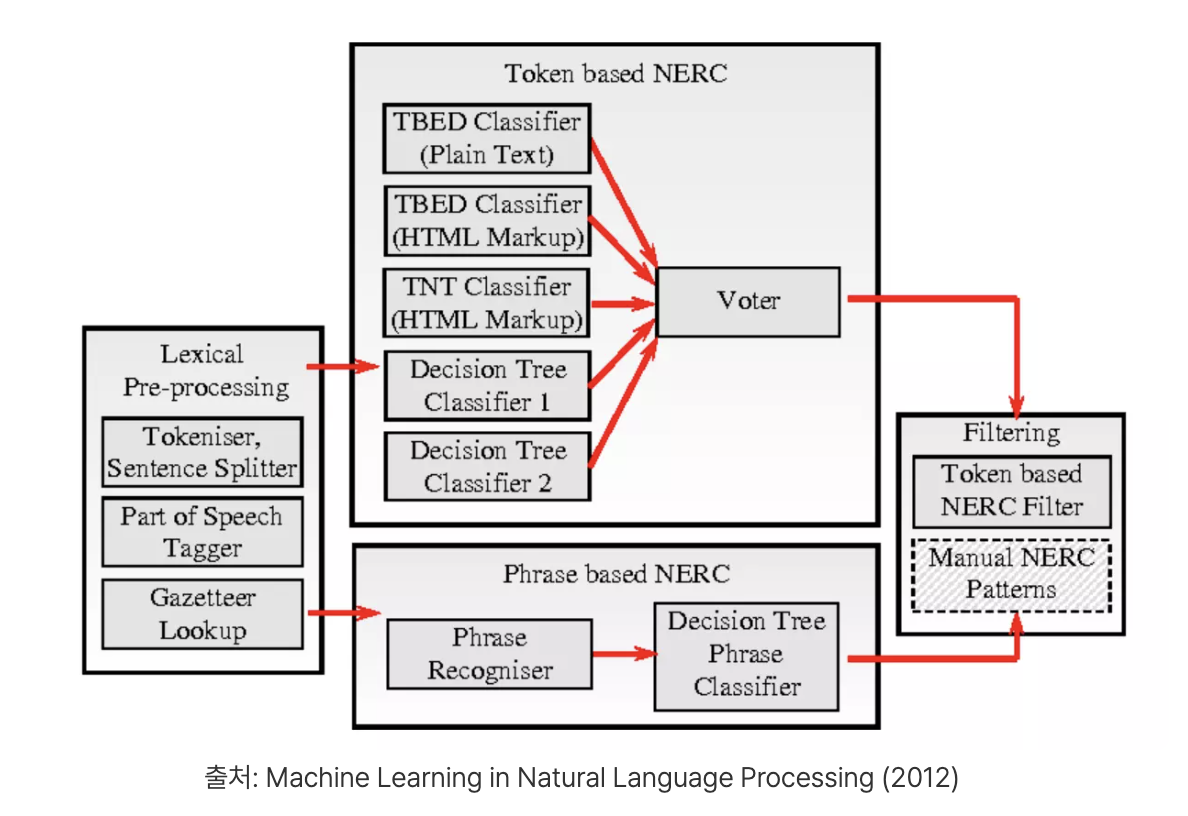
💬 텍스트 데이터 전처리
🌬️ 특수 문자 및 숫자 제거 (Removing Special Characters and Numbers)
-
정규표현식(Regular Expression)을 사용하여 특정 패턴에 일치하는 불필요한 문자열을 삭제하거나 대체 -
BUT 특수 문자와 숫자를 모두 제거하면 중요한 의미가 퇴색되는 경우가 존재!! ((유의))
import re
text = "Hello, $123 World!"
processed_text = re.sub(r"[^a-zA-Z\s]", "", text)
>>> "Hello World"정규 표현식:
[^a-zA-Z\s]
- 알파벳 소문자(a-z),
- 대문자(A-Z)
- 공백 문자(\s)가
- 아닌(^)
모든 문자에 일치
정규 표현식

🌬️ 소문자 변환 (Lowercasing)
- 텍스트 데이터를 모두 소문자로 변환(한국어 해당 x)
text = "Hello World"
processed_text = text.lower()
>>> "hello world"
🌬️ 토큰화 (Tokenization)
- 텍스트 데이터를 단어나 문장 등의 의미있는 작은 단위로 분할
- 텍스트를 처리 가능한 형태로 변환
from nltk.tokenize import word_tokenize
text = "Hello, world!"
tokens = word_tokenize(text)
>>> ["Hello", ",", "world", "!"]word_tokenize()함수를 사용하여text 변수에 저장된 텍스트 데이터를 단어 단위로 토큰화
🌬️ 불용어 처리 (Stopword Removal)
불용어: 일반적으로 자주 사용되는 단어들- 텍스트 데이터의 크기를 줄이고, 처리 성능 향상
from nltk.corpus import stopwords
stopwords = set(stopwords.words("english"))
tokens = ["I", "love", "to", "go", "the", "park"]
processed_tokens = [token for token in tokens if token.lower() not in stopwords]
>>> ['love', 'go', 'park']NLTK(Natural Language Toolkit)라이브러리의stopwords 모듈을 사용하여 영어 불용어 목록을 가져옴tokens리스트에 저장된 단어들 중 불용어가 아닌 단어들만processed_tokens리스트에 저장- 불용어를 제거한 토큰 리스트를 얻을 수 있음
🚨 주의할 점
- 한국어는 영어와는 다른 언어 특성을 가지므로 별도의 한국어 불용어 처리가 필요함
- "은", "는", "이", "가"와 같은 조사, "이/그/저", "한/그/어떤”와 같은 관사, "나", "너", "그", "저" 등의 대명사, "매우", "정말", "아주” 부사 등이 존재
🌬️ 어간 추출 및 표제어 추출 (Stemming and Lemmatization)
어간 추출과표제어 추출은 단어의 원형을 찾는 데 사용되는 기법임
📎 어간 추출 (Stemming)
- 단어의 어미를 제거함
- 단어의 형태 변화를 고려 X, 단순히 어미를 자름
NLTK라이브러리의PorterStemmer를 사용해 "running" 단어의 어간 추출
from nltk.stem import PorterStemmer
stemmer = PorterStemmer()
word = "running"
stemmed_word = stemmer.stem(word)
>>> "run"📎 표제어 추출 (Lemmatization)
- 단어의 원형인 표제어를 찾는 과정
- 단어의 형태 변화와 문법적인 특성을 고려해 단어를 통합하는 방식
- 의미가 보존되며, 문법적으로 정확한 원형 단어 얻을 수 있음
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
word = "running"
lemmatized_word = lemmatizer.lemmatize(word)
>>> "running"🥊 어간 추출과 표제어 추출 차이
어간 추출-> 단순 규칙 기반 접근법
표제어 추출-> 단어의 문법적 특성을 고려해 단어 통합 ➡️ 단어의 실제 원형에 가깝고, 문법 정확
- 어간추출
stemmer = PorterStemmer()
words = ["dogs", "cats", "horses"]
stemmed_words = [stemmer.stem(word) for word in words]
>>> ['dog', 'cat', 'hors']- 표제어 추출
lemmatizer = WordNetLemmatizer()
words = ["dogs", "cats", "horses"]
lemmatized_words = [lemmatizer.lemmatize(word) for word in words]
>>> ['dog', 'cat', 'horse']⤬ 어간 추출은 단순히 어미를 제거해서 문제가 나타남
🌬️ 텍스트 정규화(Text Normalization)
텍스트 정규화는 동의어, 오탈자, 줄임말 등을 처리하여 단어를 일관된 형태로 표현하는 작업을 말함- 하나의 라이브러리로 처리하기 어려움 + 도메인에 따라 처리 방법도 달라질 수 있음
📎 동의어 처리 (Synonym Replacement)
동의어 처리는 같은 의미의 단어가 다르게 표현된 경우 이를 통합하여 일관성을 유지하는 작업입니다. 예를 들어, 영어에서 "don't"와 "do not"는 동일한 의미를 가지므로 텍스트 정규화를 통해 "don't"을 "do not"으로 바꾸어 일관된 형태로 표현할 수 있습니다. 비슷한 예시로 “챗지피티”, ‘챗GPT”, “ChatGPT” 등도 목적에 따라 동일하게 처리할 수 있습니다.
📎 오탈자 처리 (Typo Correction)
오탈자 처리는 잘못 입력된 단어를 올바른 형태로 수정하는 작업입니다. 예를 들어, "teh"라는 오탈자를 "the"로 수정하여 올바른 표현으로 정규화할 수 있습니다.
📎 줄임말 확장 (Abbreviation Expansion)
줄임말 확장은 줄임말이나 약어를 원래의 형태로 전개하는 작업입니다. 예를 들어, "ASAP"라는 줄임말은 "As Soon As Possible"로 전개하여 일반적인 형태로 표현할 수 있습니다.
📎 숫자 처리 (Number Normalization)
숫자 처리는 숫자를 통일된 형태로 변환하는 작업입니다. 예를 들어, "100", "100.00", "1,00.0"과 같은 다양한 형태의 숫자를 "100"으로 통일하여 일관된 표현을 유지할 수 있습니다.
💬 NTN
NTN은 Neural Tensor Network의 약자로 스탠포드 대학교 교수인 Richard Socher (2013)가 "Reasoning With Neural Tensor Networks for Knowledge Base Completion"에서 지식을 넘어선 추론(Reasoning Over Knowledge)을 위해 제시한 딥러닝 모델
NTN은 자연어처리와 딥러닝의 교집합이다
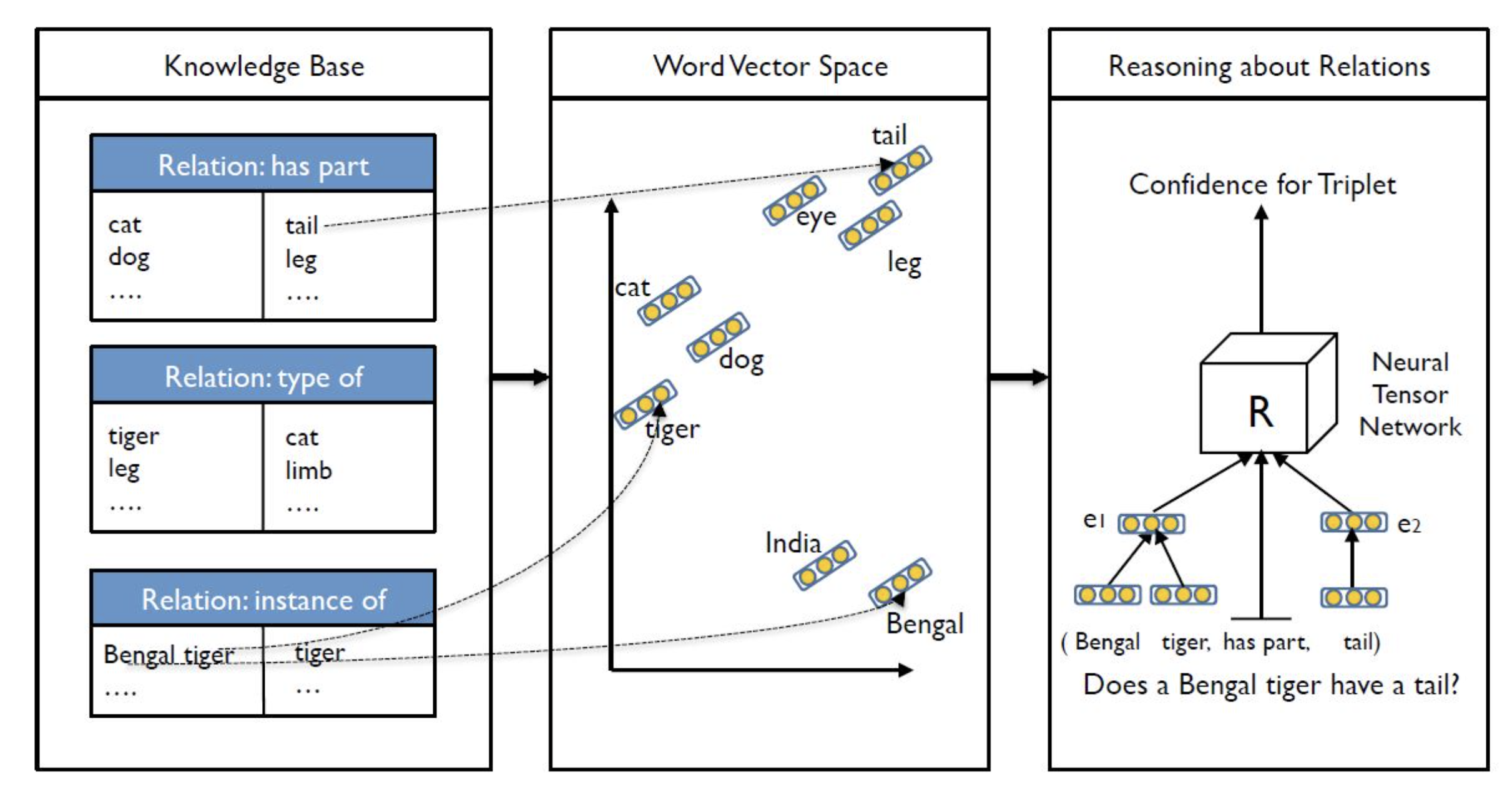
[출처 | 딥다이브 Code.zip 매거진]
