
<Gradient descent : 경사 하강법>
- 손실함수 값을 최소화하는 offset(initial parameter)을 찾아내는 과정
- 경사는 변화의 방향이 가장 큰 곳으로 업데이트된다
- Hyper parameter(알파 -> 사전에 정하는 값)와 learnable parameter(세타)
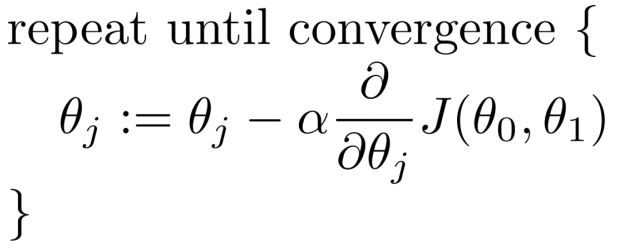
학습율 learning rate
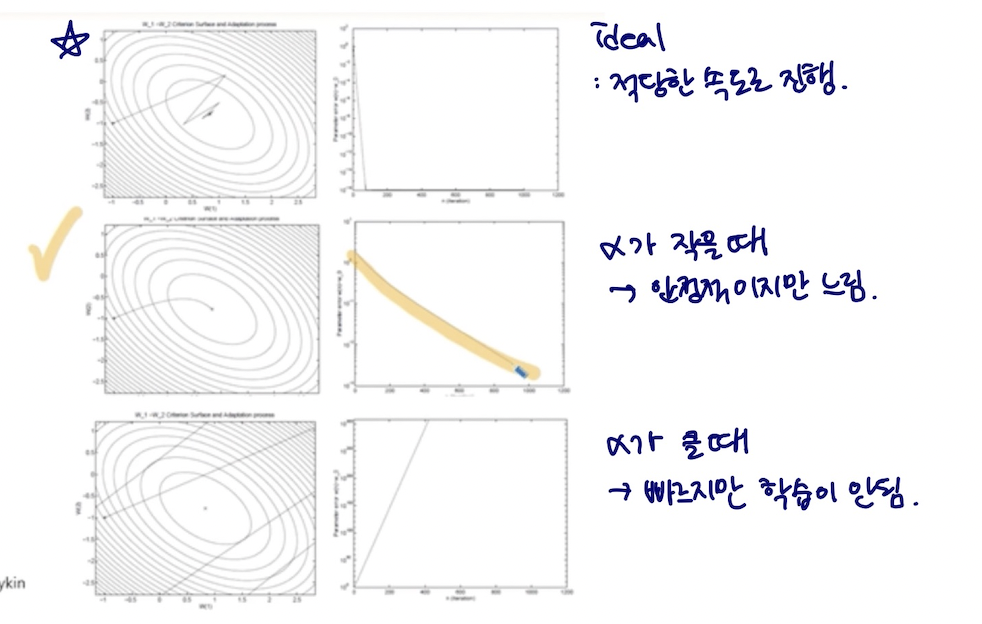 1. 적당한 속도에 학습이 진행되는 중 —> 목적!!
1. 적당한 속도에 학습이 진행되는 중 —> 목적!!
2. 수렴이 안정적으로 진행되지만 느리다 (알파가 작다)
3. 알파가 크다 그래서 빠르지만 학습이 진행이 안됨
batch gradient descent algorithm
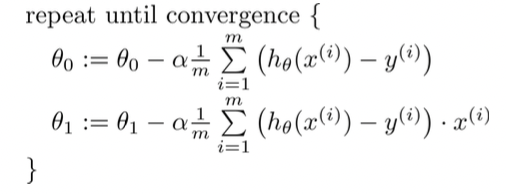
선형회귀모델에서의 목적함수 J에 편미분값을 넣어서 세타(learnable parameter)를 바꾸고 있다.
수렴할 때까지 m(데이터 개수) 만큼 computation을 반복해야 하므로 계산에서의 과부하 문제가 생길 수밖에 없다.
Stochastic gradient descent SGD
확률적 경사 하강법 : 배치크기가 1 (한번에 하나의 샘플에 대해서만 기울기를 계산) 인 경사하강법 알고리즘.
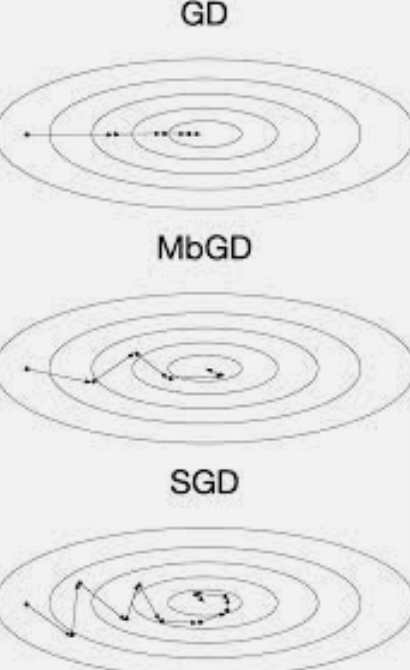
(순서대로 경사하강, 미니배치 경사하강, 확률적 경사하강)
학습 빠르지만 각 샘플 하나하나마다 연산해야해서 연산에 noise가 발생한다.
Local optimum에 빠지기 쉽다. 어디에서 computation이 시작되는지에 따라서 local인지 global인지 모른다.
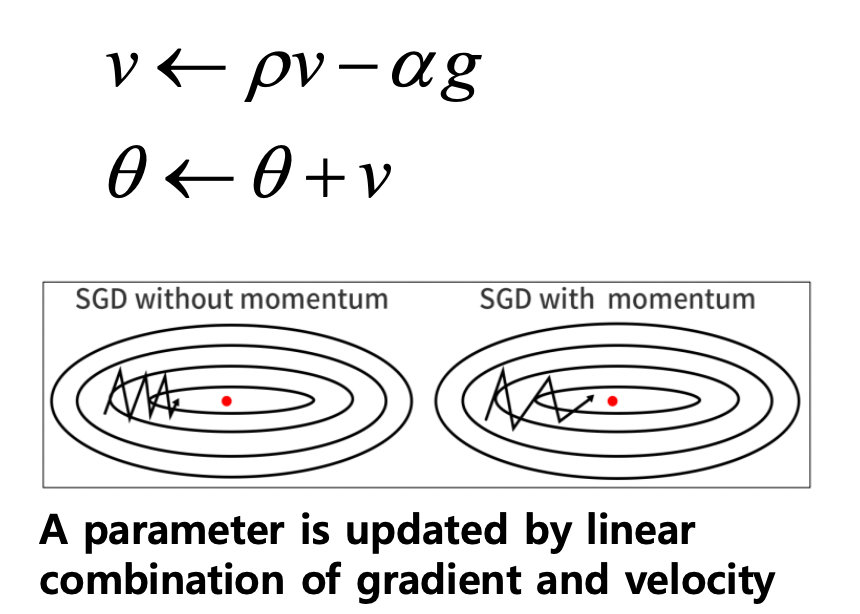
Momentum을 이용한 SGD
-> 과거의 동향을 활용해 saddle point 등에 도달하더라도 계속 학습을 하는 알고리즘
Nesterov momentum
Lookahead Gradient step

Momentum과 lookahead gradient step 값의 벡터합을 적용하는 알고리즘
AdaGrad
각 방향으로의 learning rate를 적응적으로 조정하여 학습 효율을 올리는 방식
How ? 분모로 들어가는 r은 gradient의 제곱의 누적된 합이다. 이걸로 세타값을 결정하는데 gradient가 커질수록 세타가 작아진다. (수렴이 되는 중이다) -> accumulate gradient값으로 learning rate를 조절한다.
단점 : gradient가 누적되면서 learning rate 가 작아진다 -> 학습이 일어나지 않는다.
이를 보완하기 위한 해결책이 RMSProp algorithm
RMSProp

극단적으로 gradient가 그대로 누적되는 게 아니라 어느정도 완충된 형태로 학습 속도가 줄어든다.
ADAM
Adaptive moment estimation
: RMSProp+momentum 방식의 결합체
-> (1) 모멘텀방식으로 s를 구한다
(2) RSMProp방식으로 r 구한다
(3) bias correction : s, r 값 보정
(4) bias를 활용해 파라미터 업데이트
learning rate scheduling

하이퍼파라미터인 학습율 알파값을 처음에 지정을 하면, 이 값이 너무 클 때는 빠르게 진행되지만 정확도가 떨어지고 이 값이 너무 작으면 천천히 진행되지만 정확도가 높다. 그래서 실제로는 learning rate scheduling이라는 방식을 사용하는데, 이것은 수렴 단계마다 알파값을 조정해나가는 방식이다.
초기에는 빠르게 학습하고, 수렴에 가까워질 때는 조금 더 천천히 학습하도록 보정한다.
model의 과적합 문제
Model이 지나치게 복잡 -> 학습파라미터의 숫자가 많음 -> 제한된 학습 샘플에 너무 과하게 학습이 되는 현상.
: 새로운 샘플을 넣었을 때 제대로 성능이 안 나오는 문제가 생긴다.
회귀모델에서 입력 피쳐의 숫자가 많아지면 항상 좋은 것일까?
입력 변수간에 dependent할 수도 있지만, 입력 피쳐 수가 많아지면 파라미터수가 많아진다.
이에 따라서 curse of dimension problem에 의해 데이터의 개수가 더 많아지게 된다.
그러나 실제 상황에서는 데이터를 늘리는 데에 한계가 있으므로 오버피팅 문제가 발생.
더더욱 우리가 사용하는 mse와 같은 오차 산출 방식은 노이즈와 아웃라이어에 민감한 특성을 갖는다.
regularization
복잡한 모델을 사용하더라도 복잡도에 대한 패널티를 줘서 오버피팅되지 않도록 하는 최적화 방식
MSE(fitting term)+보정(세타값이 많아질수록 커지는 값으로, 세타가 많다 = 모델이 복잡하다 = 패널티를 크게 준다)
-> 가급적 적은 숫자의 파라미터를 사용하면서 주어진 문제의 샘플에 피팅을 하면 오버피팅 문제를 피할 수 있다.
* Quiz
- Gradient descent는 numerical solution은 제공하지만 global optimum을 성취하지는 못한다
-> correct. 경사하강법은 현재의 상태에서 가장 기울기가 큰 쪽으로 움직이기 때문에 local optimum에 빠지기 쉽다는 단점이 있음. - 이전 경사 하강 단계에서의 momentum은 overfitting 문제를 방지한다
-> false. 모멘텀 방식은 local optimum 문제를 해결하기 위한 방법이다. - regularization은 인풋 피쳐의 중요성에 대하여 패널티를 주어 오버피팅 문제를 방지한다.
-> correct. 모델이 복잡하고 인풋 피쳐가 많아지면 패널티가 커진다.
* 정리
- Optimization
-> gradient descent algoritm 의 개념
-> sgd+여러 추정치를 섞은 다양한 알고리즘들
-> 그 중 adam이 가장 많이 사용됨 (경사하강 중에서) - Regularization
-> 오버피팅을 줄이기 위해 복잡도를 줄여가는 것이 목적
