해당 시리즈는 LG에서 지원하는 LG Aimers의 교육 내용을 정리한 것으로, 모든 출처는 https://www.lgaimers.ai/ 입니다.
Supervised Learning의 마지막 강의를 수강하고 글을 작성한다.
이번에는 supervised learning task에서 사용하고 있거나 개발한 알고리즘의 간단한 확장으로 모델의 성능을 올릴 수 있는 간단한 방법인 Ensemble Learning을 알아본다.
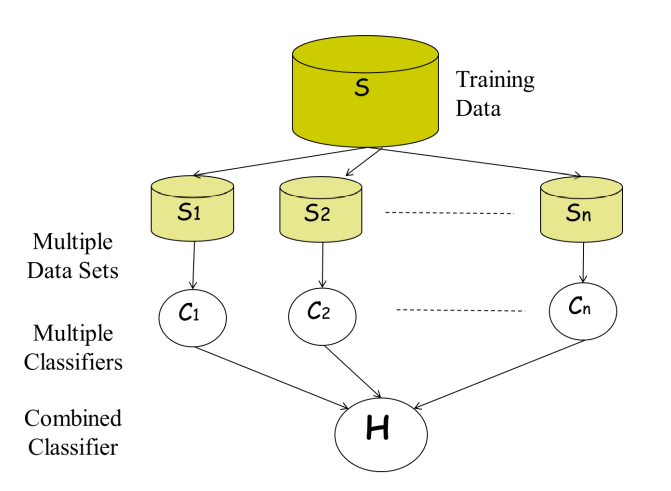
ensemble learning은 머신러닝에서 알고리즘의 종류에 상관없이 서로 다르거나 같은 메커니즘으로 동작하는 다양한 머신러닝을 묶어 함께 사용하는 방식으로, 여러 모델을 모아 예측 모델의 집합으로 사용한다. 이 때 하나의 학습 모델을 expert로 표현하며, 이를 통해 다양한 모델의 장점을 살려 예측 성능을 향상시킨다.
ensemble learning은 전체 학습 데이터셋을 랜덤하게 나누어 모델들을 학습시킨 뒤, 모델의 출력을 모아 다수결을 통해 최종 결과를 도출한다.
ensemble learning을 이용한 장점과 단점은 다음과 같다.
-
예측성능을 안정적으로 향상시킨다 : 모델 하나의 결정보다 다양한 여러 개의 모델의 결정으로 최종 예측 결과를 제공하기 때문에 기타
Noise로부터 안정적이다. -
구현이 간단하고 쉽다 : 여러 개의 모델을 학습하고, 직접적으로 연합하여 적용하기 때문에 구현이 간단하다.
-
parameter tuning이 많이 필요하지 않다 : 각 모델은 독립적으로 동작하여 모델 파라미터 튜닝이 많이 필요하지 않다. -
compact representation이 불가하다 : 다양한 모델을 혼합하여 사용하기 때문에
compact representation은 불가능하다.
Bagging과 Boosting은 앙상블을 구성하는 가장 기본적인 요소 기술이다.
bagging: 학습과정에서 학습 데이터 샘플을 랜덤하게 나누어 학습하고, 병렬적으로 학습하여 각 샘플이 다른 모델에 영향이 가지 않는다.
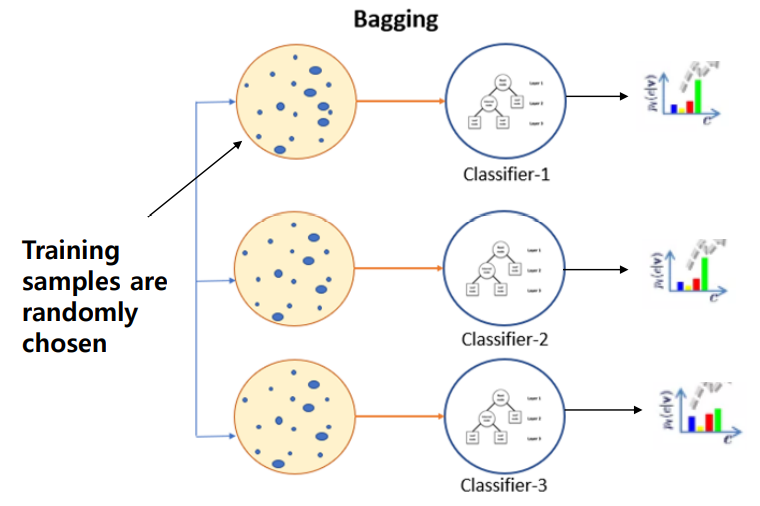
초기 데이터셋을 n개로 구분하고, classifier가 랜덤하게 학습하여 서로 다른 특성에 대해 학습한다.
bagging은 bootstrapping과 aggregating의 합으로 이루어지는데, lower variance의 안정적인 성능을 제공하는 데 유용하며 학습 데이터 샘플의 수가 적거나 모델이 복잡한 경우에 발생하는 overfitting 문제에 대해 샘플을 랜덤하게 선택하는 과정에서 data augmentation 효과를 가질 수 있고 간단한 모델을 집합적으로 사용할 수 있어 보다 더 안정적인 성능 제공이 가능하다.
bootstrapping은 다수의 샘플 데이터셋을 생성해서 학습하는 방식으로, 같은 모델을 사용한다면 모델 파라미터가 서로 달라져야 하기 때문에 샘플을 랜덤하게 선택하게끔 한다. 하지만, 서로 다른 모델인 경우, 어차피 서로 다른 형태로 동작하기에 같은 샘플을 이용할 수 있게 한다.
이러한 과정을 m번 반복하여 m개의 데이터셋을 사용하는 효과가 있도록 하고, 이를 통해 noise의 영향을 최소화한다.
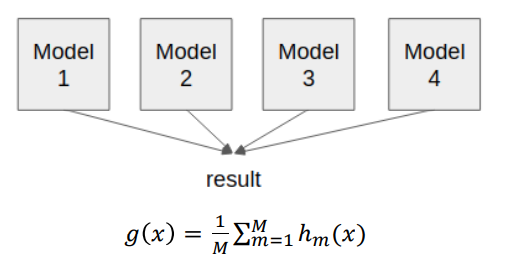
aggregating은 m개의 모델을 학습이 완료된 경우에 각 결정들을 합해 최종 결론을 도출한다.
boosting은 sequntial하기 동작하도록 하는 기법으로, 연속적으로 classifier의 결과를 적용할 경우 이전에 동작한 classifier들의 결과를 현재 classifier의 결과 향상에 사용가능하다는 아이디어를 가진다.
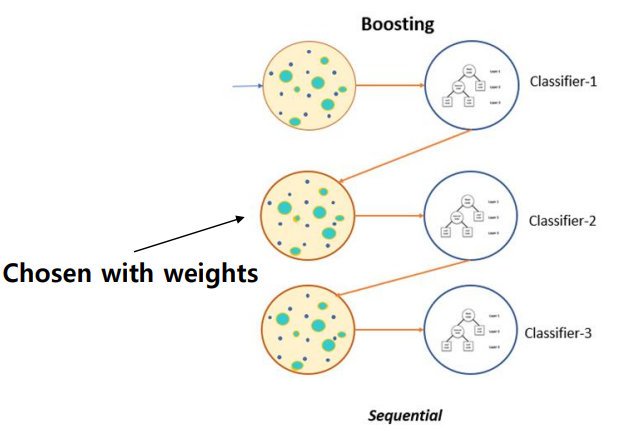
즉, 이전 classifier를 통해 예측을 수행하여 나온 결과를 다음 classifier 학습 과정에 사용하여 예측에 있어 어떤 샘플이 중요하고 어떤 샘플이 중요하지 않은지에 대한 정보를 알 수 있도록 한다.
이는 weak classifier라고 하는 bias가 높은 classifier를 이용한 기법인데, strong classifier에 비해 성능이 낮아 혼자서 높은 성능을 제공하지 못하는 classifier를 뜻한다.
하지만, weak classifer에 cascading을 적용해 연속적으로 수행할 경우 sequential한 특성을 학습하게 되고, 이를 통해 예측 성능을 더욱 향상시킬 수 있다.
위와 같은 boosting을 사용할 경우 구현이 간단하고, 특정 학습 알고리즘에 구애받지 않는 장점이 있다.
Adaboost
Adaboost는 대표적인 boosting 알고리즘의 일종으로, base classifier에 의해 오분류된 샘플에 대해 보다 높은 가중치를 두어 다음 학습에 사용할 수 있게 한다.
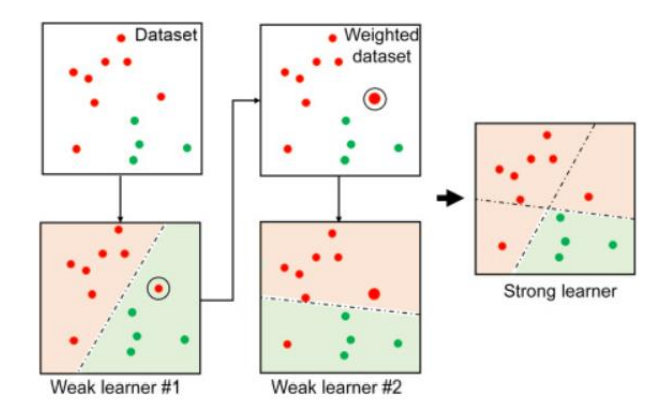
위 그림과 같이 m개의 sequential base classifier가 있다고 가정했을 때, 첫 classifier의 결과에서 특정 데이터 샘플에 w를 적용하여 다음 classifier는 해당 w를 통해 어려운 error를 해결하는 데 더 특화된 모델로써 동작할 수 있다.
이와 같은 re-classify 과정을 통해 우수한 결과를 도출할 수 있다.
bagging과 boosting을 사용한 기법들
-
random forest:Dicision Tree의 집합으로, 서로 다르게 학습된Dicision Tree의 결정으로 예측을 수행하기 때문에 자체적으로bagging을 통해 학습한다고 할 수 있다. 또한, 매 노드에서 결정이 이루어지기 때문에 자체적으로weak classification의sequential한boosting을 수행한다고 할 수 있다. -
gradient boosting machine (GBM):Generalized Adaboost by boosting
Performance Evaluation
supervised learning에서 모델의 성능은 정확도 측정을 통해 보인다.
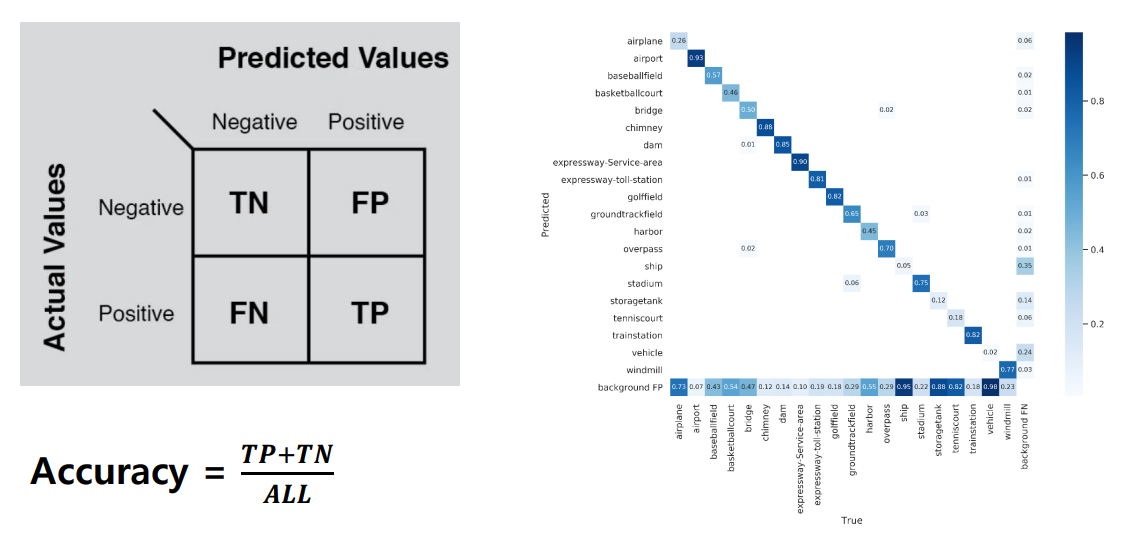
왼쪽 그림은 모델이 예측한 결과 (True/False)와 실제 데이터의 정답 (Positive/Negative)의 쌍을 나타낸 그림이며 오른쪽 그림은 각 경우에 대해 어느정도의 오차가 있었는지 표현하는 confusion matrix다.
-
True Positive(TP): 실제 True인 정답을 True라고 예측 (정답) -
False Positive(FP): 실제 False인 정답을 True라고 예측 (오답) -
False Negative(FN): 실제 True인 정답을 False라고 예측 (오답) -
True Negative(TN): 실제 False인 정답을 False라고 예측 (정답) -
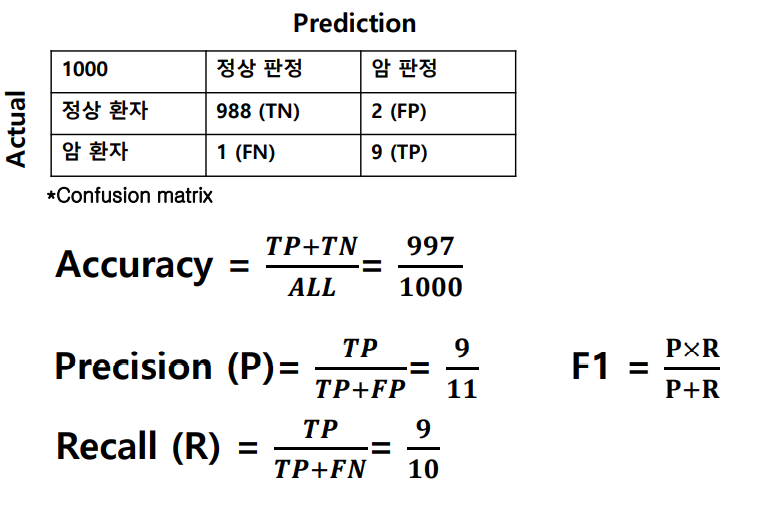
Precision: 실제 암 환자 / 전체 암 판정
: 정밀도를 나타내는 지표로, 모델이 참이라고 분류한 것 중 실제 참인 것의 비율 -
Recall: 실제 암 환자 / 전체 암 환자
: 재현율을 나타내는 지표로, 실제 참인 것 중 모델이 참이라고 분류한 것의 비율
unbalanced 데이터셋의 경우 accuracy 외에도, precision과 recall 값을 동시에 보아야 모델 성능을 제대로 측정할 수 있다.
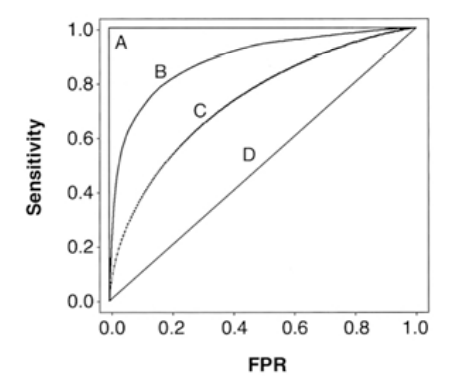
ROC Curve
roc curve는 서로 다른 classifier의 성능을 측정하는 데 사용하는 curve다.
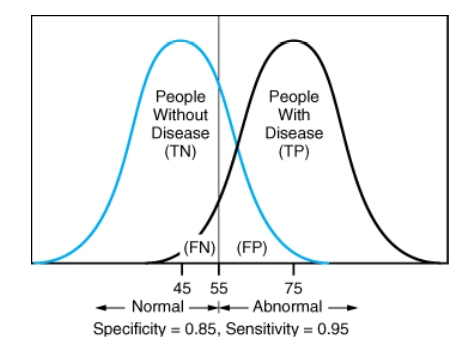
FPR은 1-TPR로 나타내며, 그래프에서 왼쪽 상단으로 갈수록 좋은 성능을 보인다.
Error measure
error measuer은 각 데이터에 따라 recall이나 prediction 값을 잘 고려해야 한다.
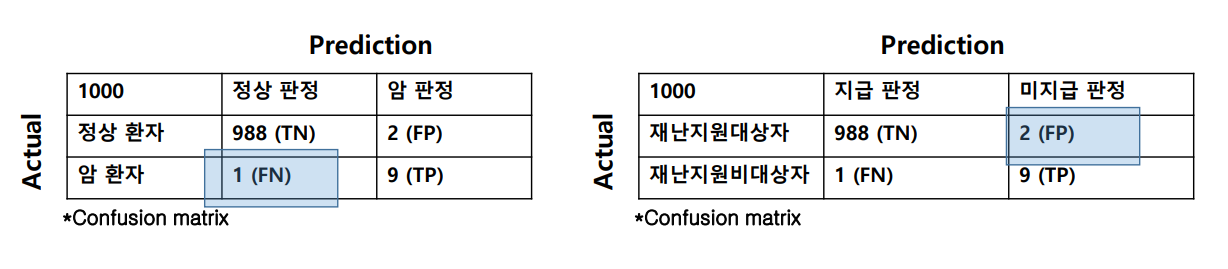
예를 들어, 위의 그림에서 왼쪽 confusion matrix같은 경우 암환자를 정상으로 판별하면 큰일나기 때문에, Recall 값이 높아야 하며, 오른쪽 그림의 경우 미지급 판정을 받은 사람이 적어야 하기에 Precision 값이 높아야 한다.
