새싹 인공지능 응용sw 개발자 양성 교육 프로그램 심선조 강사님 수업 정리 글입니다.
fashion_mnist
from keras.datasets.fashion_mnist import load_data#데이터 다운로드
(x_train, y_train), (x_test, y_test) = load_data()
print(x_train.shape,x_test.shape)Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-labels-idx1-ubyte.gz
29515/29515 [==============================] - 0s 0us/step
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-images-idx3-ubyte.gz
26421880/26421880 [==============================] - 2s 0us/step
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-labels-idx1-ubyte.gz
5148/5148 [==============================] - 0s 0us/step
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-images-idx3-ubyte.gz
4422102/4422102 [==============================] - 0s 0us/step
(60000, 28, 28) (10000, 28, 28)- load_data()
This is a dataset of 60,000 28x28 grayscale images of 10 fashion categories,
along with a test set of 10,000 images.
train : 60,000
test : 10,000
Returns:
Tuple of NumPy arrays: (x_train, y_train), (x_test, y_test).
import matplotlib.pyplot as plt
import numpy as np
np.random.seed(777)
class_names = ['T-shirt/top', 'Trouser','Pullover','Dress', 'Coat','Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
sample_size = 9
random_idx = np.random.randint(60000, size=sample_size) #randint 0~59999, size : 몇 개 뽑을 것이냐
plt.figure(figsize=(5,5))
for i, idx in enumerate(random_idx):
plt.subplot(3,3,i+1) #3행의 3열 #+1 index는 0부터시작하고 subplot순서는 1부터 시작해서
plt.xticks([])
plt.yticks([])
plt.imshow(x_train[idx],cmap='gray')
plt.xlabel(class_names[y_train[idx]])
plt.show()
x_train.min(),x_train.max() #딥러닝은 숫자가 크면 문제가 될 수 있어서 0~1사이로 맞춰준다(0, 255)#0~1사이 값으로 조정
x_train = x_train/225 #원본에 덮어쓰는 것이라서 1번만 실행해야 한다.
x_test = x_test/225x_train.min(),x_train.max()(0.0, 1.1333333333333333)y_train.min(),y_train.max()(0, 9)#마지막 결과값이 0~9까지 나오게 할 수 있다. 스팟스, categorical_crossentropy(합이 1이될 때, 9일 확률이 몇 %인지, 정답을 만들어 줄 때는 답만 100%, 나머지는 0% (원핫인코딩) 조정해줘야 한다.
#원핫인코딩
from keras.utils import to_categoricaly_train = to_categorical(y_train)
y_test = to_categorical(y_test)y_test.min(),y_test.max()(0.0, 1.0)#하나만 확인
y_train[0]array([0., 0., 0., 0., 0., 0., 0., 0., 0., 1.], dtype=float32)#학습, 테스트 데이터 분리
#학습하면서 검증도 한다. 검증데이터는 지금 없어서 만들어줌
from sklearn.model_selection import train_test_splitx_train,x_val,y_train,y_val = train_test_split(x_train,
y_train,
test_size=0.3, #데이터 3등분
random_state=777)#모델구성
from keras.models import Sequential
from keras.layers import Dense,Flatten #완결연결층(Dense) 입력과 유닛이 다 연결된 형태 ,
#Flatten: 일차원으로 펼쳐줌 입력이(28*28)으로 들어옴, 완전연결층이랑 연결될려면 1차원으로 펼쳐줘야 함, 들어올 때는 다중차원으로 들어는 것을 1차원으로 펼쳐줌, 1차원으로 reshape하는 것이랑 비슷first_model = Sequential()
first_model.add(Flatten(input_shape=(28,28))) #데이터 한 건이 이런 식으로 들어온다.
first_model.add(Dense(64,activation='relu'))
first_model.add(Dense(32,activation='relu'))
first_model.add(Dense(10,activation='softmax')) #activation='softmax' 다 합쳐서 1#학습시키려면 compile 필요
first_model.compile(optimizer='adam',#optimizer='adam' 가장 흔하게 쓰임, 경사하강법으로 w을 줄이는 쪽으로 조정한다. 처음엔 크게 움직이다 조금씩으로 움직임, 골짜기가 여러개면 넘어갈 수 있는 지 확인
loss='categorical_crossentropy', #loss: 오차계산방법
metrics=['acc']) #metrics=['acc']: 정확도로 평가, 얼마나 맞췄는지-
compile(): 모델 객체를 만든 후 훈련하기 전에 사용할 손실 함수와 측정 지표 등을 지정하는 메서드이다.
-
fit() : 모델을 훈련하는 메서드
-
evaluate() : 모델 선능을 평가하는 메서드
-
이진 분류 : loss = 'binary_crossentropy'
-
다중 분류 : loss = 'categorical_crossentropy'
-
옵티마이저 : 신경망의 가중치와 절편을 학습하기 위한 알고리즘 또는 방법을 말한다. 케라스에는 다양한 경사 하강법 알고리즘이 구현되어 있다. 대표적으로 SGE, 네스테로프 모멘텀, RMSprop, Adam등이 있다.
-
실은 fit()메서드의 실행 결과를 출력한 것이다. fit() 메서드가 무엇인가를 반환한다는 증거이다. 실은 케라스의 fit() 메서드는 Hisotry 클래스 객체를 반환한다.
Hisotry 객체에는 훈련 과정에서 계산한 지표, 즉 손실과 정확도 값이 저장되어 있다.
Hisotry 객체에는 훈련 측정값이 담겨 있는 history 딕셔너리가 들어 있다.
history 속성에 포함된 손실과 정확도는 epochs마다 계산한 값이 순서대로 나열된 단순한 리스트이다.
#모델구성확인
first_model.summary()
#784*64 연결되는 갯수만큼 가중치가 생긴다.
#32개가 10개와 연결된다.
#50240개의 파라미터를 학습한다.
#Trainable params : 파라미터 학습을 통해 값이 변경되는 것
#Non-trainable params: 파라미터 값을 고정해서 학습, 전위학습때 사용Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten (Flatten) (None, 784) 0
dense (Dense) (None, 64) 50240
dense_1 (Dense) (None, 32) 2080
dense_2 (Dense) (None, 10) 330
=================================================================
Total params: 52,650
Trainable params: 52,650
Non-trainable params: 0
_________________________________________________________________first_history = first_model.fit(x_train,
y_train,
epochs=30,#epochs=30 총 데이터 30셋트 학습하겠다
batch_size=128, #batch_size=128: 메모리 사이즈
validation_data=(x_val,y_val)) Epoch 1/30
329/329 [==============================] - 3s 6ms/step - loss: 0.6729 - acc: 0.7678 - val_loss: 0.4855 - val_acc: 0.8331
Epoch 2/30
329/329 [==============================] - 2s 6ms/step - loss: 0.4461 - acc: 0.8440 - val_loss: 0.4163 - val_acc: 0.8581
Epoch 3/30
329/329 [==============================] - 2s 7ms/step - loss: 0.4071 - acc: 0.8571 - val_loss: 0.4482 - val_acc: 0.8321
Epoch 4/30
329/329 [==============================] - 2s 5ms/step - loss: 0.3809 - acc: 0.8658 - val_loss: 0.3844 - val_acc: 0.8643
Epoch 5/30
329/329 [==============================] - 2s 5ms/step - loss: 0.3620 - acc: 0.8709 - val_loss: 0.3696 - val_acc: 0.8694#중략second_model = Sequential()
second_model.add(Flatten(input_shape=(28,28))) #데이터 한 건이 이런 식으로 들어온다.
second_model.add(Dense(128,activation='relu'))
second_model.add(Dense(64,activation='relu'))
second_model.add(Dense(32,activation='relu'))
second_model.add(Dense(10,activation='softmax'))
second_model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['acc'])
second_history = second_model.fit(x_train,
y_train,
epochs=30,
batch_size=128,
validation_data=(x_val,y_val)) Epoch 1/30
329/329 [==============================] - 3s 7ms/step - loss: 0.6038 - acc: 0.7883 - val_loss: 0.4333 - val_acc: 0.8490
Epoch 2/30
329/329 [==============================] - 2s 7ms/step - loss: 0.4143 - acc: 0.8529 - val_loss: 0.3880 - val_acc: 0.8659
Epoch 3/30
329/329 [==============================] - 2s 7ms/step - loss: 0.3773 - acc: 0.8641 - val_loss: 0.3624 - val_acc: 0.8709
Epoch 4/30
329/329 [==============================] - 2s 6ms/step - loss: 0.3462 - acc: 0.8744 - val_loss: 0.3668 - val_acc: 0.8664
Epoch 5/30
329/329 [==============================] - 2s 7ms/step - loss: 0.3257 - acc: 0.8807 - val_loss: 0.3526 - val_acc: 0.8717 #중략second_model.summary()Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten_1 (Flatten) (None, 784) 0
dense_3 (Dense) (None, 128) 100480
dense_4 (Dense) (None, 64) 8256
dense_5 (Dense) (None, 32) 2080
dense_6 (Dense) (None, 10) 330
=================================================================
Total params: 111,146
Trainable params: 111,146
Non-trainable params: 0
_________________________________________________________________def draw_loss_acc(history1,history2,epochs):
his_dict_1 = history1.history
his_dict_2 = history2.history
keys = list(his_dict_1.keys())
epochs = range(1,epochs)
fig = plt.figure(figsize=(10,10))
ax = fig.add_subplot(1,1,1)
ax.spines['top'].set_color('none')
ax.spines['bottom'].set_color('none')
ax.spines['left'].set_color('none')
ax.spines['right'].set_color('none')
ax.tick_params(labelcolor='w',top=False,bottom=False,left=False,right=False)
for i in range(len(his_dict_1)): #i=0~3,( loss=0, acc=1, val_loss=2, val_acc=3)
temp_ax = fig.add_subplot(2,2,i+1)#임시
temp = keys[i%2]#0,1,0,1
val_temp = keys[(i+2)%2+2] #(0+2=2%2=0+2=2, 1+2=3%2=1+2=3, 2+2=4%2=0+2=2, 3+2=5%2=1+2=3) #2, 3, 2, 3
temp_history = his_dict_1 if i < 2 else his_dict_2
#선그래프
temp_ax.plot(epochs,temp_history[temp][1:],color='blue',label='train_'+temp)
temp_ax.plot(epochs,temp_history[val_temp][1:],color='orange',label='val_'+val_temp)
if(i==1 or i==3):
start,end = temp_ax.get_ylim()
temp_ax.yaxis.set_ticks(np.arange(np.round(start, 2),end,0.01)) #arange : 순차적으로 만듦
temp_ax.legend()
ax.set_ylabel('loss',size=20, labelpad=20)
ax.set_xlabel('Epochs',size=20,labelpad=20)
plt.tight_layout()
plt.show()
draw_loss_acc(first_history,second_history,30)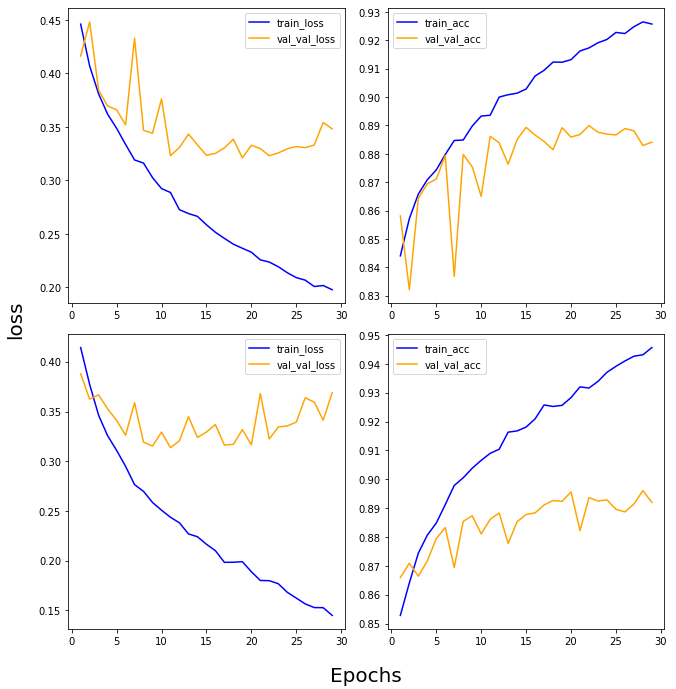
from google.colab import drive
drive.mount('/content/drive')from PIL import Image
import numpy as npimg = Image.open('/content/drive/MyDrive/Colab Notebooks/sesac_deeplerning/04_fashion_mnist_img/img02.jpg')
img = img.convert('L')
img = img.resize((28,28))
img = np.array(img)
img = (255-img)/255 #0~1사이 값으로 조정
plt.imshow(img,cmap='gray') #학습된 모델형태로 데이터를 넣어줘야 한다
plt.show()img.shape,x_train[0].shape #x_train 여러개다
img.shape,x_train[0].shapeimg.shape,x_train.shaperesult = first_model.predict(img.reshape(-1,28,28))result.shapenp.argmax(np.round(result,2))class_names[np.argmax(np.round(result,2))]보스턴 주택 가격 예측
연속적인 값을 예측하는 회귀
from keras.datasets.boston_housing import load_data(x_train, y_train), (x_test, y_test) = load_data() #returnDownloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/boston_housing.npz
57026/57026 [==============================] - 0s 0us/stepx_train.shape,x_test.shape #columns의 수 13, 데이터 건수: 404,102((404, 13), (102, 13))y_train.shape(404,)y_train[0]15.2import numpy as npmean = np.mean(x_train) #standarscaler와 비슷
std = np.std(x_train) #학습데이터(train)에 맞춰서 구하기
x_train = (x_train-mean)/std
x_test = (x_test-mean)/std #평균이 1, 표준편차가 1인 형태로 만들어줌from sklearn.model_selection import train_test_splitx_train,x_val,y_train,y_val = train_test_split(x_train,
y_train,
test_size=0.33,
random_state=777)from keras.models import Sequential
from keras.layers import Densemodel = Sequential()
model.add(Dense(64,activation='relu',input_shape=(13,)))#columns이 13개라서 13으로 들어감
model.add(Dense(32,activation='relu',input_shape=(13,)))
model.add(Dense(1)) #최종결과는 값이 1개로 나가면 된다.
#회귀는 activation 함수를 따로 사용하지 않는다.
model.compile(optimizer='adam',loss='mse',metrics=['mae']) #mse:제곱, mae: 절댓값
history = model.fit(x_train,y_train,epochs=300,validation_data=(x_val,y_val))
#val_mae: 3.6096 = 실제와 3천달러 정도 차이가 난다.Epoch 1/300
9/9 [==============================] - 1s 24ms/step - loss: 10232.1318 - mae: 86.9389 - val_loss: 572.0309 - val_mae: 16.9066
Epoch 2/300
9/9 [==============================] - 0s 5ms/step - loss: 1153.9900 - mae: 29.3517 - val_loss: 1861.4796 - val_mae: 40.7154
Epoch 3/300
9/9 [==============================] - 0s 7ms/step - loss: 1101.8955 - mae: 28.9706 - val_loss: 263.9049 - val_mae: 13.6544
Epoch 4/300
9/9 [==============================] - 0s 5ms/step - loss: 248.9337 - mae: 12.2273 - val_loss: 252.5219 - val_mae: 12.9567
Epoch 5/300
9/9 [==============================] - 0s 5ms/step - loss: 242.9705 - mae: 12.7658 - val_loss: 94.9467 - val_mae: 7.4209 #중략model.evaluate(x_test,y_test)4/4 [==============================] - 0s 4ms/step - loss: 32.8565 - mae: 4.2282
[32.85646057128906, 4.228188991546631]from keras.datasets.boston_housing import load_data
from keras.models import Sequential
from keras.layers import Dense
from sklearn.model_selection import KFold
import numpy as np(x_train, y_train), (x_test, y_test) = load_data(seed=777)
mean = np.mean(x_train)
std = np.std(x_train)
x_train = (x_train-mean)/std
x_test = (x_test-mean)/std
k=3
kfold = KFold(n_splits=k,shuffle=True,random_state=777)
def get_model():
model = Sequential()
model.add(Dense(64,activation='relu',input_shape=(13,)))
model.add(Dense(32,activation='relu',input_shape=(13,)))
model.add(Dense(1))
model.compile(optimizer='adam',loss='mse',metrics=['mae'])
return model
mae_list=[]#교차검증 결과값
for train_index,val_index in kfold.split(x_train):
x_train_fold,x_val_fold = x_train[train_index],x_train[val_index]
y_train_fold,y_val_fold = y_train[train_index],y_train[val_index]
model = get_model()
model.fit(x_train_fold,y_train_fold,epochs=300,validation_data=(x_val_fold,y_val_fold))
#2개가 return 앞에는 mse, 뒤는 mae 평가는 mae로, _ = 값을 저장하지 않겠다.
_,test_mae = model.evaluate(x_test,y_test)
mae_list.append(test_mae)
Epoch 1/300
9/9 [==============================] - 1s 21ms/step - loss: 540.3470 - mae: 21.5779 - val_loss: 593.4420 - val_mae: 22.1595
Epoch 2/300
9/9 [==============================] - 0s 5ms/step - loss: 517.9594 - mae: 21.0401 - val_loss: 570.3544 - val_mae: 21.6133
Epoch 3/300
9/9 [==============================] - 0s 7ms/step - loss: 494.2890 - mae: 20.4442 - val_loss: 543.8036 - val_mae: 20.9738
Epoch 4/300
9/9 [==============================] - 0s 8ms/step - loss: 466.2677 - mae: 19.7332 - val_loss: 512.0202 - val_mae: 20.1866
Epoch 5/300
9/9 [==============================] - 0s 7ms/step - loss: 432.9722 - mae: 18.8435 - val_loss: 473.8460 - val_mae: 19.2045 #중략#교차검증 개별값, 평균값 확인
print(mae_list)
print(np.mean(mae_list))[5.067984580993652, 4.904557704925537, 4.5069756507873535]
4.826505978902181- mnist는 다중분류
다중 label = 2가지, 3가지 여러가지 선택하는 것
from google.colab import drive
drive.mount('/content.drive')Mounted at /content.drive!pwd/content!mkdir clothes_dataset!unzip '/content.drive/MyDrive/Colab Notebooks/sesac_deeplerning/clothes_dataset.zip' -d ./clothes_dataset/[1;30;43m스트리밍 출력 내용이 길어서 마지막 5000줄이 삭제되었습니다.[0m
inflating: ./clothes_dataset/brown_shoes/30ef20bcb027c99409c81fd6127957502b0e693e.jpg
inflating: ./clothes_dataset/brown_shoes/312cf581fd4ec3678b8794f9f488aa1dad2f2908.jpg
inflating: ./clothes_dataset/brown_shoes/337a443bf71b424c5ff4bfa06bdfcc2a447f9535.jpg #중략#정보 만들기 : 해당하는 이미지의 레이블값 연결
import numpy as np
import pandas as pd
import tensorflow as tf
import glob as glob
import cv2
all_data = np.array(glob.glob('/content/clothes_dataset/*/*.jpg', recursive=True))
# 색과 옷의 종류를 구별하기 위해 해당되는 label에 1을 삽입합니다.
def check_cc(color, clothes):
labels = np.zeros(11,) #0으로 채워서 11칸을 만들어라
# color check
if(color == 'black'):
labels[0] = 1
color_index = 0
elif(color == 'blue'):
labels[1] = 1
color_index = 1
elif(color == 'brown'):
labels[2] = 1
color_index = 2
elif(color == 'green'):
labels[3] = 1
color_index = 3
elif(color == 'red'):
labels[4] = 1
color_index = 4
elif(color == 'white'):
labels[5] = 1
color_index = 5
# clothes check
if(clothes == 'dress'):
labels[6] = 1
elif(clothes == 'shirt'):
labels[7] = 1
elif(clothes == 'pants'):
labels[8] = 1
elif(clothes == 'shorts'):
labels[9] = 1
elif(clothes == 'shoes'):
labels[10] = 1
return labels, color_index
# label과 color_label을 담을 배열을 선언합니다.
all_labels = np.empty((all_data.shape[0], 11)) #(행{all_data.shape[0]:데이터 건수},열)
all_color_labels = np.empty((all_data.shape[0], 1))
# print(all_data[0])
for i, data in enumerate(all_data):
color_and_clothes = all_data[i].split('/')[-2].split('_')
color = color_and_clothes[0]
clothes = color_and_clothes[1]
# print(color,clothes)
labels, color_index = check_cc(color, clothes)
all_labels[i] = labels #i번째에 labels을 넣어라
all_color_labels[i] = color_index
all_labels = np.concatenate((all_labels, all_color_labels), axis = -1) #axis = -1 , columns 옆으로 붙인다.all_data #일차원 벡터형태array(['/content/clothes_dataset/red_shoes/57007b1e36f9b86f2832005bf20de8d3fe12b518.jpg',
'/content/clothes_dataset/red_shoes/5e006b1eab73efeaa91fb76aa7c2d6e24706e60f.jpg',
'/content/clothes_dataset/red_shoes/c23f9fcb3caebad169fd4b671cf71fd196fed7e3.jpg',
...,
'/content/clothes_dataset/blue_shirt/83c86d0baf7782dc40aced68d451ad835bce930c.jpg',
'/content/clothes_dataset/blue_shirt/7b0dae0a9bd09af24390c50089e14ed5874c060c.jpg',
'/content/clothes_dataset/blue_shirt/c93ff1693d6d827ff4262c7bcf24c0d44ce397be.jpg'],
dtype='<U82')all_labels.shape(11385, 12)from sklearn.model_selection import train_test_split
# 훈련, 검증, 테스트 데이터셋으로 나눕니다.
train_x, test_x, train_y, test_y = train_test_split(all_data, all_labels, shuffle = True, test_size = 0.3,
random_state = 99)
train_x, val_x, train_y, val_y = train_test_split(train_x, train_y, shuffle = True, test_size = 0.3,
random_state = 99)train_df = pd.DataFrame({'image':train_x, 'black':train_y[:, 0], 'blue':train_y[:, 1],
'brown':train_y[:, 2], 'green':train_y[:, 3], 'red':train_y[:, 4],
'white':train_y[:, 5], 'dress':train_y[:, 6], 'shirt':train_y[:, 7],
'pants':train_y[:, 8], 'shorts':train_y[:, 9], 'shoes':train_y[:, 10],
'color':train_y[:, 11]})
val_df = pd.DataFrame({'image':val_x, 'black':val_y[:, 0], 'blue':val_y[:, 1],
'brown':val_y[:, 2], 'green':val_y[:, 3], 'red':val_y[:, 4],
'white':val_y[:, 5], 'dress':val_y[:, 6], 'shirt':val_y[:, 7],
'pants':val_y[:, 8], 'shorts':val_y[:, 9], 'shoes':val_y[:, 10],
'color':val_y[:, 11]})
test_df = pd.DataFrame({'image':test_x, 'black':test_y[:, 0], 'blue':test_y[:, 1],
'brown':test_y[:, 2], 'green':test_y[:, 3], 'red':test_y[:, 4],
'white':test_y[:, 5], 'dress':test_y[:, 6], 'shirt':test_y[:, 7],
'pants':test_y[:, 8], 'shorts':test_y[:, 9], 'shoes':test_y[:, 10],
'color':test_y[:, 11]})train_df.head() #색상값 원핫인코딩됨 #데이터가 정리가 되있어야 한다.| image | black | blue | brown | green | red | white | dress | shirt | pants | shorts | shoes | color | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | /content/clothes_dataset/green_shorts/e74d11d3... | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 3.0 |
| 1 | /content/clothes_dataset/black_dress/f1be32393... | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 2 | /content/clothes_dataset/black_shoes/04f78f68a... | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 |
| 3 | /content/clothes_dataset/brown_pants/0671d132b... | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 2.0 |
| 4 | /content/clothes_dataset/white_shoes/59803fb01... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 5.0 |
<svg xmlns="http://www.w3.org/2000/svg" height="24px"viewBox="0 0 24 24"
width="24px">
<script>
const buttonEl =
document.querySelector('#df-167ca4c7-17e9-4c83-bd1c-a17868b5fdc9 button.colab-df-convert');
buttonEl.style.display =
google.colab.kernel.accessAllowed ? 'block' : 'none';
async function convertToInteractive(key) {
const element = document.querySelector('#df-167ca4c7-17e9-4c83-bd1c-a17868b5fdc9');
const dataTable =
await google.colab.kernel.invokeFunction('convertToInteractive',
[key], {});
if (!dataTable) return;
const docLinkHtml = 'Like what you see? Visit the ' +
'<a target="_blank" href=https://colab.research.google.com/notebooks/data_table.ipynb>data table notebook</a>'
+ ' to learn more about interactive tables.';
element.innerHTML = '';
dataTable['output_type'] = 'display_data';
await google.colab.output.renderOutput(dataTable, element);
const docLink = document.createElement('div');
docLink.innerHTML = docLinkHtml;
element.appendChild(docLink);
}
</script>
</div>!pwd/content!mkdir csv_datatrain_df.to_csv('/content/csv_data/train.csv',index=False)
val_df.to_csv('/content/csv_data/val.csv',index=False)
test_df.to_csv('/content/csv_data/test.csv',index=False)#파일을 숫자로 읽어와야 함 -> batch_size
from keras.preprocessing.image import ImageDataGenerator #preprocessing = 전처리train_datagen = ImageDataGenerator(rescale=1./255) #0~1사이 값으로 조정
val_datagen = ImageDataGenerator(rescale=1./255)
def get_steps(num_samples,batch_size): #batch_sizer = 한 번에 작업할 갯수
if(num_samples % batch_size) > 0:
return (num_samples // batch_size) + 1 #//=몫, % = 나머지
else:
return (num_samples // batch_size) from keras.models import Sequential
from keras.layers import Dense,Flattenmodel = Sequential()
model.add(Flatten(input_shape=(112,112,3))) #input_shape=(112,112,3) R G B->3차원
model.add(Dense(128,activation='relu'))
model.add(Dense(64,activation='relu'))
model.add(Dense(11,activation='sigmoid'))#softmax를 사용할 수 없음
model.compile(optimizer='adam',loss='binary_crossentropy',metrics=['binary_accuracy'])
- sigmoid
값을 0~1사이로 만들어줌
model.summary()Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten (Flatten) (None, 37632) 0
dense (Dense) (None, 128) 4817024
dense_1 (Dense) (None, 64) 8256
dense_2 (Dense) (None, 11) 715
=================================================================
Total params: 4,825,995
Trainable params: 4,825,995
Non-trainable params: 0
_________________________________________________________________train_df.columnsIndex(['image', 'black', 'blue', 'brown', 'green', 'red', 'white', 'dress',
'shirt', 'pants', 'shorts', 'shoes', 'color'],
dtype='object')batch_size = 32
class_col = ['black', 'blue', 'brown', 'green', 'red', 'white', 'dress','shirt', 'pants', 'shorts', 'shoes']
train_generator = train_datagen.flow_from_dataframe(dataframe=train_df,
x_col='image',
y_col=class_col,
target_size=(112,112),
color_mode='rgb',
class_mode='raw',
batch_size=batch_size,
shuffle=True,
seed=42) #디렉토리로 불러온다면 cat - cat만, 구조 정보를 가지고 label로 처리
val_generator = val_datagen.flow_from_dataframe(dataframe=val_df,
x_col='image',
y_col=class_col,
target_size=(112,112),
color_mode='rgb',
class_mode='raw',
batch_size=batch_size,
shuffle=True,
)Found 5578 validated image filenames.
Found 2391 validated image filenames.model.fit(train_generator,
steps_per_epoch=get_steps(len(train_df),batch_size),
validation_data=val_generator,
validation_steps=get_steps(len(val_df),batch_size),
epochs=10)
Epoch 1/10
175/175 [==============================] - 32s 170ms/step - loss: 0.5400 - binary_accuracy: 0.8449 - val_loss: 0.3948 - val_binary_accuracy: 0.8488
Epoch 2/10
175/175 [==============================] - 29s 164ms/step - loss: 0.3062 - binary_accuracy: 0.8823 - val_loss: 0.3138 - val_binary_accuracy: 0.8857
Epoch 3/10
175/175 [==============================] - 29s 164ms/step - loss: 0.2688 - binary_accuracy: 0.8944 - val_loss: 0.2285 - val_binary_accuracy: 0.9120
Epoch 4/10
175/175 [==============================] - 28s 159ms/step - loss: 0.2411 - binary_accuracy: 0.9066 - val_loss: 0.2349 - val_binary_accuracy: 0.9083
Epoch 5/10
175/175 [==============================] - 27s 157ms/step - loss: 0.2192 - binary_accuracy: 0.9131 - val_loss: 0.2567 - val_binary_accuracy: 0.9056
Epoch 6/10
175/175 [==============================] - 28s 158ms/step - loss: 0.2067 - binary_accuracy: 0.9180 - val_loss: 0.2070 - val_binary_accuracy: 0.9216
Epoch 7/10
175/175 [==============================] - 28s 160ms/step - loss: 0.1900 - binary_accuracy: 0.9242 - val_loss: 0.2039 - val_binary_accuracy: 0.9178
Epoch 8/10
175/175 [==============================] - 28s 159ms/step - loss: 0.1859 - binary_accuracy: 0.9261 - val_loss: 0.2049 - val_binary_accuracy: 0.9185
Epoch 9/10
175/175 [==============================] - 29s 167ms/step - loss: 0.1822 - binary_accuracy: 0.9288 - val_loss: 0.2099 - val_binary_accuracy: 0.9206
Epoch 10/10
175/175 [==============================] - 28s 158ms/step - loss: 0.1873 - binary_accuracy: 0.9267 - val_loss: 0.2576 - val_binary_accuracy: 0.9010
<keras.callbacks.History at 0x7fcb1c8e09d0>test_datagen = ImageDataGenerator(rescale=1./255)
test_generator = test_datagen.flow_from_dataframe(dataframe=test_df,
x_col='image',
y_col=None,
target_size=(112,112),
color_mode='rgb',
class_mode=None,
batch_size=batch_size,
shuffle=False)
preds = model.predict(test_generator,steps=get_steps(len(val_df),batch_size),verbose=1)Found 3416 validated image filenames.
75/75 [==============================] - 9s 121ms/stepnp.round(preds[0],2)array([0., 0., 0., 1., 0., 0., 0., 1., 0., 0., 0.], dtype=float32)import matplotlib.pyplot as pltdo_preds = preds[:8] #맨 앞에서부터 index 8까지
for i , pred in enumerate(do_preds):
plt.subplot(2,4,i+1)
prob = zip(class_col, list(pred)) #class_col: 색깔, 옷종류
#print(list(prob))
prob = sorted(list(prob),key=lambda x:x[1], reverse=True) #list(prob) = x , x[1] = x의 index 1번 (2.6131565e-05) , 숫자값으로 정렬하겠다
# print(prob)
image = cv2.imread(test_df['image'][i])
image = cv2.cvtColor(image,cv2.COLOR_BGR2RGB)
plt.imshow(image)
plt.title(f'{prob[0][0]}:{round(prob[0][1]*100,2)}% \n{prob[1][0]}:{round(prob[1][1]*100,2)}%') #\n = 줄바꿈
plt.tight_layout()
plt.show()
#모델예측, 예측은 label값은 필요없다
data_datagen = ImageDataGenerator(rescale = 1./255)
data_generator = data_datagen.flow_from_directory(directory='/content.drive/MyDrive/Colab Notebooks/sesac_deeplerning/06_clothes_img',
target_size=(112,112),
color_mode='rgb',
batch_size=batch_size,
shuffle=False)
result = model.predict(data_generator,steps=get_steps(2,batch_size),verbose=1)Found 2 images belonging to 1 classes.
1/1 [==============================] - 0s 70ms/stepnp.round(result,2)array([[0.68, 0.79, 0. , 0.27, 0. , 0. , 0.51, 0.08, 0.3 , 0.04, 0.25],
[0.56, 0.97, 0. , 0.01, 0. , 0. , 0.02, 0.01, 0. , 0.01, 0.93]],
dtype=float32)#다중레이블처리, 이미지를 수집했는데 사이즈가 제 각각이면 ImageDataGenerator사용해서 필요한 만큼 사용 + 메모리 활용
#cnn 사용할 때는 cnn에 맞는 방식을 사용해야 한다.
for i , pred in enumerate(result):
prob = zip(class_col,list(pred))
prob = sorted(list(prob),key=lambda x:x[1], reverse=True)
print((f'{prob[0][0]}:{round(prob[0][1]*100,2)}% \n{prob[1][0]}:{round(prob[1][1]*100,2)}%'))
blue:79.42%
black:68.24%
blue:96.88%
shoes:93.22%