final_attack_17011806(Bitcoin-hashrate)
# This Python 3 environment comes with many helpful analytics libraries installed
# It is defined by the kaggle/python Docker image: https://github.com/kaggle/docker-python
# For example, here's several helpful packages to load
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the read-only "../input/" directory
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname, _, filenames in os.walk('/kaggle/input'):
for filename in filenames:
print(os.path.join(dirname, filename))
# You can write up to 20GB to the current directory (/kaggle/working/) that gets preserved as output when you create a version using "Save & Run All"
# You can also write temporary files to /kaggle/temp/, but they won't be saved outside of the current session
데이터 로드
train = pd.read_csv('/kaggle/input/sejongai-hashrate/train.csv')
test = pd.read_csv('/kaggle/input/sejongai-hashrate/test.csv')
sample = pd.read_csv('/kaggle/input/sejongai-hashrate/submit_sample.csv')모듈 임포트 및 GPU 사용
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
import torch.optim as optim
import random
from sklearn.preprocessing import StandardScaler
device ='cuda' if torch.cuda.is_available() else 'cpu'
random.seed(777)
torch.manual_seed(777)
if device == 'cuda' :
torch.cuda.manual_seed_all(777)
device데이터 파싱
x_train = train.iloc[:,1:-1]
# year
x_train['Timestamp'].str.split(' ').str[0].str.split('/').str[2].astype(int)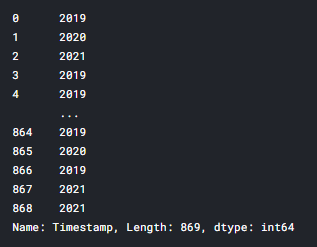
# month
x_train['Timestamp'].str.split('/').str[0].astype(int)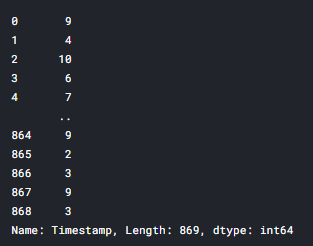
# date
x_train['Timestamp'].str.split(' ').str[0].str.split('/').str[1].astype(int)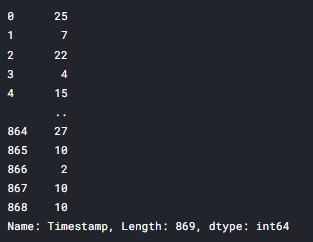
x_train['month'] = x_train['Timestamp'].str.split('/').str[0].astype(int)
x_test = test.iloc[:,1:]
x_test['month'] = x_test['Timestamp'].str.split('/').str[0].astype(int)
y_train = train.iloc[:,-1]
x_train['year'] = x_train['Timestamp'].str.split(' ').str[0].str.split('/').str[2].astype(int)
x_test['year'] = x_test['Timestamp'].str.split(' ').str[0].str.split('/').str[2].astype(int)
x_train['date'] = x_train['Timestamp'].str.split(' ').str[0].str.split('/').str[1].astype(int)
x_test['date'] = x_test['Timestamp'].str.split(' ').str[0].str.split('/').str[1].astype(int)
x_train = x_train.drop(['Timestamp'],axis=1)
x_test = x_test.drop(['Timestamp'],axis=1)
# x_train = x_train.drop(['n-unique-addresses'], axis=1)
# x_test = x_test.drop(['n-unique-addresses'], axis=1)
sc = StandardScaler()
x_train = sc.fit_transform(x_train)
x_test = sc.transform(x_test)
x_train = torch.FloatTensor(x_train).to(device)
x_test = torch.FloatTensor(x_test).to(device)
y_train = torch.FloatTensor(y_train).reshape(-1,1).to(device)데이터 확인
# train data
print(x_train[:5])
print(x_train.shape)
print(y_train[:5])
print(y_train.shape)
# test data
print(x_test[:3])
모델 정의
class NN(torch.nn.Module):
def __init__(self):
super(NN,self).__init__()
self.linear1 = nn.Linear(9,512,bias=True)
self.linear2 = nn.Linear(512,256,bias=True)
self.linear3 = nn.Linear(256,512,bias=True)
self.linear4 = nn.Linear(512,64,bias=True)
self.linear5 = nn.Linear(64,32,bias=True)
self.linear6 = nn.Linear(32,1,bias=True)
self.relu = nn.ReLU()
torch.nn.init.orthogonal_(self.linear1.weight)
torch.nn.init.orthogonal_(self.linear2.weight)
torch.nn.init.orthogonal_(self.linear3.weight)
torch.nn.init.orthogonal_(self.linear4.weight)
torch.nn.init.orthogonal_(self.linear5.weight)
torch.nn.init.orthogonal_(self.linear6.weight)
def forward(self,x):
out = self.linear1(x)
out = self.relu(out)
out = self.linear2(out)
out = self.relu(out)
out = self.linear3(out)
out = self.relu(out)
out = self.linear4(out)
out = self.relu(out)
out = self.linear5(out)
out = self.relu(out)
out = self.linear6(out)
return out학습 파라미터 설정
model = NN().to(device)
optimizer = optim.Adam(model.parameters(), lr=15e-5)
loss = nn.MSELoss().to(device)
epochs = 1700
model
모델 학습
model.train()
plt_los = []
train_total_batch = len(x_train)
for epoch in range(epochs+1) :
avg_cost = 0
model.train()
hypothesis = model(x_train)
cost = loss(hypothesis,y_train)
optimizer.zero_grad()
cost.backward()
optimizer.step()
avg_cost += cost / train_total_batch
plt_los.append([avg_cost.item()])
if epoch%100==0:
print('Epoch : {}, Cost : {}'.format(epoch, avg_cost.item()))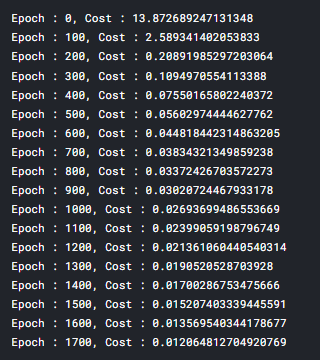
Plot
import matplotlib.pyplot as plt
def plot(loss_list: list, ylim=None, title=None) -> None:
bn = [i[0] for i in loss_list]
plt.figure(figsize=(10, 10))
plt.plot(bn, label='avg_cost')
if ylim:
plt.ylim(ylim)
if title:
plt.title(title)
plt.legend()
plt.grid('on')
plt.show()
plot(plt_los , [0.0, 1.0], title='Loss at Epoch')
print(avg_cost.item())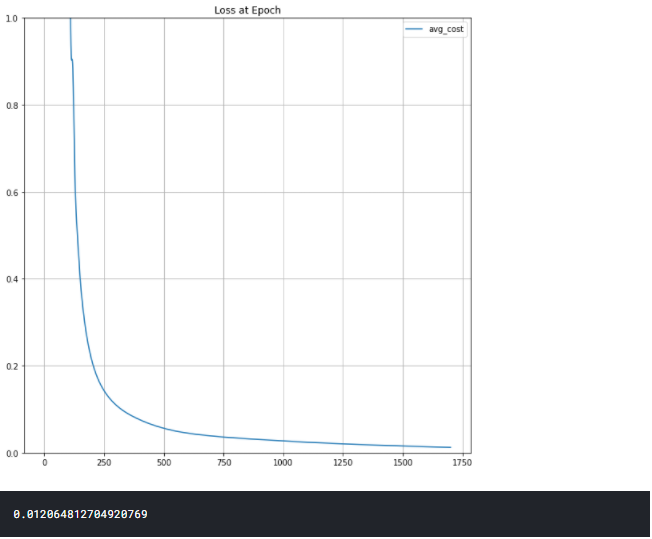
예측 값 도출 및 제출
model.eval()
with torch.no_grad():
y_pred = model(x_test)
sample['hash-rate'] = y_pred.cpu().numpy()
sample.to_csv('submit_sample.csv',index=False)
sample
리더보드 결과
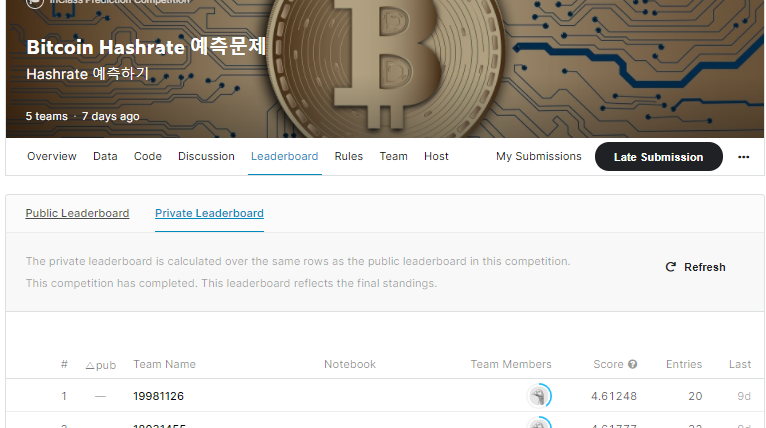
본 코드는 리더보드에서 가장 높은 성능을 보이는 코드입니다.

✏️세상의 모든 기록 ✏️