
Dataset : https://www.kaggle.com/davinwijaya/customer-retention
이번 시간에는 Kaggle의 Marketing Promotion Campaign 데이터셋을 활용해 EDA와 가설 검정을 진행해보도록 하겠습니다.
먼저 데이터를 불러온 다음 중복값 제거 후 데이터의 구조를 확인해보겠습니다.
ab <- read.csv("data.csv")
ab <- unique(ab)
str(ab)'data.frame': 57397 obs. of 9 variables:
$ recency : int 10 6 7 9 2 6 9 9 9 10 ...
$ history : num 142.4 329.1 180.7 675.8 45.3 ...
$ used_discount: int 1 1 0 1 1 0 1 0 1 0 ...
$ used_bogo : int 0 1 1 0 0 1 0 1 1 1 ...
$ zip_code : chr "Surburban" "Rural" "Surburban" "Rural" ...
$ is_referral : int 0 1 1 1 0 0 1 0 1 1 ...
$ channel : chr "Phone" "Web" "Web" "Web" ...
$ offer : chr "Buy One Get One" "No Offer" "Buy One Get One" "Discount" ...
$ conversion : int 0 0 0 0 0 1 0 0 0 0 ...
데이터의 구조를 확인해보니 총 9개의 변수와 53797개의 행으로 이루어진 것을 확인할 수 있습니다.
한 번 결측값 또한 VIM 패키지의 aggr() 함수를 통해 확인해보겠습니다.
aggr(ab)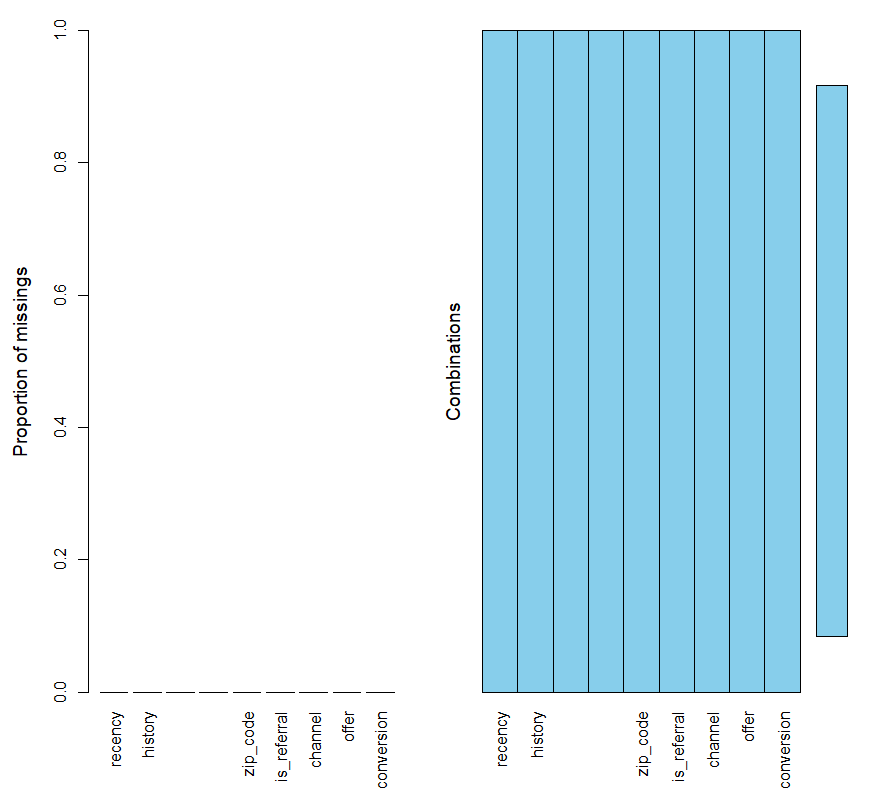
결측값 그래프 확인 결과 모든 변수에서 결측값이 존재하지 않는 사실을 알 수 있습니다.
각 변수들에 대해 설명하자면,
recency : 마지막 구매 이후 몇 개월이 지났는지 여부
history : 지금까지의 총 구매액
used_discount : 고객이 이전에 할인을 사용했는 지 여부
used_bogo : 고객이 이전에 1+1을 사용했는 지 여부
zip_code : 우편 번호의 분류 종류
is_referral : 고객을 추천 채널에서 획득하였는 지 여부
channel : 고객이 사용한 채널의 종류
offer : 고객에게 발송된 제안의 종류
conversion : 고객의 구매 여부
로 설명드릴 수 있습니다.
이제 각 변수들을 적절한 타입에 맞도록 변환하겠습니다. 변수가 많은 경우에는 일일이 타입을 변환하기 까다롭기 때문에 recipes 패키지를 사용하는 것이 훨씬 효율적입니다.
recipes 패키지를 사용하여 각 변수들을 변환하겠습니다.
recipe <- ab %>% recipe(conversion ~.) %>%
step_mutate_at(1,3,4,5,6,7,8,9, fn = factor) %>%
prep(training = ab)
ab <- juice(recipe)
str(ab)
tibble [57,397 x 9] (S3: tbl_df/tbl/data.frame)
$ recency : Factor w/ 12 levels "1","2","3","4",..: 10 6 7 9 2 6 9 9 9 10 ...
$ history : num [1:57397] 142.4 329.1 180.7 675.8 45.3 ...
$ used_discount: Factor w/ 2 levels "0","1": 2 2 1 2 2 1 2 1 2 1 ...
$ used_bogo : Factor w/ 2 levels "0","1": 1 2 2 1 1 2 1 2 2 2 ...
$ zip_code : Factor w/ 3 levels "Rural","Surburban",..: 2 1 2 1 3 2 2 3 1 3 ...
$ is_referral : Factor w/ 2 levels "0","1": 1 2 2 2 1 1 2 1 2 2 ...
$ channel : Factor w/ 3 levels "Multichannel",..: 2 3 3 3 3 2 2 2 2 3 ...
$ offer : Factor w/ 3 levels "Buy One Get One",..: 1 3 1 2 1 1 1 1 2 1 ...
$ conversion : Factor w/ 2 levels "0","1": 1 1 1 1 1 2 1 1 1 1 ...
recipes 패키지를 사용하여 각 변수들의 타입을 한꺼번에 변환하였습니다.
str() 함수를 통해 다시 한 번 구조를 확인해보니 변환이 제대로 이루어진 것을 확인할 수 있습니다.
이제 데이터를 가지고 EDA를 진행하도록 하겠습니다.
ab %>% group_by(recency) %>% count() %>% ggplot(aes(x = recency, y=n, fill=recency)) + geom_bar(stat = "identity") + geom_text(aes(label = n), size = 6) + ylab("count")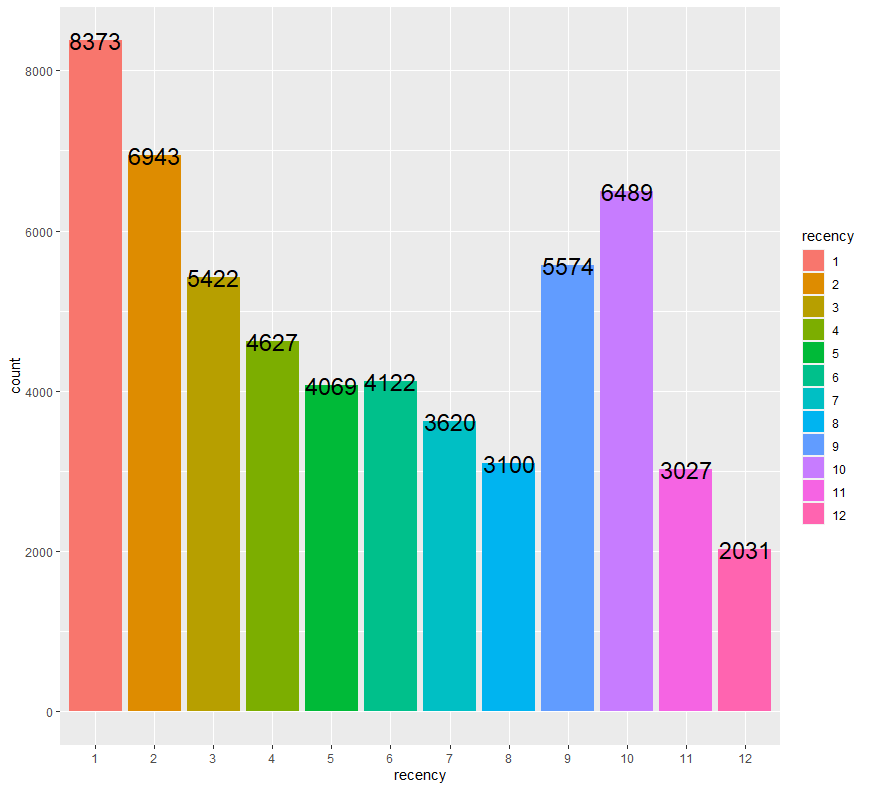
마지막 구매 후 1개월이 지난 고객의 수가 가장 많으며, 12개월이 지난 고객의 수가 가장 적은 모습을 보이고 있습니다.
특이한 점은 마지막 구매 후 9개월~10개월이 지난 고객의 수 또한 제법 많다는 사실입니다.
ab %>% ggplot(aes(x=history)) + geom_histogram(fill = "black", color = "white")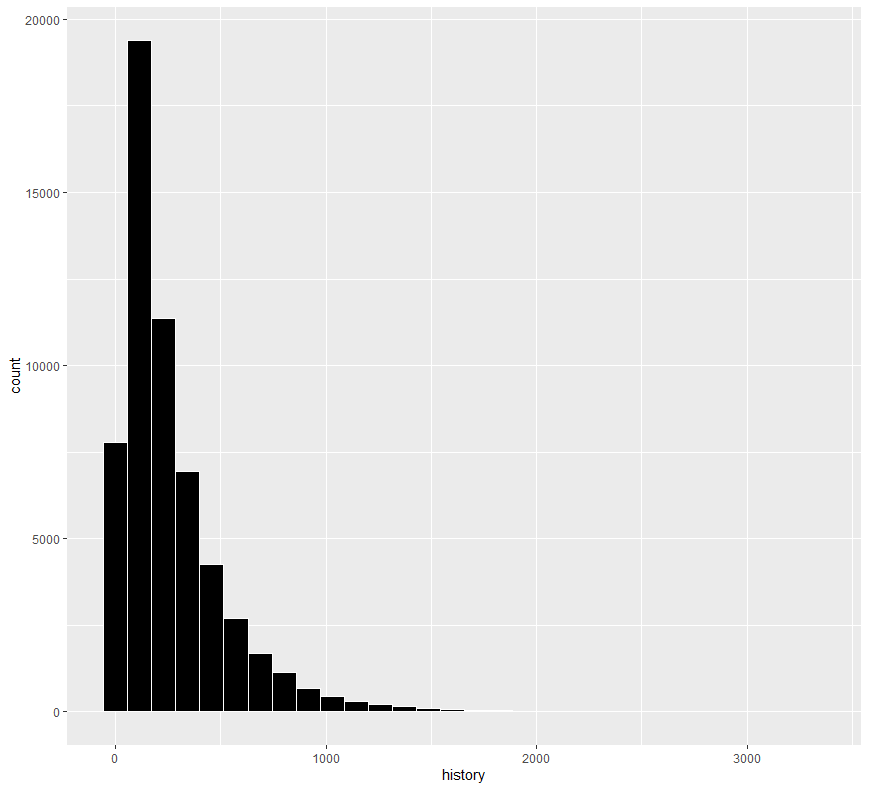
지금까지의 총 구매액은 왼쪽으로 치우친 분포를 보이고 있습니다.
아마 구매액의 경우에는 고객마다 천차만별로 다르며, 충성도가 높은 고객과 그렇지 않은 고객 사이의 액수 차이는 크게 벌어지기 때문으로 추정됩니다.
일단 데이터가 정규분포를 따르지 않기 때문에 가능한 정규분포화 해주는 것이 좋아보입니다. 로그화를 사용할 수도 있지만, 전혀 구매하지 않은 고객의 경우에 구매액이 0으로 산정되기 때문에 로그화를 적용하기 위해서는 이 값 또한 0이 아닌 다른 값으로 대체해줘야 됩니다.
따라서 박스플롯을 활용해 이상값을 변환하도록 하겠습니다.
box <- boxplot(ab$history)
min(box$out)[1] 746.93
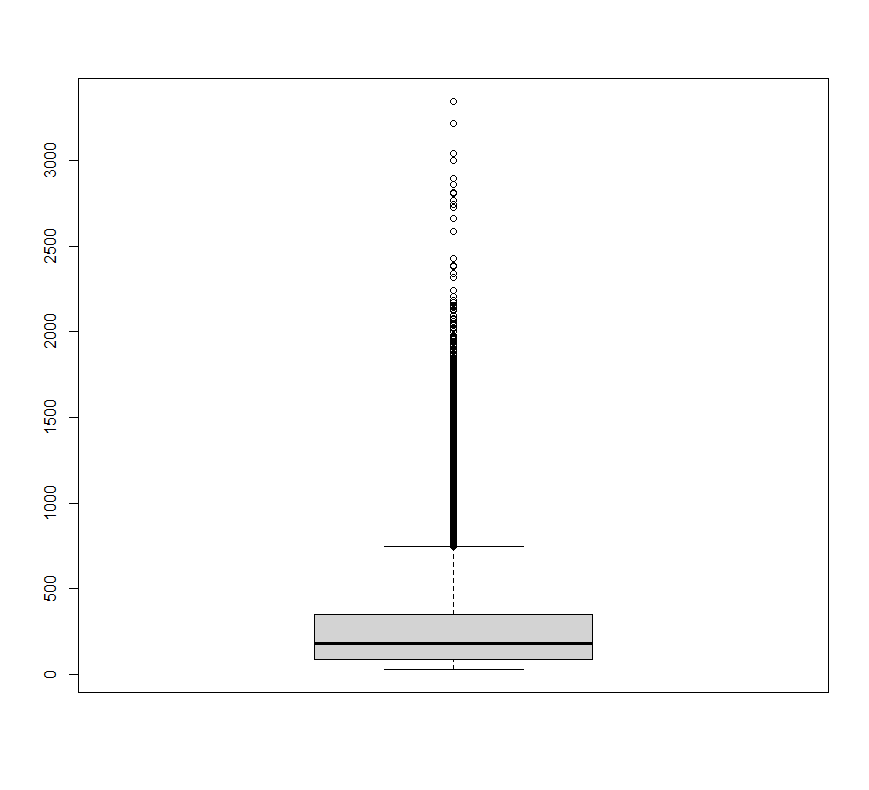
박스플롯을 활용해 이상값 중 최소값을 확인해보니 746.93으로 확인되었습니다. 즉, 746.93보다 큰 값들을 전부 이상값으로 간주한 다음 이 값들을 중앙값으로 대체하도록 하겠습니다.
ab$history <- ifelse(ab$history >= 746.93, median(ab$history), ab$history)
ab %>% ggplot(aes(x=history)) + geom_histogram(fill = "black", color = "white")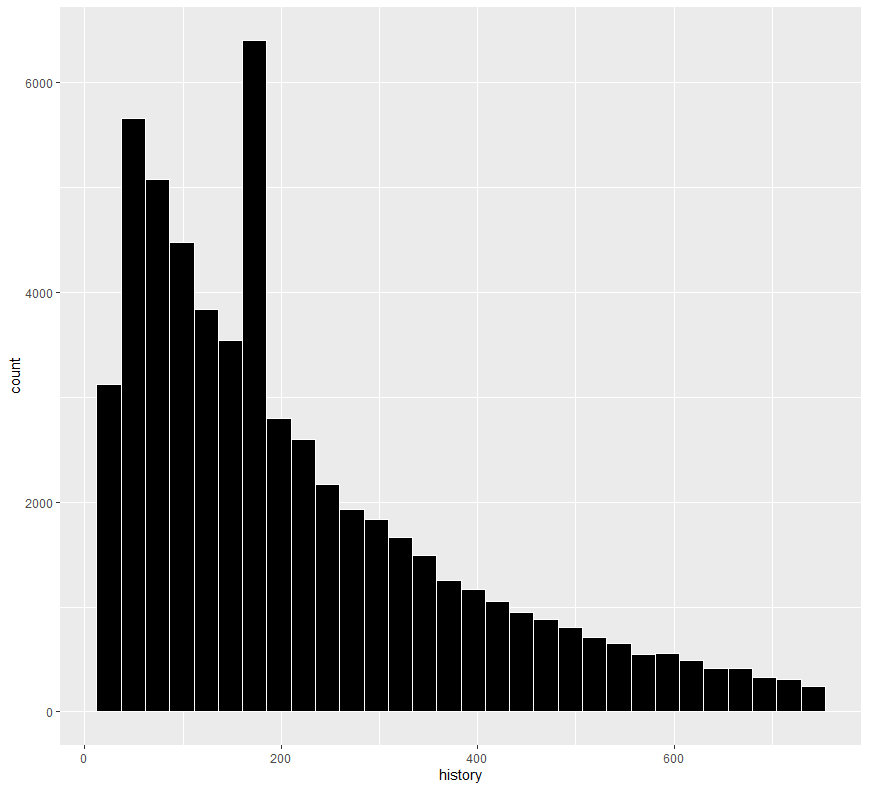
이상값을 중앙값으로 대체 후 데이터의 히스토그램을 다시 확인해보니 왼쪽으로 치우친 형태가 꽤 완만해진 것을 보실 수 있습니다.
ab %>% group_by(used_discount) %>% count() %>% ggplot(aes(x=used_discount, y=n, fill=used_discount)) + geom_bar(stat = "identity") + geom_text(aes(label = n), size = 6) + ylab("count")
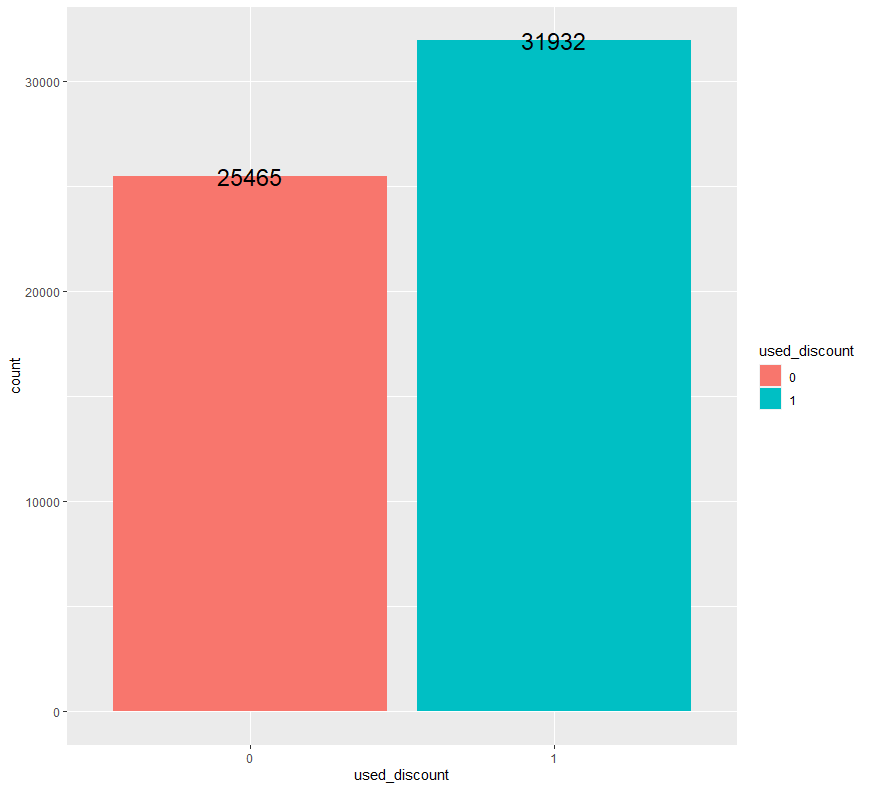
이전에 할인을 사용하지 않았던 고객(0)의 수보다 이전에 할인을 사용했던 고객(1)의 수가 더 많은 것을 확인할 수 있습니다.
ab %>% group_by(used_bogo) %>% count() %>% ggplot(aes(x=used_bogo, y=n, fill=used_bogo)) + geom_bar(stat = "identity") + geom_text(aes(label = n), size = 6) + ylab("count")
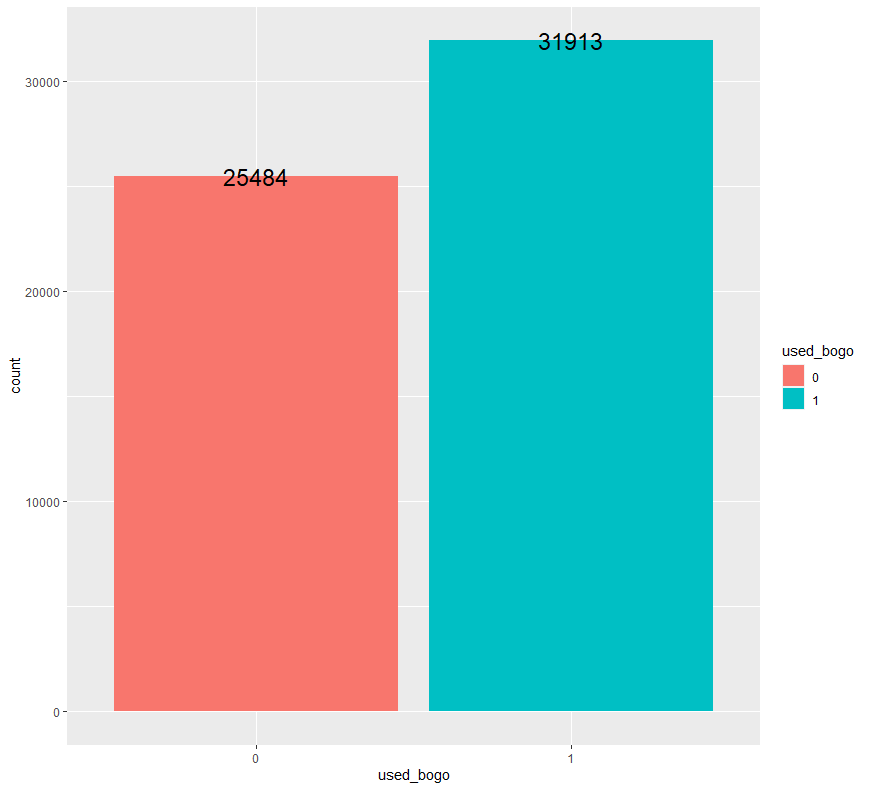
이전에 1+1을 사용하지 않은 고객(0)의 수보다 이전에 1+1을 사용한 고객(1)의 수가 더 많은 것을 확인할 수 있습니다.
ab %>% group_by(zip_code) %>% count() %>% ggplot(aes(x=zip_code, y=n, fill=zip_code)) + geom_bar(stat = "identity") + geom_text(aes(label = n), size = 6) + ylab("count")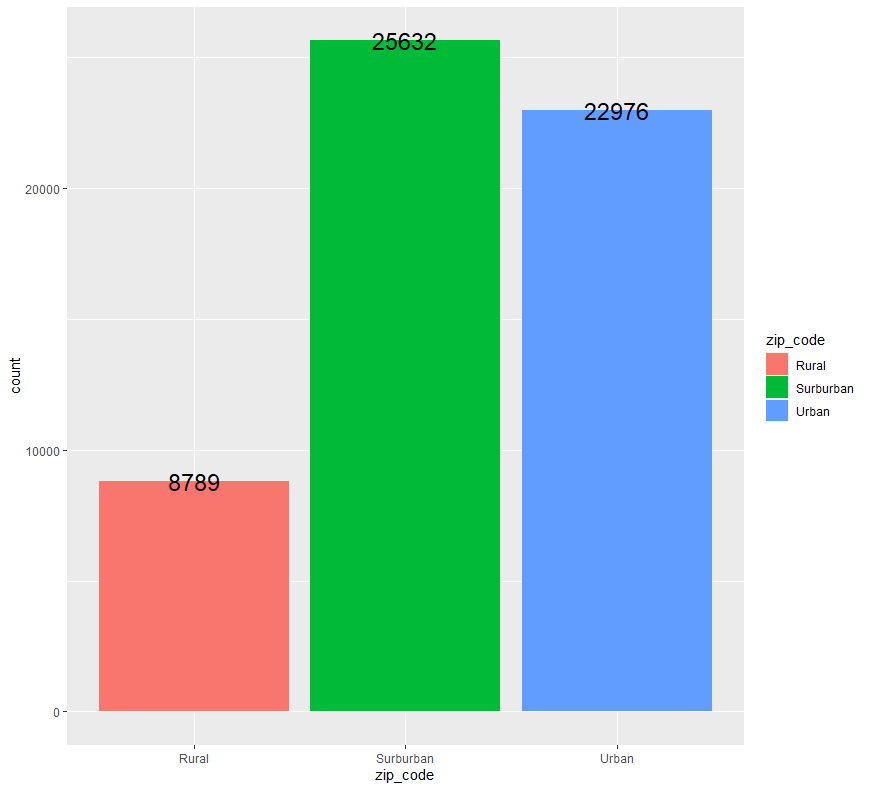
고객의 우편 번호를 세 지역으로 구분하였을 때(Rural = 시골, Surburban = 교외, Urban = 도시), 교외에 사는 고객의 수가 가장 많고 시골에 사는 고객의 수가 가장 적은 것을 확인할 수 있습니다.
또한 교외에 사는 고객의 수와 도시에 사는 고객의 수에는 큰 차이가 나지 않습니다.
ab %>% group_by(is_referral) %>% count() %>% ggplot(aes(x=is_referral, y=n, fill=is_referral)) + geom_bar(stat = "identity") + geom_text(aes(label = n), size = 6) + ylab("count")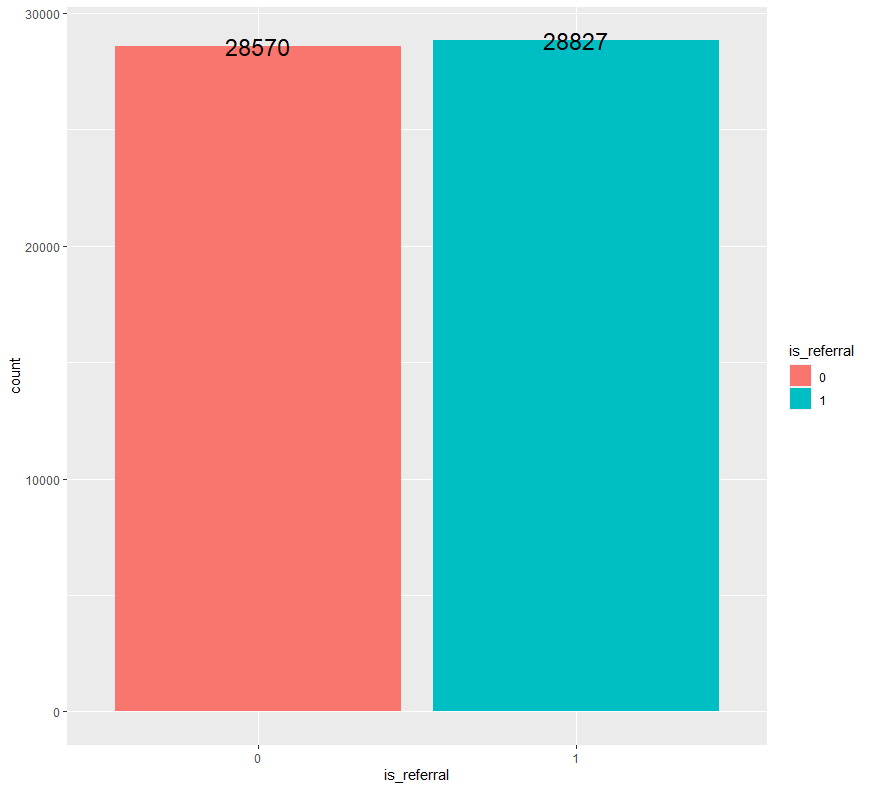
고객을 추천 채널에서 획득하지 못한 경우(0)와 고객을 추천 채널에서 획득한 경우(1) 사이에는 그렇게 큰 차이가 나지 않은 것을 확인할 수 있습니다.
ab %>% group_by(channel) %>% count() %>% ggplot(aes(x=channel, y=n, fill=channel)) + geom_bar(stat = "identity") + geom_text(aes(label = n), size = 6) + ylab("count")
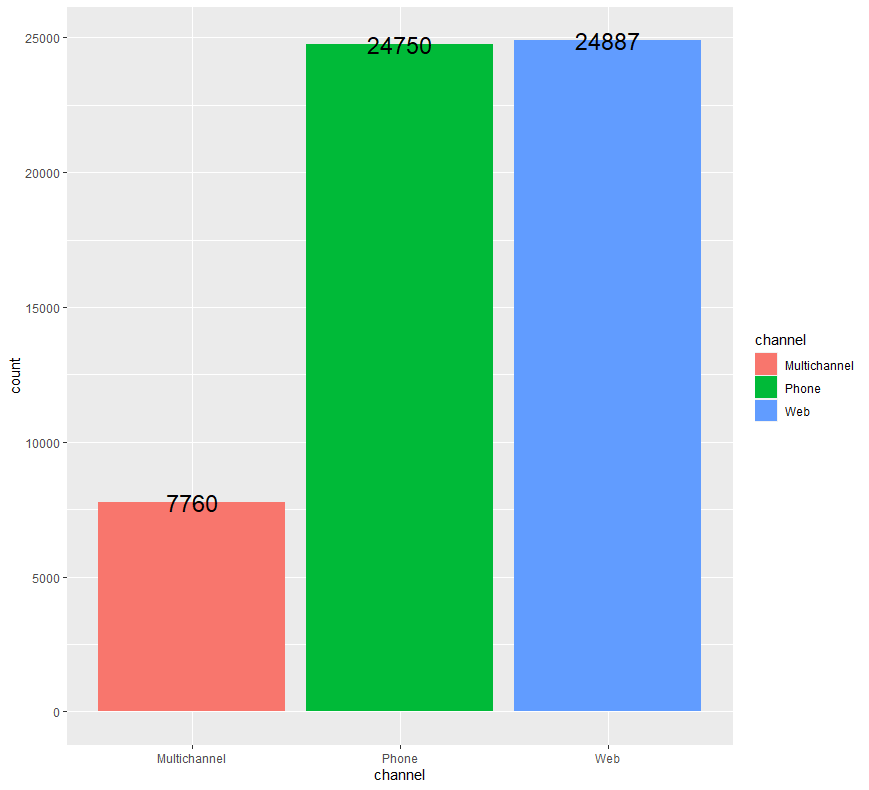
고객이 사용한 채널을 세 종류로 구분하였을 때(Multichannel = 멀티채널, Phone = 핸드폰, Web = 웹사이트), 웹사이트를 사용한 고객의 수가 가장 많고 멀티채널을 사용한 고객의 수가 가장 적은 것을 알 수 있습니다만, 웹사이트를 사용한 고객의 수와 핸드폰을 사용한 고객의 수는 거의 비슷합니다.
ab %>% group_by(offer) %>% count() %>% ggplot(aes(x=offer, y=n, fill=offer)) + geom_bar(stat = "identity") + geom_text(aes(label = n), size = 6) + ylab("count")
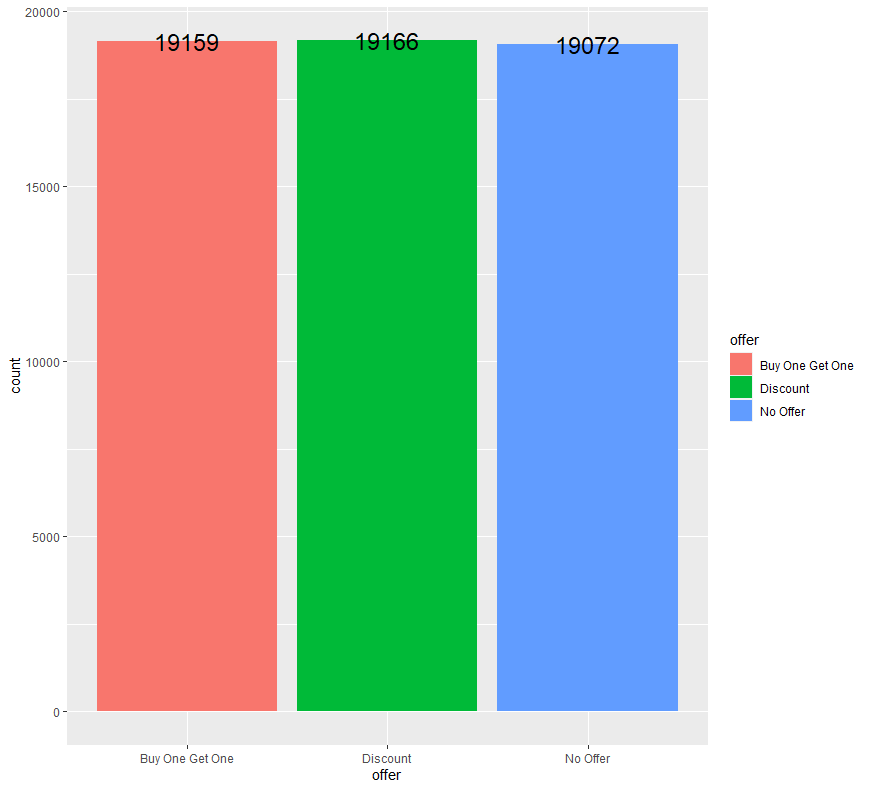
고객에게 발송된 제안을 세 종류로 구분하였을 때(Buy One Get One = 1+1, Discount = 할인, No Offer = 아무 제안이 없음), 그 수가 모두 비슷한 것을 확인할 수 있습니다.
ab %>% group_by(conversion) %>% count() %>% ggplot(aes(x=conversion, y=n, fill=conversion)) + geom_bar(stat = "identity") + geom_text(aes(label = n), size = 6) + ylab("count")
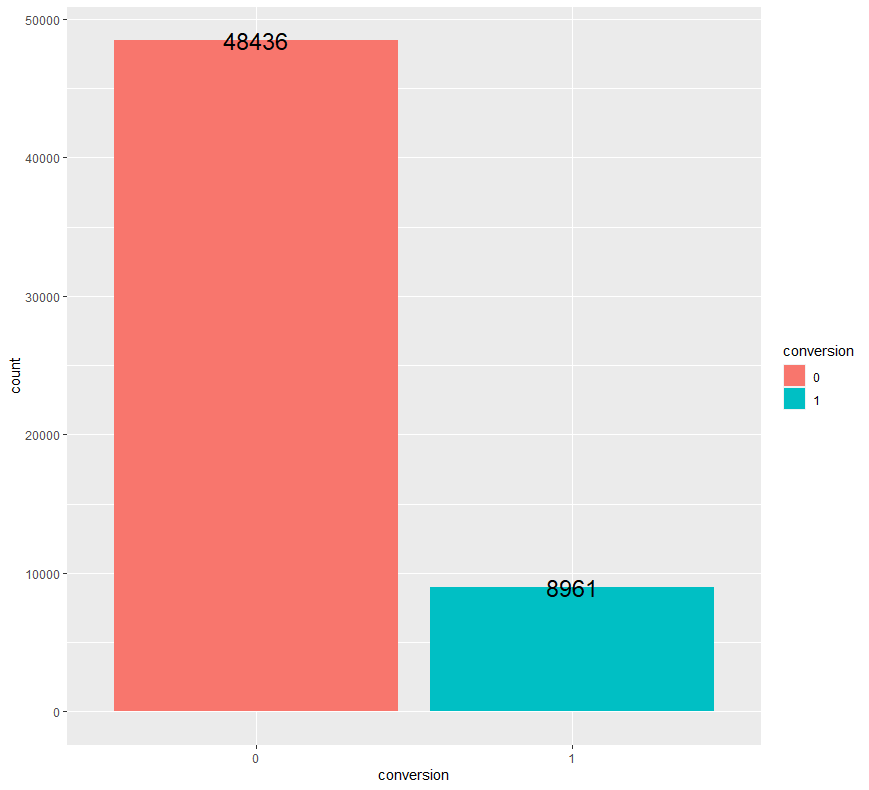
고객이 구매하지 않은 경우(0)가 고객이 구매한 경우(1)보다 압도적으로 많은 것을 확인할 수 있습니다만, 이는 지극히 정상적인 현상으로 파악됩니다.
이렇게 EDA를 마친 결과 다양한 가설 검정을 진행할 수 있지만, 이번 연습에서는 총 3개의 가설만 검정하도록 하겠습니다.
-
고객을 추천 채널에서 획득하지 못한 경우보다 고객을 추천 채널에서 획득한 경우에 구매 전환율이 더 높을 것이다.
-
고객이 이전에 1+1을 사용하지 않은 경우보다 고객이 이전에 1+1을 사용한 경우에 구매 전환율이 더 높을 것이다.
-
고객에게 발송된 제안의 종류에 따라 구매 전환율에는 유의한 차이가 존재할 것이다.
1. 고객을 추천 채널에서 획득하지 못한 경우보다 고객을 추천 채널에서 획득한 경우에 구매 전환율이 더 높을 것이다.
독립변수는 is_referral, 목표변수는 conversion이 되며, 두 개의 그룹에서 이항 범주의 비율 차이를 검정하는 것이기 때문에 모비율 차이 검정을 적용할 수 있습니다.
한 번 그래프를 통해 대략적인 비율 차이를 알아보겠습니다.
ab %>% group_by(is_referral) %>% count(conversion) %>% mutate(prop = n/sum(n)) %>%
ggplot(aes(x=is_referral, y=prop, fill=conversion)) + geom_bar(stat = "identity", position = "dodge") + geom_text(aes(label = paste(round(prop, 4), "%")), size = 10) + scale_fill_brewer(palette = "Paired")
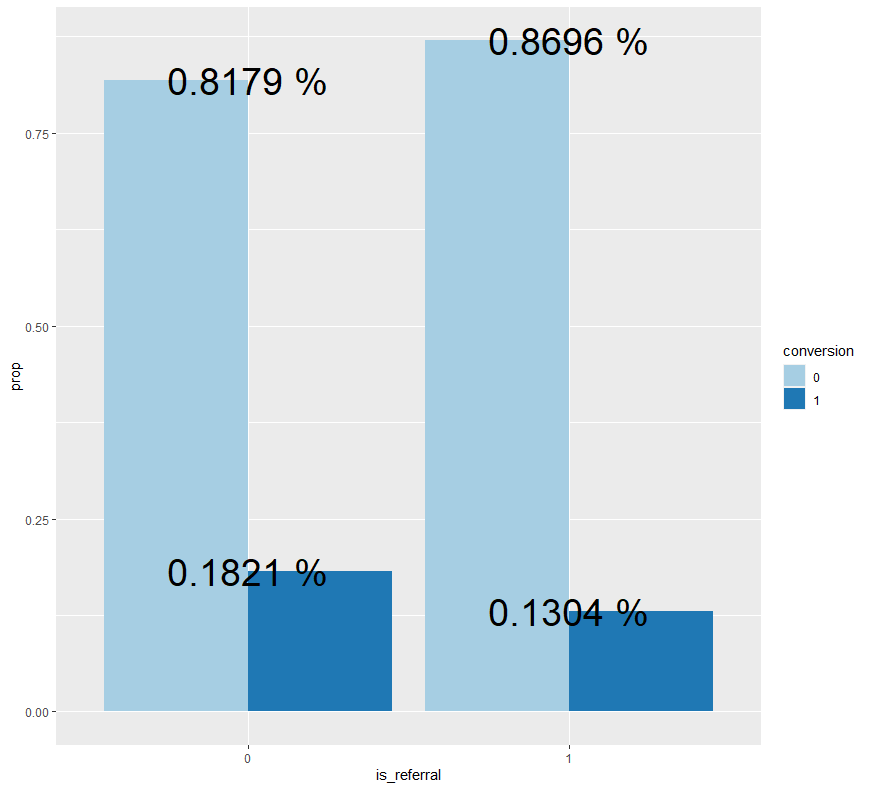
고객을 추천 채널에서 획득하지 못한 경우의 구매 전환율(1)은 약 18.2%이며, 고객을 추천 채널에서 획득한 경우의 구매 전환율(1)은 약 13%로 보입니다.
prop.test() 함수를 통해 모비율 차이 검정을 진행하도록 하겠습니다.
prop.test(x = c(5203, 3758), n = c(28570, 28827), alter = "less", correct = F)
2-sample test for equality of proportions without continuity correction
data: c(5203, 3758) out of c(28570, 28827)
X-squared = 291.67, df = 1, p-value = 1
alternative hypothesis: less
95 percent confidence interval:
-1.00000000 0.05672469
sample estimates:
prop 1 prop 2
0.1821141 0.1303639
검정 결과 p-value가 0.05보다 매우 크기 때문에 귀무가설을 기각하지 못하게 됩니다.
즉, 고객을 추천 채널에서 획득한 경우의 구매 전환율이 고객을 추천 채널에서 획득하지 못한 경우의 구매 전환율보다 통계적으로 높다고 말할 수 없습니다.
2. 고객이 이전에 1+1을 사용하지 않은 경우보다 고객이 이전에 1+1을 사용한 경우에 구매 전환율이 더 높을 것이다.
독립변수는 used_bogo, 목표변수는 conversion이 되며, 역시 두 개의 그룹에서 이항 범주의 비율 차이를 검정하는 것이기 때문에 모비율 차이 검정을 적용할 수 있습니다.
한 번 그래프를 통해 대략적인 비율 차이를 확인해보겠습니다.
ab %>% group_by(used_bogo) %>% count(conversion) %>% mutate(prop = n/sum(n)) %>%
ggplot(aes(x=used_bogo, y=prop, fill=conversion)) + geom_bar(stat = "identity", position = "dodge") + geom_text(aes(label = paste(round(prop, 4), "%")), size = 10) + scale_fill_brewer(palette = "Paired")
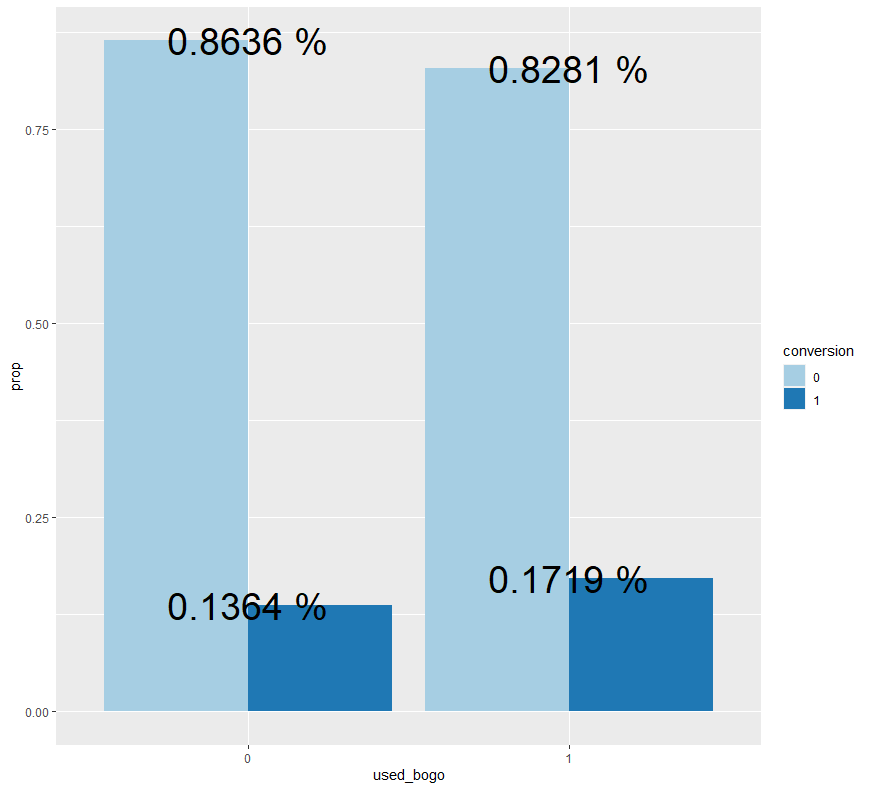
고객이 이전에 1+1을 사용하지 않은 경우의 구매 전환율은 약 13.6%이며, 고객이 이전에 1+1을 사용한 경우의 구매 전환율은 약 17.2%인 것을 확인할 수 있습니다.
prop.test() 함수를 통해 미리 설정한 가설이 맞는지 확인해보겠습니다.
prop.test(x = c(3476, 5485), n = c(25484, 31913), alter = "less", correct = F)2-sample test for equality of proportions without continuity correction
data: c(3476, 5485) out of c(25484, 31913)
X-squared = 135.34, df = 1, p-value < 2.2e-16
alternative hypothesis: less
95 percent confidence interval:
-1.00000000 -0.03051714
sample estimates:
prop 1 prop 2
0.1363993 0.1718735
검정 결과 p-value가 0.05보다 매우 작으므로 귀무가설을 기각할 수 있습니다.
즉, 고객이 이전에 1+1을 사용한 경우의 구매 전환율이 고객이 이전에 1+1을 사용하지 않은 경우의 구매 전환율보다 통계적으로 높다고 말할 수 있으며, 미리 설정한 가설이 통계적으로 유의하다고 판단할 수 있습니다.
3. 고객에게 발송된 제안의 종류에 따라 구매 전환율에는 유의한 차이가 존재할 것이다.
독립변수는 offer, 목표변수는 conversion이며 두 그룹 간의 모비율 차이 검정이 아닌 세 그룹 간의 모비율 차이 검정으로 봐야 합니다.
또한 두 그룹 간의 모비율 차이 검정과 달리 세 그룹 간의 모비율 차이 검정에서는 귀무가설(세 그룹 간의 모비율이 동일하다)이 기각될 경우 사후 검정이 필수적으로 요구됩니다.
먼저 그래프를 통해 세 그룹 간의 비율 차이를 확인해보겠습니다.
ab %>% group_by(offer) %>% count(conversion) %>% mutate(prop = n/sum(n)) %>%
ggplot(aes(x=offer, y=prop, fill=conversion)) + geom_bar(stat = "identity", position = "dodge") + geom_text(aes(label = paste(round(prop, 4), "%")), size = 10) + scale_fill_brewer(palette = "Paired")
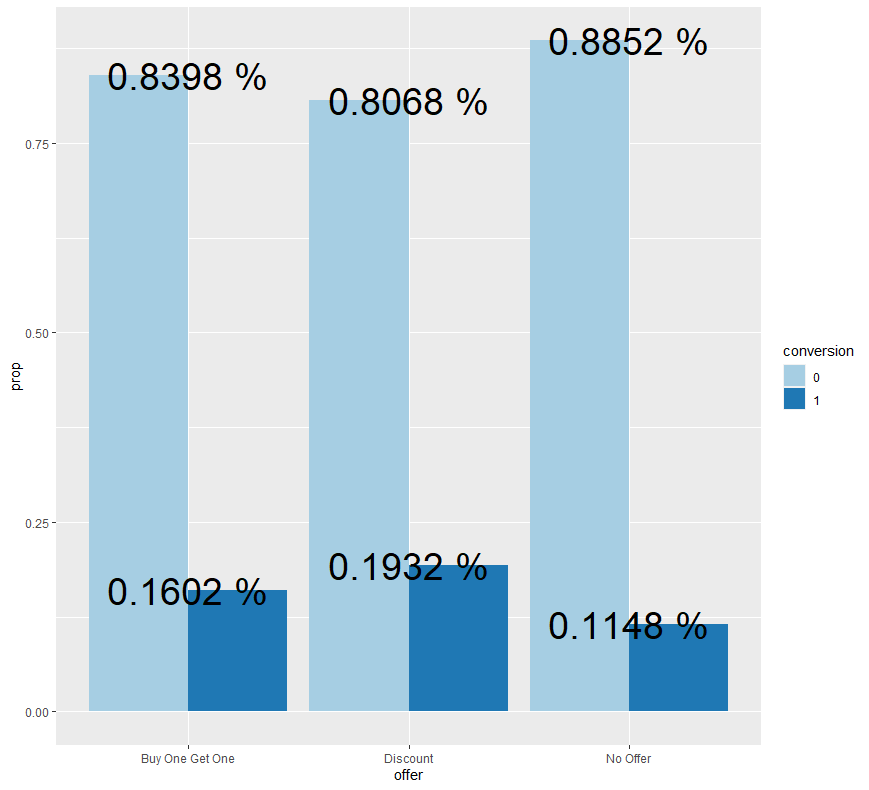
그래프를 보면 1+1을 발송한 경우의 구매 전환율은 약 16%, 할인이라고 발송한 경우의 구매 전환율은 약 19.3%, 그리고 아무 제안 없이 발송한 경우의 구매 전환율은 약 11.5%인 것을 확인할 수 있습니다.
prop.test() 함수를 통해 세 그룹 간의 모비율에 차이가 존재하는 지 확인해보도록 하겠습니다.
prop.test(x = c(3069, 3703, 2189), n = c(19159, 19166, 19072), correct = F)
3-sample test for equality of proportions without continuity correction
data: c(3069, 3703, 2189) out of c(19159, 19166, 19072)
X-squared = 449.94, df = 2, p-value < 2.2e-16
alternative hypothesis: two.sided
sample estimates:
prop 1 prop 2 prop 3
0.1601858 0.1932067 0.1147756
검정 결과 p-value가 0.05보다 매우 작기 때문에 귀무가설을 기각할 수 있습니다.
즉, 세 그룹 간의 모비율은 모두 같다는 귀무가설을 기각할 수 있기 때문에 사후 검정을 통해 어느 그룹 간의 차이가 통계적으로 유의한지 확인해봐야 합니다.
세 그룹 이상의 모비율 차이 사후 검정에는 pairwise.prop.test() 함수를 사용할 수 있습니다.
pairwise.prop.test(x = c(3069, 3703, 2189), n = c(19159, 19166, 19072))
Pairwise comparisons using Pairwise comparison of proportions
data: c(3069, 3703, 2189) out of c(19159, 19166, 19072)
1 2
2 <2e-16 -
3 <2e-16 <2e-16
P value adjustment method: holm
사후 검정 결과 모든 p-value 값이 0.05보다 매우 작기 때문에 세 그룹 모두 모비율이 통계적으로 같지 않다고 할 수 있습니다.
따라서 할인이라고 발송한 경우의 구매 전환율이 약 19.3%로 가장 높았으며, 그 다음으로 1+1이라고 발송한 경우의 구매 전환율이 약 16%로 높았으며, 마지막으로 아무 제안 없이 발송한 경우의 구매 전환율이 약 11.5%로 가장 낮았다고 말할 수 있습니다.
이렇게 가설 검정을 진행한 결과 구매 전환율 향상이라는 목표에 대한 3개의 인사이트를 얻을 수 있었습니다.
- 고객을 추천 채널에서 획득한 경우의 구매 전환율이 고객을 추천 채널에서 획득하지 못한 경우의 구매 전환율보다 통계적으로 높지 않습니다.
-> 고객을 추천 채널에서 획득하는 것이 구매 전환율에는 별 영향이 없거나 오히려 떨어지는 결과를 보이기 때문에 추천 채널을 통해 고객을 획득하는 방법은 재고할 필요가 있어 보입니다.
- 고객이 이전에 1+1을 사용한 경우의 구매 전환율이 고객이 이전에 1+1을 사용하지 않은 경우의 구매 전환율보다 통계적으로 더 높았습니다.
-> 고객이 이전에 1+1을 사용한 경우가 구매 전환율에 긍정적인 영향을 미쳤기 때문에 1+1 event에 대한 다양한 구상과 확장이 필요할 것 같습니다.
- 고객에게 발송된 제안의 종류에 따라 구매 전환율에는 통계적으로 유의한 차이가 존재하였으며, 할인이라는 제안의 경우 구매 전환율이 가장 높았고 아무 제안이 없는 경우 구매 전환율이 가장 낮았습니다.
-> 고객에게 아무 제안 없이 발송하는 경우가 구매 전환율이 가장 낮았기 때문에 아무 제안이 없는 것보다는 제안이 존재하는 것이 구매 전환율을 향상시키는 데 긍정적으로 보입니다.
또한 제안을 넣을 경우에는 1+1의 내용보다는 할인 위주의 내용을 작성하는 것이 고객의 구매 전환율 향상에 더 긍정적인 효과가 있을 것으로 보입니다.
이렇게 Kaggle Dataset을 통해 EDA 및 가설 검정을 연습해보았습니다.
감사합니다.
