해당 시리즈는 LG에서 지원하는 LG Aimers의 교육 내용을 정리한 것으로, 모든 출처는 https://www.lgaimers.ai/ 입니다.
Deep Learning Representation is Under Constarained
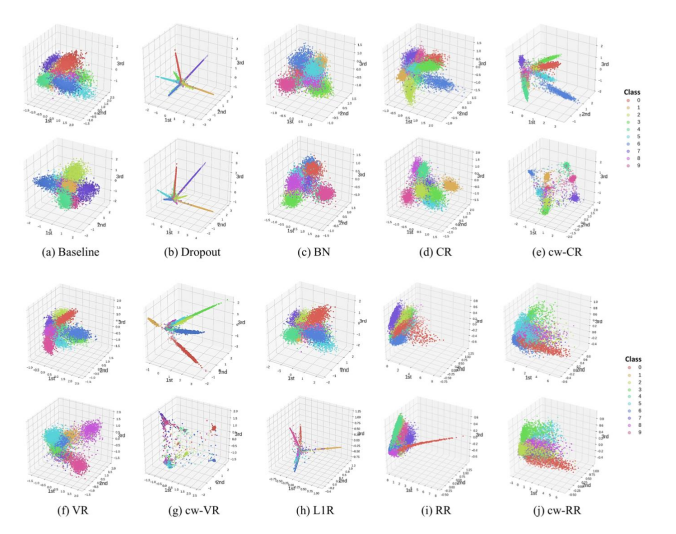
위 그림은, activation vector에 있는 것을 3차원으로 투영하여 dimention reduction 과정을 통해 representation을 그림으로 나타냈다. 동일한 task에 약간씩 다른 regualizer를 달아 학습에 영향을 준 결과인데, 각 regualizer 기법에 따른 representation이 매우 다른 것을 확인할 수 있다.
특이한건, representation이 각각 달라도 이에 따른 성능 차이가 존재하지 않고, 동일한 task에 성능이 좋았다는 것으로 이를 어떤 방식으로 해설해야 하는지를 말할 수 없다.
즉, 우리는 모델의 성능이 좋을 경우 representation learning이 잘 되었다는 표현을 하는데, 주어진 task에 대해 performance가 잘 나오면 구체적으로 어떤 작업이 수행되어 수학적으로 어떤 의미를 갖는지는 아무도 얘기하지 못한다는 것이다.
Disentangled Representation
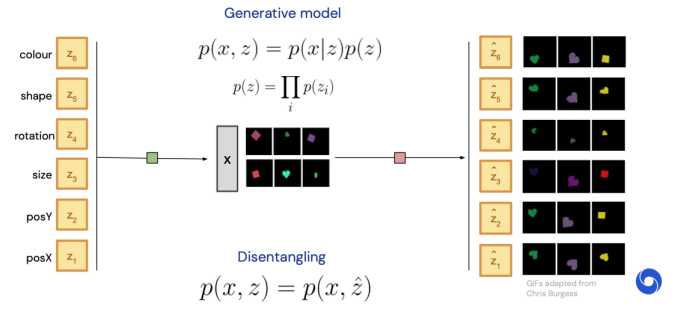
disentangled representation은 X라는 observation에서 representation을 만들어나가다가, n개의 개념이 하나의 뉴런마다 mapping이 되거나, 결과 값으로 n개가 나오면 좋겠다는 개념으로, n개의 가장 주요한 representation을 기존 데이터에서 완전히 분리하는 것을 말한다.
AlignedIndependent,Subspaces
supervised learning에서의 classification의 경우 우리가 하려고 하는 task가 무엇인지 명확히 정해져있고,정답인 y도 존재하기 때문에 representation에 대한 고민이 줄어든다.
Informational Bottleneck
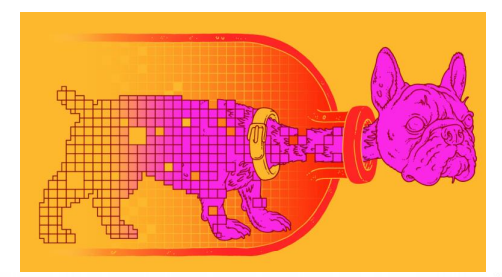
informational bottleneck은 위 그림처럼, 원하는 정보가 강아지의 머리인 경우 머리는 병밖에 두고, bottleneck을 구성하여 우리가 원하는 정보만 추출할 수 있다는 아이디어를 도출한 기법이다.
즉, X라는 observation data가 다양한 정보로 섞여 엉켜있는데, 그 중 원하는 y 정보만 뽑아낸다는 것이다.
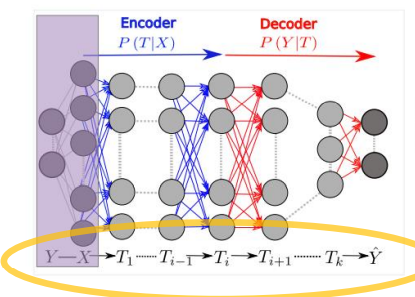
위 그림의 왼쪽 회색부분은 우리가 알 수 없는 shaped layer로, Y라는 정보가 X를 만들었음을 의미한다.
그림 속 Encoder와 Decoder 사이의 layer는 밑에서 올라온 정보에서 Y에 관계된 정보 즉, 최종적으로 남기고 싶은 정보는 최대한 다 살려두면서 그것과 상관없는 X의 나머지 부분은 최대한 지우는 식의 작업을 수행한다.
Unsupervised Learning - Vague Concept
General Purpose Downstream Task: 결국 1~5번task를 풀 것인데, 아직 그것을 모르는 상황에서unsupervised learning을 해서representation을 잘 정리해봐라, 잘 정리되었다면 최종적으로linear layer를 달아
linear evaluation을 진행한다.
마지막 1개의 layer만 잘 training하는 방식으로 1~5 task에 대해 좋은 결과가 나와야 할거야. 그래야지만 정보가 general purpose로 잘 정리된 것이다.
Word2Vec
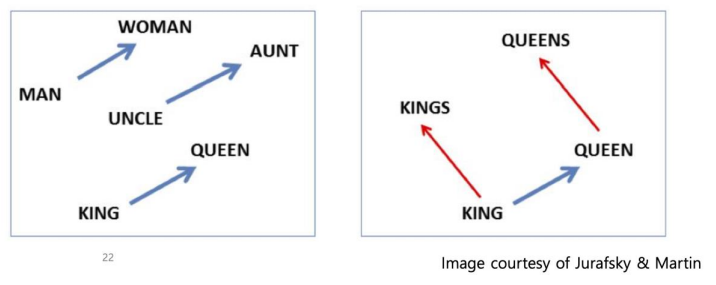
word2vec은 단어 하나하나를 숫자로 mapping 하는 기법이다.
해당 방법은 task를 정할 때 unsupervised learning 데이터셋임에도 불구하고, 문장으로 이루어진 데이터셋에서 문장에 있는 단어 하나를 지워서 알고리즘에게 이 문제를 해결하도록 한다.
이는 정답이 있는 supervised set이 없음에도, supervised data set이 되는 Self-Supervised Learning이라고 한다.
downstream task라는게 정해지기 전까지는,
unsupervised representation learning이 얼마나 잘 되었는가를 논의하는 것도 쉽지 않다.
결국 우리가 원하는 것은 정확한 representation은 무엇인지, 해당 representation이 잘 된 것인지를 구하는 것이지만 현실에서는
representation이 정의되지 않는다.
Two Extreme Points of View #1
즉, representation은 Interpretable & Explainable Representations 해야하며, 인간에게 쓸모있고 말이되는 일을 알고리즘이 하고 있다.
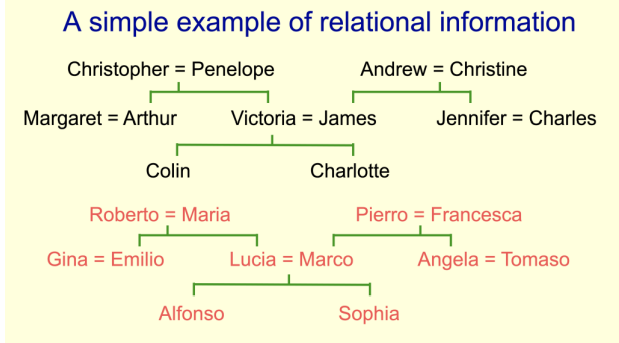
위 그림은 Hilton 가계도를 나타낸다.

1986년 Hilton 교수님은, 모델의 representation을 나타내기 위해, 가계도에 있는 모든 정보를 주지않고 일부마 주어 빈칸을 만들고 이를 문제로써 알고리즘이 풀도록 한다.

nerual network가 스스로 representation 하는 어떤 rule을 만들었는데, rule을 자세히 보니, 1세대 2세대 3세대라는 정보를 정리해놓고 남성, 여성의 정보를 정리해놓았다.
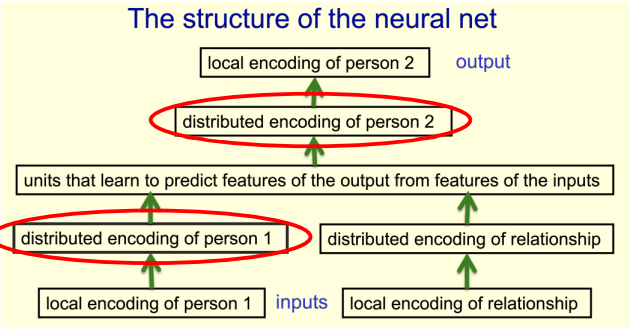
encoding 과정을 통해 모델이 스스로 정보를 학습해낼 수 있다.
첫 번째 view point : 인간이 그러하듯, 인간의 nerual network가 뭔가를 제대로 배웠다면, 의미있는 방식으로 정보를 전달할 뿐 아니라 규칙을 다 찾아내고 의미있는 정보의 종류도 다 분리해내는 것을 스스로 해낼 수 있을 것이다.
Visualization
visualization은 representation이 학습되었을 때, 그것을 그림으로 그려봤을 때 사람이 이해할 수 있다는 방식이다.

위 그림에서와 같이 하단 layer에서부터 최상단 layer로 올라올수록 고도화된 정보를 추출하여 각 레이어마다 정보를 진화시키고 최종적으로 마지막
output layer에서classifiction를 통해 결과를 도출한다.
Issues
만약 unsupervised learning에서 representation을 잘 추출한다면, 모델의 최상단 layer부터 망가뜨리면, representation을 정확히 못 잡아야하지 않을까?

상당히 많은 알고리즘들을 제대로 개념을 잡고 있으냐 아니냐 그걸 보고 있던게 아니라 Edge Detector의 역할을 하고있던 것이라서 input이 들어오면 값이 심하게 변하는 부분들이 잡혀서 보여주고 있던거지, 개념을 이해했다, 정리했다라고 말할 수는 없다.
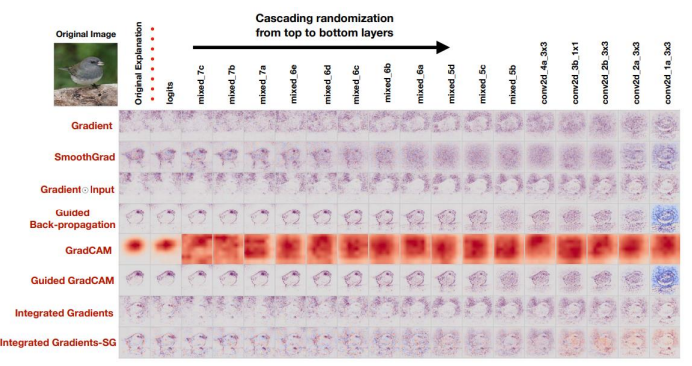
하지만, 어느 부분을 보고 알고리즘이 이러한 결론을 내렸는지는 해석가능하다.
Feature Visualization

윗 줄에서 이런 input이 들어왔을 때 activation이 maximize 되더라.
즉, 해당 관점에서는 representation network이 배우는 representation은 상당히 의미가 있는 것들이고, 잘 정리가 되고 있을 것이다라는 관점이다.
Intelligence Without Representation
해당 관점은 representation 필요 없다라는 관점으로, intelligence가 왜 반드시 우리가 이해할 수 있는 방식으로 잘 정리된 정보가 있어야지만 intelligence라고 생각을 하느냐라는 관점이다.
본 관점에서는 인간이 자꾸 정보를 정리하려 해, AI의 성능이 뛰어난게 아니라, 인간이 잘 정리된 representation을 제공했기에 문제를 푼것이다 라고 생각한다.
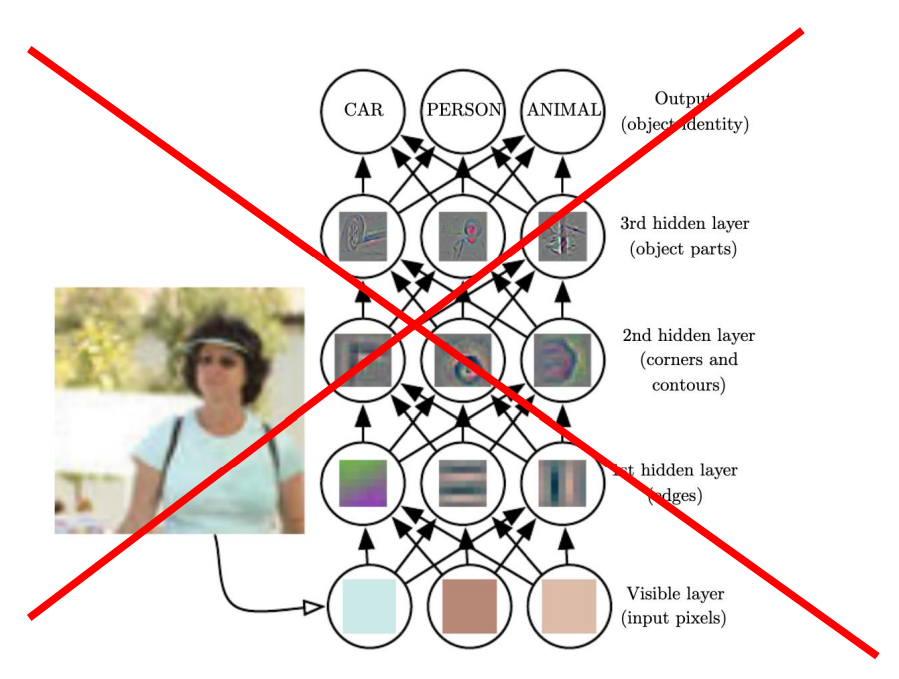
알고리즘이 알아서 학습, 분류, 정리할 일인데 왜 자꾸 인간이 개입하려하는가?
에 대한 개념이다.
본 관점에서 evaluation을 하려면 task와 목표가 명확해야한다.
representation 신경쓰지 않는다.
