새싹 인공지능 응용sw 개발자 양성 교육 프로그램 심선조 강사님 수업 정리 글입니다.
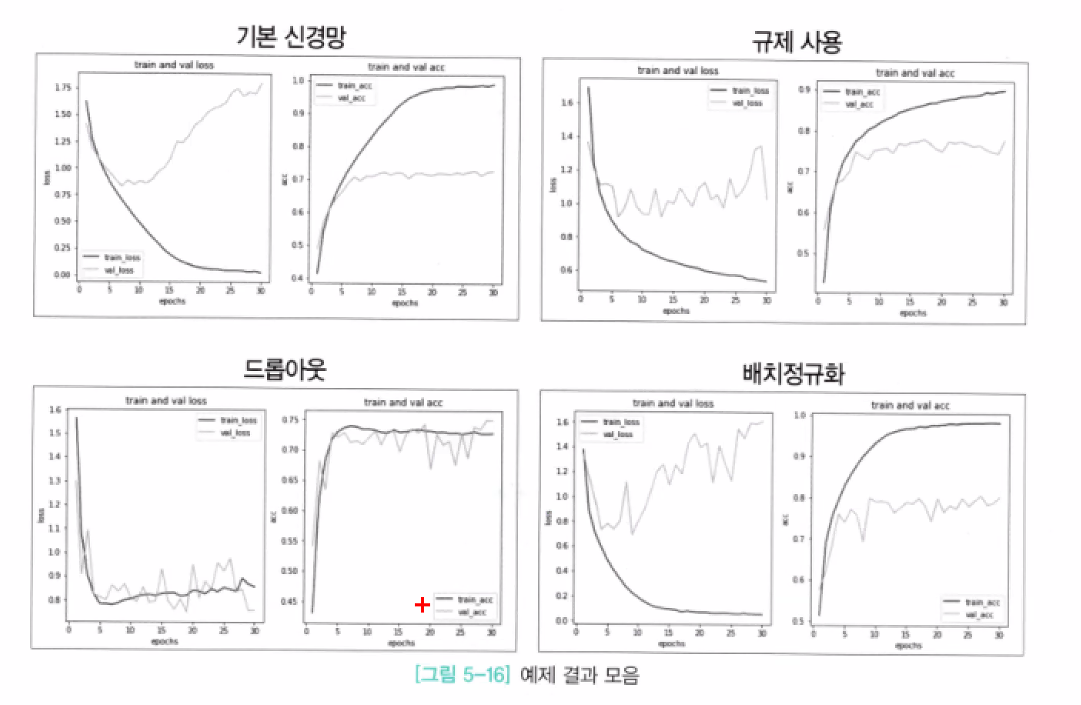
validation data는 새로운 데이터
과적합 방지하기 위한 배치 정규화, 규제 사용, 드롭 아웃 등등 사용
딥러닝은 엄청나게 많은 데이터를 수집해야 제대로된 학습이 된다. 데이터가 부족하면 기존에 있는 데이터를 증식하는 방법도 있다.
데이터 증식
이미지 데이터의 데이터 증식
이미지는 사이즈, 회전 등등 여러 방식으로 원본 데이터와 다르게 만들 수 있다.
데이터 증식의 장점
- 다양한 데이터를 입력시킴으로써 모델을 더욱 견고하게 만들어줘서 테스트 시에 더 높은 성능을 기대할 수 있다.
- 수집된 데이터가 적은 경우에 강력한 힘을 발휘한다.
데이터가 적은 경우 모델을 일반화시키기 어렵기에 과대적합이 발생할 확률이 높다.
batch_size : 몇 개의 샘플로 가중치를 갱신할 것인지 설정
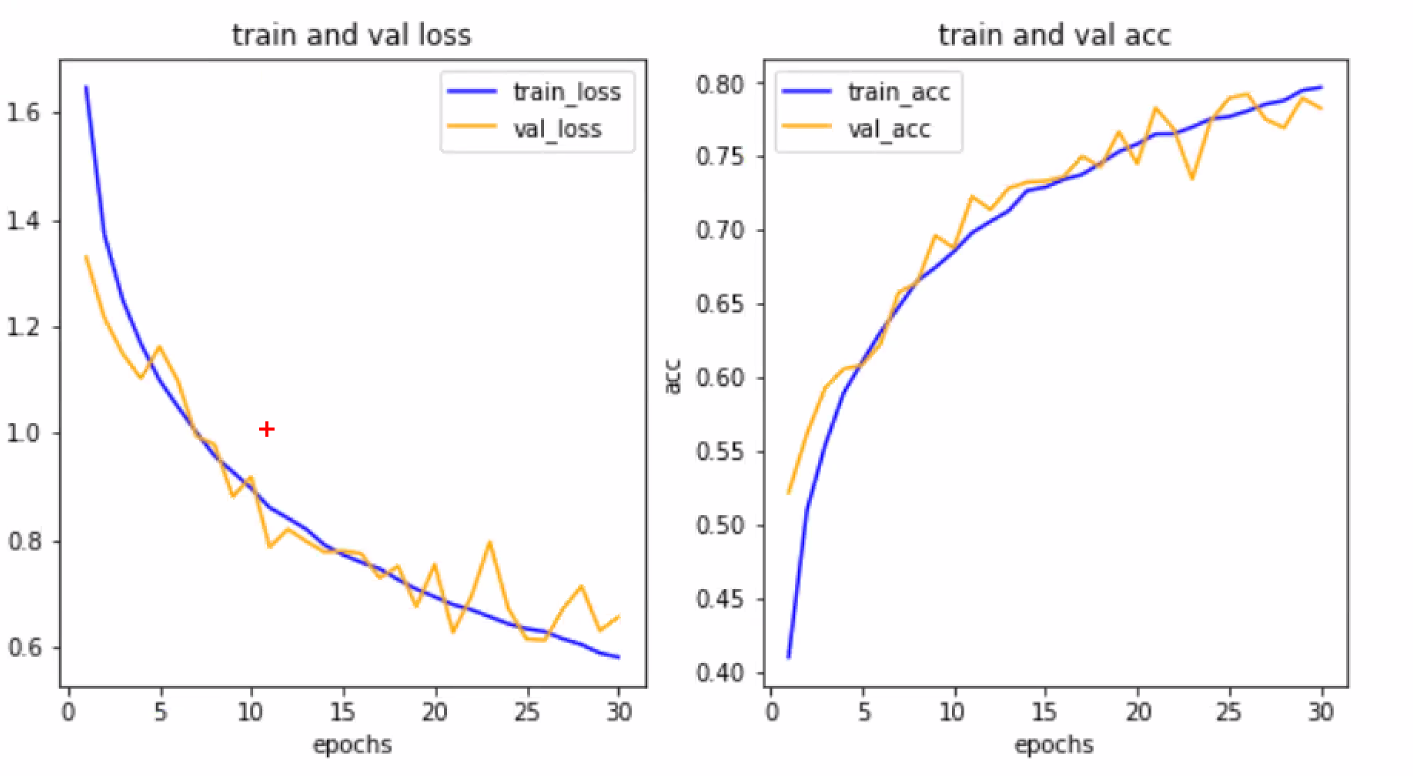
- 좋은 그래프
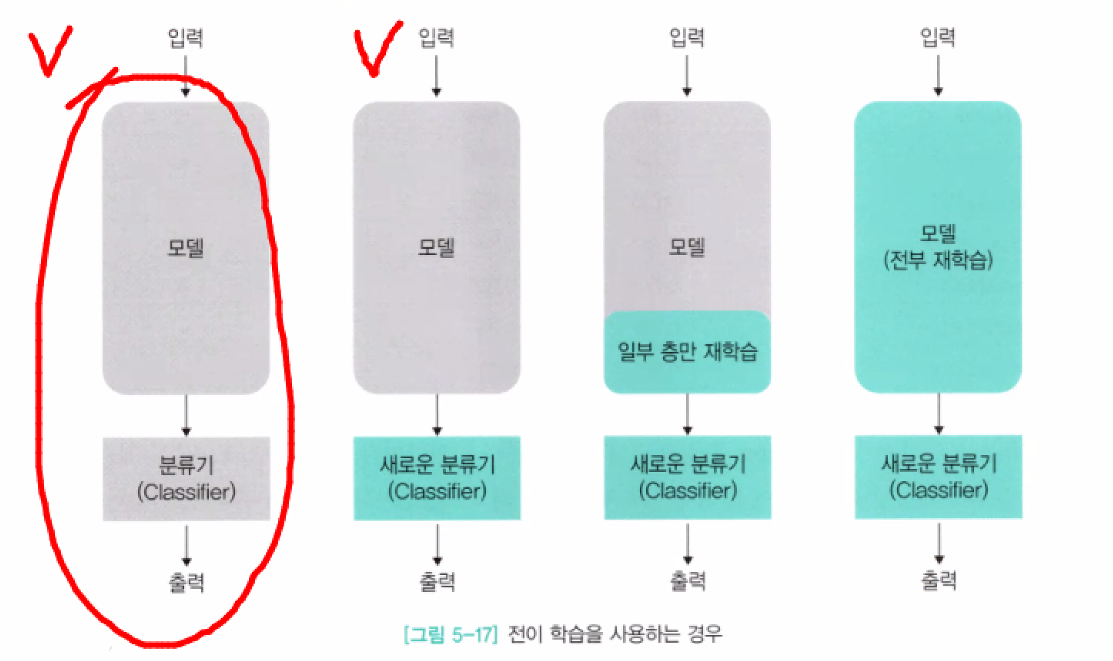
전이학습
해결하려는 문제에서 빠른 속도로 일정 수준의 베이스라인 성능을 얻고 싶을 때, 쉽고 빠른 방법인 전이 학습
전이 학습의 핵심은 사전 학습된 네트워크의 가중치를 사요하는 것이다.
전이 학습은 크게 세가지로 분류한다.
- 모델을 변형하지 않고 사용하는 방법
- 모델의 분류기를 재학습하는 방법(기본적으로 가장 많이 사용)
- 모델의 일부를 동결 해제하여 재학습
- 2번째 모델을 가장 많이 씀
함수를 만들 때 Sequneital모델로 만듦. 단점은 층이 순서대로 쌓음
우리가 사용할 데이터셋에서 어떤 구조의 모델이 최고 성능을 낼지 모르기 때문에, 다양한 모델을 사용하여 학습시켜보고 결과를 비교해보는 것도 중요하다.
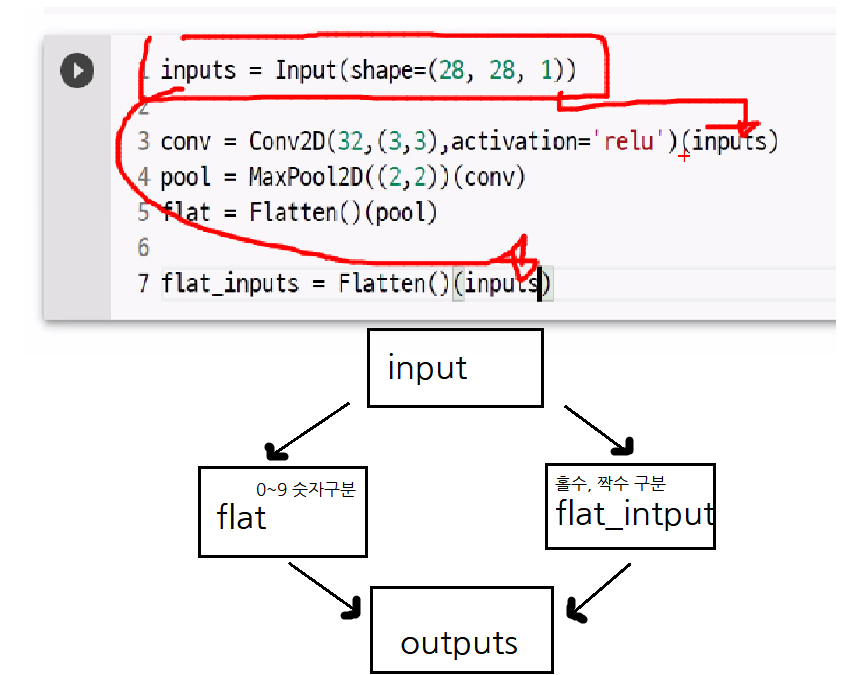
- predict() 메서드는 항상 입력의 첫 번째 차원이 배치 차원일 것으로 기대한다. 하나의 샘플을 전달하더라도 꼭 첫 번째 차원을 유지해야 한다.
from keras.utils import load_img, img_to_array
from keras.preprocessing.image import ImageDataGenerator
import matplotlib.pyplot as plt
import numpy as nptrain_datagen = ImageDataGenerator(horizontal_flip=True, #horizontal_flip=True 수평으로 뒤집어서 이미지 변경
vertical_flip=True, #vertical_flip=True 수직으로 뒤집어서 이미지 변경
shear_range=0.5,#시계반대방향으로 50%회전
brightness_range=[0.5,1.5], #밝기
zoom_range=0.2, #확대
width_shift_range=0.1, #넓이쪽으로 이동 전체크기 10% 좌우로 조절
height_shift_range=0.1, #높이쪽 이동 위아래로 조정
rotation_range=30, #회전
fill_mode='nearest') #주변매꾸는 방식 img = img_to_array(load_img('img001.jpg')).astype(np.uint8)
plt.imshow(img)<matplotlib.image.AxesImage at 0x7f0af67b53d0>
result = img.reshape((1,)+img.shape) #reshape((1 앞에다 차원 붙이겠다.
img.shape,result.shape #1, 249, 202, 3 = 1(데이터 건수), -1해서 추가해도 된다?((249, 202, 3), (1, 249, 202, 3))train_generator = train_datagen.flow(result,batch_size=1)#batch_size=1 : 1개씩 returnfig = plt.figure(figsize=(5,5))
fig.suptitle('jisoo')
for i in range(9):
data = next(train_generator) #batch_size만큼 next(train_generator) train_generator을 받아서 reutrn해준다
#print(data.shape)
#4차원은 차트로 못 그려서 1건만 가져와야 한다.
image = data[0]
plt.subplot(3,3,i+1) #3행 3열 i+1번째
plt.xticks([])
plt.yticks([])
plt.imshow(np.array(image,dtype=np.uint8))
# print(image.min(),image.max())
plt.show() #지정해준 범위안에서 무작위로 나타남
#데이터 가져오기
from keras.datasets import cifar10
import numpy as np
from sklearn.model_selection import train_test_split
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
#기본 전처리
x_mean = np.mean(x_train,axis=(0,1,2))
x_std = np.std(x_train,axis=(0,1,2))
x_train=(x_train-x_mean)/x_std
x_test =(x_test-x_mean)/x_std
#데이터 분리
x_train,x_val,y_train,y_val = train_test_split(x_train,y_train,test_size=0.3,random_state=777)Downloading data from https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz
170498071/170498071 [==============================] - 14s 0us/steptrain_datagen = ImageDataGenerator(horizontal_flip=True,
zoom_range=0.2,
width_shift_range=0.1,
height_shift_range=0.1,
rotation_range=30,
fill_mode='nearest')
val_datagen = ImageDataGenerator()
batch_size = 32
train_generator = train_datagen.flow(x_train,y_train,batch_size=batch_size)
val_generator = val_datagen.flow(x_val,y_val,batch_size=batch_size)from keras.models import Sequential
from keras.layers import Conv2D,MaxPool2D,Dense,Flatten,Activation,BatchNormalization
from keras.optimizers import Adam
model = Sequential([
Conv2D(filters=32,kernel_size=3,padding='same', input_shape=(32, 32, 3)),
BatchNormalization(),
Activation('relu'),
Conv2D(filters=32,kernel_size=3,padding='same'),
BatchNormalization(),
Activation('relu'),
MaxPool2D(pool_size=(2,2),strides=2,padding='same'),
Conv2D(filters=64,kernel_size=3,padding='same'),
BatchNormalization(),
Activation('relu'),
Conv2D(filters=64,kernel_size=3,padding='same'),
BatchNormalization(),
Activation('relu'),
MaxPool2D(pool_size=(2,2),strides=2,padding='same'),
Conv2D(filters=128,kernel_size=3,padding='same'),
BatchNormalization(),
Activation('relu'),
Conv2D(filters=128,kernel_size=3,padding='same'),
BatchNormalization(),
Activation('relu'),
MaxPool2D(pool_size=(2,2),strides=2,padding='same'),
Flatten(),
Dense(256),
BatchNormalization(),
Activation('relu'),
Dense(10, activation='softmax') #결과값이 나가는 층이라서 상관x
])
model.compile(optimizer=Adam(1e-4),loss='sparse_categorical_crossentropy',metrics=['acc'])
def get_step(train_len,batch_size):
if(train_len % batch_size > 0):
return train_len // batch_size +1
else:
return train_len // batch_size
#fit
history = model.fit(train_generator,
epochs=30,
steps_per_epoch=get_step(len(x_train),batch_size),
validation_data=val_generator,
validation_steps=get_step(len(x_val),batch_size))Epoch 1/30
96/1094 [=>............................] - ETA: 19s - loss: 2.1468 - acc: 0.1872import matplotlib.pyplot as plt
his_dict = history.history
loss = his_dict['loss']
val_loss = his_dict['val_loss']
epochs = range(1, len(loss)+1)
fig = plt.figure(figsize=(10,5))
ax1 = fig.add_subplot(1,2,1) #1,2,1 = 1행 2열의 1째 것
ax1.plot(epochs,loss,color='blue',label='train_loss')
ax1.plot(epochs,val_loss,color='orange',label='val_loss')
ax1.set_title('loss')
ax1.legend()
#정확도
acc = his_dict['acc']
val_acc = his_dict['val_acc']
ax2 = fig.add_subplot(1,2,2) #1,2,1 = 1행 2열의 1째 것
ax2.plot(epochs,acc,color='blue',label='train_acc')
ax2.plot(epochs,val_acc,color='orange',label='val_acc')
ax2.set_title('acc')
ax2.legend()
plt.show()#predict하고 싶으면 adarray로 바로 넣으면 안 된다. -> 학습했을 때 형태로 넣어줘야 한다.
test_datagen = ImageDataGenerator()
test_generator = test_datagen.flow(x_test,
batch_size = batch_size)
pred = model.predict(x_test)
np.argmax(np.round(pred[0],2))test_datagen = ImageDataGenerator()
test_generator = test_datagen.flow_from_directory('./data',
batch_size = batch_size)
pred = model.predict(x_test)
np.argmax(np.round(pred[0],2))#데이터 가져오기
from keras.datasets import cifar10
import numpy as np
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
plt.imshow(x_test[0])
#기본 전처리
x_mean = np.mean(x_train,axis=(0,1,2))
x_std = np.std(x_train,axis=(0,1,2))
x_train=(x_train-x_mean)/x_std
x_test =(x_test-x_mean)/x_std
#데이터 분리
x_train,x_val,y_train,y_val = train_test_split(x_train,y_train,test_size=0.3,random_state=777)
y_train.shapeDownloading data from https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz
170498071/170498071 [==============================] - 9s 0us/step
(35000, 1)
x_train.shape(35000, 32, 32, 3)# 전위학습
from keras.preprocessing.image import ImageDataGenerator
train_datagen = ImageDataGenerator(horizontal_flip=True,
zoom_range=0.2,
width_shift_range=0.1,
height_shift_range=0.1,
rotation_range=30,
fill_mode='nearest')
val_datagen = ImageDataGenerator()
batch_size = 32
train_generator = train_datagen.flow(x_train,y_train,batch_size=batch_size)
val_generator = val_datagen.flow(x_val,y_val,batch_size=batch_size)include_top: bool = True : 기존 것을 사용하겠다
include_top: bool = False : 내거를 쓰겠다. -> input_shape: Any
모델에 처음 들어올 때 형태
학습할 때 사용했던 데이터 형태와 나의 데이터 형태를 맞춰줘야 한다.
weights: 가중치
# 모델
from keras.models import Sequential
from keras.layers import Conv2D,MaxPool2D,Dense,Flatten,Activation,BatchNormalization
from keras.optimizers import Adam
#학습된 모델 가져오기
from keras.applications import VGG16
vgg16 =VGG16(include_top=False,input_shape=(32, 32, 3))
vgg16.summary() #필터 = 커널
#MaxPooling2D -> 반으로 줄어듬Downloading data from https://storage.googleapis.com/tensorflow/keras-applications/vgg16/vgg16_weights_tf_dim_ordering_tf_kernels_notop.h5
58889256/58889256 [==============================] - 2s 0us/step
Model: "vgg16"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 32, 32, 3)] 0
block1_conv1 (Conv2D) (None, 32, 32, 64) 1792
block1_conv2 (Conv2D) (None, 32, 32, 64) 36928
block1_pool (MaxPooling2D) (None, 16, 16, 64) 0
block2_conv1 (Conv2D) (None, 16, 16, 128) 73856
block2_conv2 (Conv2D) (None, 16, 16, 128) 147584
block2_pool (MaxPooling2D) (None, 8, 8, 128) 0
block3_conv1 (Conv2D) (None, 8, 8, 256) 295168
block3_conv2 (Conv2D) (None, 8, 8, 256) 590080
block3_conv3 (Conv2D) (None, 8, 8, 256) 590080
block3_pool (MaxPooling2D) (None, 4, 4, 256) 0
block4_conv1 (Conv2D) (None, 4, 4, 512) 1180160
block4_conv2 (Conv2D) (None, 4, 4, 512) 2359808
block4_conv3 (Conv2D) (None, 4, 4, 512) 2359808
block4_pool (MaxPooling2D) (None, 2, 2, 512) 0
block5_conv1 (Conv2D) (None, 2, 2, 512) 2359808
block5_conv2 (Conv2D) (None, 2, 2, 512) 2359808
block5_conv3 (Conv2D) (None, 2, 2, 512) 2359808
block5_pool (MaxPooling2D) (None, 1, 1, 512) 0
=================================================================
Total params: 14,714,688
Trainable params: 14,714,688
Non-trainable params: 0
_________________________________________________________________# 일부만 동결 나머지는 학습 x
for layer in vgg16.layers[:-4]:
#뒤에 4개만 빼고, 뒤에 4개(block5_conv1 (Conv2D),block5_conv2 (Conv2D),block5_conv3 (Conv2D),block5_pool (MaxPooling2D))는 학습 같이 됨
layer.trainable = False
#Non-trainable params은 fit해도 바뀌지 않음
#동결시키면 weight 변화xvgg16.summary()Model: "vgg16"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 32, 32, 3)] 0
block1_conv1 (Conv2D) (None, 32, 32, 64) 1792
block1_conv2 (Conv2D) (None, 32, 32, 64) 36928
block1_pool (MaxPooling2D) (None, 16, 16, 64) 0
block2_conv1 (Conv2D) (None, 16, 16, 128) 73856
block2_conv2 (Conv2D) (None, 16, 16, 128) 147584
block2_pool (MaxPooling2D) (None, 8, 8, 128) 0
block3_conv1 (Conv2D) (None, 8, 8, 256) 295168
block3_conv2 (Conv2D) (None, 8, 8, 256) 590080
block3_conv3 (Conv2D) (None, 8, 8, 256) 590080
block3_pool (MaxPooling2D) (None, 4, 4, 256) 0
block4_conv1 (Conv2D) (None, 4, 4, 512) 1180160
block4_conv2 (Conv2D) (None, 4, 4, 512) 2359808
block4_conv3 (Conv2D) (None, 4, 4, 512) 2359808
block4_pool (MaxPooling2D) (None, 2, 2, 512) 0
block5_conv1 (Conv2D) (None, 2, 2, 512) 2359808
block5_conv2 (Conv2D) (None, 2, 2, 512) 2359808
block5_conv3 (Conv2D) (None, 2, 2, 512) 2359808
block5_pool (MaxPooling2D) (None, 1, 1, 512) 0
=================================================================
Total params: 14,714,688
Trainable params: 7,079,424
Non-trainable params: 7,635,264
_________________________________________________________________model = Sequential([
vgg16,
Flatten(),
Dense(256),
BatchNormalization(), #BatchNormalization 하면
Activation('relu'),
Dense(10,activation='softmax')
])
model.compile(optimizer=Adam(1e-4),loss='sparse_categorical_crossentropy',metrics=['acc'])
def get_step(train_len,batch_size):
if(train_len % batch_size > 0):
return train_len // batch_size +1
else:
return train_len // batch_size
#fit
history = model.fit(train_generator,
epochs=30,
steps_per_epoch=get_step(len(x_train),batch_size),
validation_data=val_generator,
validation_steps=get_step(len(x_val),batch_size))Epoch 1/30
1094/1094 [==============================] - 44s 32ms/step - loss: 1.1230 - acc: 0.1014 - val_loss: 0.9420 - val_acc: 0.0969
Epoch 2/30
1094/1094 [==============================] - 34s 31ms/step - loss: 0.9244 - acc: 0.1036 - val_loss: 0.8633 - val_acc: 0.0638
Epoch 3/30
1094/1094 [==============================] - 35s 32ms/step - loss: 0.8526 - acc: 0.1036 - val_loss: 0.8123 - val_acc: 0.0887
Epoch 4/30
1094/1094 [==============================] - 33s 30ms/step - loss: 0.8116 - acc: 0.1026 - val_loss: 0.7372 - val_acc: 0.0947
Epoch 5/30
1094/1094 [==============================] - 33s 30ms/step - loss: 0.7678 - acc: 0.1034 - val_loss: 0.8402 - val_acc: 0.1045
Epoch 6/30
1094/1094 [==============================] - 32s 29ms/step - loss: 0.7402 - acc: 0.1029 - val_loss: 0.7179 - val_acc: 0.0956
Epoch 7/30
1094/1094 [==============================] - 32s 29ms/step - loss: 0.7081 - acc: 0.1044 - val_loss: 0.7519 - val_acc: 0.0882
Epoch 8/30
1094/1094 [==============================] - 32s 29ms/step - loss: 0.6694 - acc: 0.1019 - val_loss: 0.6851 - val_acc: 0.1156
Epoch 9/30
1094/1094 [==============================] - 32s 29ms/step - loss: 0.6534 - acc: 0.1025 - val_loss: 0.6701 - val_acc: 0.0852
Epoch 10/30
1094/1094 [==============================] - 32s 29ms/step - loss: 0.6275 - acc: 0.1032 - val_loss: 0.6628 - val_acc: 0.0866
Epoch 11/30
1094/1094 [==============================] - 32s 29ms/step - loss: 0.6068 - acc: 0.1030 - val_loss: 0.6583 - val_acc: 0.0855
Epoch 12/30
1094/1094 [==============================] - 32s 29ms/step - loss: 0.5797 - acc: 0.1022 - val_loss: 0.6602 - val_acc: 0.0941
Epoch 13/30
1094/1094 [==============================] - 31s 29ms/step - loss: 0.5586 - acc: 0.1015 - val_loss: 0.6777 - val_acc: 0.0926
Epoch 14/30
1094/1094 [==============================] - 31s 29ms/step - loss: 0.5392 - acc: 0.1027 - val_loss: 0.7254 - val_acc: 0.0967
Epoch 15/30
1094/1094 [==============================] - 32s 29ms/step - loss: 0.5231 - acc: 0.1020 - val_loss: 0.6975 - val_acc: 0.0926
Epoch 16/30
1094/1094 [==============================] - 32s 29ms/step - loss: 0.5092 - acc: 0.1023 - val_loss: 0.6612 - val_acc: 0.0893
Epoch 17/30
1094/1094 [==============================] - 31s 29ms/step - loss: 0.4974 - acc: 0.1015 - val_loss: 0.7115 - val_acc: 0.0911
Epoch 18/30
1094/1094 [==============================] - 31s 29ms/step - loss: 0.4738 - acc: 0.1029 - val_loss: 0.7025 - val_acc: 0.0764
Epoch 19/30
1094/1094 [==============================] - 32s 29ms/step - loss: 0.4615 - acc: 0.1029 - val_loss: 0.6699 - val_acc: 0.0939
Epoch 20/30
1094/1094 [==============================] - 32s 29ms/step - loss: 0.4400 - acc: 0.1017 - val_loss: 0.6527 - val_acc: 0.0904
Epoch 21/30
1094/1094 [==============================] - 31s 28ms/step - loss: 0.4250 - acc: 0.1016 - val_loss: 0.6488 - val_acc: 0.0914
Epoch 22/30
1094/1094 [==============================] - 32s 29ms/step - loss: 0.4102 - acc: 0.1019 - val_loss: 0.7199 - val_acc: 0.1028
Epoch 23/30
1094/1094 [==============================] - 31s 28ms/step - loss: 0.4022 - acc: 0.1012 - val_loss: 0.6527 - val_acc: 0.1087
Epoch 24/30
1094/1094 [==============================] - 31s 28ms/step - loss: 0.3870 - acc: 0.1021 - val_loss: 0.6803 - val_acc: 0.0948
Epoch 25/30
1094/1094 [==============================] - 31s 28ms/step - loss: 0.3718 - acc: 0.1027 - val_loss: 0.6907 - val_acc: 0.0907
Epoch 26/30
1094/1094 [==============================] - 32s 29ms/step - loss: 0.3612 - acc: 0.1021 - val_loss: 0.6954 - val_acc: 0.0920
Epoch 27/30
1094/1094 [==============================] - 32s 30ms/step - loss: 0.3480 - acc: 0.1016 - val_loss: 0.7366 - val_acc: 0.1009
Epoch 28/30
1094/1094 [==============================] - 34s 31ms/step - loss: 0.3411 - acc: 0.1015 - val_loss: 0.7433 - val_acc: 0.0937
Epoch 29/30
1094/1094 [==============================] - 32s 29ms/step - loss: 0.3208 - acc: 0.1023 - val_loss: 0.7718 - val_acc: 0.0866
Epoch 30/30
1094/1094 [==============================] - 32s 29ms/step - loss: 0.3159 - acc: 0.1021 - val_loss: 0.7293 - val_acc: 0.0925
test_datagen = ImageDataGenerator()
test_generator = test_datagen.flow(x_test,
batch_size = batch_size)
pred = model.predict(x_test)
np.argmax(np.round(pred[0],2))313/313 [==============================] - 4s 11ms/step
3from keras.datasets.mnist import load_data
import numpy as np(x_train, y_train), (x_test, y_test) = load_data()Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/mnist.npz
11490434/11490434 [==============================] - 0s 0us/stepmnist
0~9숫자, 짝수, 홀수 구분
# 홀수여부(홀수:1,짝수:0)
y_train_odd = []
for y in y_train:
if y % 2 == 0:
y_train_odd.append(0)
else:
y_train_odd.append(1)
y_train_odd = np.array(y_train_odd)
y_train_odd.shape(60000,)print(y_train[:10])
print(y_train_odd[:10])[5 0 4 1 9 2 1 3 1 4]
[1 0 0 1 1 0 1 1 1 0]y_test_odd = []
for y in y_test:
if y % 2 == 0:
y_test_odd.append(0)
else:
y_test_odd.append(1)
y_test_odd = np.array(y_test_odd)
y_test_odd.shape(10000,)x_train.min(),x_train.max()(0, 255)x_train = x_train/255.
x_test = x_test/255.x_train.min(),x_train.max()(0.0, 1.0)x_train.shape(60000, 28, 28)함수형 API
Sequential 클래스는 층을 차례대로 쌓은 모델을 만든다. 딥러닝에서는 복잡한 모델이 많이 있다. 예를 들어 입력이 2개일 수도 있고 출력이 2개일 수 있다. 이런 경우에는 Sequential 클래스 대신 함수형 API(functional API)을 사용한다.
함수형 API는 케라스의 Model 클래스를 사용하여 모델을 만든다.
컨볼루션 layer
채널값이 3
기본적으로 3차원이 되어야 한다.
데이터가 여러 건이라서 4차원이어야 한다.
x_train.shape
(60000, 28, 28)
-> 차원 하나 추가해야 한다. -> reshape, np.expand_dims
x_train_in = np.expand_dims(x_train,-1) #-1 : 맨 뒤에 추가하겠다
x_test_in = np.expand_dims(x_test,-1)
x_train_in.shape,x_test_in.shape((60000, 28, 28, 1), (10000, 28, 28, 1))from keras.models import Model
from keras.layers import Input,Conv2D,MaxPool2D,Flatten,Dense,Concatenate #Concatenate 분기했다가 합칠 때 사용 # 입력 1개, 출력 2개. 나갈 때는 1
# functional api로 만들 때
inputs = Input(shape=(28, 28, 1))
#입력받은 layer층
conv = Conv2D(32, (3,3), activation='relu')(inputs)#필터의 갯수(32), 커널 사이즈((3,3)), (inputs)을 받는다
pool = MaxPool2D((2,2))(conv) #기본값 (2,2), (conv)을 받는다
flat = Flatten()(pool)
flat_inputs = Flatten()(inputs)
concat =Concatenate()([flat,flat_inputs])
outputs = Dense(10, activation='softmax')(concat)
model = Model(inputs=inputs, outputs=outputs)
model.summary()Model: "model"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) [(None, 28, 28, 1)] 0 []
conv2d (Conv2D) (None, 26, 26, 32) 320 ['input_1[0][0]']
max_pooling2d (MaxPooling2D) (None, 13, 13, 32) 0 ['conv2d[0][0]']
flatten (Flatten) (None, 5408) 0 ['max_pooling2d[0][0]']
flatten_1 (Flatten) (None, 784) 0 ['input_1[0][0]']
concatenate (Concatenate) (None, 6192) 0 ['flatten[0][0]',
'flatten_1[0][0]']
dense (Dense) (None, 10) 61930 ['concatenate[0][0]']
==================================================================================================
Total params: 62,250
Trainable params: 62,250
Non-trainable params: 0
__________________________________________________________________________________________________from keras.utils import plot_model#순차적으로 쌓는 구조(Sequencial)가 아닌 분기했다가 합치는 형태
plot_model(model, show_shapes=True,show_layer_names=True)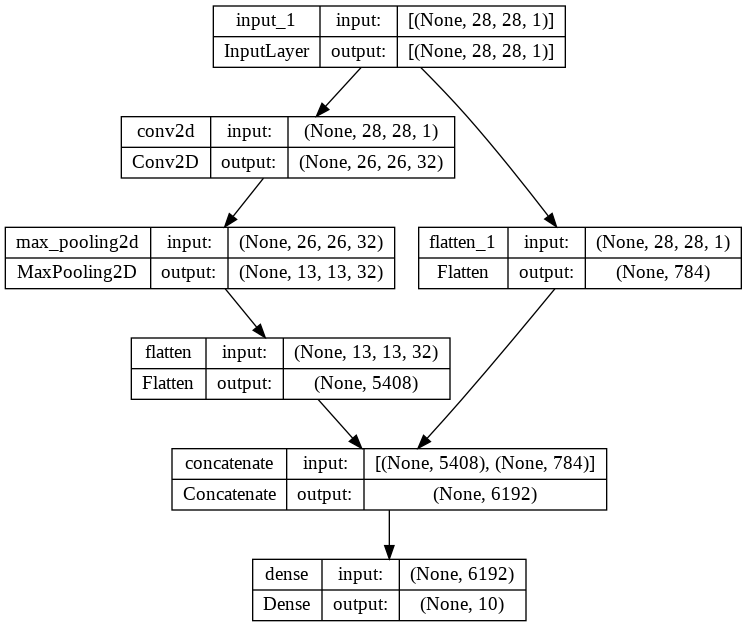
모델 만드는 방법 3가지
- Sequencial
- functional api
- class
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
history = model.fit(x_train_in,
y_train,
validation_data=(x_test_in,y_test),
epochs=10)
model.evaluate(x_test_in,y_test)Epoch 1/10
1875/1875 [==============================] - 35s 18ms/step - loss: 0.0187 - accuracy: 0.9939 - val_loss: 0.0671 - val_accuracy: 0.9816
Epoch 2/10
1875/1875 [==============================] - 33s 18ms/step - loss: 0.0146 - accuracy: 0.9955 - val_loss: 0.0637 - val_accuracy: 0.9839
Epoch 3/10
1875/1875 [==============================] - 38s 20ms/step - loss: 0.0121 - accuracy: 0.9961 - val_loss: 0.0665 - val_accuracy: 0.9814
Epoch 4/10
1875/1875 [==============================] - 39s 21ms/step - loss: 0.0110 - accuracy: 0.9965 - val_loss: 0.0717 - val_accuracy: 0.9829
Epoch 5/10
1875/1875 [==============================] - 42s 22ms/step - loss: 0.0093 - accuracy: 0.9970 - val_loss: 0.0700 - val_accuracy: 0.9843
Epoch 6/10
1875/1875 [==============================] - 43s 23ms/step - loss: 0.0088 - accuracy: 0.9972 - val_loss: 0.0695 - val_accuracy: 0.9836
Epoch 7/10
1875/1875 [==============================] - 39s 21ms/step - loss: 0.0071 - accuracy: 0.9979 - val_loss: 0.0759 - val_accuracy: 0.9839
Epoch 8/10
1875/1875 [==============================] - 41s 22ms/step - loss: 0.0073 - accuracy: 0.9976 - val_loss: 0.0716 - val_accuracy: 0.9837
Epoch 9/10
1875/1875 [==============================] - 42s 22ms/step - loss: 0.0051 - accuracy: 0.9985 - val_loss: 0.0766 - val_accuracy: 0.9833
Epoch 10/10
1875/1875 [==============================] - 43s 23ms/step - loss: 0.0046 - accuracy: 0.9987 - val_loss: 0.0765 - val_accuracy: 0.9841
313/313 [==============================] - 2s 7ms/step - loss: 0.0765 - accuracy: 0.9841
[0.0765172615647316, 0.9840999841690063]loss: 0.08077141642570496 acc: 0.9835000038146973
inputs = Input(shape=(28, 28, 1),name='inputs')
#입력받은 layer층
#입력 1개, 출력 2개
conv = Conv2D(32,(3,3),activation='relu',name='conv2d')(inputs)#필터의 갯수(32), 커널 사이즈((3,3)), (inputs)을 받는다
pool = MaxPool2D((2,2),name='maxpool')(conv)#기본값 (2,2), (conv)을 받는다
flat = Flatten(name='flatten')(pool)
flat_inputs = Flatten()(inputs)
concat = Concatenate()([flat,flat_inputs])#name 지정 안 하면 임의로 지정해줌
digit_outputs = Dense(10,activation='softmax',name='digit_output')(concat)
odd_outputs = Dense(1,activation='sigmoid',name='odd_output')(flat_inputs)
model = Model(inputs=inputs,outputs=[digit_outputs,odd_outputs])
model.summary()Model: "model_2"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
inputs (InputLayer) [(None, 28, 28, 1)] 0 []
conv2d (Conv2D) (None, 26, 26, 32) 320 ['inputs[0][0]']
maxpool (MaxPooling2D) (None, 13, 13, 32) 0 ['conv2d[0][0]']
flatten (Flatten) (None, 5408) 0 ['maxpool[0][0]']
flatten_3 (Flatten) (None, 784) 0 ['inputs[0][0]']
concatenate_2 (Concatenate) (None, 6192) 0 ['flatten[0][0]',
'flatten_3[0][0]']
digit_output (Dense) (None, 10) 61930 ['concatenate_2[0][0]']
odd_output (Dense) (None, 1) 785 ['flatten_3[0][0]']
==================================================================================================
Total params: 63,035
Trainable params: 63,035
Non-trainable params: 0
__________________________________________________________________________________________________plot_model(model, show_shapes=True,show_layer_names=True)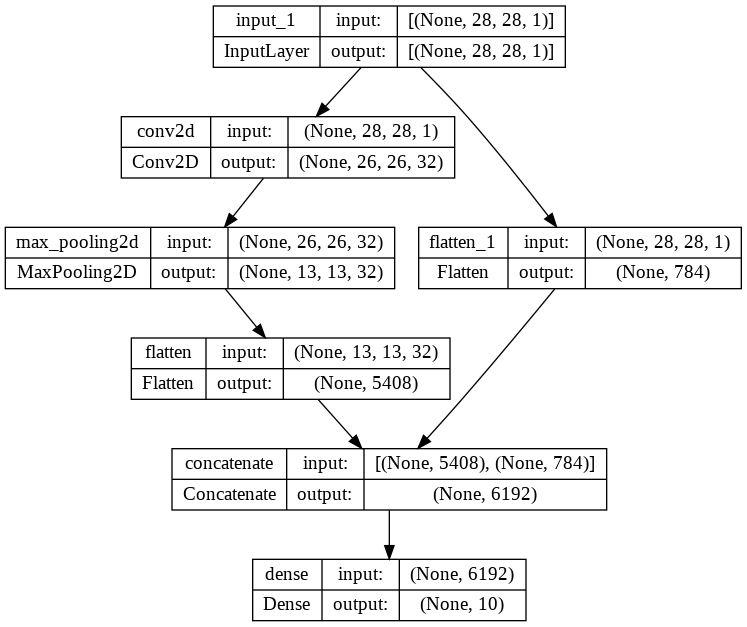
print(model.input)KerasTensor(type_spec=TensorSpec(shape=(None, 28, 28, 1), dtype=tf.float32, name='input_1'), name='input_1', description="created by layer 'input_1'")print(model.output)KerasTensor(type_spec=TensorSpec(shape=(None, 10), dtype=tf.float32, name=None), name='dense/Softmax:0', description="created by layer 'dense'")# loss값을 딕셔너리 형태로 만들어야 한다.
model.compile(optimizer='adam',
loss={'digit_output':'sparse_categorical_crossentropy',
'odd_output':'binary_crossentropy'},
loss_weights={'digit_output':1,
'odd_output':0.5},
metrics=['accuracy'])
history = model.fit({'inputs':x_train_in},
{'digit_output':y_train,'odd_output':y_train_odd},
validation_data=({'inputs':x_test_in}, {'digit_output':y_test,'odd_output':y_test_odd}),
epochs=10)Epoch 1/10
1875/1875 [==============================] - 34s 18ms/step - loss: 0.3728 - digit_output_loss: 0.2103 - odd_output_loss: 0.3251 - digit_output_accuracy: 0.9407 - odd_output_accuracy: 0.8646 - val_loss: 0.2204 - val_digit_output_loss: 0.0803 - val_odd_output_loss: 0.2801 - val_digit_output_accuracy: 0.9760 - val_odd_output_accuracy: 0.8901
Epoch 2/10
1875/1875 [==============================] - 34s 18ms/step - loss: 0.2125 - digit_output_loss: 0.0767 - odd_output_loss: 0.2717 - digit_output_accuracy: 0.9775 - odd_output_accuracy: 0.8907 - val_loss: 0.1991 - val_digit_output_loss: 0.0672 - val_odd_output_loss: 0.2637 - val_digit_output_accuracy: 0.9785 - val_odd_output_accuracy: 0.8960
Epoch 3/10
1875/1875 [==============================] - 40s 21ms/step - loss: 0.1893 - digit_output_loss: 0.0580 - odd_output_loss: 0.2627 - digit_output_accuracy: 0.9826 - odd_output_accuracy: 0.8960 - val_loss: 0.1999 - val_digit_output_loss: 0.0704 - val_odd_output_loss: 0.2591 - val_digit_output_accuracy: 0.9782 - val_odd_output_accuracy: 0.9012
Epoch 4/10
1875/1875 [==============================] - 38s 20ms/step - loss: 0.1776 - digit_output_loss: 0.0480 - odd_output_loss: 0.2591 - digit_output_accuracy: 0.9855 - odd_output_accuracy: 0.8981 - val_loss: 0.1838 - val_digit_output_loss: 0.0542 - val_odd_output_loss: 0.2591 - val_digit_output_accuracy: 0.9830 - val_odd_output_accuracy: 0.9002
Epoch 5/10
1875/1875 [==============================] - 40s 22ms/step - loss: 0.1691 - digit_output_loss: 0.0405 - odd_output_loss: 0.2572 - digit_output_accuracy: 0.9873 - odd_output_accuracy: 0.8992 - val_loss: 0.1845 - val_digit_output_loss: 0.0557 - val_odd_output_loss: 0.2577 - val_digit_output_accuracy: 0.9816 - val_odd_output_accuracy: 0.8992
Epoch 6/10
1875/1875 [==============================] - 46s 25ms/step - loss: 0.1614 - digit_output_loss: 0.0335 - odd_output_loss: 0.2557 - digit_output_accuracy: 0.9897 - odd_output_accuracy: 0.8988 - val_loss: 0.1781 - val_digit_output_loss: 0.0499 - val_odd_output_loss: 0.2565 - val_digit_output_accuracy: 0.9844 - val_odd_output_accuracy: 0.9020
Epoch 7/10
1875/1875 [==============================] - 43s 23ms/step - loss: 0.1568 - digit_output_loss: 0.0294 - odd_output_loss: 0.2549 - digit_output_accuracy: 0.9904 - odd_output_accuracy: 0.9003 - val_loss: 0.1832 - val_digit_output_loss: 0.0550 - val_odd_output_loss: 0.2564 - val_digit_output_accuracy: 0.9840 - val_odd_output_accuracy: 0.9017
Epoch 8/10
1875/1875 [==============================] - 35s 18ms/step - loss: 0.1514 - digit_output_loss: 0.0244 - odd_output_loss: 0.2540 - digit_output_accuracy: 0.9923 - odd_output_accuracy: 0.9002 - val_loss: 0.1798 - val_digit_output_loss: 0.0520 - val_odd_output_loss: 0.2555 - val_digit_output_accuracy: 0.9840 - val_odd_output_accuracy: 0.9017
Epoch 9/10
1875/1875 [==============================] - 33s 17ms/step - loss: 0.1482 - digit_output_loss: 0.0214 - odd_output_loss: 0.2536 - digit_output_accuracy: 0.9930 - odd_output_accuracy: 0.9006 - val_loss: 0.1838 - val_digit_output_loss: 0.0565 - val_odd_output_loss: 0.2546 - val_digit_output_accuracy: 0.9835 - val_odd_output_accuracy: 0.9006
Epoch 10/10
1875/1875 [==============================] - 33s 18ms/step - loss: 0.1440 - digit_output_loss: 0.0174 - odd_output_loss: 0.2533 - digit_output_accuracy: 0.9947 - odd_output_accuracy: 0.9017 - val_loss: 0.1860 - val_digit_output_loss: 0.0579 - val_odd_output_loss: 0.2563 - val_digit_output_accuracy: 0.9836 - val_odd_output_accuracy: 0.9036model.evaluate({'inputs':x_test_in}, {'digit_output':y_test,'odd_output':y_test_odd})313/313 [==============================] - 3s 8ms/step - loss: 0.1860 - digit_output_loss: 0.0579 - odd_output_loss: 0.2563 - digit_output_accuracy: 0.9836 - odd_output_accuracy: 0.9036
[0.1860315054655075,
0.05788664519786835,
0.2562895715236664,
0.9836000204086304,
0.9035999774932861]digit,odd = model.predict(x_test_in)313/313 [==============================] - 4s 12ms/stepnp.argmax(np.round(digit[0],2))7(odd[0] > 0.5).astype(int)array([1])import matplotlib.pyplot as plt
plt.imshow(x_test[0],cmap='gray')<matplotlib.image.AxesImage at 0x7f6654d4e2e0>
plot_model(model,show_shapes=True,show_layer_names=True)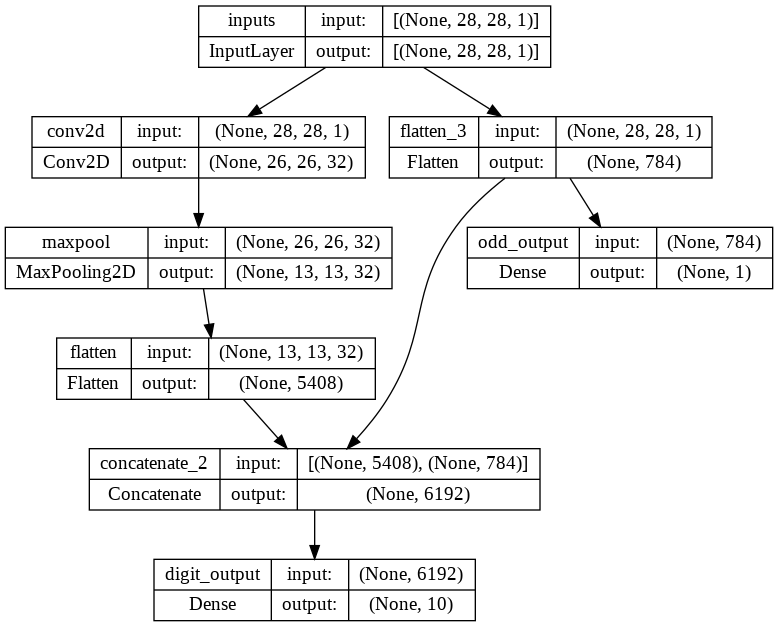
base_model_output = model.get_layer('flatten').outputbase_model = Model(inputs=model.input,outputs=base_model_output,name='base')
plot_model(base_model,show_shapes=True,show_layer_names=True)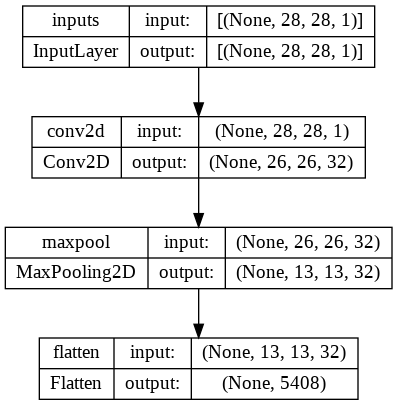
from keras import Sequential
digit_model = Sequential([
base_model,
Dense(10,activation='softmax')
])
plot_model(digit_model,show_shapes=True,show_layer_names=True)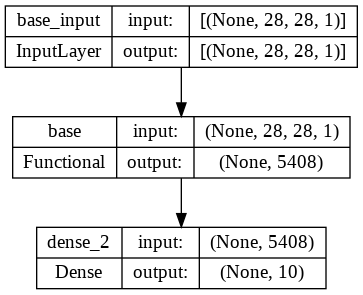
digit_model.summary()Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
base (Functional) (None, 5408) 320
dense_2 (Dense) (None, 10) 54090
=================================================================
Total params: 54,410
Trainable params: 54,410
Non-trainable params: 0
_________________________________________________________________digit_model.compile(optimizer='adam',loss='sparse_categorical_crossentropy',metrics=['acc']) #분류기 2개 중 1개만 보기
history = digit_model.fit(x_train_in,y_train,
validation_data=(x_test_in,y_test),
epochs=5)Epoch 1/5
1875/1875 [==============================] - 36s 19ms/step - loss: 0.1286 - acc: 0.9642 - val_loss: 0.0795 - val_acc: 0.9738
Epoch 2/5
1875/1875 [==============================] - 34s 18ms/step - loss: 0.0590 - acc: 0.9821 - val_loss: 0.0541 - val_acc: 0.9808
Epoch 3/5
1875/1875 [==============================] - 37s 20ms/step - loss: 0.0436 - acc: 0.9865 - val_loss: 0.0553 - val_acc: 0.9817
Epoch 4/5
1875/1875 [==============================] - 42s 22ms/step - loss: 0.0359 - acc: 0.9884 - val_loss: 0.0502 - val_acc: 0.9838
Epoch 5/5
1875/1875 [==============================] - 35s 19ms/step - loss: 0.0299 - acc: 0.9905 - val_loss: 0.0509 - val_acc: 0.9848처음하는 보다는 나중에 돌린 모델이 가중치가 학습이 된 형태라서 더 정확도가 좋다.
-처음 모델
val_acc:0.8705
-나중 모델
val_acc:0.9738
뒤에 모델이 더 정확함
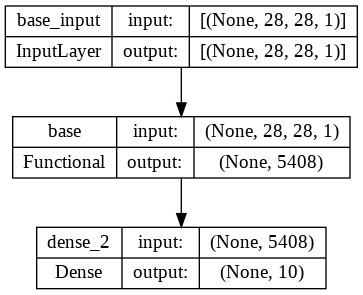
base_model_frozen = Model(inputs=model.input,outputs=base_model_output,name='base')
base_model_frozen.trainable=False
base_model_frozen.summary()
plot_model(digit_model,show_shapes=True,show_layer_names=True)Model: "base"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
inputs (InputLayer) [(None, 28, 28, 1)] 0
conv2d (Conv2D) (None, 26, 26, 32) 320
maxpool (MaxPooling2D) (None, 13, 13, 32) 0
flatten (Flatten) (None, 5408) 0
=================================================================
Total params: 320
Trainable params: 0
Non-trainable params: 320
_________________________________________________________________
함수 api로 만들어야 layer 사이도 볼 수 있다.
inputs (InputLayer) [(None, 28, 28, 1)] 0
conv2d (Conv2D) (None, 26, 26, 32) 320
maxpool (MaxPooling2D) (None, 13, 13, 32) 0
flatten (Flatten) (None, 5408) 0
그냥 만들면 base로만 보인다.
base (Functional) (None, 5408) 320
dense_2 (Dense) (None, 10) 54090
특정 layer만 동결
base_model_frozen.trainable=False
base모델에 가중치값 고정시킴
#분류기 추가
dense_output = Dense(10,activation='softmax')(base_model_frozen.output) #함수 api라서 무엇을 받을거냐를 적어줘야 함 :(base_model_frozen)
#(base_model_frozen.output) : (base_model_frozen)이랑 output이랑 연결해라
#모델 만들기
digit_model_frozen = Model(inputs=base_model_frozen.input,outputs=dense_output)
digit_model_frozen.summary()
Model: "model_4"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
inputs (InputLayer) [(None, 28, 28, 1)] 0
conv2d (Conv2D) (None, 26, 26, 32) 320
maxpool (MaxPooling2D) (None, 13, 13, 32) 0
flatten (Flatten) (None, 5408) 0
dense_4 (Dense) (None, 10) 54090
=================================================================
Total params: 54,410
Trainable params: 54,090
Non-trainable params: 320
_________________________________________________________________#weight값에 새로 부여
digit_model_frozen.compile(optimizer='adam',loss='sparse_categorical_crossentropy',metrics=['acc']) #분류기 2개 중 1개만 보기
history = digit_model_frozen.fit(x_train_in,y_train,
validation_data=(x_test_in,y_test),
epochs=10)Epoch 1/10
1875/1875 [==============================] - 18s 9ms/step - loss: 0.1191 - acc: 0.9680 - val_loss: 0.0608 - val_acc: 0.9801
Epoch 2/10
1875/1875 [==============================] - 17s 9ms/step - loss: 0.0509 - acc: 0.9846 - val_loss: 0.0483 - val_acc: 0.9841
Epoch 3/10
1875/1875 [==============================] - 17s 9ms/step - loss: 0.0385 - acc: 0.9882 - val_loss: 0.0480 - val_acc: 0.9832
Epoch 4/10
1875/1875 [==============================] - 17s 9ms/step - loss: 0.0300 - acc: 0.9908 - val_loss: 0.0509 - val_acc: 0.9841
Epoch 5/10
1875/1875 [==============================] - 17s 9ms/step - loss: 0.0245 - acc: 0.9927 - val_loss: 0.0499 - val_acc: 0.9841
Epoch 6/10
1875/1875 [==============================] - 17s 9ms/step - loss: 0.0204 - acc: 0.9938 - val_loss: 0.0562 - val_acc: 0.9837
Epoch 7/10
1875/1875 [==============================] - 22s 12ms/step - loss: 0.0166 - acc: 0.9952 - val_loss: 0.0579 - val_acc: 0.9829
Epoch 8/10
1875/1875 [==============================] - 22s 11ms/step - loss: 0.0148 - acc: 0.9954 - val_loss: 0.0556 - val_acc: 0.9841
Epoch 9/10
1875/1875 [==============================] - 21s 11ms/step - loss: 0.0118 - acc: 0.9966 - val_loss: 0.0511 - val_acc: 0.9855
Epoch 10/10
1875/1875 [==============================] - 19s 10ms/step - loss: 0.0106 - acc: 0.9969 - val_loss: 0.0527 - val_acc: 0.9842digit_model_frozen.get_layer('conv2d').trainable = True
#false = 학습을 안 한다
#학습을 통해 가중치값을 갱신하게 된다.
#digit_model_frozen.get_layer('conv2d').trainable = True #하나만 풀기digit_model_frozen.summary()Model: "model_4"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
inputs (InputLayer) [(None, 28, 28, 1)] 0
conv2d (Conv2D) (None, 26, 26, 32) 320
maxpool (MaxPooling2D) (None, 13, 13, 32) 0
flatten (Flatten) (None, 5408) 0
dense_4 (Dense) (None, 10) 54090
=================================================================
Total params: 54,410
Trainable params: 54,410
Non-trainable params: 0
_________________________________________________________________