새싹 인공지능 응용sw 개발자 양성 교육 프로그램 심선조 강사님 수업 정리 글입니다.
cnn
from keras.datasets import fashion_mnist(x_train, y_train), (x_test, y_test) = fashion_mnist.load_data()Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-labels-idx1-ubyte.gz
29515/29515 [==============================] - 0s 0us/step
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-images-idx3-ubyte.gz
26421880/26421880 [==============================] - 0s 0us/step
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-labels-idx1-ubyte.gz
5148/5148 [==============================] - 0s 0us/step
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-images-idx3-ubyte.gz
4422102/4422102 [==============================] - 0s 0us/stepimport matplotlib.pyplot as plt
import numpy as npx_train.shape(60000, 28, 28)np.random.seed(777)
#결과값이 확률값으로 나오면 해당 위치에 있는 의미하는 바를 찍어줘야 한다.
class_name = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat', 'Sandal', 'Shirt', 'Sneaker', 'Bag','Ankle boot']
sample_size = 9
random_idx = np.random.randint(60000,size=sample_size)
x_train = np.reshape(x_train/255,(-1,28,28,1)) #(-1,28,28) 원래 있는 모양과 동일 (-1,28,28,1) 1=color rgb=3, grayscale=1
x_test = np.reshape(x_test/255,(-1,28,28,1)) x_train.shape(60000, 28, 28, 1)딥러닝은 차원이 제각각이라서 몇 차원으로 맞춰야 하는 지 잘 정해야 한다. 이럴 때 이렇게 쓴다 정도만 알아두기
완전연결층과의 차이
- 단순히 데이터를 펼쳐서 사용하기 때문에 각 이미지 픽셀의 관계를 고려하지 않는다.
- 2차원 배열 형태의 데이터(28, 28)를 1차원 배열 형태의 데이터를 (28*28)로 변환하면서 데이터 특색이 사라진다.
cnn은 다차원데이터가 들어간다.
컨볼루션 데이터는 특징맵 featuremap?
필터 = 커널
필터의 사이즈는 거의 홀수로 지정한다.
짝수로 지정하면 나중에 비대칭이 되고 padding을 사용할 때 작업하기 힘들어 진다.
from keras.datasets import fashion_mnist(x_train, y_train), (x_test, y_test) = fashion_mnist.load_data()import matplotlib.pyplot as pltplt.imshow(x_train[0],cmap='gray')<matplotlib.image.AxesImage at 0x7fd3606f4cd0>
import numpy as np
import cv2#가로선 특화 필터 , 세로선 특화 필터
#필터 사이즈는 홀수(3,5...)
#이미지 -> 숫자 -> 계산된 숫자에 필터 적용
h_filter = np.array([[1.,2.,1.], #가로선 특화
[0.,0.,0.],
[-1,-2,-1]])
v_filter = np.array([[1.,0.,-1], #세로선 특화
[2.,0.,-2],
[1.,0.,-1]])CIFAR-10
총 10개 클래스
CIFAR-100 총 100개 크래스
from keras.datasets import cifar10(x_train, y_train), (x_test, y_test) = cifar10.load_data()x_train.shape,x_test.shape((50000, 32, 32, 3), (10000, 32, 32, 3))y_train[0]array([6], dtype=uint8)x_train.min(),x_train.max()(0, 255)import matplotlib.pyplot as plt
import numpy as np
np.random.seed(777)
class_names = ['airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']
sample_size = 9
random_idx = np.random.randint(50000,size=sample_size)
plt.figure(figsize=(5,5))
for i,idx in enumerate(random_idx):
plt.subplot(3,3,i+1)
plt.xticks([]) #눈금제거
plt.yticks([])
plt.imshow(x_train[idx],cmap='gray')
plt.xlabel(class_names[int(y_train[idx])]) #index값 int처리 하는 이유 y_train이 실수값이면 int처리 해줘야 함, 지금은 int형이라 필요x
plt.show<function matplotlib.pyplot.show(*args, **kw)>
#전처리 평균 = 0, 표준편차 = 1로 만들어 줌
x_mean = np.mean(x_train,axis=(0,1,2))
x_std = np.std(x_train,axis=(0,1,2))
x_train=(x_train-x_mean)/x_std
x_test =(x_test-x_mean)/x_stdx_train.min(),x_train.max()(-1.98921279913639, 2.1267894095169213)np.round(np.mean(x_train), 1) #평균은 0에 가까운 값으로 바꿔줌0.0np.round(np.std(x_train), 1) #표준편차은 1에 가까운 값으로 바꿔줌1.0from sklearn.model_selection import train_test_splitx_train,x_val,y_train,y_val = train_test_split(x_train,y_train,test_size=0.3,random_state=777)x_train.shape,x_val.shape((35000, 32, 32, 3), (15000, 32, 32, 3))# from keras.utils import to_categorical
# y_train = to_categorical(y_train)
# y_test = to_categorical(y_test)#모델구성
from keras.models import Sequential
from keras.layers import Conv2D,MaxPool2D,Dense,Flatten
from keras.optimizers import Adam #객체를 생성해서 객체를 넣으면(Adam) 학습률 등등 조절 가능, 문자열을 넣으면 학습률 등등 조정 불가model = Sequential([
Conv2D(filters=32,kernel_size=3,padding='same',activation='relu', input_shape=(32, 32, 3)), #패딩은 들가는 값, 나오는 값 똑같이 만들어줌
Conv2D(filters=32,kernel_size=3,padding='same',activation='relu'),
MaxPool2D(pool_size=(2,2),strides=2,padding='same'),
Conv2D(filters=64,kernel_size=3,padding='same',activation='relu'),
Conv2D(filters=64,kernel_size=3,padding='same',activation='relu'),
MaxPool2D(pool_size=(2,2),strides=2,padding='same'),
Conv2D(filters=128,kernel_size=3,padding='same',activation='relu'),
Conv2D(filters=128,kernel_size=3,padding='same',activation='relu'),
MaxPool2D(pool_size=(2,2),strides=2,padding='same'),
Flatten(), #일차원으로 펼쳐줌
Dense(256,activation='relu'),
Dense(10, activation='softmax')
])
model.compile(optimizer=Adam(1e-4),loss='sparse_categorical_crossentropy',metrics=['acc']) #Adam 객체 생성, 0.0001model.fit(x_train,y_train,epochs=30,batch_size=32,validation_data=(x_val,y_val))Epoch 1/30
1094/1094 [==============================] - 18s 9ms/step - loss: 1.6168 - acc: 0.4132 - val_loss: 1.3330 - val_acc: 0.5146
Epoch 2/30
1094/1094 [==============================] - 7s 6ms/step - loss: 1.2453 - acc: 0.5568 - val_loss: 1.1764 - val_acc: 0.5818
Epoch 3/30
1094/1094 [==============================] - 7s 6ms/step - loss: 1.0677 - acc: 0.6269 - val_loss: 1.0550 - val_acc: 0.6242
Epoch 4/30
1094/1094 [==============================] - 7s 6ms/step - loss: 0.9422 - acc: 0.6720 - val_loss: 0.9636 - val_acc: 0.6655
Epoch 5/30
1094/1094 [==============================] - 7s 6ms/step - loss: 0.8471 - acc: 0.7055 - val_loss: 0.9098 - val_acc: 0.6818
Epoch 6/30
1094/1094 [==============================] - 7s 6ms/step - loss: 0.7655 - acc: 0.7343 - val_loss: 0.8469 - val_acc: 0.7005
Epoch 7/30
1094/1094 [==============================] - 7s 6ms/step - loss: 0.6887 - acc: 0.7596 - val_loss: 0.8098 - val_acc: 0.7168
Epoch 8/30
1094/1094 [==============================] - 7s 6ms/step - loss: 0.6186 - acc: 0.7860 - val_loss: 0.8021 - val_acc: 0.7265
Epoch 9/30
1094/1094 [==============================] - 7s 6ms/step - loss: 0.5549 - acc: 0.8099 - val_loss: 0.8279 - val_acc: 0.7206
Epoch 10/30
1094/1094 [==============================] - 7s 6ms/step - loss: 0.4900 - acc: 0.8315 - val_loss: 0.7811 - val_acc: 0.7375
Epoch 11/30
1094/1094 [==============================] - 7s 6ms/step - loss: 0.4292 - acc: 0.8527 - val_loss: 0.8378 - val_acc: 0.7269
Epoch 12/30
1094/1094 [==============================] - 7s 6ms/step - loss: 0.3709 - acc: 0.8725 - val_loss: 0.8330 - val_acc: 0.7369
Epoch 13/30
1094/1094 [==============================] - 7s 6ms/step - loss: 0.3169 - acc: 0.8916 - val_loss: 0.8973 - val_acc: 0.7290
Epoch 14/30
1094/1094 [==============================] - 7s 6ms/step - loss: 0.2636 - acc: 0.9125 - val_loss: 0.9185 - val_acc: 0.7320
Epoch 15/30
1094/1094 [==============================] - 7s 6ms/step - loss: 0.2179 - acc: 0.9249 - val_loss: 0.9452 - val_acc: 0.7386
Epoch 16/30
1094/1094 [==============================] - 7s 6ms/step - loss: 0.1731 - acc: 0.9420 - val_loss: 1.0809 - val_acc: 0.7191
Epoch 17/30
1094/1094 [==============================] - 7s 7ms/step - loss: 0.1385 - acc: 0.9527 - val_loss: 1.1225 - val_acc: 0.7360
Epoch 18/30
1094/1094 [==============================] - 7s 6ms/step - loss: 0.1101 - acc: 0.9630 - val_loss: 1.1725 - val_acc: 0.7346
Epoch 19/30
1094/1094 [==============================] - 7s 6ms/step - loss: 0.0922 - acc: 0.9695 - val_loss: 1.3306 - val_acc: 0.7239
Epoch 20/30
1094/1094 [==============================] - 7s 6ms/step - loss: 0.0769 - acc: 0.9746 - val_loss: 1.3441 - val_acc: 0.7324
Epoch 21/30
1094/1094 [==============================] - 7s 6ms/step - loss: 0.0710 - acc: 0.9774 - val_loss: 1.4303 - val_acc: 0.7319
Epoch 22/30
1094/1094 [==============================] - 7s 6ms/step - loss: 0.0619 - acc: 0.9787 - val_loss: 1.5521 - val_acc: 0.7267
Epoch 23/30
1094/1094 [==============================] - 7s 6ms/step - loss: 0.0602 - acc: 0.9804 - val_loss: 1.4822 - val_acc: 0.7342
Epoch 24/30
1094/1094 [==============================] - 7s 6ms/step - loss: 0.0548 - acc: 0.9815 - val_loss: 1.4839 - val_acc: 0.7311
Epoch 25/30
1094/1094 [==============================] - 7s 6ms/step - loss: 0.0538 - acc: 0.9827 - val_loss: 1.5327 - val_acc: 0.7315
Epoch 26/30
1094/1094 [==============================] - 7s 6ms/step - loss: 0.0518 - acc: 0.9826 - val_loss: 1.6265 - val_acc: 0.7343
Epoch 27/30
1094/1094 [==============================] - 7s 6ms/step - loss: 0.0487 - acc: 0.9833 - val_loss: 1.5696 - val_acc: 0.7287
Epoch 28/30
1094/1094 [==============================] - 7s 6ms/step - loss: 0.0461 - acc: 0.9850 - val_loss: 1.5710 - val_acc: 0.7337
Epoch 29/30
1094/1094 [==============================] - 7s 6ms/step - loss: 0.0405 - acc: 0.9867 - val_loss: 1.6835 - val_acc: 0.7279
Epoch 30/30
1094/1094 [==============================] - 7s 6ms/step - loss: 0.0363 - acc: 0.9879 - val_loss: 1.7594 - val_acc: 0.7249
<keras.callbacks.History at 0x7f25103189d0>feature_maps = visual_model.predict(test_img)1/1 [==============================] - 0s 257ms/stepfeature_maps[array([[[[0. , 1.4529483 , 0. , ..., 0.3918791 ,
0. , 0.17814378],
[0.6320291 , 1.1041299 , 0. , ..., 0. ,
0.6043985 , 0.90298533],
[0.6042557 , 1.1171033 , 0. , ..., 0. ,
0.583368 , 0.8844857 ],
...,
for layer_name, feature_map in zip(get_layer_name,feature_maps):
# print(layer_name, feature_map) #이미지 1개가 들어가서 특정 layer의 output
if (len(feature_map.shape)==4): #feature_map.shape 튜플값이 4차원이냐 , 뒷 부분 Flatten은 1차원이라서, 앞부분만 쓰겠다
img_size = feature_map.shape[1] #feature_map.shape[1] : 행값, 행값을 알아야 잘라서 볼 수 있다
features = feature_map.shape[-1] #feature_map.shape[-1] : color, 들어갈 때는 채널 수, 나올 때는 필터 수!
display_grid = np.zeros((img_size,img_size*features)) #img_size : 행, img_size*features : 열
for i in range(features):
x = feature_map[0,:,:,i] #0:이미지 1개, :행 열값 그대로, i:특정채널, 한 장씩 가져옴
x -= x.mean()
x /= x.std()
x *= 64
x += 128
x = np.clip(x,0,255).astype('uint8') #x=이미지라서 0~255범위, 0보다 작으면 0으로처리 255보다 크면 255처리
display_grid[:,i*img_size:(i+1)*img_size] = x
plt.figure(figsize=(features,2+1./features))
plt.title(layer_name,fontsize=20)
plt.grid(False) #grid=모눈선
plt.imshow(display_grid,aspect='auto')<ipython-input-56-b743650fe045>:10: RuntimeWarning: invalid value encountered in true_divide
x /= x.std()
_, (x_test1, y_test1) = cifar10.load_data()plt.imshow(x_test1[1])<matplotlib.image.AxesImage at 0x7f251910adf0>
#데이터 가져오기
from keras.datasets import cifar10
import numpy as np
from sklearn.model_selection import train_test_split
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
#기본 전처리
x_mean = np.mean(x_train,axis=(0,1,2))
x_std = np.std(x_train,axis=(0,1,2))
x_train=(x_train-x_mean)/x_std
x_test =(x_test-x_mean)/x_std
#데이터 분리
x_train,x_val,y_train,y_val = train_test_split(x_train,y_train,test_size=0.3,random_state=777)Downloading data from https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz
170498071/170498071 [==============================] - 6s 0us/stepl1 절댓값사용 규제
l2 제곱사용 규제
(회귀계수값을 줄여서 0에 가깝게, 0이 되진 않음)
l1,l2 규제 쓰는 이유 값마다 가중치가 존재한다. 가중치가 계속커져서 과적합이 될 수 있는 문제가 있다. 가중치값이 커지지 않게 해주고 과적합방지
#모델구성
from keras.models import Sequential
from keras.layers import Conv2D,MaxPool2D,Dense,Flatten
from keras.optimizers import Adam
from keras.regularizers import l2
model = Sequential([
Conv2D(filters=32,kernel_size=3,padding='same',activation='relu', input_shape=(32, 32, 3)),
Conv2D(filters=32,kernel_size=3,padding='same',activation='relu'),
MaxPool2D(pool_size=(2,2),strides=2,padding='same'),
Conv2D(filters=64,kernel_size=3,padding='same',activation='relu'),
Conv2D(filters=64,kernel_size=3,padding='same',activation='relu'),
MaxPool2D(pool_size=(2,2),strides=2,padding='same'),
Conv2D(filters=128,kernel_size=3,padding='same',activation='relu'),
Conv2D(filters=128,kernel_size=3,padding='same',activation='relu'),
MaxPool2D(pool_size=(2,2),strides=2,padding='same'),
Flatten(),
Dense(256,activation='relu',kernel_regularizer=l2(0.001)),
Dense(10, activation='softmax')
])
model.compile(optimizer=Adam(1e-4),loss='sparse_categorical_crossentropy',metrics=['acc'])
#fit
history = model.fit(x_train,y_train,epochs=30,batch_size=32,validation_data=(x_val,y_val))Epoch 1/30
1094/1094 [==============================] - 19s 9ms/step - loss: 1.9308 - acc: 0.4041 - val_loss: 1.6060 - val_acc: 0.4966
Epoch 2/30
1094/1094 [==============================] - 9s 8ms/step - loss: 1.4942 - acc: 0.5439 - val_loss: 1.4192 - val_acc: 0.5601
Epoch 3/30
1094/1094 [==============================] - 10s 9ms/step - loss: 1.3002 - acc: 0.6083 - val_loss: 1.2409 - val_acc: 0.6211
Epoch 4/30
1094/1094 [==============================] - 8s 8ms/step - loss: 1.1476 - acc: 0.6621 - val_loss: 1.1533 - val_acc: 0.6507
Epoch 5/30
1094/1094 [==============================] - 11s 10ms/step - loss: 1.0358 - acc: 0.6973 - val_loss: 1.1012 - val_acc: 0.6644
Epoch 6/30
1094/1094 [==============================] - 8s 8ms/step - loss: 0.9365 - acc: 0.7312 - val_loss: 1.0213 - val_acc: 0.6973
Epoch 7/30
1094/1094 [==============================] - 9s 8ms/step - loss: 0.8492 - acc: 0.7591 - val_loss: 0.9974 - val_acc: 0.7033
Epoch 8/30
1094/1094 [==============================] - 9s 8ms/step - loss: 0.7747 - acc: 0.7818 - val_loss: 0.9588 - val_acc: 0.7169
Epoch 9/30
1094/1094 [==============================] - 8s 7ms/step - loss: 0.6982 - acc: 0.8063 - val_loss: 0.9361 - val_acc: 0.7241
Epoch 10/30
1094/1094 [==============================] - 9s 8ms/step - loss: 0.6334 - acc: 0.8287 - val_loss: 0.9455 - val_acc: 0.7248
Epoch 11/30
1094/1094 [==============================] - 9s 8ms/step - loss: 0.5721 - acc: 0.8471 - val_loss: 0.9366 - val_acc: 0.7332
Epoch 12/30
1094/1094 [==============================] - 7s 7ms/step - loss: 0.5136 - acc: 0.8684 - val_loss: 0.9762 - val_acc: 0.7346
Epoch 13/30
1094/1094 [==============================] - 9s 8ms/step - loss: 0.4522 - acc: 0.8893 - val_loss: 1.0396 - val_acc: 0.7250
Epoch 14/30
1094/1094 [==============================] - 9s 8ms/step - loss: 0.3971 - acc: 0.9074 - val_loss: 1.0480 - val_acc: 0.7301
Epoch 15/30
1094/1094 [==============================] - 10s 9ms/step - loss: 0.3514 - acc: 0.9230 - val_loss: 1.1206 - val_acc: 0.7277
Epoch 16/30
1094/1094 [==============================] - 10s 9ms/step - loss: 0.3050 - acc: 0.9385 - val_loss: 1.1451 - val_acc: 0.7371
Epoch 17/30
1094/1094 [==============================] - 9s 8ms/step - loss: 0.2821 - acc: 0.9452 - val_loss: 1.2107 - val_acc: 0.7286
Epoch 18/30
1094/1094 [==============================] - 9s 8ms/step - loss: 0.2501 - acc: 0.9564 - val_loss: 1.3049 - val_acc: 0.7179
Epoch 19/30
1094/1094 [==============================] - 10s 9ms/step - loss: 0.2306 - acc: 0.9630 - val_loss: 1.3672 - val_acc: 0.7233
Epoch 20/30
1094/1094 [==============================] - 9s 8ms/step - loss: 0.2150 - acc: 0.9673 - val_loss: 1.4016 - val_acc: 0.7249
Epoch 21/30
1094/1094 [==============================] - 7s 7ms/step - loss: 0.2059 - acc: 0.9699 - val_loss: 1.5579 - val_acc: 0.7151
Epoch 22/30
1094/1094 [==============================] - 10s 9ms/step - loss: 0.1943 - acc: 0.9736 - val_loss: 1.4323 - val_acc: 0.7263
Epoch 23/30
1094/1094 [==============================] - 8s 8ms/step - loss: 0.1840 - acc: 0.9764 - val_loss: 1.5211 - val_acc: 0.7331
Epoch 24/30
1094/1094 [==============================] - 9s 8ms/step - loss: 0.1804 - acc: 0.9772 - val_loss: 1.4886 - val_acc: 0.7318
Epoch 25/30
1094/1094 [==============================] - 10s 9ms/step - loss: 0.1748 - acc: 0.9789 - val_loss: 1.5742 - val_acc: 0.7354
Epoch 26/30
1094/1094 [==============================] - 9s 8ms/step - loss: 0.1768 - acc: 0.9759 - val_loss: 1.5218 - val_acc: 0.7294
Epoch 27/30
1094/1094 [==============================] - 9s 8ms/step - loss: 0.1570 - acc: 0.9843 - val_loss: 1.6411 - val_acc: 0.7187
Epoch 28/30
1094/1094 [==============================] - 9s 8ms/step - loss: 0.1667 - acc: 0.9804 - val_loss: 1.5549 - val_acc: 0.7339
Epoch 29/30
1094/1094 [==============================] - 8s 7ms/step - loss: 0.1617 - acc: 0.9813 - val_loss: 1.5785 - val_acc: 0.7275
Epoch 30/30
1094/1094 [==============================] - 7s 7ms/step - loss: 0.1597 - acc: 0.9814 - val_loss: 1.6498 - val_acc: 0.7269import matplotlib.pyplot as plt
his_dict = history.history
loss = his_dict['loss']
val_loss = his_dict['val_loss']
epochs = range(1, len(loss)+1)
fig = plt.figure(figsize=(10,5))
ax1 = fig.add_subplot(1,2,1) #1,2,1 = 1행 2열의 1째 것
ax1.plot(epochs,loss,color='blue',label='train_loss')
ax1.plot(epochs,val_loss,color='orange',label='val_loss')
ax1.set_title('loss')
ax1.legend()
#정확도
acc = his_dict['acc']
val_acc = his_dict['val_acc']
ax2 = fig.add_subplot(1,2,2) #1,2,1 = 1행 2열의 1째 것
ax2.plot(epochs,acc,color='blue',label='train_acc')
ax2.plot(epochs,val_acc,color='orange',label='val_acc')
ax2.set_title('acc')
ax2.legend()
plt.show()
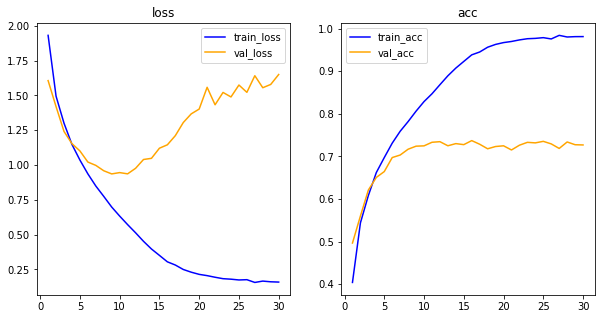
드롭 아웃
의도적으로 연결을 끊는다. 전달을 막는다.
과대적합을 방지한다.
#데이터 가져오기
from keras.datasets import cifar10
import numpy as np
from sklearn.model_selection import train_test_split
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
#기본 전처리
x_mean = np.mean(x_train,axis=(0,1,2))
x_std = np.std(x_train,axis=(0,1,2))
x_train=(x_train-x_mean)/x_std
x_test =(x_test-x_mean)/x_std
#데이터 분리
x_train,x_val,y_train,y_val = train_test_split(x_train,y_train,test_size=0.3,random_state=777)Downloading data from https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz
170498071/170498071 [==============================] - 13s 0us/step#모델구성
from keras.models import Sequential
from keras.layers import Conv2D,MaxPool2D,Dense,Flatten,Dropout
from keras.optimizers import Adam
model = Sequential([
Conv2D(filters=32,kernel_size=3,padding='same',activation='relu', input_shape=(32, 32, 3)),
Conv2D(filters=32,kernel_size=3,padding='same',activation='relu'),
MaxPool2D(pool_size=(2,2),strides=2,padding='same'),
Conv2D(filters=64,kernel_size=3,padding='same',activation='relu'),
Conv2D(filters=64,kernel_size=3,padding='same',activation='relu'),
MaxPool2D(pool_size=(2,2),strides=2,padding='same'),
Conv2D(filters=128,kernel_size=3,padding='same',activation='relu'),
Conv2D(filters=128,kernel_size=3,padding='same',activation='relu'),
MaxPool2D(pool_size=(2,2),strides=2,padding='same'),
#dropout layer추가, 0.2% 전달x
Dropout(0.2),
Flatten(),
Dense(256,activation='relu'),
Dense(10, activation='softmax')
])
model.compile(optimizer=Adam(1e-4),loss='sparse_categorical_crossentropy',metrics=['acc'])
#fit
history = model.fit(x_train,y_train,epochs=30,batch_size=32,validation_data=(x_val,y_val))Epoch 1/30
1094/1094 [==============================] - 16s 7ms/step - loss: 1.6593 - acc: 0.3998 - val_loss: 1.3943 - val_acc: 0.5022
Epoch 2/30
1094/1094 [==============================] - 7s 6ms/step - loss: 1.2821 - acc: 0.5461 - val_loss: 1.1609 - val_acc: 0.5891
Epoch 3/30
1094/1094 [==============================] - 7s 7ms/step - loss: 1.1067 - acc: 0.6097 - val_loss: 1.0378 - val_acc: 0.6315
Epoch 4/30
1094/1094 [==============================] - 7s 6ms/step - loss: 0.9841 - acc: 0.6581 - val_loss: 0.9576 - val_acc: 0.6623
Epoch 5/30
1094/1094 [==============================] - 7s 6ms/step - loss: 0.8880 - acc: 0.6902 - val_loss: 0.8861 - val_acc: 0.6859
Epoch 6/30
1094/1094 [==============================] - 7s 6ms/step - loss: 0.8180 - acc: 0.7162 - val_loss: 0.8517 - val_acc: 0.7033
Epoch 7/30
1094/1094 [==============================] - 7s 6ms/step - loss: 0.7548 - acc: 0.7416 - val_loss: 0.8109 - val_acc: 0.7176
Epoch 8/30
1094/1094 [==============================] - 9s 9ms/step - loss: 0.6917 - acc: 0.7608 - val_loss: 0.7857 - val_acc: 0.7263
Epoch 9/30
1094/1094 [==============================] - 9s 9ms/step - loss: 0.6426 - acc: 0.7761 - val_loss: 0.7889 - val_acc: 0.7299
Epoch 10/30
1094/1094 [==============================] - 9s 9ms/step - loss: 0.5909 - acc: 0.7943 - val_loss: 0.7606 - val_acc: 0.7367
Epoch 11/30
1094/1094 [==============================] - 9s 8ms/step - loss: 0.5449 - acc: 0.8110 - val_loss: 0.7332 - val_acc: 0.7460
Epoch 12/30
1094/1094 [==============================] - 9s 8ms/step - loss: 0.5006 - acc: 0.8276 - val_loss: 0.7233 - val_acc: 0.7515
Epoch 13/30
1094/1094 [==============================] - 9s 8ms/step - loss: 0.4579 - acc: 0.8406 - val_loss: 0.7521 - val_acc: 0.7483
Epoch 14/30
1094/1094 [==============================] - 8s 8ms/step - loss: 0.4198 - acc: 0.8548 - val_loss: 0.7349 - val_acc: 0.7571
Epoch 15/30
1094/1094 [==============================] - 7s 6ms/step - loss: 0.3811 - acc: 0.8685 - val_loss: 0.7215 - val_acc: 0.7629
Epoch 16/30
1094/1094 [==============================] - 7s 6ms/step - loss: 0.3418 - acc: 0.8813 - val_loss: 0.7548 - val_acc: 0.7615
Epoch 17/30
1094/1094 [==============================] - 10s 9ms/step - loss: 0.3117 - acc: 0.8903 - val_loss: 0.7790 - val_acc: 0.7596
Epoch 18/30
1094/1094 [==============================] - 8s 7ms/step - loss: 0.2754 - acc: 0.9038 - val_loss: 0.8076 - val_acc: 0.7610
Epoch 19/30
1094/1094 [==============================] - 8s 8ms/step - loss: 0.2442 - acc: 0.9131 - val_loss: 0.7981 - val_acc: 0.7609
Epoch 20/30
1094/1094 [==============================] - 8s 7ms/step - loss: 0.2263 - acc: 0.9199 - val_loss: 0.8213 - val_acc: 0.7566
Epoch 21/30
1094/1094 [==============================] - 10s 9ms/step - loss: 0.1985 - acc: 0.9308 - val_loss: 0.8391 - val_acc: 0.7669
Epoch 22/30
1094/1094 [==============================] - 9s 8ms/step - loss: 0.1790 - acc: 0.9377 - val_loss: 0.8766 - val_acc: 0.7644
Epoch 23/30
1094/1094 [==============================] - 10s 9ms/step - loss: 0.1643 - acc: 0.9415 - val_loss: 0.8793 - val_acc: 0.7678
Epoch 24/30
1094/1094 [==============================] - 9s 8ms/step - loss: 0.1477 - acc: 0.9482 - val_loss: 0.9044 - val_acc: 0.7695
Epoch 25/30
1094/1094 [==============================] - 7s 7ms/step - loss: 0.1292 - acc: 0.9545 - val_loss: 0.9256 - val_acc: 0.7631
Epoch 26/30
1094/1094 [==============================] - 8s 7ms/step - loss: 0.1248 - acc: 0.9568 - val_loss: 0.9614 - val_acc: 0.7694
Epoch 27/30
1094/1094 [==============================] - 10s 9ms/step - loss: 0.1168 - acc: 0.9591 - val_loss: 0.9879 - val_acc: 0.7656
Epoch 28/30
1094/1094 [==============================] - 10s 9ms/step - loss: 0.1074 - acc: 0.9627 - val_loss: 1.0202 - val_acc: 0.7689
Epoch 29/30
1094/1094 [==============================] - 10s 9ms/step - loss: 0.1032 - acc: 0.9637 - val_loss: 1.0051 - val_acc: 0.7638
Epoch 30/30
1094/1094 [==============================] - 9s 8ms/step - loss: 0.0928 - acc: 0.9679 - val_loss: 1.0504 - val_acc: 0.7612import matplotlib.pyplot as plt
his_dict = history.history
loss = his_dict['loss']
val_loss = his_dict['val_loss']
epochs = range(1, len(loss)+1)
fig = plt.figure(figsize=(10,5))
ax1 = fig.add_subplot(1,2,1) #1,2,1 = 1행 2열의 1째 것
ax1.plot(epochs,loss,color='blue',label='train_loss')
ax1.plot(epochs,val_loss,color='orange',label='val_loss')
ax1.set_title('loss')
ax1.legend()
#정확도
acc = his_dict['acc']
val_acc = his_dict['val_acc']
ax2 = fig.add_subplot(1,2,2) #1,2,1 = 1행 2열의 1째 것
ax2.plot(epochs,acc,color='blue',label='train_acc')
ax2.plot(epochs,val_acc,color='orange',label='val_acc')
ax2.set_title('acc')
ax2.legend()
plt.show()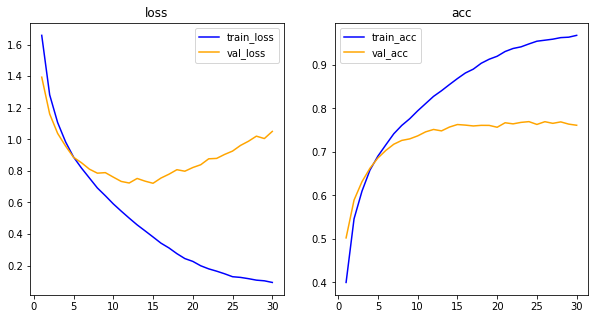
배치 정규화
- stanardscale, minmaxscale, 평균0 표준편차1 등등
근본적으로 과대적합을 피하기 위한 방법은 아니지만 어느정도는 영향이 있다. 규제랑 dropout을 섞으면 과대적합을 완만하게 만들 수 있다.
내부 공선성을 해결하기 위해 고안되었다. 매우 큰 범위의 출력값은 신경망을 불안하게 하여 성능 저하시킬 수 있다.
배치 정규화는 신경망층의 출력값이 가질 수 있는 범위, 출력값 분포의 범위를 줄여 불확실성을 줄이는 방법
-
기본 신경망은 높은 학습률을 사용하는 경우, 그래디언트 손실. 폭발의 문제점이 존재하지만 배치 정규화를 사용하면 문제를 방지할 수 있다.
-
자체적인 규제효과 -> 과대적합 문제를 피할 수 있다.
장점은 보장되지 않는다. 배치 정규화를 사용하면 규제화 함수나 드롭아웃을 사용하지 않아도 된다. -
Dense, Conv2D층 -> BaatchNormalization() -> Activation()
#데이터 가져오기
from keras.datasets import cifar10
import numpy as np
from sklearn.model_selection import train_test_split
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
#기본 전처리
x_mean = np.mean(x_train,axis=(0,1,2))
x_std = np.std(x_train,axis=(0,1,2))
x_train=(x_train-x_mean)/x_std
x_test =(x_test-x_mean)/x_std
#데이터 분리
x_train,x_val,y_train,y_val = train_test_split(x_train,y_train,test_size=0.3,random_state=777)#모델구성
from keras.models import Sequential
from keras.layers import Conv2D,MaxPool2D,Dense,Flatten,Activation,BatchNormalization
from keras.optimizers import Adam
model = Sequential([
Conv2D(filters=32,kernel_size=3,padding='same', input_shape=(32, 32, 3)),
BatchNormalization(),
Activation('relu'),
Conv2D(filters=32,kernel_size=3,padding='same'),
BatchNormalization(),
Activation('relu'),
MaxPool2D(pool_size=(2,2),strides=2,padding='same'),
Conv2D(filters=64,kernel_size=3,padding='same'),
BatchNormalization(),
Activation('relu'),
Conv2D(filters=64,kernel_size=3,padding='same'),
BatchNormalization(),
Activation('relu'),
MaxPool2D(pool_size=(2,2),strides=2,padding='same'),
Conv2D(filters=128,kernel_size=3,padding='same'),
BatchNormalization(),
Activation('relu'),
Conv2D(filters=128,kernel_size=3,padding='same'),
BatchNormalization(),
Activation('relu'),
MaxPool2D(pool_size=(2,2),strides=2,padding='same'),
Flatten(),
Dense(256),
BatchNormalization(),
Activation('relu'),
Dense(10, activation='softmax') #결과값이 나가는 층이라서 상관x
])
model.compile(optimizer=Adam(1e-4),loss='sparse_categorical_crossentropy',metrics=['acc'])
#fit
history = model.fit(x_train,y_train,epochs=30,batch_size=32,validation_data=(x_val,y_val))Epoch 1/30
1094/1094 [==============================] - 20s 10ms/step - loss: 1.4206 - acc: 0.4948 - val_loss: 1.1491 - val_acc: 0.5927
Epoch 2/30
1094/1094 [==============================] - 9s 8ms/step - loss: 0.9952 - acc: 0.6542 - val_loss: 1.0516 - val_acc: 0.6321
Epoch 3/30
1094/1094 [==============================] - 9s 8ms/step - loss: 0.7889 - acc: 0.7315 - val_loss: 0.9553 - val_acc: 0.6677
Epoch 4/30
1094/1094 [==============================] - 10s 9ms/step - loss: 0.6274 - acc: 0.7940 - val_loss: 0.9214 - val_acc: 0.6810
Epoch 5/30
1094/1094 [==============================] - 10s 9ms/step - loss: 0.4883 - acc: 0.8480 - val_loss: 0.9787 - val_acc: 0.6671
Epoch 6/30
1094/1094 [==============================] - 9s 8ms/step - loss: 0.3740 - acc: 0.8867 - val_loss: 0.9895 - val_acc: 0.6733
Epoch 7/30
1094/1094 [==============================] - 9s 8ms/step - loss: 0.2778 - acc: 0.9238 - val_loss: 1.0066 - val_acc: 0.6774
Epoch 8/30
1094/1094 [==============================] - 10s 9ms/step - loss: 0.2029 - acc: 0.9481 - val_loss: 1.1214 - val_acc: 0.6694
Epoch 9/30
1094/1094 [==============================] - 10s 9ms/step - loss: 0.1478 - acc: 0.9648 - val_loss: 1.1200 - val_acc: 0.6729
Epoch 10/30
1094/1094 [==============================] - 10s 9ms/step - loss: 0.1218 - acc: 0.9702 - val_loss: 1.1290 - val_acc: 0.6819
Epoch 11/30
1094/1094 [==============================] - 10s 9ms/step - loss: 0.0980 - acc: 0.9764 - val_loss: 1.2340 - val_acc: 0.6687
Epoch 12/30
1094/1094 [==============================] - 9s 8ms/step - loss: 0.0879 - acc: 0.9778 - val_loss: 1.3122 - val_acc: 0.6645
Epoch 13/30
1094/1094 [==============================] - 9s 8ms/step - loss: 0.0758 - acc: 0.9818 - val_loss: 1.4406 - val_acc: 0.6518
Epoch 14/30
1094/1094 [==============================] - 9s 8ms/step - loss: 0.0735 - acc: 0.9789 - val_loss: 1.3587 - val_acc: 0.6697
Epoch 15/30
1094/1094 [==============================] - 9s 8ms/step - loss: 0.0657 - acc: 0.9821 - val_loss: 1.2922 - val_acc: 0.6793
Epoch 16/30
1094/1094 [==============================] - 9s 8ms/step - loss: 0.0608 - acc: 0.9843 - val_loss: 1.3698 - val_acc: 0.6729
Epoch 17/30
1094/1094 [==============================] - 9s 8ms/step - loss: 0.0562 - acc: 0.9850 - val_loss: 1.3622 - val_acc: 0.6799
Epoch 18/30
1094/1094 [==============================] - 10s 9ms/step - loss: 0.0513 - acc: 0.9864 - val_loss: 1.4270 - val_acc: 0.6761
Epoch 19/30
1094/1094 [==============================] - 10s 9ms/step - loss: 0.0515 - acc: 0.9854 - val_loss: 1.5120 - val_acc: 0.6589
Epoch 20/30
1094/1094 [==============================] - 9s 8ms/step - loss: 0.0519 - acc: 0.9845 - val_loss: 1.5980 - val_acc: 0.6575
Epoch 21/30
1094/1094 [==============================] - 9s 8ms/step - loss: 0.0497 - acc: 0.9854 - val_loss: 1.4027 - val_acc: 0.6807
Epoch 22/30
1094/1094 [==============================] - 10s 9ms/step - loss: 0.0430 - acc: 0.9869 - val_loss: 1.5171 - val_acc: 0.6770
Epoch 23/30
1094/1094 [==============================] - 13s 12ms/step - loss: 0.0459 - acc: 0.9867 - val_loss: 1.4776 - val_acc: 0.6807
Epoch 24/30
1094/1094 [==============================] - 10s 9ms/step - loss: 0.0436 - acc: 0.9870 - val_loss: 1.6015 - val_acc: 0.6617
Epoch 25/30
1094/1094 [==============================] - 9s 8ms/step - loss: 0.0460 - acc: 0.9852 - val_loss: 1.4964 - val_acc: 0.6801
Epoch 26/30
1094/1094 [==============================] - 9s 8ms/step - loss: 0.0392 - acc: 0.9886 - val_loss: 1.6892 - val_acc: 0.6676
Epoch 27/30
1094/1094 [==============================] - 10s 9ms/step - loss: 0.0355 - acc: 0.9889 - val_loss: 1.5379 - val_acc: 0.6791
Epoch 28/30
1094/1094 [==============================] - 9s 8ms/step - loss: 0.0403 - acc: 0.9878 - val_loss: 1.5176 - val_acc: 0.6847
Epoch 29/30
1094/1094 [==============================] - 10s 9ms/step - loss: 0.0394 - acc: 0.9882 - val_loss: 1.6963 - val_acc: 0.6643
Epoch 30/30
1094/1094 [==============================] - 9s 8ms/step - loss: 0.0377 - acc: 0.9883 - val_loss: 1.5240 - val_acc: 0.6874import matplotlib.pyplot as plt
his_dict = history.history
loss = his_dict['loss']
val_loss = his_dict['val_loss']
epochs = range(1, len(loss)+1)
fig = plt.figure(figsize=(10,5))
ax1 = fig.add_subplot(1,2,1) #1,2,1 = 1행 2열의 1째 것
ax1.plot(epochs,loss,color='blue',label='train_loss')
ax1.plot(epochs,val_loss,color='orange',label='val_loss')
ax1.set_title('loss')
ax1.legend()
#정확도
acc = his_dict['acc']
val_acc = his_dict['val_acc']
ax2 = fig.add_subplot(1,2,2) #1,2,1 = 1행 2열의 1째 것
ax2.plot(epochs,acc,color='blue',label='train_acc')
ax2.plot(epochs,val_acc,color='orange',label='val_acc')
ax2.set_title('acc')
ax2.legend()
plt.show()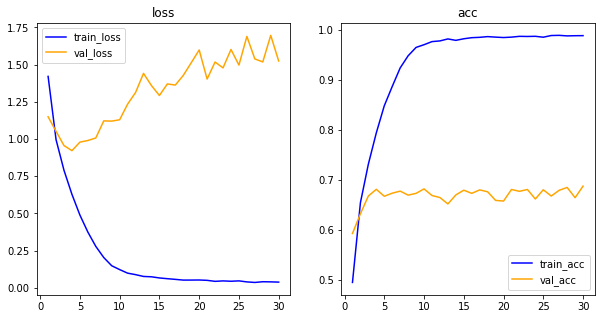
layer구성에 따라 성능에 영향을 준다.
