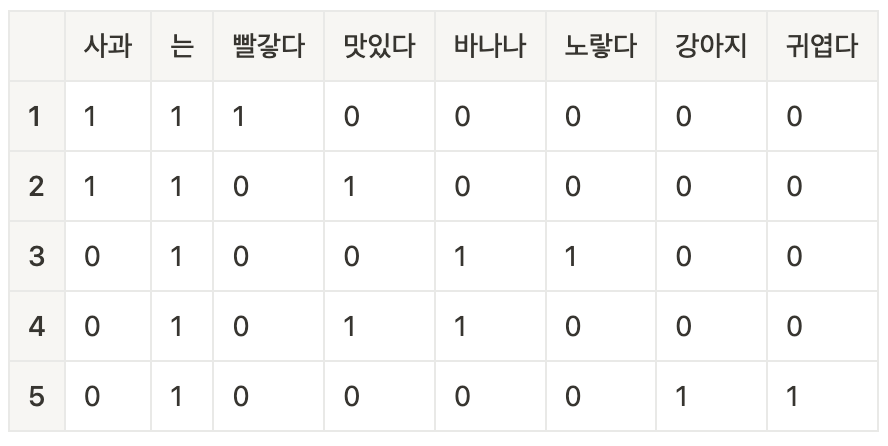
(1)5개 한국어 문장 예시
1. 사과는 빨갛다.
2. 사과는 맛있다.
3. 바나나는 노랗다.
4. 바나나는 맛있다.
5. 강아지는 귀엽다.
(2)TF(Term Frequency) 계산
(3)IDF(Inverse Document Frequency) 계산

(4)TF-IDF 계산
- IDF 값을 TF에 곱해주면 TF-IDF 계산 가능
- '는'이라는 불용어의 IDF가 log(5/5)가 되므로 이 단어의 TF-IDF 값은 0
- TF-IDF는 불용어의 중요도를 낮추는 효과
📚 TP-IDF 장단점
🎈 TP-IDF 장점
1. 단어의 상대적 중요도를 고려한 가중체 계산 및 강조 가능
2. 불용어 제거 가능
3. 벡터표현
- 문서간의 유사도를 계산 가능
- 다양한 머신러닝 알고리즘에 적용 가능
🎈 TP-IDF 단점
- 단어의 순서 정보 손실
- 단어의 등장 빈도에 기반하여 가중치를 계산하므로 단어의 순서 정보를 고려하지 않음
- 보완)
N-gram모델 등의 접근방식 활용
- 단어의 다의성 처리 어려움
- 한 단어가 다양한 의미를 가질 수 있는 경우, TF-IDF가 의미를 구분 X
- bank -> 은행 or 강둑
- 데이터 희소성 문제
- 데이터 희소성으로 인해 모델의 성능이 저하될 수 있음
- 보완) 차원 축소 기법이나 다른 벡터화 방법을 적용
📚 TP-IDF 텍스트 분류 예제
TF-IDF 변환 후, 로지스틱 회귀 모델 학습
(0) 데이터셋 가져오기
from sklearn.datasets import fetch_20newsgroups
# 데이터셋 가져오기
newsgroups_data = fetch_20newsgroups(subset='all', shuffle=True, random_state=42, remove=('headers', 'footers', 'quotes'))
# 데이터 확인
print("뉴스 그룹 주제:", newsgroups_data.target_names)
print("뉴스 기사 수:", len(newsgroups_data.data))
print("첫 번째 뉴스 기사:\n", newsgroups_data.data[0])
print("첫 번째 뉴스 기사 주제:", newsgroups_data.target[0])
>>>
뉴스 그룹 주제: ['alt.atheism', 'comp.graphics',
'comp.os.ms-windows.misc', 'comp.sys.ibm.pc.hardware',
'comp.sys.mac.hardware', 'comp.windows.x',
'misc.forsale', 'rec.autos',
'rec.motorcycles', 'rec.sport.baseball',
'rec.sport.hockey', 'sci.crypt',
'sci.electronics', 'sci.med',
'sci.space', 'soc.religion.christian',
'talk.politics.guns', 'talk.politics.mideast',
'talk.politics.misc', 'talk.religion.misc']
뉴스 기사 수: 18846
첫 번째 뉴스 기사:
I am sure some bashers of Pens fans are pretty confused about the lack
of any kind of posts about the recent Pens massacre of the Devils. Actually,
I am bit puzzled too and a bit relieved. However, I am going to put an end
to non-PIttsburghers' relief with a bit of praise for the Pens. Man, they
are killing those Devils worse than I thought. Jagr just showed you why
he is much better than his regular season stats. He is also a lot
fo fun to watch in the playoffs. Bowman should let JAgr have a lot of
fun in the next couple of games since the Pens are going to beat the pulp out of Jersey anyway. I was very disappointed not to see the Islanders lose the final
regular season game. PENS RULE!!!
첫 번째 뉴스 기사 주제: 10- 총 20개의 분류를 가지고 있고, 각 기사마다 타깃 테이블을 가지고 있음
- 위의 예시의 경우, 11번째 레이블(0부터 시작이여서 10은 11번째임)이 타겟 테이블인
rec.sport.hockey에 해당
(1) 필요한 라이브러리 임포트
- 데이터셋 가져오는 라이브러리, TF-IDF수행 라이브러리
- 모델학습 라이브러리:
LogisticRegression, - 전처리 라이브러리:
stopwords(불용어 처리),PorterStemmer(어간 추출)
from sklearn.datasets import fetch_20newsgroups
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
import re
from nltk.corpus import stopwords
from nltk.stem import PorterStemmer(2) 텍스트 데이터 전처리
- preprocess 함수를 정의
- 모든 단어를 소문자로 변환, 불용어를 제거, 어간 추출
# 전처리 함수 정의
def preprocess(text):
# 1. 특수 문자 제거
text = re.sub(r'[^\w\s]', '', text)
# 2. 소문자 변환
text = text.lower()
# 3. 토큰화
tokens = text.split()
# 4. 불용어 제거
stop_words = set(stopwords.words('english'))
tokens = [token for token in tokens if token not in stop_words]
# 5. 어간 추출
stemmer = PorterStemmer()
tokens = [stemmer.stem(token) for token in tokens]
# 6. 토큰들을 다시 문서 형태로 반환
return ' '.join(tokens)(3) 데이터 불러오기
- fetch_20newsgroups 함수를 사용하여 20개의 뉴스 그룹 데이터셋을 가져옴
- 데이터 중에서 헤더(Header), 푸터(Footer), 인용구 제거
- 실제 데이터는 약 18000개이나, 5000개만 가지고 옴
# 20개의 뉴스 그룹 데이터 세트 가져오기 (5000개 데이터만)
newsgroups_data = fetch_20newsgroups(subset='all', shuffle=True, random_state=42, remove=('headers', 'footers', 'quotes'))
newsgroups_data.data = newsgroups_data.data[:5000]
newsgroups_data.target = newsgroups_data.target[:5000](4) TfidfVectorizer 객체 생성
-
TfidfVectorizer를 사용하여TF-IDF객체를 생성
- 이 변환기는 텍스트 데이터를 TF-IDF 행렬로 변환하는 역할을 함
-
preprocessor의 인자로preprocess함수 적용 -
fit_transform메소드를 사용하여 텍스트 데이터를 TF-IDF 행렬로 변환
# TF-IDF 객체 생성 (전처리 함수 적용)
vectorizer = TfidfVectorizer(preprocessor=preprocess)
# 문서 집합을 TF-IDF 행렬로 변환
tfidf_matrix = vectorizer.fit_transform(newsgroups_data.data)
(5) Logistic Regression 모델 학습
tfidf_matrix를 학습 데이터와 테스트 데이터로 나눔- `LogisticRegression을 사용하여 로지스틱 회귀 모델을 생성하고, fit 메소드를 사용하여 이 모델을 학습 데이터에 맞게 학습
# 학습 데이터와 테스트 데이터로 분할
X_train, X_test, y_train, y_test = train_test_split(tfidf_matrix, newsgroups_data.target, test_size=0.2, random_state=42)
# 로지스틱 회귀 분류 모델 구축
model = LogisticRegression(C=1.0, max_iter=1000)
model.fit(X_train, y_train)(6) 테스트 데이터 예측
predict메소드를 이용해 예측 수행- 예측결과와 실제 라벨을 비교하여 모델의 예측 정확도를 계산하고 출력
# 테스트 데이터에 대한 예측
predictions = model.predict(X_test)
# 정확도 출력
accuracy = (predictions == y_test).mean()
print("Accuracy:", accuracy)
>>> Accuracy: 0.681최종적으로 0.681의 정확도를 얻음을 알 수 있음
[출처 | 딥다이브 Code.zip 매거진]

@fragrance_0의 개발로그