발표 순서
데이터 선정
1) 문제 인식
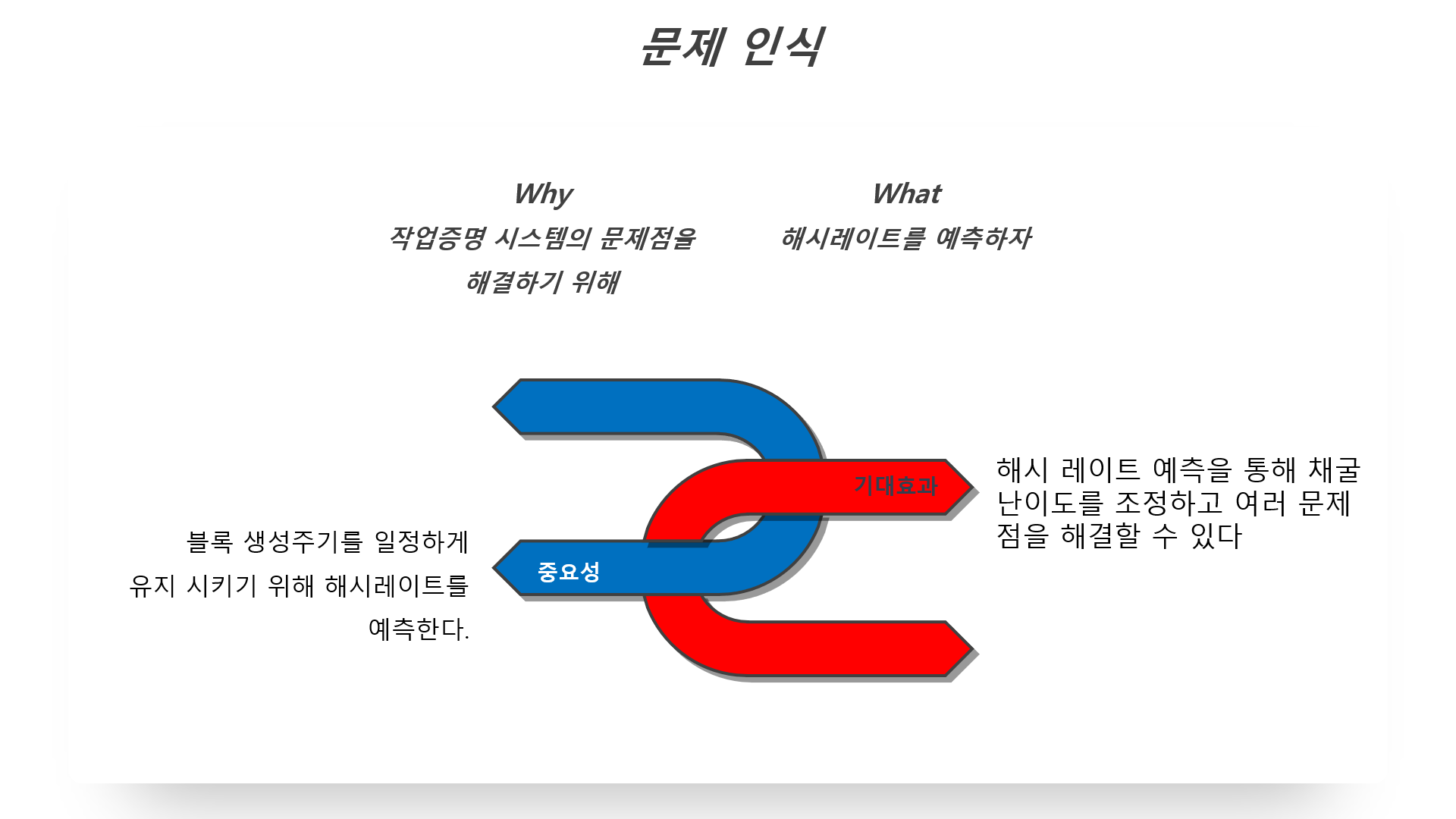
처음으로 인식된 문제에서 작업증명 시스템의 문제점을 해결하기 위해 해시레이트를 예측하자는 결론이 도출됐습니다.
비트코인의 활동 단위인 블록 생성의 실제 시간과 예정 시간 간의 간극을 줄이기 위해서는
채굴에 투입되는 해시파워를 정확히 예측하여 채굴 난이도를 계산하여야 합니다. 채굴 난이도가 예측을 통해 정확히 계산된다면 비트코인 시스템을 통한 거래시 현실 세계의 시간 중심의 스케줄을 따라갈 수 있고, 또한 코인 호핑 공격이라는 공격이 주기적으로 발생하더라도 이를 예측하고 난이도를 조절해 줌으로써 정직한 채굴자들에게 수입을 보장해 주어 채굴 시스템을 안정적으로 유지시켜줄 수 있게 되기에 해시레이트를 예측할 필요성이 있었습니다.
우선 이 ‘해싱’이라는 것에 대해 간략히 설명하겠습니다.
2) 해싱이란?
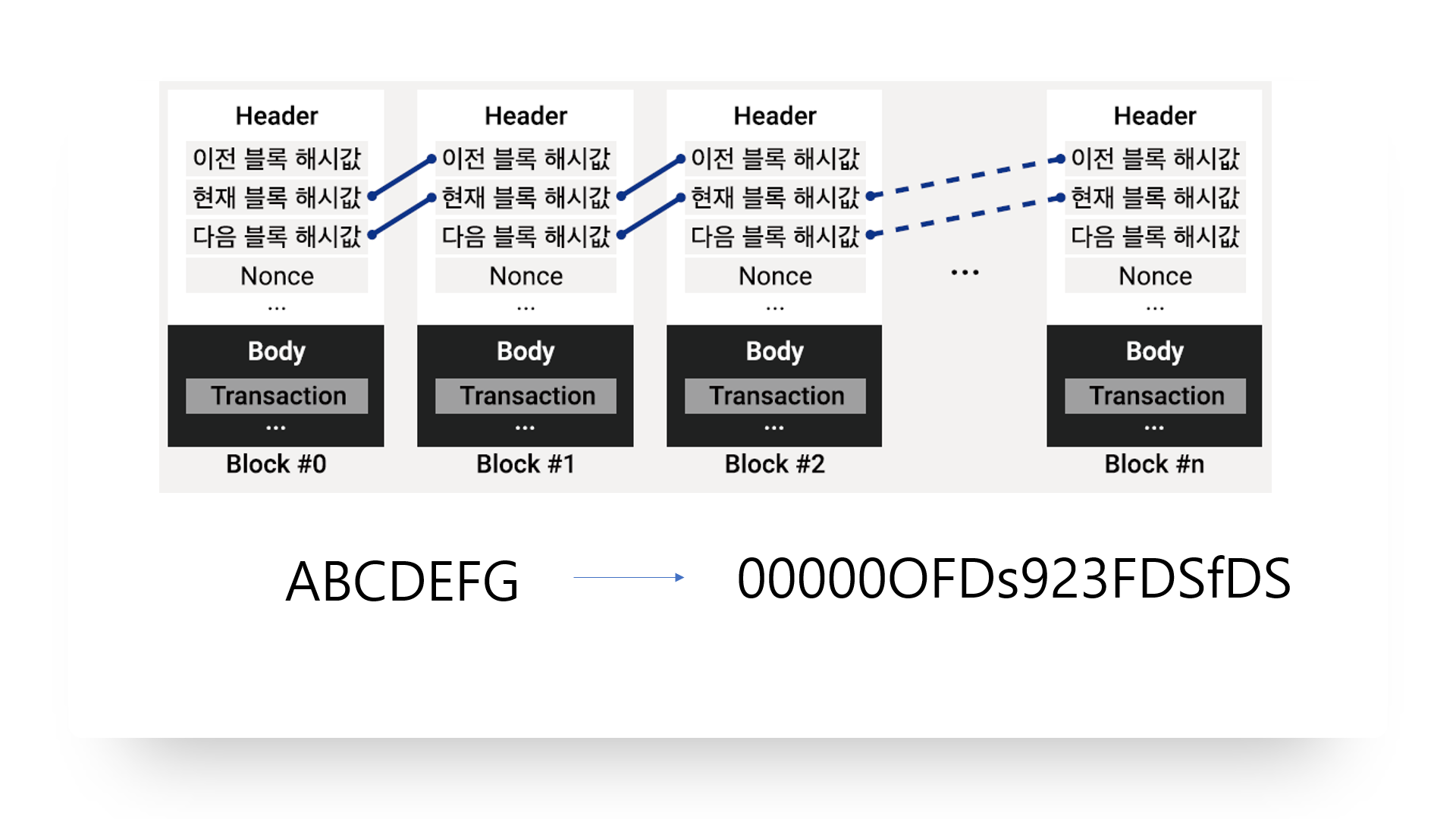
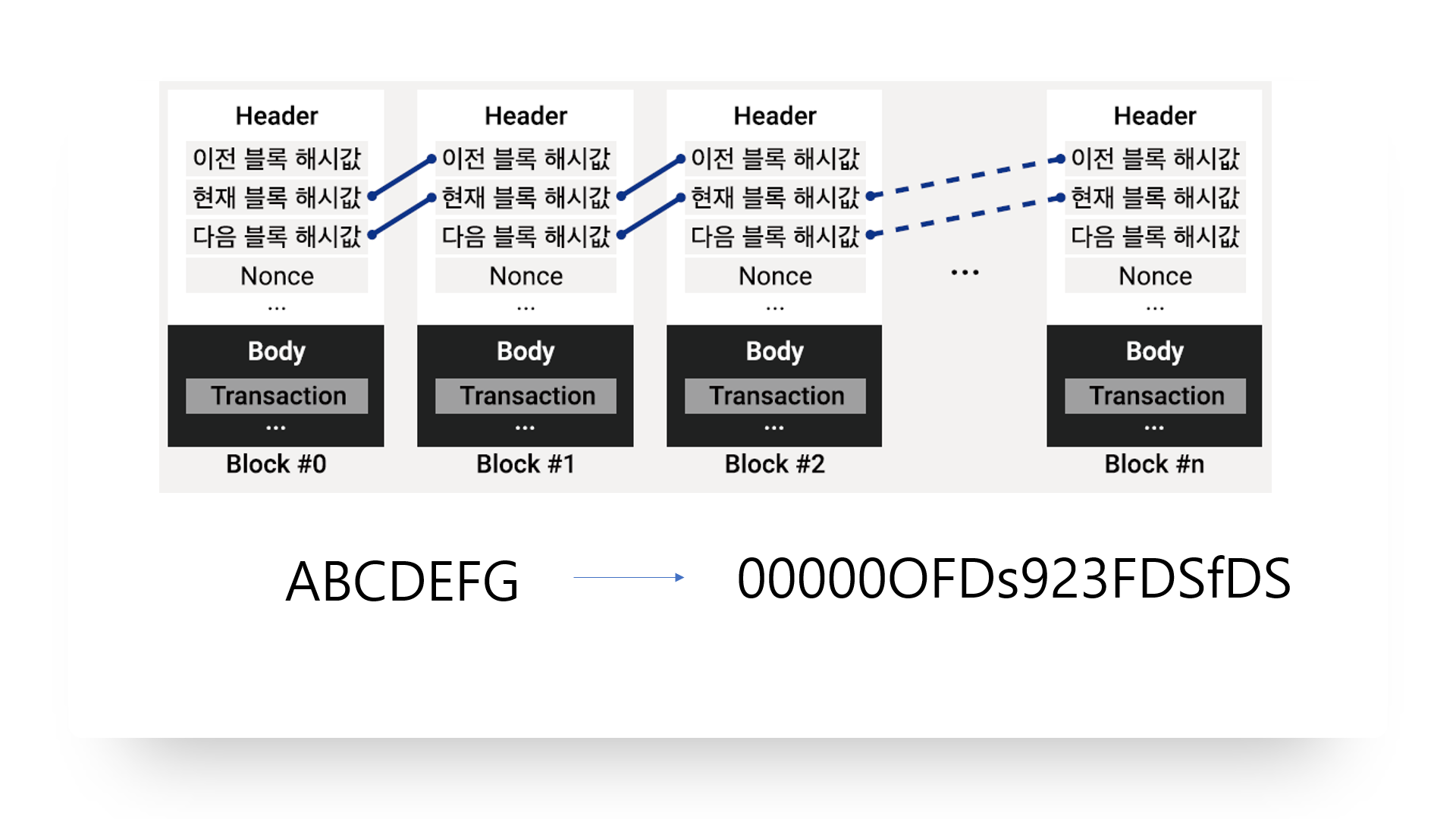
블록체인의 기본 구조는 다음과 같습니다.
얼핏보면 링크드 리스트처럼 생겼습니다. 각 블록들은 자신의 해시값을 가지고 있으며 서로 이전 블록과 다음 블록의 해시값을 동시에 가지며 연결되어 있습니다.
중간에 1번째 블록을 기준으로 봤을 때 자기자신의 해시값과 Nonce값과 그리고 모든 거래정보나 서비스의 정보들이 담겨져있는 바디 부분의 데이터들이 합쳐져서 ABC라는 데이터가 되었다고 가정하겠습니다. 그럼 이 데이터를 해쉬함수에 넣었을 때 나오는 값이 오른쪽에 보이는 이 해시값입니다. 이 해시값이 바로 그다음에 생성될 블록의 해시값으로 등록이 되는 것입니다.
즉 2번째 블록의 헤더부분에 이 해시값이 자기자신의 값으로 등록이 되는 것이죠. 이렇게 끊임없이 나아가 링크드리스트처럼 연결이 됩니다.
여기서 중요한 해쉬함수에 대해 설명하겠습니다.

비트코인은 SHA256해쉬 함수를 사용하고 있습니다.
해쉬함수란 만약 제가 헬로월드를 해쉬함수에 넣었다면 그 결과값은 이렇게 읽을 수 없는 값으로 암호화되어 나오게 됩니다. 해쉬함수는 단방향 함수라고 하는데 헬로월드를 해쉬함수를 거쳐서 암호화된 이런 복잡한 값으로 나올 수 있지만 이 복잡한 값을 다시 헬로월드로 되돌릴수는 없습니다. 때문에 단방향 함수라고 불리웁니다.
또 한가지 특징이 있는데 헬로월드에서 느낌표 단 하나만 붙이고 해쉬함수를 거쳐보겠습니다.
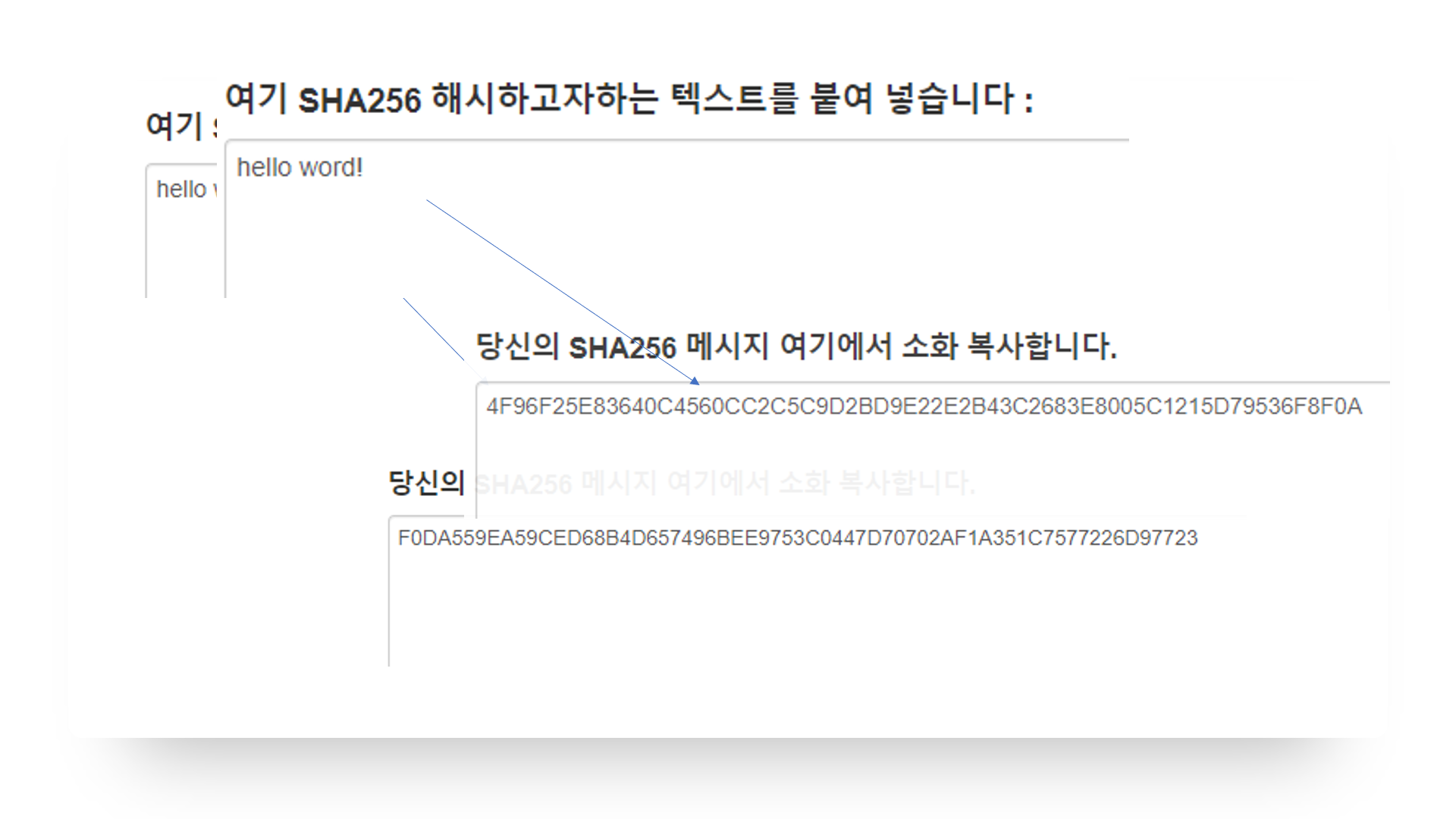
위와 같이 조금만 달라져도 해쉬함수를 거쳐서 나오는 값은 어마어마하게 달라집니다. 이것의 해시함수의 큰 특징입니다.
위와 같이 비트코인은 다음 블록의 해시값을 도출해내기 위해서 Nonce값도 같이 합쳐서 해시함수를 돌린다고 했습니다. 이때 채굴자는 해시값정보와 바디에 있는 정보를 절대 건드릴 수 없습니다. 유일하게 건드릴 수 있는 정보는 Nonce값입니다. 그래서 채굴자는 이 Nonce값을 무작위로 대입하여서 오른쪽에 이처럼 해시값의 앞자리에 0인 수가 일정 개수 이상 나와야지 블록이 생성되고 ,그 블록의 소유권을 가지게 되어 보상을 받게 되는 방식입니다.
위 자료에서는 0이 다섯개 있는데 이것을 채굴 난이도가 5개라고 말합니다. 즉 채굴난이도가 5이면 해시값의 맨 앞에있는 0이 5개가 되도록하는 Nonce값을 구해야만 한다는 것입니다.
직접 그 Nonce값이라는 것을 제가 직접 넣어보겠습니다.

123이라는 무작위 Nonce값을 넣어 해쉬함수를 거치면 이러한 값이 나옵니다.
여기서 난이도가 5라면 앞에 0이 다섯개 나와야하는데 당연히 간단한 Nonce값을 넣어줬으므로 나오지 않겠죠. 비트코인은 이 난이도가 19라고 알고있습니다.
그러니 상상도 할 수 없는 무작위 숫자를 무한히 대입하는 과정이 이루어져서 많은 GPU성능과 전력을 잡아 먹는 주 요인이 바로 이것입니다.
현재까지 이런 방식의 여러 문제점들을 해결하기 위한 실험과 연구 논문들도 조금씩 나오고 있는 중인데요.
이처럼 비트코인에서 사용하고 있는 채굴 방식인 POW의 여러 문제점들을 개선하기 위해서 채굴 시스템의 중요한 요소인 Hashrate를 예측하는 문제를 선정하게 됐습니다.
데이터 수집
비트코인 시스템은 다수의 채굴자들이 데이터를 주고 받으면서 동일한 블록체인을 유지해야 합니다. 이를 위해서 외적요소가 아닌 블록체인 내의 데이터를 기반으로 채굴난이도가 계산되고 검증되어야 하는데요. 본 프로젝트에서 채굴난이도 예측을 위해 사용하는 데이터는 비트코인 블록체인 내의 데이터로 한정했습니다.
비트코인은 2009년 1월 처음 발행된 이후 지속적으로 채굴이 진행되고 있는데요. 발행 초기 단계에는 기계학습을 위한 데이터로 적합하지 않다고 판단되어서, 2018년 11월 1일부터 2021년 10월 22일 까지 약 3년간의 데이터들만 추출하여 사용했습니다.
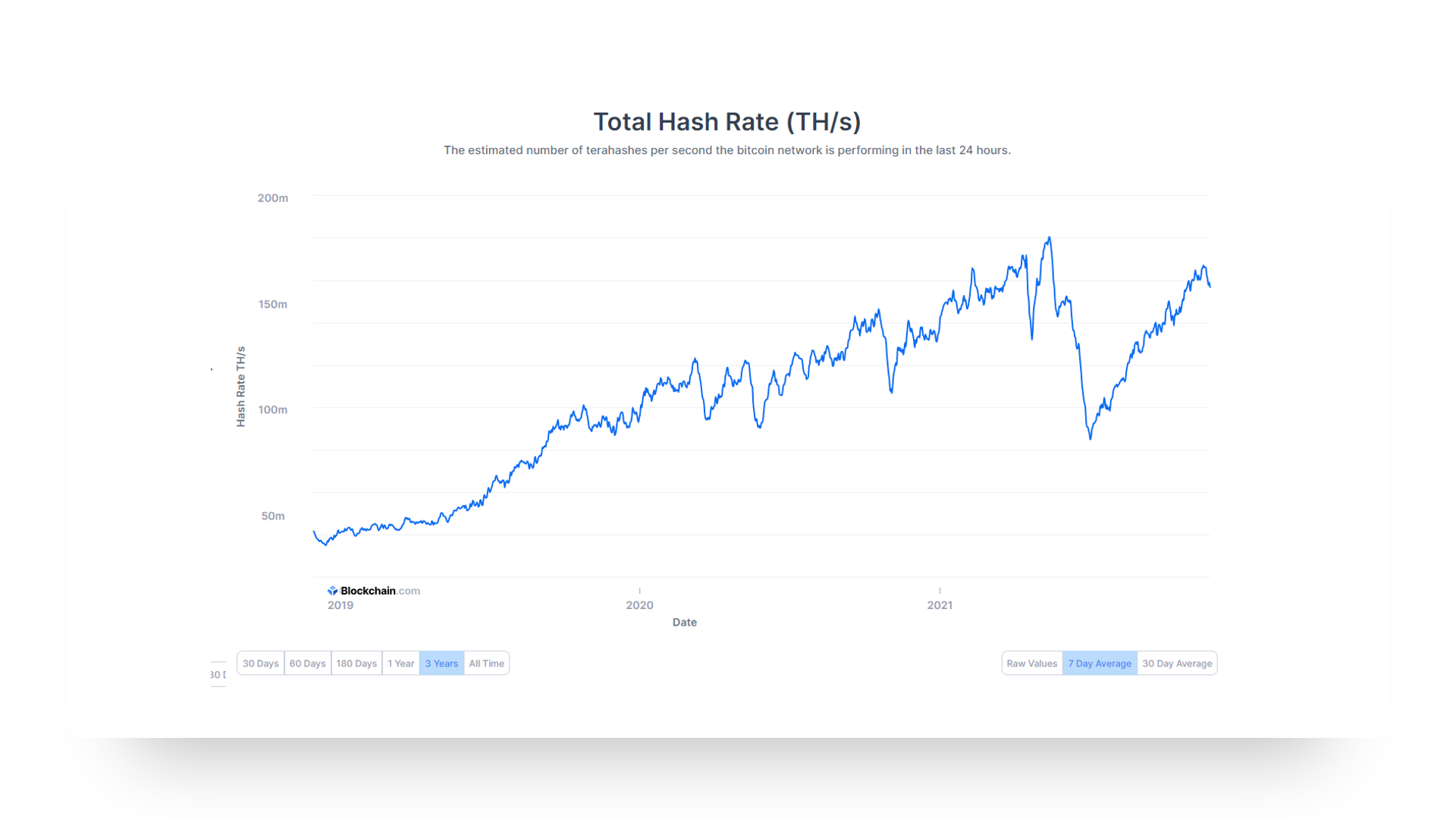
블록체인 공식사이트에는 여러 데이터 들이 있는데 그중에서 난이도와 같은 데이터도 제공하고 있으며 라벨링에 쓰일 해시레이트 데이터들도 모두 위와 같이 제공하고 있습니다.
데이터 가공

데이터 가공은 공식 블록체인 사이트에서 여기에 있는 모든 데이터들의 데이터 페이지에 들어가 각각 다운로드 받은 후 모두 합쳐주고 채굴 난이도와 블록당 지불횟수를 정수화 시켜 가공을 진행시켜주었습니다.
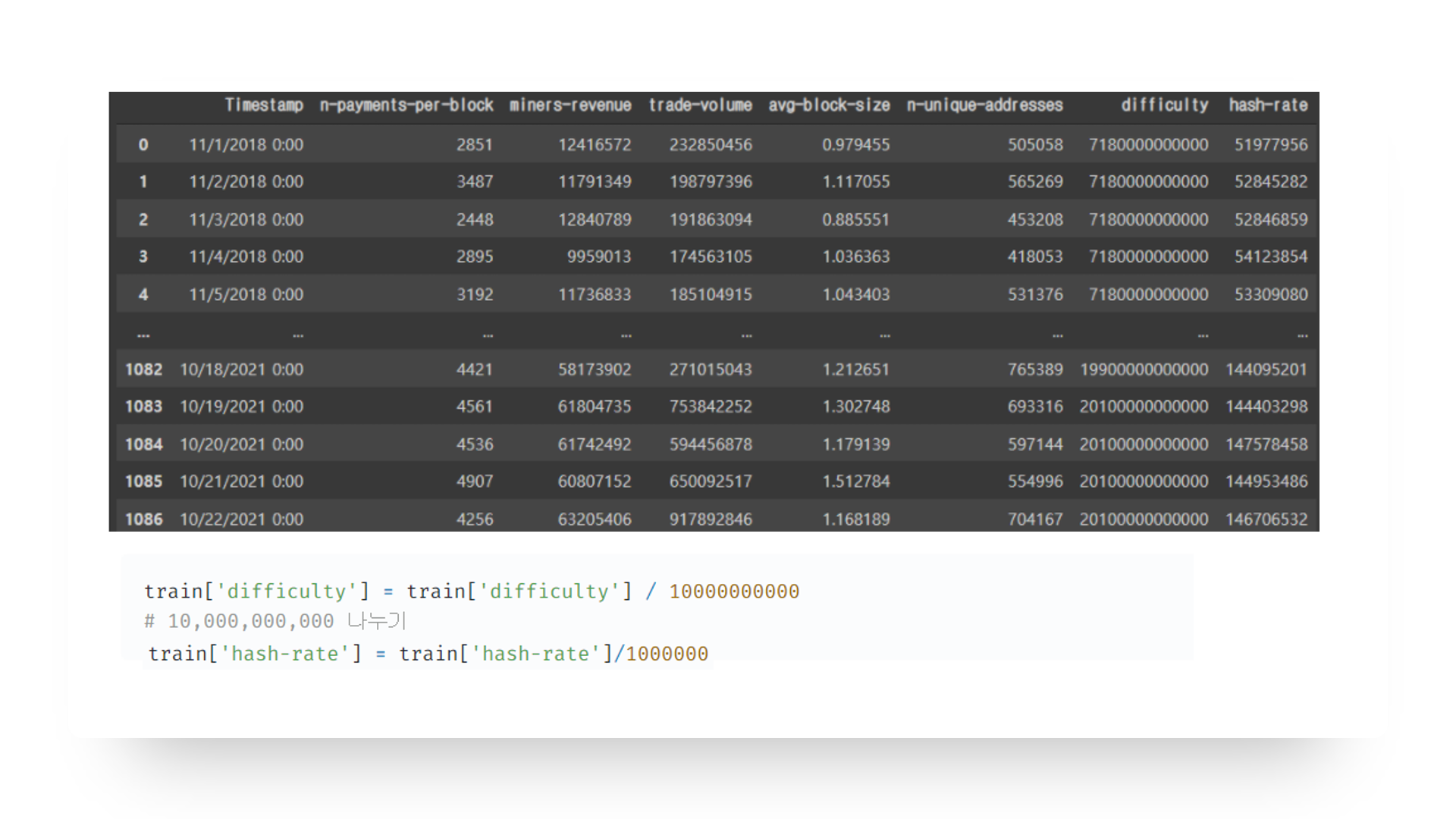
난이도와 해시레이트의 스케일이 매우 큰 것을 확인하여 난이도는 맨 앞자리의 3~4 자리 외에는 의미가 없다고 판단되어 특정 수로 나누어 주어 스케일을 조정하였습니다. 해시 레이트도 동일하게 스케일을 조정해 마쳤습니다.
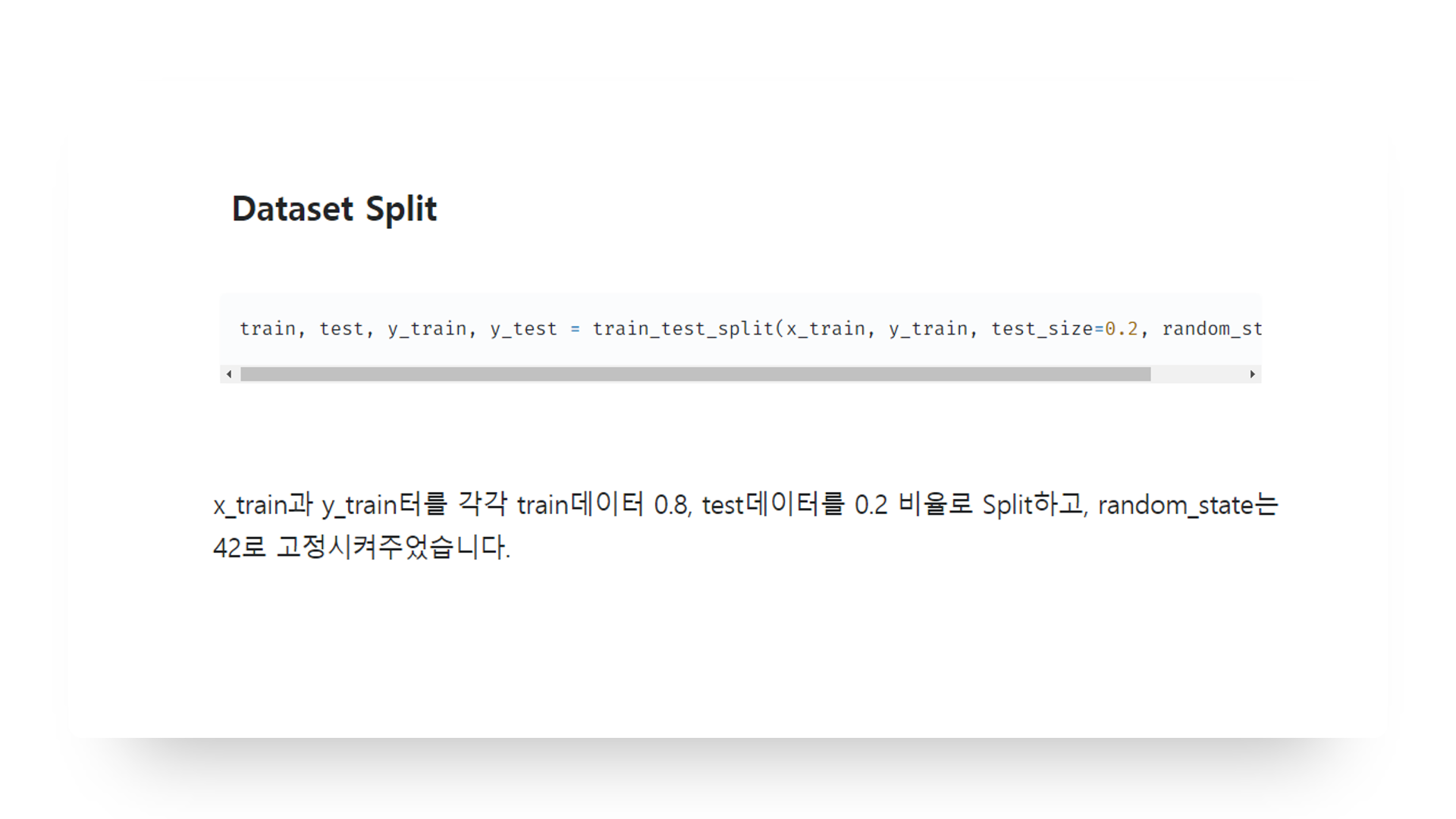
스플릿은 train셋과 test셋을 8대2 비율로 나누어 주어 사용했습니다.
베이스라인 설정
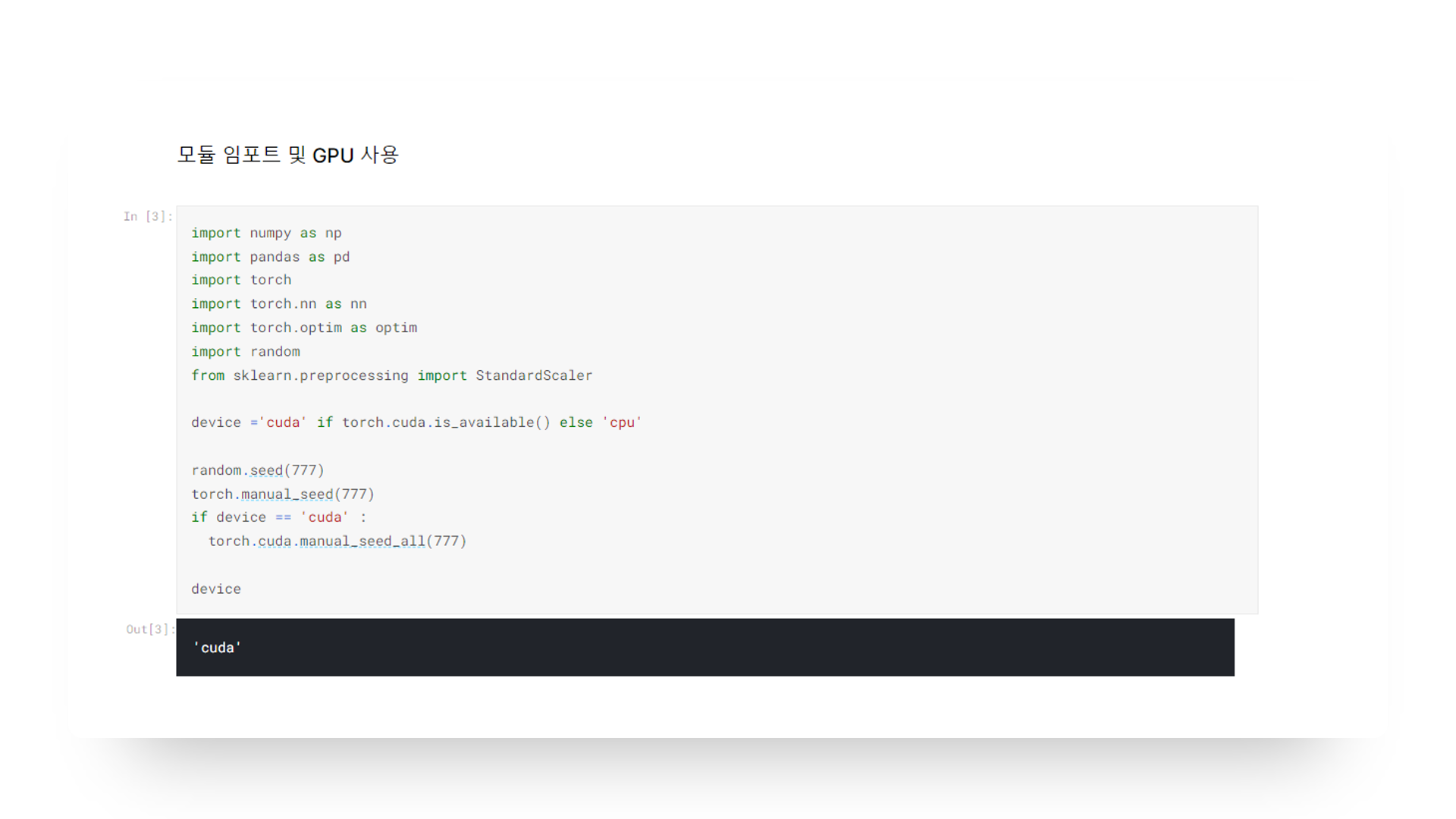
모든 실습과정과 동일하게 GPU를 사용하기 위해서 cuda를 디바이스에 넣어주고 시드를 모두 고정시켜 주고 시작하였습니다.
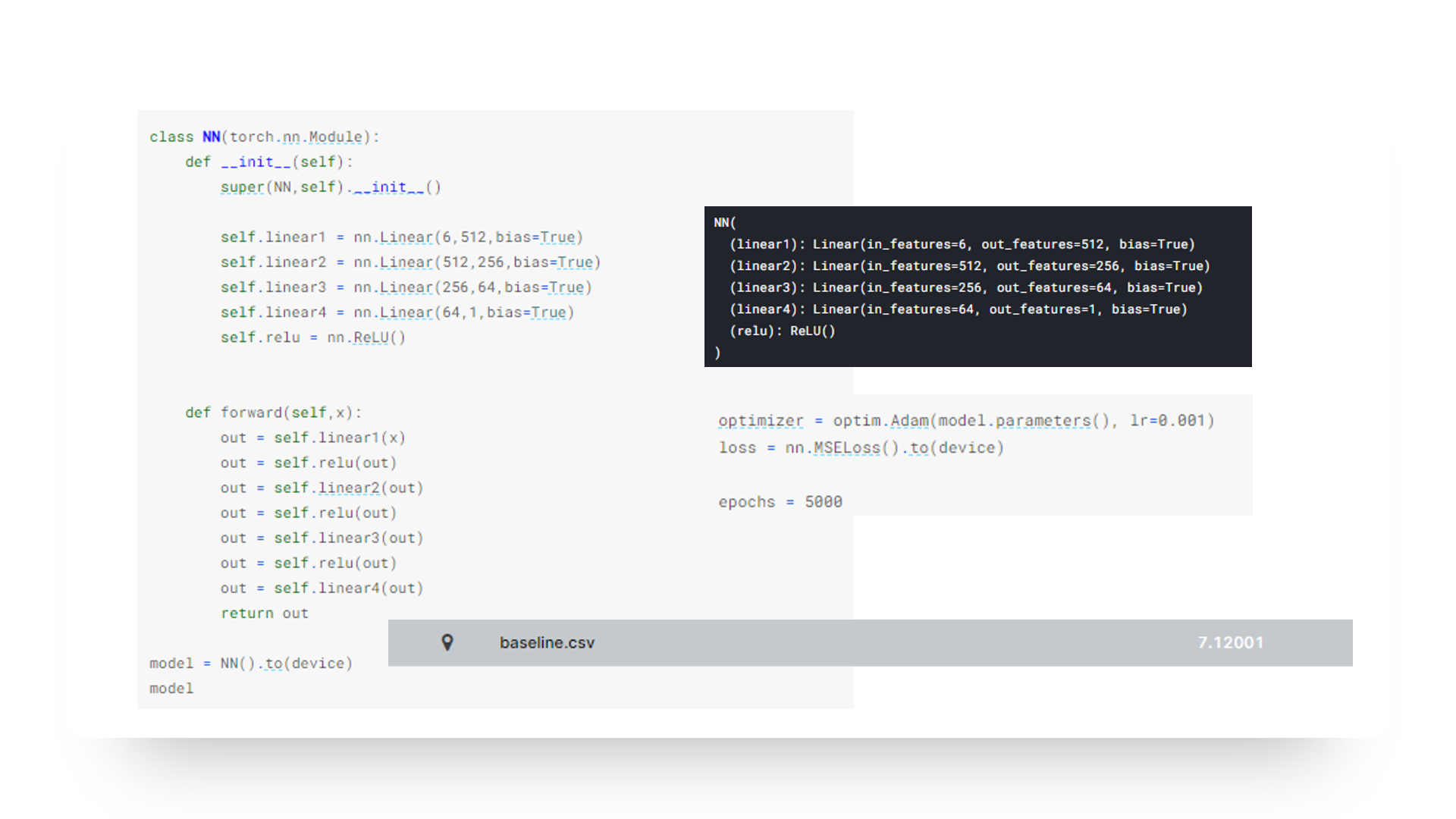
제가 설정한 모델은 위와 같습니다.
4개의 레이어를 겹쳐 쌓았으며 512부터 줄어드는 패턴으로 히든레이어를 설계하였습니다. 또한 활성화함수는 ReLU방식을 사용하여 주었구요. 옵티마저는 Adam을 사용하고, 회귀 문제이기 때문에 로스는 MSELoss를 사용하여 에포크를 5000번 돌렸습니다.
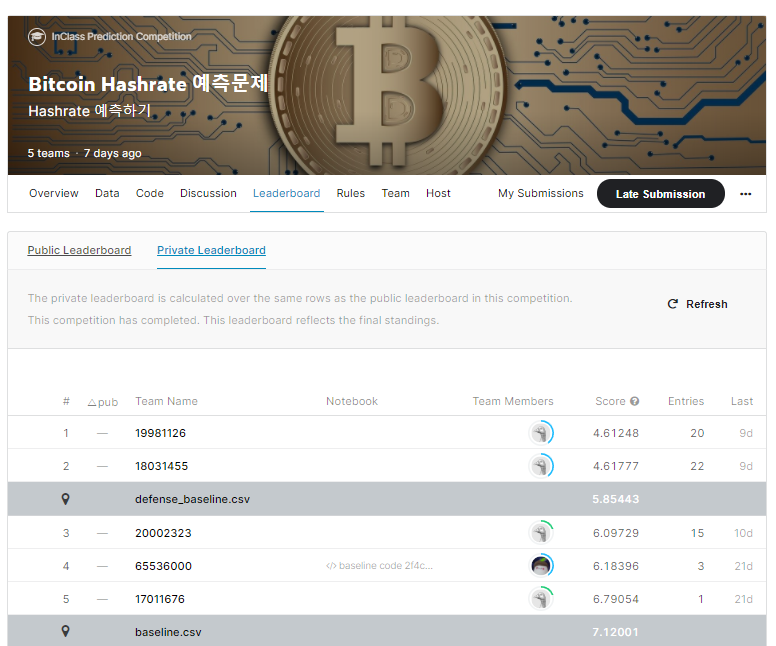
그랬을 때 baseline은 RMSE평가방식을 통한 점수인 7.12001이 나왔습니다.