
> SJU-AI-Term Project
본 Kaggle Compete는 비트코인 공식 사이트에서 제공한 여러 데이터를 통해 비트코인 채굴 시 발생하는 Hash rate를 예측하는 Compete입니다.
비트코인이 많은 사람들에게 알려지면서 사회에 미치는 영향도 큽니다. 현재 까지만 해도 비트코인 채굴 시 발생하는 전력 소모로 인해 장기적으로 본다면 지구 환경에 해를 끼칠 수도 있다고 합니다. 또한 미래의 화폐로 인정을 받게 된다면 이 화폐를 사용하여 거래할 시에 딜레이가 없어야 하는데 이것이 현재 시스템에 많은 문제가 되며, 거래에서 가장 중요한 것이라고도 할 수 있으며, 딜레이가 발생하면 '코인 호핑'이라는 공격에도 취약점을 노출 시킬 수 있기 때문에 블록 생성 시간이 빠를 수록 보안도 향상됩니다.
 출처 : https://blockgeeks.com/guides/proof-of-work-vs-proof-of-stake/
출처 : https://blockgeeks.com/guides/proof-of-work-vs-proof-of-stake/
비트코인은 탈중앙화 분산원장을 특징으로 하는 암호화폐로서 POW(proof of work)라는 작업증명 채굴 시스템을 통해 유지됩니다. 이 방식은 해싱 과정을 통해 나온 값이 비트코인에서 지정한 채굴 난이도를 통과했다면 블록이 생성되어 채굴자는 그에 따른 보상을 받게 되는 프로세스입니다. 이 때 해싱 과정은 지정한 난이도의 수학적 문제를 통과할 때 까지 무작위의 Nonce값을 무한이 대입하게 되는데, 이 해시 연산에서 많은 컴퓨팅적 계산 능력이 필요하여 전력 소모가 심각해지는 이유이기도 합니다.
현재까지 이러한 문제점들을 해결하기 위한 실험을 통해 기존 채굴 난이도 조정방식보다 오차율을 약 36%나 더 줄일 수 있는 논문 결과도 존재합니다.
그래서 이러한 비트코인에서 사용하고 있는 채굴 방식인 Pow의 여러 문제점들을 개선하기 위해 채굴 시스템의 중요한 요소인 Hash-rate를 예측하는 문제를 선정했습니다.
데이터 가공과정
해시레이트에 영향을 주는 요인은 여러가지가 있습니다. 그 중 예측에 필요하다 판단된 2018년 11월1일 부터 2021년 10월22일 까지 약 3년간의 데이터들을 블록체인 공식사이트에서 일부 추출하였습니다.
Data List
- train.csv
- Hash rate를 포함한 3년간 기록된 비트코인의 데이터들을 가지고 있습니다.
- test.csv
- Hash rate를 제외한 3년간 기록된 비트코인의 데이터들을 가지고 있습니다.
- submit_sample.csv
- index와 hash-rate로 이루어 져있으며 'hash-rate'에 예측 값을 기재해야합니다.
Datatype Description
- (1열) id : 각 데이터들의 ID값 (int64)
- (1열) Timestamp : 3년간 일 단위의 시간 순서 (object)
- (2열) n-payments-per-block : 블록당 평균 지불 횟수(int64)
- (3열) miners-revenue : 블록 생성시 채굴자에게 주어지는 보상 (float64)
- (4열) trade-volume : 거래량 (float64)
- (5열) avg-bloc-size : 생성되는 평균 블록 사이즈 (float64)
- (6열) n-unique-addresses : 채굴에 참여하는 고유 주소 (float64)
- (7열) difficulty : 채굴 난이도 (int64)
- (8열) hash-rate : 해시 레이트 (float64)
Code
import pandas as pd
import numpy as np
from sklearn.preprocessing import MinMaxScaler
from sklearn.model_selection import train_test_splitpandas와 numpy를 활용하여 데이터를 가공할 예정이며 가공 과정에서 사용될 MinMaxScaler와 split하기 위한 모듈들을 import 시켜 주었습니다.
train = pd.read_csv('./train.csv')
train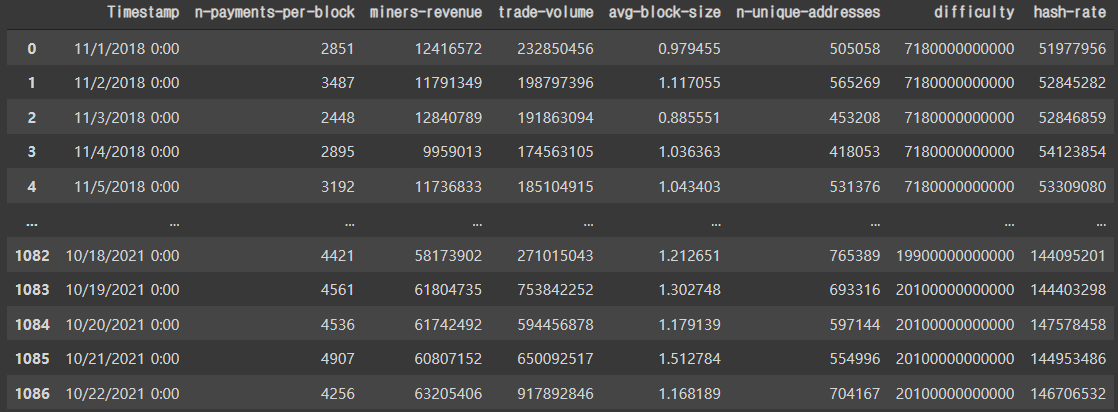
'난이도' 스케일 조정
추출한 데이터를 모아둔 train.csv파일을 읽어드려 출력해보았습니다.
여기서 hashrate와 평균블록 사이즈 외에 모두 정수화를 이미 시켜주었으며 'difficulty'열의 데이터는 너무 큰 숫자이기에 스케일을 조정해줬습니다.
train['difficulty'] = train['difficulty'] / 10000000000
# 10,000,000,000 나누기MinMaxScaler 적용
columns = ['n-payments-per-block', 'miners-revenue', 'trade-volume',
'n-unique-addresses', 'difficulty', 'hash-rate']
# float -> int
for i in columns:
train[i] = train[i].astype('int')
columns = ['miners-revenue', 'trade-volume',
'n-unique-addresses']
sc = MinMaxScaler()
train[columns] = sc.fit_transform(train[columns])
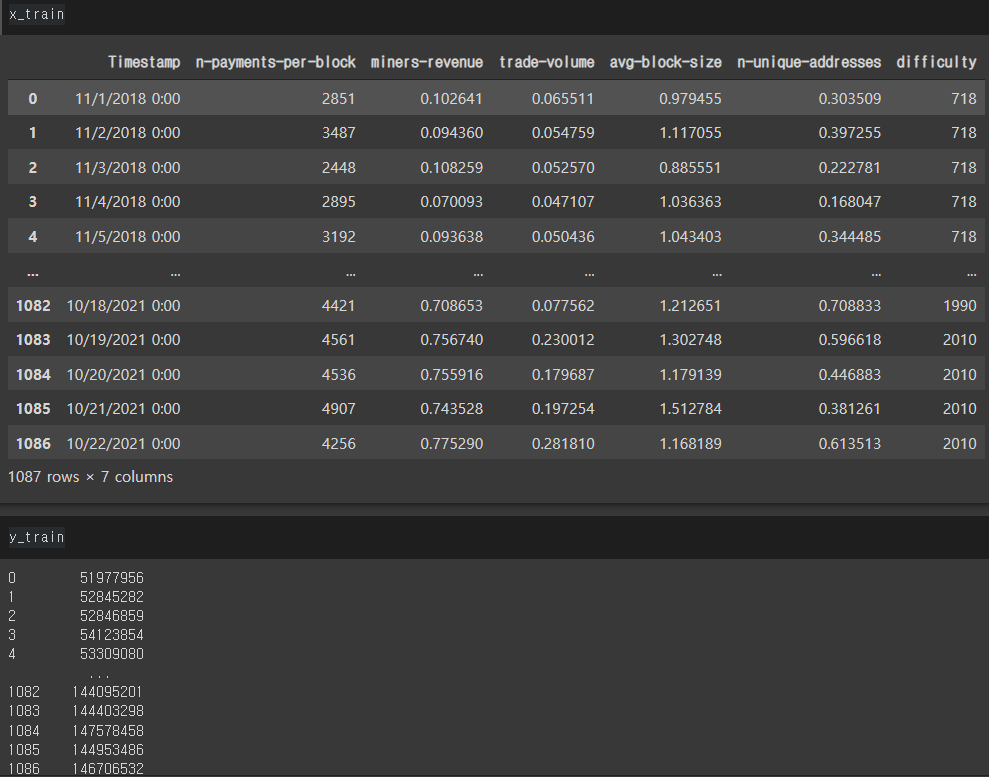
x_train = train.iloc[:,:-1]
y_train = train.iloc[:,-1]스케일 조정후 평균 블록 사이즈 외에 모두 정수화를 다시 시켜주고, 다음 세개의 열에 MinMaxScaler를 적용 시켜주었습니다.
그다음 학습데이터에 사용하기 위해 hash-rate열만 제외한 데이터들 x_train에 담고, y_train에 라벨데이터인 hash-rate를 담아주었습니다.
Dataset Split
스케일이 잘 조정이 된 것을 확인 한후 데이터 셋을 분리해야합니다.
train, test, y_train, y_test = train_test_split(x_train, y_train, test_size=0.2, random_state=42)x_train과 y_train터를 각각 train데이터 0.8, test데이터를 0.2 비율로 Split하고, random_state는 42로 고정시켜주었습니다.
train = pd.concat([train,y_train],axis=1)Label Data 스케일 조정
그 후 섞어서 Split한 데이터중 train과 y_train만 합친 후,
y_test = y_test/1000000
train['hash-rate'] = train['hash-rate']/1000000
train['hash-rate']라벨 데이터를 다시 1000000으로 나눠 스케일을 조정한 후에 다시 집어 넣어 주었습니다.
최종 Dataset 추출
train.to_csv('train.csv',index=True)
test.to_csv('test.csv',index=True)
y_test.to_csv('submit_sample.csv',index=True)Kaggle 대회 데이터에 사용하기 위해 최종적으로 모두 가공된 데이터들을 index를 포함하여 csv파일로 다시 추출하여 주었습니다.
