해당 시리즈는 LG에서 지원하는 LG Aimers의 교육 내용을 정리한 것으로, 모든 출처는 https://www.lgaimers.ai/ 입니다.
어제부로, supervised learning 내용을 다 듣고, 오늘부터 unsupervised learning에 대해 알아본다.
unsupervised learning은 supervised learning과 달리 인간의 개입이 최소화된 인공지능 학습 방법으로 알고있었지만, 사실 인간이 개입되는 부분도 많다는 것을 알 수 있었다.
이런 unsupervised learning의 가장 대표적인 예는, 사람이 아기일 때로 아기는 걸어다니는 법, 목을 가누는 법, 무언가를 잡는 법 등 누군가 가르쳐주지 않아도, 시간이 지남에 따라 자신의 몸을 제어할 수 있으며 점점 그 정도가 증가한다.
K-means Clustering
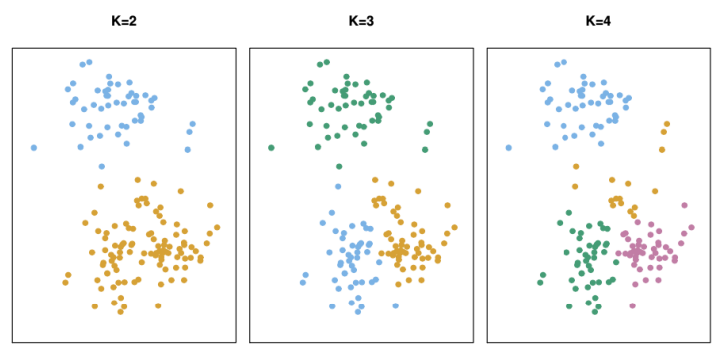
k-means clustering은 대표적인 unsupervised learning으로, 많은 데이터들을 k개의 클러스터로 나누어서 비교적 비슷한 특징을 갖는 각각의 클러스터로 데이터 집합을 구성하는 것을 목표로 한다.
아래는 k가 3일 때의 3-means clustering 과정을 보인다. 해당 데이들은 label이 존재하지 않는다.
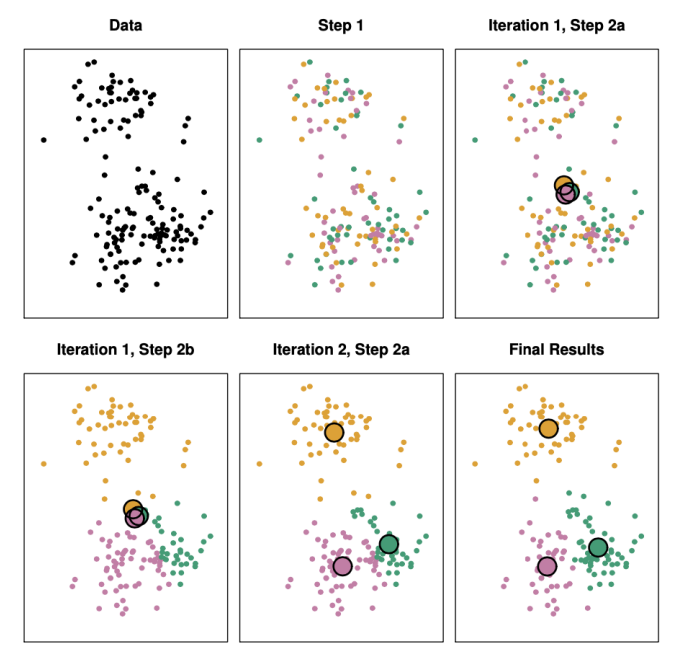
-
step 1: 3개의 클러스터를 설정하여 각각의 점이 3개의 다른 특징을 가지는 클러스터 중 하나에 포함한다. -
Iteration 1, step 2a: 각각 클러스터에 할당된 점들을 모아서Centroid (평균)에 해당하는 점의 위치를 찾는다. 이때, 데이터들이 무작위로 할당되어 있어 3개의Centroid가 상당히 모여있다. -
Iteration 1, step 2b: 새로 계산된 3개의Centroid를 기준으로 각각의 점들을 가장 가까운Centroid에 할당한다. -
Iteration 2, step 2a: 새로 할당된 점들을 이용해Centroid를 계산한다.
위와 같은 방식으로 clustering을 완료한 경우, 숫자적으로 의미가 있는지 꼭 검증이 필요하다.
다른 여타 unsupervised learning 으로는 아래 3개의 예가 있다.
Hirarchical Clustering
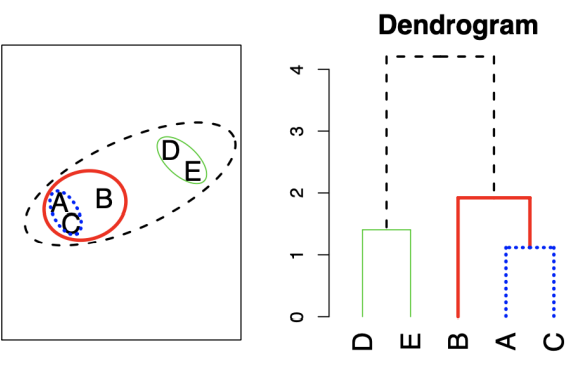
이는 가까운 것들끼리 묶는 과정의 반복을 통해 계층 구조를 형성한다.
Density Estimation
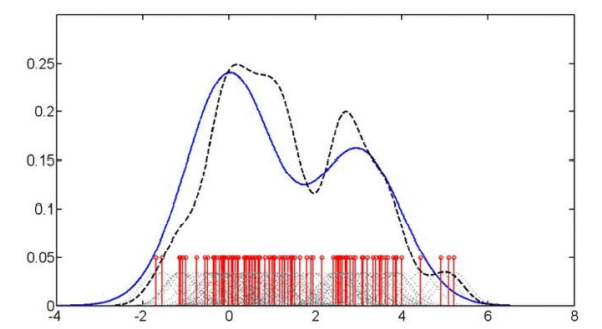
빨갛게 밑에 보이는 선들이 각각의 샘플 값들이고, 샘플의 값은 이 경우에 1-dimentional 한 스칼라 값이다. 이런 스칼라 값이 있을 때, 어느 스칼라 값 근처에서 점들이 발생하는가에 대한 확률을 계산하는 문제다.
PCA
dimention을 줄이기 위한 기법으로, Eigenvalue Decomposition과 동일한 방식이다.
Traditional Machine Learning
Low Dimentional Data: 작은dimentional dataSimple Concepts: 개념이 간단Reliable: 결과에 대한 검증이 필요
-
Internal cluster validation: 하나의 클러스터가 있으면, 클러스터 안에 모여있는 점들간의 평균거리와 서로 다른 클러스터에 모여 있는 점들간의 평균거리 등을 비교하여 검증 -
External cluster validation: 원래 데이터가label이 있는 데이터이고, 각 데이터가label이 없다고 가정한 뒤,k-means clustering을 수행하여 나온 결과가label하고 일치하면 의미 있는 결과이고 일치하지 않으면 의미없는 결과다.
클러스터링 후 가장 중요한 스텝은 클러스터링 된 결과가 말이 되는지 꼭 검증과정을 수행하는 것이다.
hint
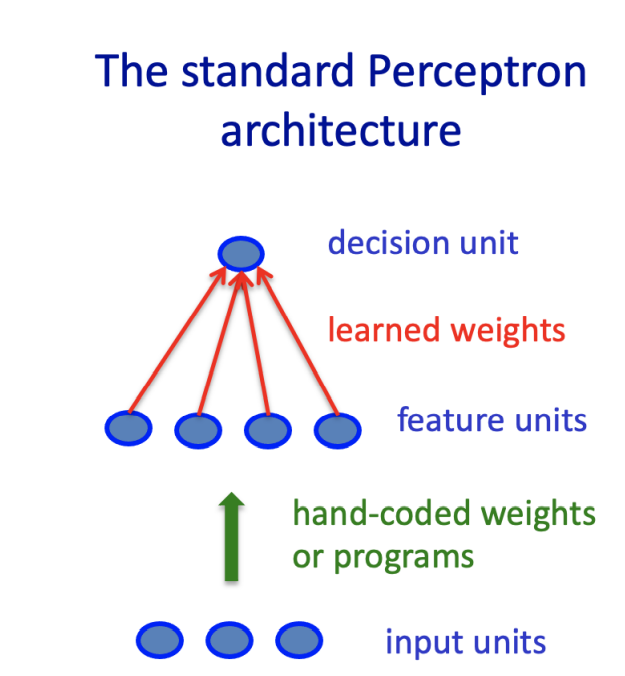
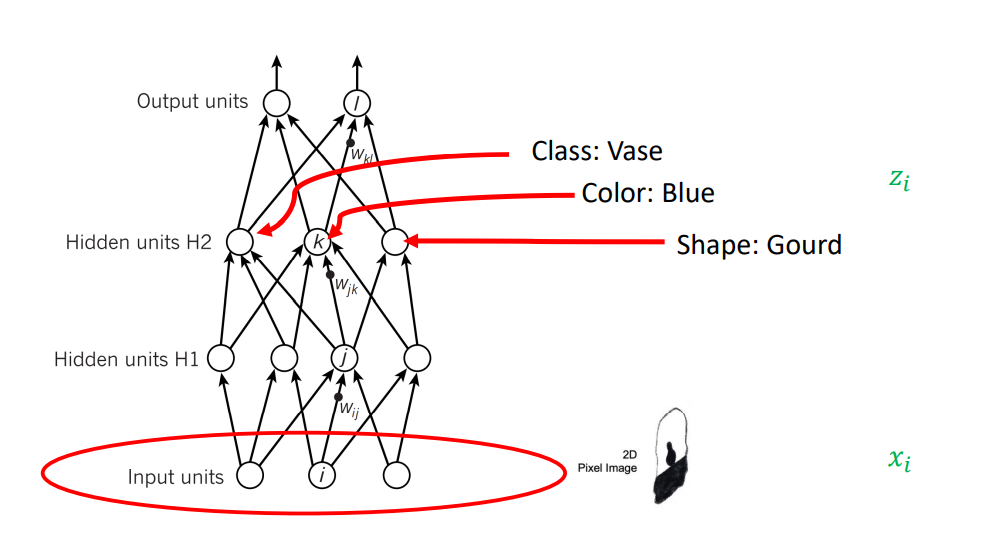
위의 perceptron과 같이 단순한 알고리즘을 쓸 때는, 좋은 성능을 바로 내기 어렵기 때문에 Raw data (original input data)를 인간이 가공해서 Hand cord weight을 통과시키거나, 프로그램을 만들어 통과시키는 과정을 통해 인간이 수작업으로 중요한 정보들을 잘 정리해주고 잘 정리된 정보를 중간 layer에 넣어주면, 최종적으로 좋은 결과를 도출해낼 수 있다.
Typical Prediction Problem

일반적으로 우리가 원하는 것은, X라는 데이터가 있을 때 f라는 함수를 잘 찾아서 X를 함수에 넣었을 때 나오는 결과 Y^을 우리가 원하는 값이 나오게 하는 것이다.
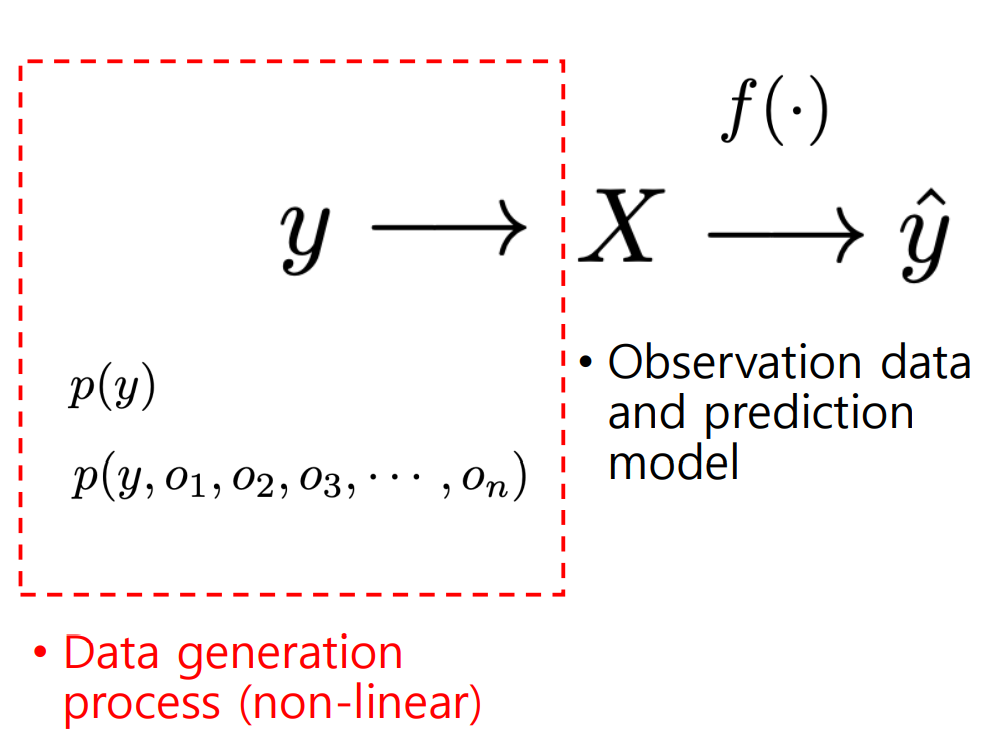
하지만, 이러한 문제를 풀 때 우리가 다루지 않는 부분이 존재한다. 아래 그림 속 빨간 네모 박스 부분인데, 우리는 데이터 X가 어떠한 과정으로 생성되었는지 알 수도 없고, 알려고 하지도 않는다. 이는 수많은 random variable이 복잡한 규칙을 통해 거의 모든 상황에서 non-linear한 관계로 섞여 X라는 데이터가 된다.
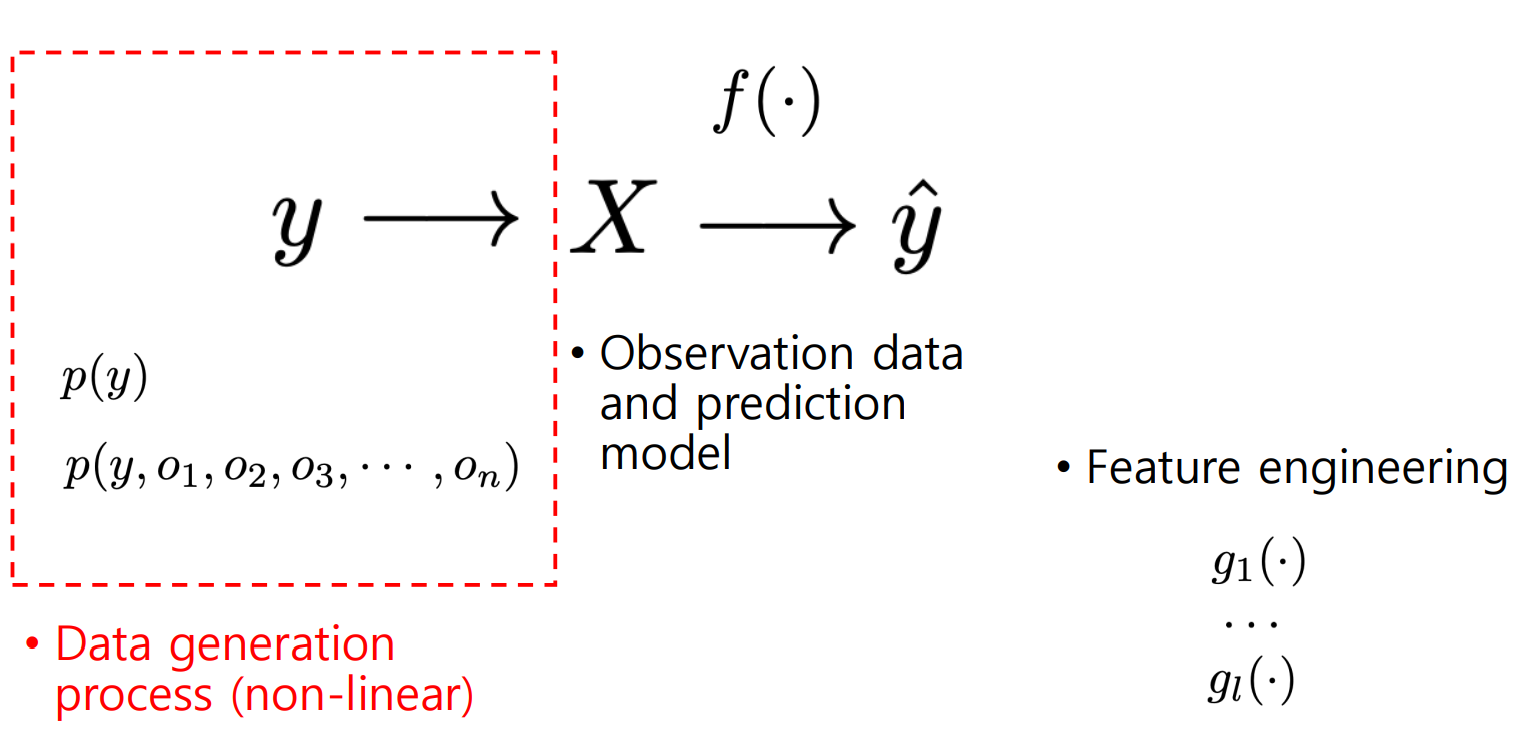
우리는 Y에서 X로 가는 과정은 정말 알 수 없지만, 푸는 문제가 어떤 domain에 있는 데이터인지에 따라 어느정도의 힌트는 얻을 수 있다.
그로인해, 모델을 도와주기 위해 X를 입력으로 받아 잘 정리된 정보 g(X)를 제공한다면 쉽게 문제를 풀 수 있을 것이고, 인간은 이를 최대한 잘 만들려고 노력할 것이다. 즉, g(X)를 f(X)가 잘 쓸 수 있게 만들었다면 해당 모델은 우리가 원하는 결과 값을 잘 낼 것이다.
Feature Engineering vs Representation Learning
feature engineering의 속성은 다음과 같다.
By humanDomain knowledge & creativityBrainstorming
전통적 접근법에 해당하는 내용들이다. g()를 찾는 과정을 feature engineering으로 통칭하며, 통상적으로는 함수 f()가 스스로 해내지 못하기 때문에, 인간이 모델의 결과값을 위해 g()를 찾아주는 데 도움을 준다.
representation learning의 속성은 다음과 같다.
By machine or algorithmDeep learning knowledge & coding skillTrial and Error
representation learning은 아래의 질문을 항상 고민한다.
나중에 풀어야하는 문제들에 대해 이미 정보를 잘 구성해놨으니, 얼마나 쉽게 문제를 풀 수 있을까?
deep learning의 목표는 앞서 설명한 g()를 찾지 않는 것이다. 즉, 인간의 개입 없이 알고리즘이 스스로 중요한 정보를 잘 정리해서 y라는 정보를 뽑아내는데 어려움이 없어 마지막에 linear layer만 집어넣어도 linear한 방식으로 y를 뽑을 수 있음을 뜻한다.
이러한 특성으로, vision이나 language에 관계된 데이터 타입의 문제를 풀 때는 representation learning이 더 잘 할 확률이 크다.
Modern Unsupervised Learning
-
High Dimentional Data (Image, Language) -
Difficult Concepts: 잘 이해되지는 않지만, 좋은 성능 및 결과를 보임 -
Deep learning -
Unsupervised Representation Learning
Representation Example
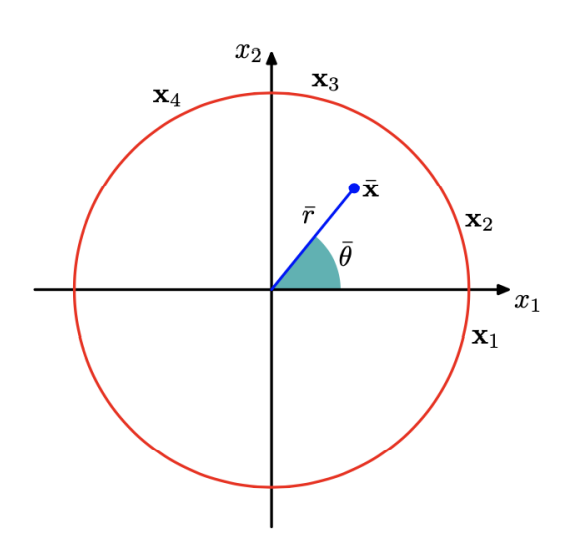
인간이 인공지능 모델에게 각도의 값을 전달할 때, 어떻게 전달해야 할까?
0, 2π는 인간이 봤을 때, 동일한 값으로 보지만 인공지능은 다르다고 판단0, 1.9π는 인간이 봤을 때, 가까운 값으로 보지만 인공지능은 멀다고 판단
이를 해결하기 위해서, representation에 변화를 주어 전달한다.
(x1, x2) = (cos(θ), sin(θ))로 표현하여 위에서 말한0, 2π와0, 1.9π를 주면 원점으로부터 특정한 좌표값을 얻게되어 인간과 동일한 방식으로 이해한다.
인간이 인공지능 모델에게 공간과 속도에 대한 정보를 전달할 때, 어떻게 전달해야 할까?
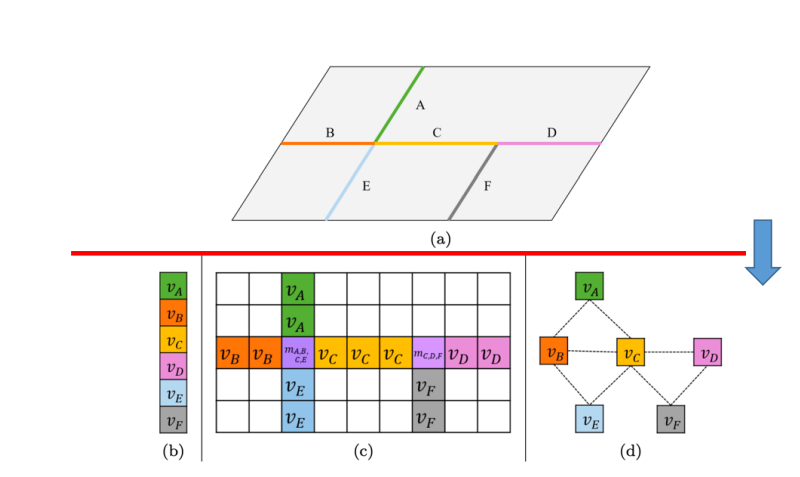
-
(a): 모델은 이해할 수 없다 -
(b): 각segmetation에 대한 정보만 얻을 수 있다. -
(c): 2차원grid를 생성하여 인공지능 모델이 이해할 수 있는matrix나2-dimentional tensor를 생성하여 도로가 없으면 비워놓고, 값이 있는 부분에는 도로segment의 평균속도 값을 입력하며 교차로에는 만나는segment의 평균속도를 적는 식으로 수행한다. 많은 정보를 알 수 있지만 불필요한 정보도 있다. -
(d): 그래프 형식으로segment를 나타내어 어느segment끼리 연관있는지, 평균 속력 등 필요한 정보만 얻을 수 있도록 한다.
위와 같이, 특정 형식으로 표현된 데이터에 특화된 알고리즘을 사용하면 원하는 문제에 대해 가장 좋은 성능을 기대할 수 있다.
Representation은 어떤
X라는 개념이 있을 때 이를 수학적인 기호로 표현하는 규칙들을 의미한다.
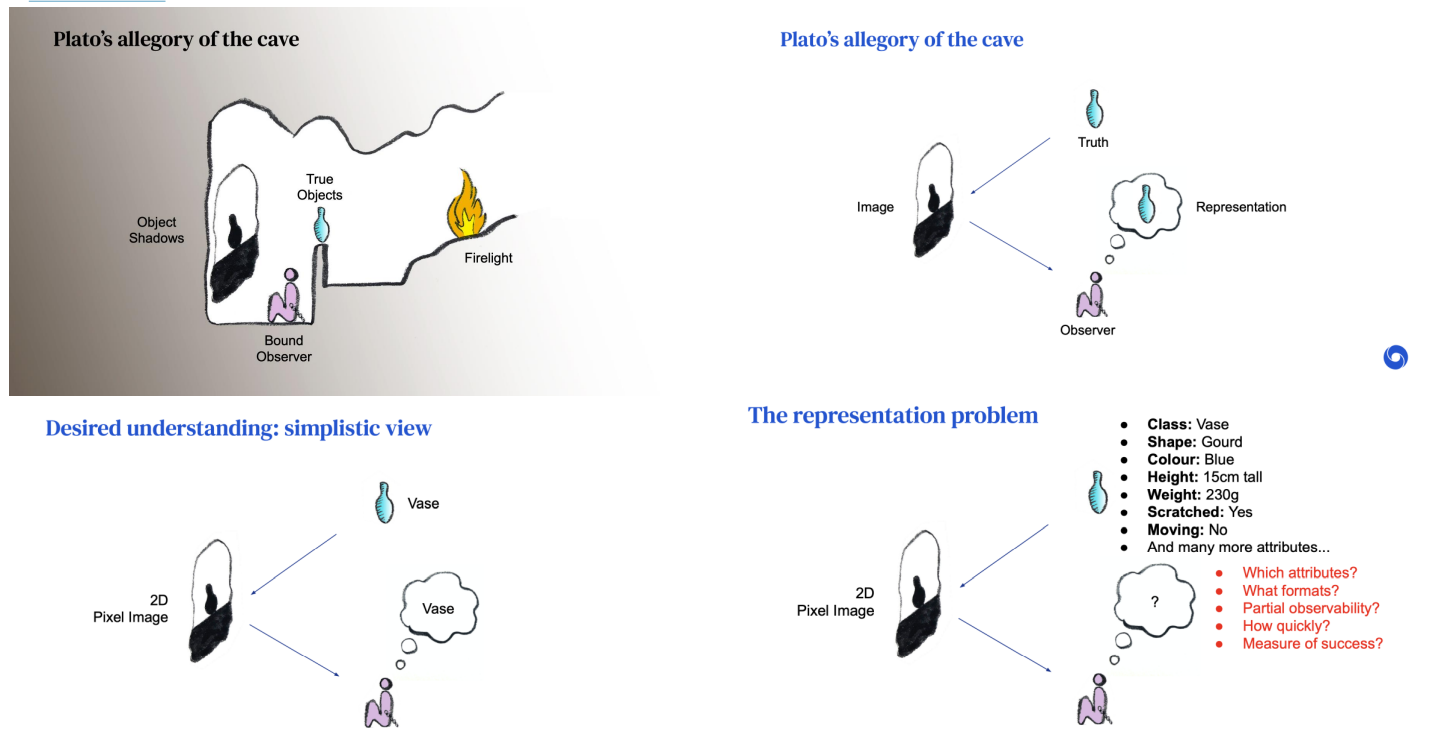
본 그림은 unsupervised learning의 예를 나타내는 그림이다. 왼쪽 위의 그림에서 사람은 불에 비친 물병의 그림자만을 볼 수 있다. True Object는 무엇인지 볼 수 없고, 그에 해당하는 Object Shadows를 보고 무엇일지 생각한다.
supervised learning에서는 Task가 명확하기 때문에, Class에 대한 정보를 원하고, vase라고 하는 class정보나 도움이 되는 정보를 정리해내는 것이 목표다.
하지만 unsupervised learning은 어떤 Task를 풀고 싶은 것인지 정해놓지 않았기 때문에, 정보를 잘 정리하여 어디에 쓸지에 대해 지정해놓지 않아 supervised learning에 비해 막연하다.
우리가 실질적으로 얻고자 하는 것은, 이미지가 입력으로 들어왔을 때 인공지능이 알아서 이미지를 분석하고 분해하여 어떤 class인지, 어떤 color인지, 어떤 shape인지 등 모든 정보를 알아내고, 해당 정보를 잘 정리하는 것을 바라지만 현실적으로 불가능하다.
그렇기 때문에, 인간이 어느정도 도움을 줘야 가능한 부분이다.
데이터의 입력단에서 pre-processing을 통해 모델을 도와준다.
Heavy Pre-Processing: 데이터가 복잡하거나 모델이 처리하지 못하는 경우 인간이 이런저런feature를 뽑아 새로운 입력 값을 넣어줌으로써 도움을 줌 =human feature engineeringMinimum Pre-Processing: const normalization of imagesNo Pre-Processing: text of a wiki page : 텍스트의 경우 너무 복잡하여 인간이 도와줄 수 없다.
데이터의 출력단에서, Relu 처럼 단순한 Activation Function을 쓰고, 마지막 Classification 하는 경우는 Cross-Entrophy Loss를 사용하면 설명할 수 있다는 점으로 학습이 잘 됨을 알았다.
Good Representation 이라고 하는 것은, 무엇인지 딱 정의하기 어렵지만, Useful 하고 Irrelevant 해야한다.
