
데이터
와인 데이터는 분류 문제에서 많이 사용하는 Iris 꽃 데이터만큼 알려지진 않았지만, 많이 사용된다.
1. 데이터 불러오기
import pandas as pd
red_wine = pd.read_csv(red_url, sep=';') red_wine.head()

white_wine = pd.read_csv(white_url, sep=';') white_wine.head()

두 데이터의 구조는 동일하다.
<컬럼 설명>
- fixed acidity : 고정 산도
- volatile acidity : 휘발성 산도
- citric acid : 시트르산
- residual sugar : 잔류당분
- chlorides : 염화물
- free sulfur dioxide : 자유 이산화황
- total sulfur dioxide : 총 이산화황
- density : 밀도
- pH
- sulphates : 황산염
- alcohol : 알콜농도
- quality : 높을수록 좋은 품질
2. 데이터 합치기
두 데이터를 하나로 합쳐보자.
red_wine['color'] = 1 white_wine['color'] = 0 wine = pd.concat([red_wine, white_wine])
대신 레드와인/화이트와인 을 분류해야 하니 "color"컬럼을 만들어
레드와인은 1, 화이트와인은 0 값을 입력했다.
wine.info()
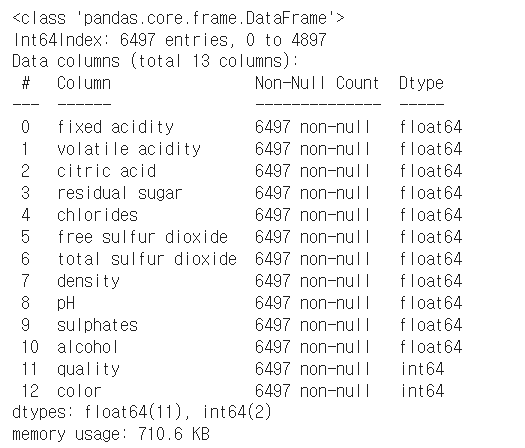
합친 데이터는 이렇게 생겼다!
wine['quality'].unique()
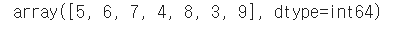
와인 등급은3에서 9사이 값을 갖는다.
import plotly.express as px
fig = px.histogram(wine, x="quality") fig.show()
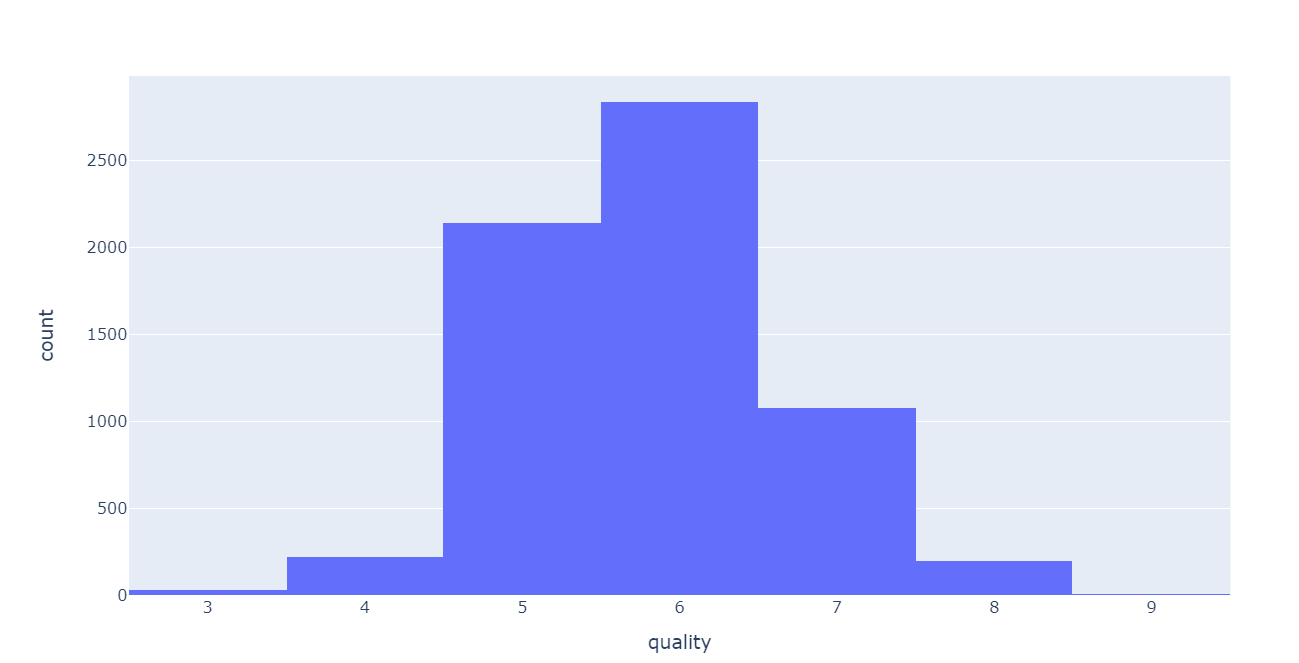
plotly를 사용해 와인 등급의 분포를 히스토그램으로 그려보았다.
fig = px.histogram(wine, x="quality", color="color") fig.show()
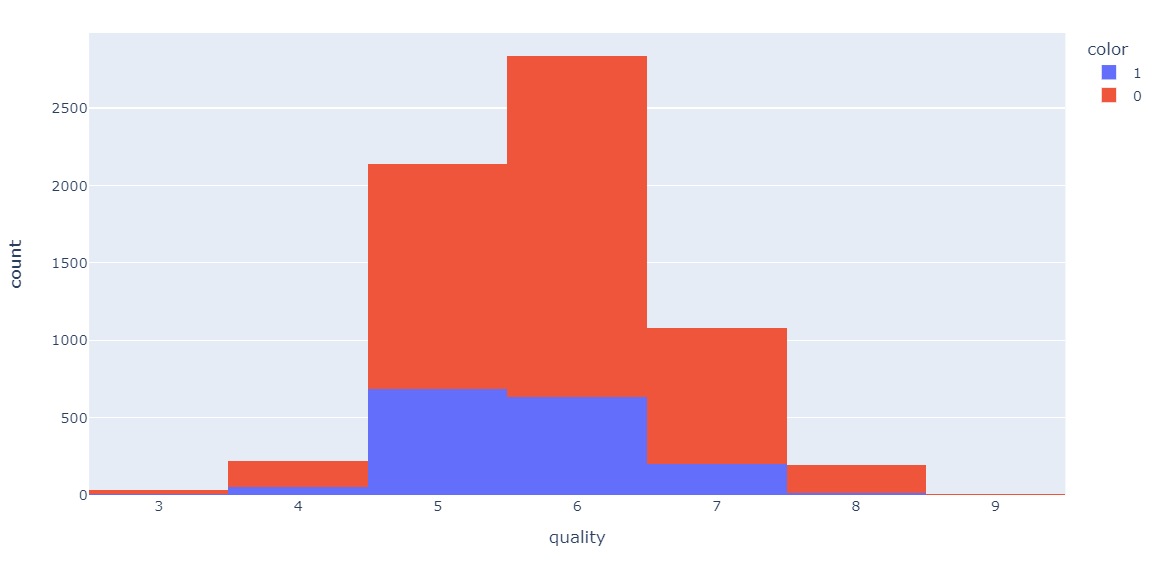
레드와인/화이트와인 별 등급의 분포도 그려보았다.
레드와인은 1, 화이트와인은 0 이다.
전반적으로 화이트와인의 수가 많다.
두 와인 모두 5,6 등급이 가장 많다.
3. 모델 만들기
와인 데이터를 입력했을 때, 이 와인이 레드와인인지 화이트와인인지 분류하는 모델을 만들어보자!
(1) 데이터 분리
from sklearn.model_selection import train_test_split import numpy as np
X = wine.drop(['color'], axis=1) y = wine['color'] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=13)
X는 feature 이므로, color 컬럼을 제외한 모든 컬럼이 해당한다.
y는 분류 대상이므로, color 컬럼만 해당한다.
train과 test는 8대 2의 비율로 나눴다.
train과 test 데이터의 등급별 데이터가 어떻게 나눠졌는지, 히스토그램으로 알아보자.
히스토그램 2개를 같이 그릴때 사용하는plotly.graph_objects 를 사용한다.
import plotly.graph_objects as go
fig = go.Figure() fig.add_trace(go.Histogram(x=X_train['quality'], name="Train")) fig.add_trace(go.Histogram(x=X_test['quality'], name="Test")) fig.update_layout(barmode="overlay") fig.update_traces(opacity=0.75) fig.show()
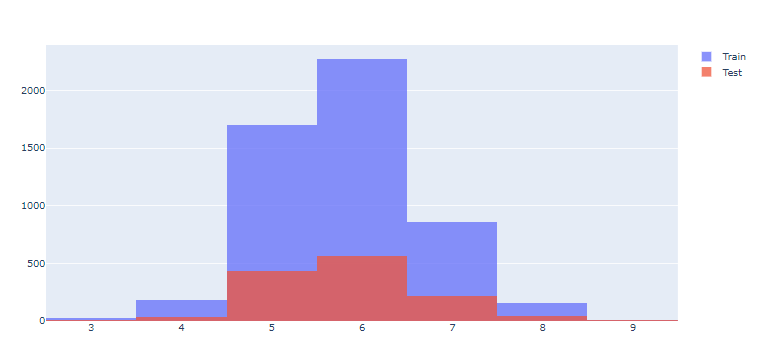
fig.update_layout(barmode="overlay"): 두 그래프를 겹쳐서 그려라
fig.update_traces(opacity=0.75): 히스토그램의 투명도 수정
(2) 모델 만들기
from sklearn.tree import DecisionTreeClassifier
wine_tree = DecisionTreeClassifier(max_depth=2, random_state=13) wine_tree.fit(X_train, y_train)
Decision Tree 모델을 max_depth를 2로 설정하고, train 데이터로 학습시켰다.
from sklearn.metrics import accuracy_score
y_pred_tr = wine_tree.predict(X_train) y_pred_test = wine_tree.predict(X_test) print('Train Acc :', accuracy_score(y_train, y_pred_tr)) print('Test Acc :', accuracy_score(y_test, y_pred_test))
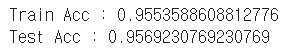
학습한 모델로 train 데이터와 test 데이터를 예측해봤다.
둘다 약 95%의 정확성을 보였다..!!
(3) 모델의 주요 특성 확인
dict(zip(X_train.columns, wine_tree.feature_importances_))

max_depth를 높이면 저 수치가 변한다.
wine_tree = DecisionTreeClassifier(max_depth=4, random_state=13) wine_tree.fit(X_train, y_train) dict(zip(X_train.columns, wine_tree.feature_importances_))

max_depth를 2에서 4로 변경했더니
volatile acidity, density, sulphates의 중요도가 높아진것을 볼수 있다.
4. 데이터 전처리
여기서 잠깐..!
fig = go.Figure() fig.add_trace(go.Box(y=X['fixed acidity'], name="fixed acidity")) fig.add_trace(go.Box(y=X['chlorides'], name="chlorides")) fig.add_trace(go.Box(y=X['quality'], name="quality")) fig.show()
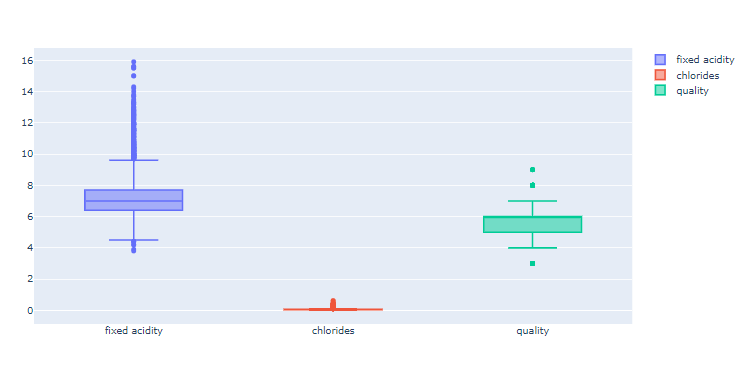
3개 컬럼의 분포를 확인해보니 컬럼들의 최대/최소 범위가 각각 다르고, 평균과 분산이 각각 다르다.
컬럼 간 격차가 심한 경우에는 모델 학습이 제대로 안될 수 있다.
전처리 방법에는 min_max scaler, standard scaler, robust scaler 등이 있는데
이런 경우에는 min_max scaler, standard scaler 를 사용한다.
근데 컬럼 간 격차가 심한 경우 MinMaxScaler 가 효과적일수도 있지만, Desicion Tree에서는 별 차이 없다.
푸항항
일단 둘다 해보자!
MinMaxScaler 와 StandardScaler 중 어떤것이 좋을지는 해봐야 안다!
from sklearn.preprocessing import MinMaxScaler, StandardScaler
mms = MinMaxScaler() ss = StandardScaler() ss.fit(X) mms.fit(X) X_ss = ss.transform(X) X_mms = mms.transform(X) X_ss_pd = pd.DataFrame(X_ss, columns = X.columns) X_mms_pd = pd.DataFrame(X_mms, columns = X.columns)
스케일러를 import 한 후, X(feature) 로 fit(학습) 시킨다.
이후 X를 .transform() 하여 스케일러를 적용한다.
스케일링을 한 X값을 각각 X_ss_pd, X_mms_pd 로 저장했다.
근데 Desicion Tree 에서 이런 전처리는 의미를 갖지 않는다....
주로 Cost Function을 최적화할 때 유효하다.
(1) MinMaxScaler
- 최소값을 0, 최대값을 1 로 맞추는 방법.
fig = go.Figure() fig.add_trace(go.Box(y=X_mms_pd["fixed acidity"], name="fixed acidity")) fig.add_trace(go.Box(y=X_mms_pd["chlorides"], name="chlorides")) fig.add_trace(go.Box(y=X_mms_pd["quality"], name="quality")) fig.show()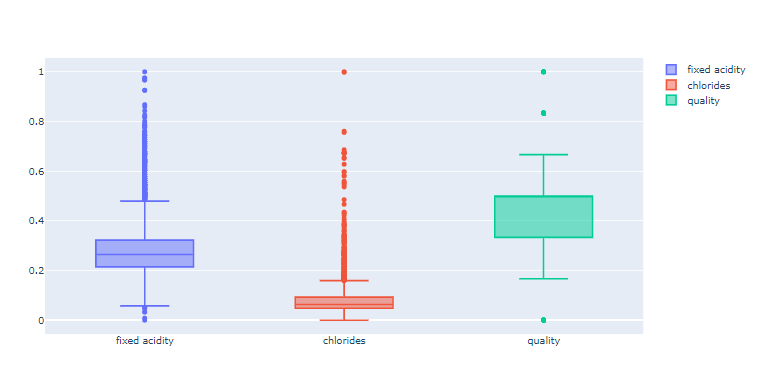
컬럼들의 분포가 좀 비슷해진것 같다!
이제 이 데이터로 다시 모델을 만들어 학습하고, 예측까지 해보자!
X_train, X_test, y_train, y_test = train_test_split(X_mms_pd, y, test_size=0.2, random_state=13) wine_tree_mms = DecisionTreeClassifier(max_depth=2, random_state=13) wine_tree_mms.fit(X_train, y_train) y_pred_tr_mms = wine_tree_mms.predict(X_train) y_pred_test_mms = wine_tree_mms.predict(X_test) print('Train Acc :', accuracy_score(y_train, y_pred_tr_mms)) print('Test Acc :', accuracy_score(y_test, y_pred_test_mms))
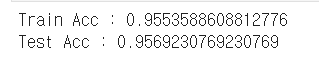
처음 모델과 정확도에 큰 차이가 없다.
역시 Decision Tree에서 MinMax는 큰 의미가 없다..!
(2) StandardScaler
- 평균을 0, 표준편차를 1 로 맞추는 방법.
fig = go.Figure() fig.add_trace(go.Box(y=X_ss_pd["fixed acidity"], name="fixed acidity")) fig.add_trace(go.Box(y=X_ss_pd["chlorides"], name="chlorides")) fig.add_trace(go.Box(y=X_ss_pd["quality"], name="quality")) fig.show()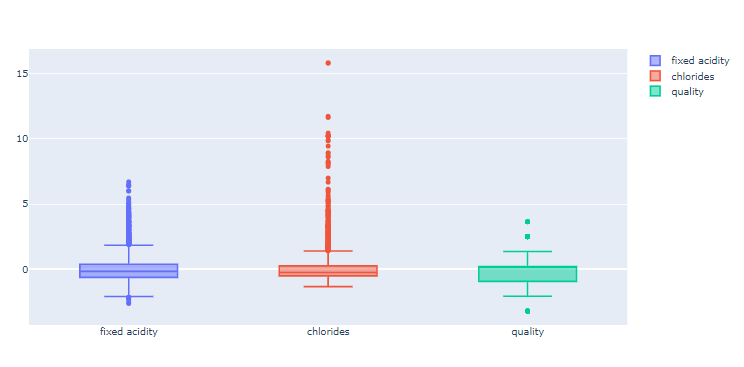
이번에도 이 데이터로 다시 모델을 만들어 학습하고, 예측까지 해보자!
X_train, X_test, y_train, y_test = train_test_split(X_ss_pd, y, test_size=0.2, random_state=13) wine_tree_ss = DecisionTreeClassifier(max_depth=2, random_state=13) wine_tree_ss.fit(X_train, y_train) y_pred_tr_ss = wine_tree_ss.predict(X_train) y_pred_test_ss = wine_tree_ss.predict(X_test) print('Train Acc :', accuracy_score(y_train, y_pred_tr_ss)) print('Test Acc :', accuracy_score(y_test, y_pred_test_ss))
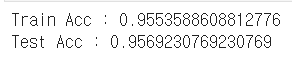
이번에도 정확도에 큰 차이가 없다..
이 방법도 별 효과가 없는듯...!
5. 이진 분류
먼저 quality 컬럼을 이진화 하여 taste 컬럼으로 생성하자.
wine['taste'] = [1. if grade>5 else 0. for grade in wine['quality']] wine.head()
quality 컬럼은 3에서 9사이의 값을 갖는다.
그래서 5보다 크면 taste=1.0 이고 5이하 값이면 taste=0.0 이 되도록 만들었다.
이제 데이터를 train, test로 분리해
taste 컬럼을 예측하는 모델을 만들고, train 데이터로 학습한뒤
train, test 데이터를 모두 예측해보자
X = wine.drop(['taste'], axis=1) y = wine['taste'] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=13) wine_tree_taste = DecisionTreeClassifier(max_depth=2, random_state=13) wine_tree_taste.fit(X_train, y_train) y_pred_tr_taste = wine_tree_taste.predict(X_train) y_pred_test_taste = wine_tree_taste.predict(X_test) print('Train Acc :', accuracy_score(y_train, y_pred_tr_taste)) print('Test Acc :',accuracy_score(y_test, y_pred_test_taste))
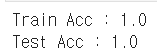
train, test 모두 정확도가 100%...!!
이건 의심해야 한다!!!!!
일단 모델이 어떻게 생겼는지 알아보자!
from sklearn.tree import plot_tree import matplotlib.pyplot as plt
plt.figure(figsize=(12, 8)) plot_tree(wine_tree_taste, feature_names=X.columns);
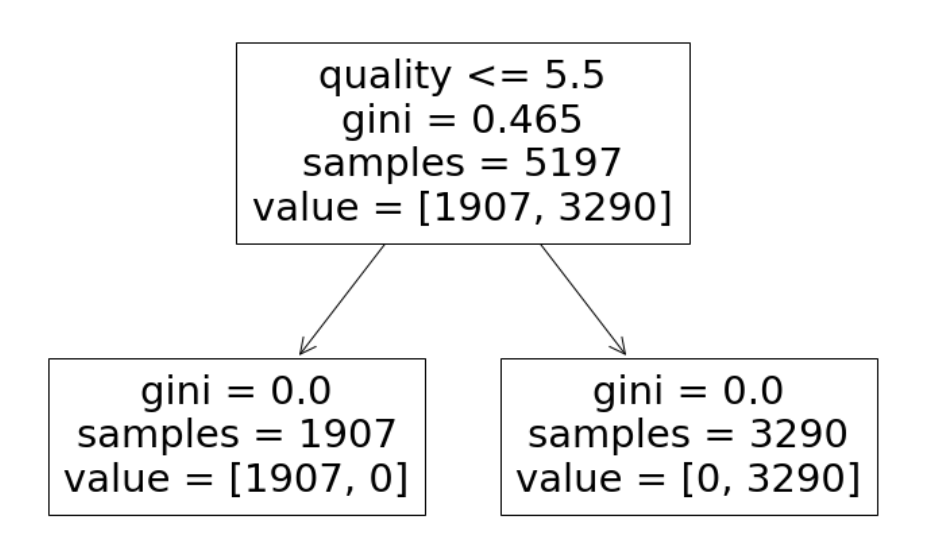
quality 컬럼으로 taste 컬럼을 만들고 지우지 않았다...!
quality 컬럼을 지우고 다시 처음부터 해보자!
X = wine.drop(['taste', 'quality'], axis=1) y = wine['taste'] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=13) wine_tree_taste = DecisionTreeClassifier(max_depth=2, random_state=13) wine_tree_taste.fit(X_train, y_train) y_pred_tr_taste = wine_tree_taste.predict(X_train) y_pred_test_taste = wine_tree_taste.predict(X_test) print('Train Acc :', accuracy_score(y_train, y_pred_tr_taste)) print('Test Acc :',accuracy_score(y_test, y_pred_test_taste))
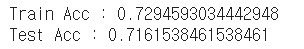
오 이제 좀 정상적인 수치가 나왔다.
혹시 모르니 다시 모델을 확인해보자.
plt.figure(figsize=(12, 8)) plot_tree(wine_tree_taste, feature_names=X.columns, filled=True, rounded=True) plt.show();
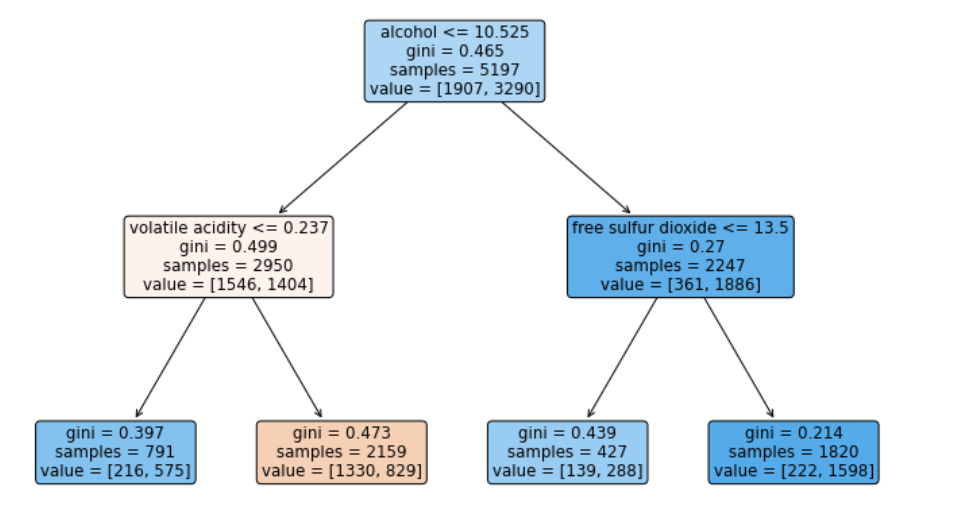
filled=True, rounded=True 옵션을 사용해 가독성을 높여봤당.
alcohol, volatile acidity, free sulfur dioxide 이 3 컬럼이 사용된걸 알수 있다.
