
- 전체보기(35)
- 누구나 자료구조와 알고리즘(11)
- 자료구조(8)
- 알고리즘(8)
- 회고(4)
- Epson Challenge(3)
- next.js(3)
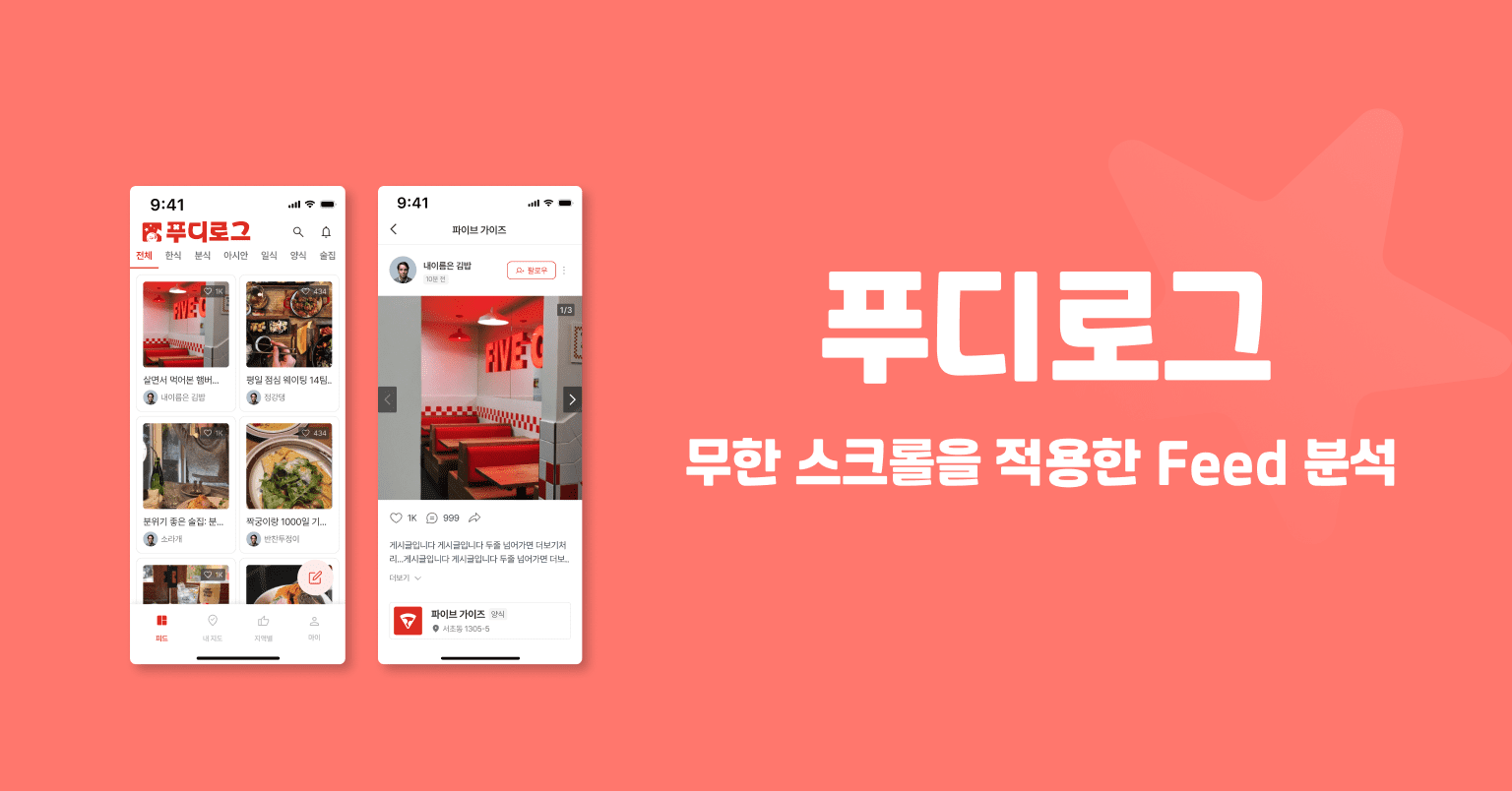
- 푸디로그(2)
- 재귀함수(2)
- 클린아키텍처(2)
- tanstack-query(2)
- airbnb 코드 컨벤션(1)
- 팀 빌딩(1)
- Dependency-Cruiser(1)
- 네트워킹(1)
- S3(1)
- bundle-analyze(1)
- 무한스크롤(1)
- 개발(1)
- imagemin(1)
- google play store(1)
- Performance(1)
- 해시테이블(1)
- route53(1)
- react-route-dom(1)
- 브라우저 랜더링(1)
- server component(1)
- loader(1)
- 사이드프로젝트(1)
- 타입스크립트(1)
- useLoaderData(1)
- ESLint(1)
- Prettier(1)
- 안드로이드 앱(1)
- lighthouse(1)
- 2024 Epson Challenge(1)
- Lazy loading(1)
- 멘토링(1)
- 연결리스트(1)
- DOM(1)
- 자료구조와 알고리즘(1)
- 테스트코드(1)
- 퀵정렬(1)
- MSW(1)
- repaint()(1)
- 데모데이(1)
- 이진 탐색 트리(1)
- 삽입정렬(1)
- jest(1)
- aws(1)
- github(1)
- bundle(1)
- CSSOM(1)
- 이미지 최적화(1)
- 의존성(1)
- 빅오표기법(1)
- reflow(1)
- useRouteLoaderData(1)
- pwa(1)
- git(1)
- cloudfront(1)
- 최적화(1)
- 맛집SNS(1)
- API(1)


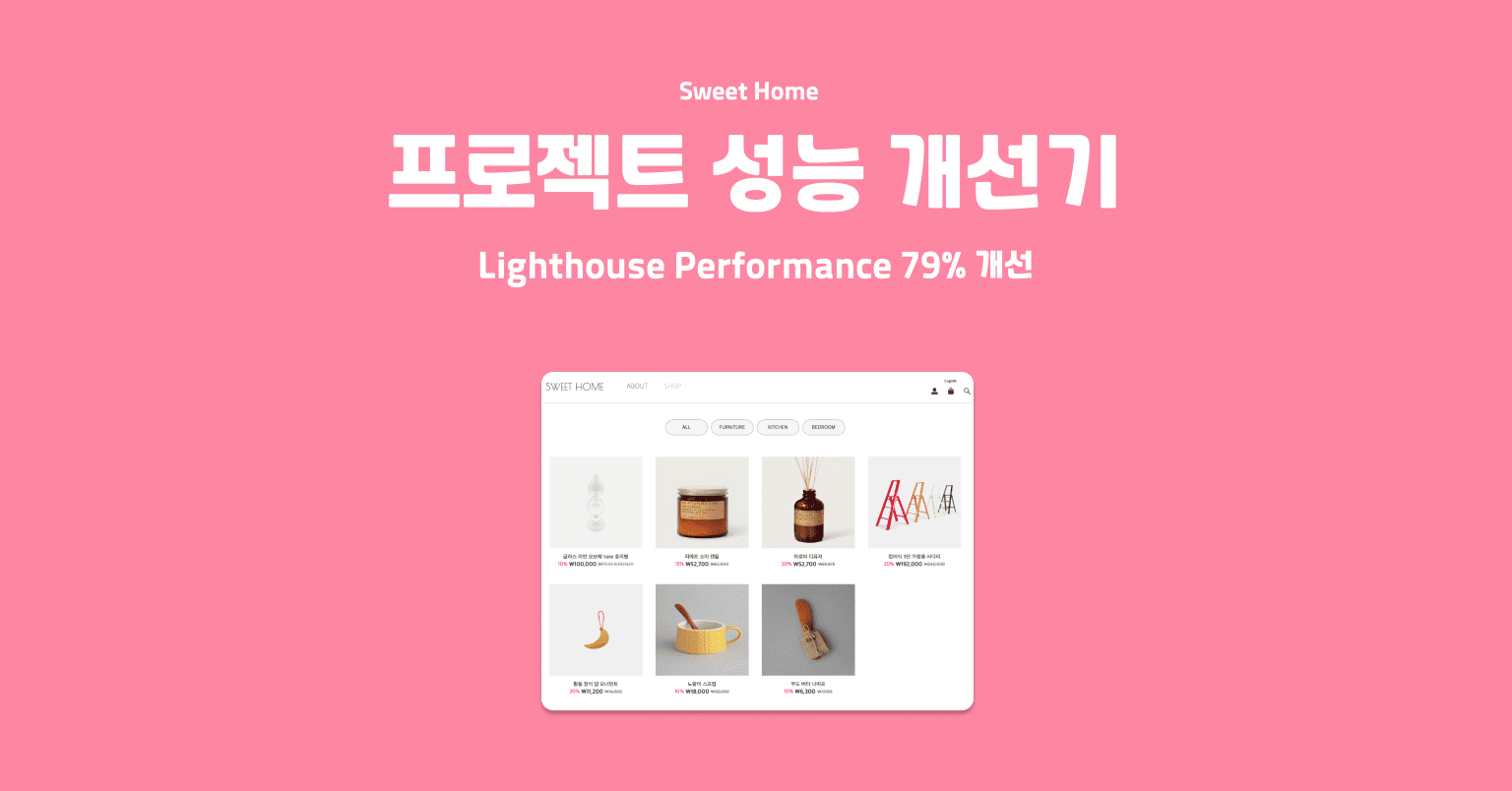



[2024 Epson Challenge] 회고(3): 개발과 기술 멘토링
2024 Epson Innovation Challenge in Korea 도전기

[2024 Epson Challenge] 회고 (2): API 교육과 네트워킹 데이
2024 Epson Innovation Challenge in Korea 도전기

[2024 Epson Challenge] 회고(1): 팀 빌딩 및 기획서 제출
2024 Epson Innovation Challenge in Korea 도전기

[알고리즘과 자료구조] 이진 탐색 트리 알아보기
데이터를 특정 순서로 정리할 때, 가장 효율적인 알고리즘은 무엇일까? 정렬 알고리즘은 아무리 빨라도 O(logN)이다. 정렬된 배열에선 삽입과 삭제할 때 O(N)이 걸린다. 해시 테이블은 검색, 삽입, 삭제가 O(1)이지만, 순서를 유지하지 못한다.순서를 유지하면서 빠

[알고리즘와 자료구조] 노드 기반 자료 구조
\*\*연결 리스트(Linked List)항목의 리스트를 표현하는 자료 구조연결 리스트는 배열과 다르게 동작한다. 연결 리스트 내 데이터는 연속된 메모리 블록이 아니라 컴퓨터 메모리 전체에 걸쳐 여러 셀에 퍼져 있을 수 있다. 메모리에 곳곳에 흩어진 연결되니 데이터는

[푸디로그] Google Play Store에 PWA앱 등록하기
사이드 프로젝트로 진행했던 **푸디로그 앱**을 실제 사용자에게 제공하고 피드백을 받아 앱을 개선해보기 위해서 Google Play Store에 프로덕션 신청을 해보았다.

[알고리즘과 자료구조] 퀵 정렬에 대해 알아보기
실제 배열을 정렬할 때 버블 정렬과 선택 정렬, 삽입 정렬은 잘 사용하지 않는다. 컴퓨터 언어의 내장 함수를 사용해 시간과 노력을 아껴준다. 그 중 퀵 정렬(Quicksort)은 정렬 알고리즘으로 많이 쓰인다. 퀵 정렬 동작 방식을 통해 재귀가 어떻게 알고리즘의 속도를
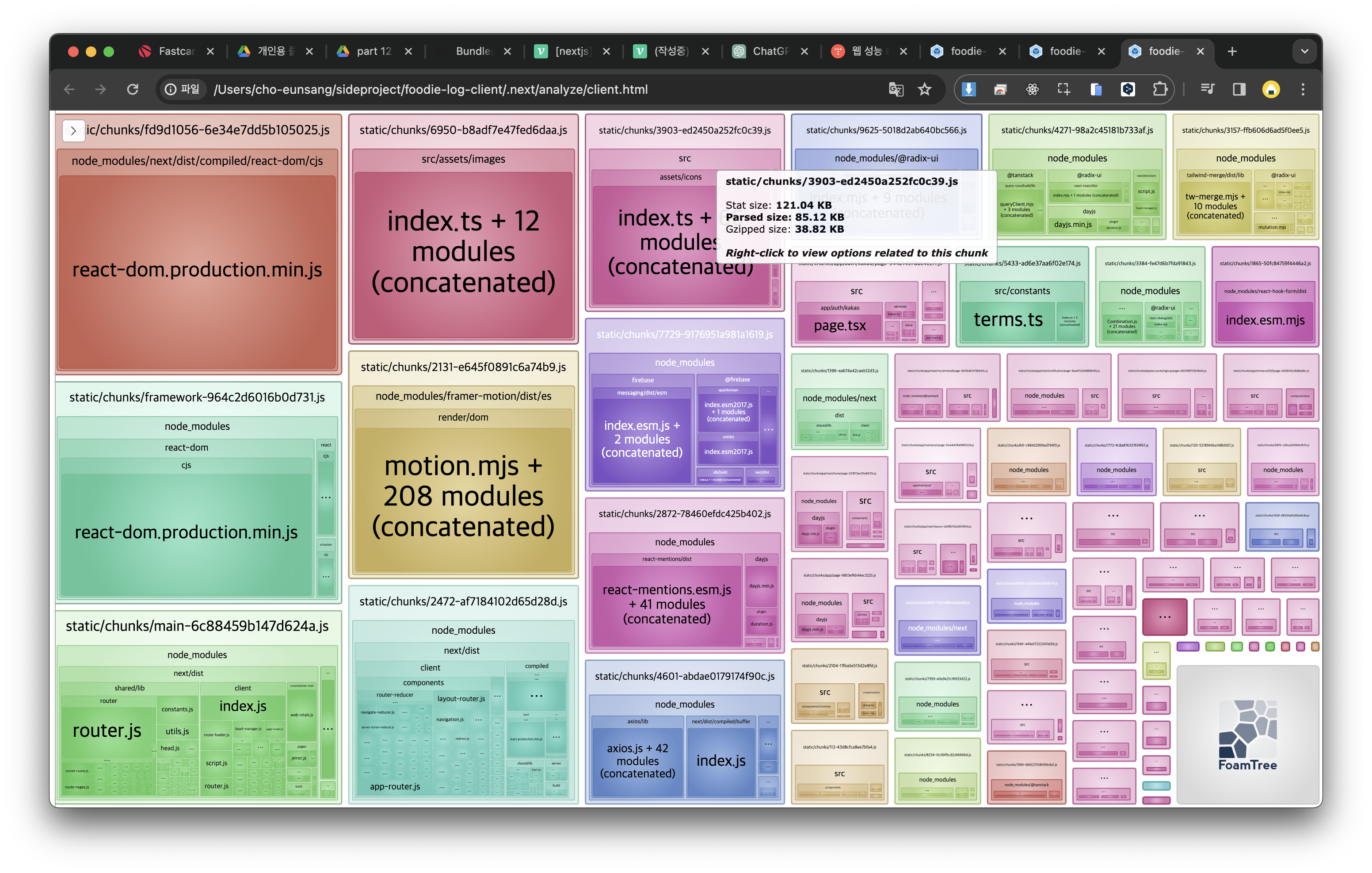

실제 프로젝트에 적용해본 클린 아키텍쳐에 따르는 구조화
클린 아키텍처를 적용하면서 의존성을 관리하는 것은 애플리케이션의 유지보수성, 확장성 및 독립성을 향상시킬 수 있습니다. 실제 프로젝트에 적용한 내용을 바탕으로 dependency-cruiser를 활용한 소스코드 검증과 의존성 시각화 절차에 클린 아키텍처의 개념을 통합하

Dependency-Cruiser를 사용해서 프로젝트 의존성 구조 파악하기
Dependency-cruiser 설치Dependency-cruiser 초기화dependency-cruiser를 설치하면 .dependency-cruiser.js 가 루프 경로에 자동으로 생성됨소스코드 검증의존성 시각화

[알고리즘과 자료구조] 재귀 속도를 개선하는 방식을 알아보자
12장에서 재귀 코드의 속도를 느리게 만드는 원인을 찾고, 빅 오 관점에서 어떻게 나타내는지 배워보자.재귀 함수를 사용해서 배열에서 최댓값을 찾는다.예를 들어, 배열 1,2,3,4에서 최댓값을 찾는다면, 첫 번째 원소인 1과 배열 2,3,4의 최댓값을 비교한다. 이어서

[알고리즘과 자료구조] 재귀함수를 사용해 다양한 문제를 접근해보자
📝 '누구나 자료구조와 알고리즘' 책을 공부한 내용을 담고 있습니다.11장에서는 재귀적 사고방식을 기르는 데 집중한다. 여러 가지 재귀 문제를 다루면서 문제에 다양한 "카테고리"가 있음을 알게 됐다. 같은 카테고리에 속한 문제는 같은 기법으로 해결할 수 있다.예를 들

[회고]'푸디로그' 프로젝트를 마치고...
'푸디로그' 프로젝트 작년 7월~10월 진행했던 '푸디로그'가 새롭게 리뉴얼 시도하면서 다시금 프로젝트를 재개하였다. 보통의 프로젝트는 단기간 작업 후 새로운 프로젝트를 작업하는 데 바빠 코드 리팩토링을 신경쓰지 못했었다. 하지만, 푸디로그는 사이드 프로젝트로 진행했던