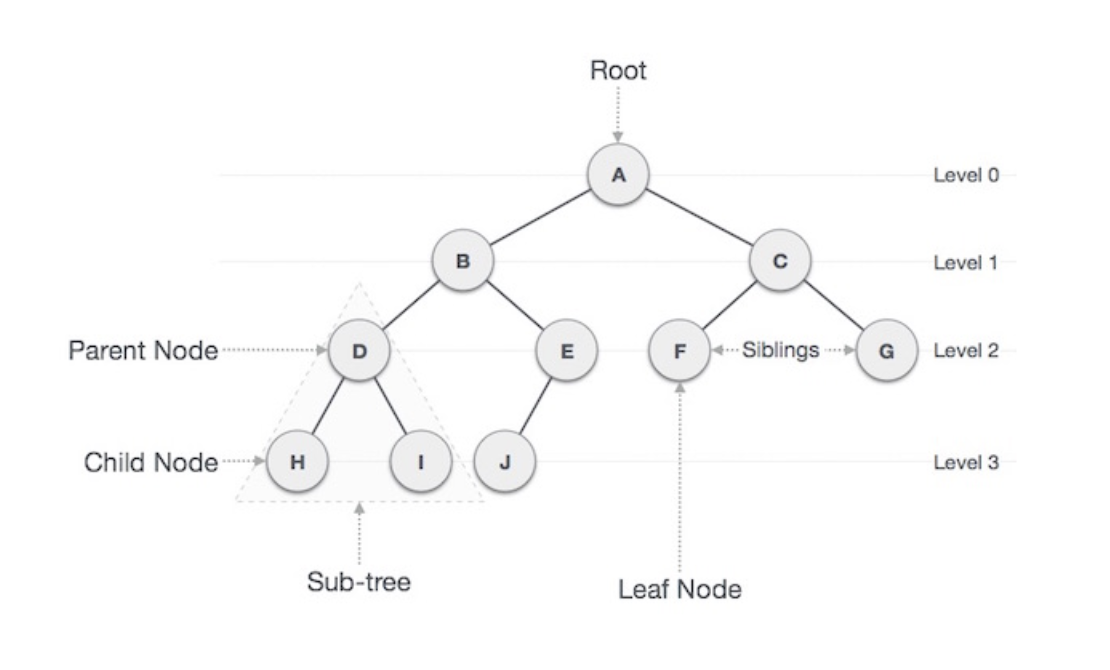
트리(Tree)란?
트리(Tree)란, 한 노드(Node)가 여러 노드를 가리킬 수 있는 비선형 자료구조이다. 순서보다는 데이터 구조의 계층적인 상하관계를 표현할 때 주로 사용하고, 그래프(Graph)라는 자료구조의 일종이다.
트리는 다음과 같이 나무를 거꾸로 뒤집어 놓은 모양과 유사하다.
트리구조의 특징
- 루트 노드는 1개만 존재
- 트리 내에 사이클은 존재하지 않음
- 자녀 노드는 하나의 부모 노드만 가짐
- 모든 노드는 단 하나의 경로로 연결
- 데이터를 순차적으로 저장하지 않는 비선형 구조
- 트리에 서브 트리가 있는 재귀적 구조
- N개의 노드와 N-1개의 간선
- 계층적 구조
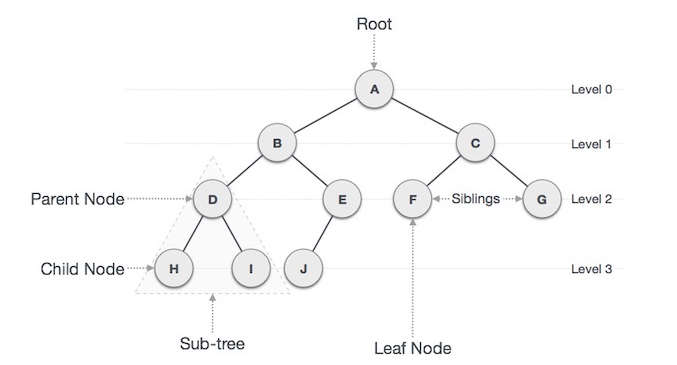
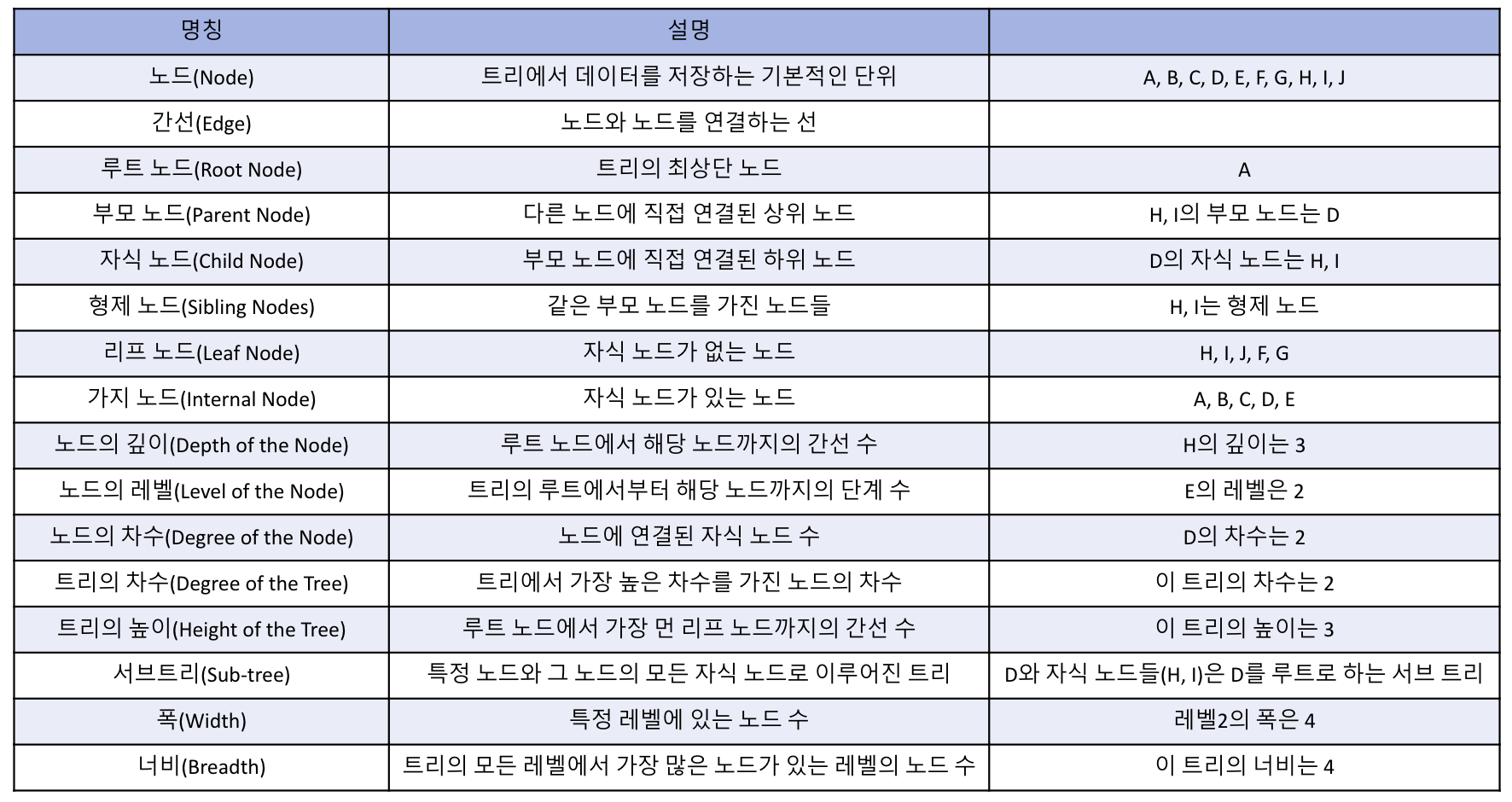
트리의 기본 용어
트리의 종류
이진 트리(Binary Tree)
이진 트리란, 자식 노드가 최대 두 개인 노드들로 구성된 트리 자료 구조이다.
여러 유형의 트리 중 가장 기본적인 형태로, 다양한 트리 자료 구조의 기초가 된다.
-
포화 이진 트리(Full Binary Tree)
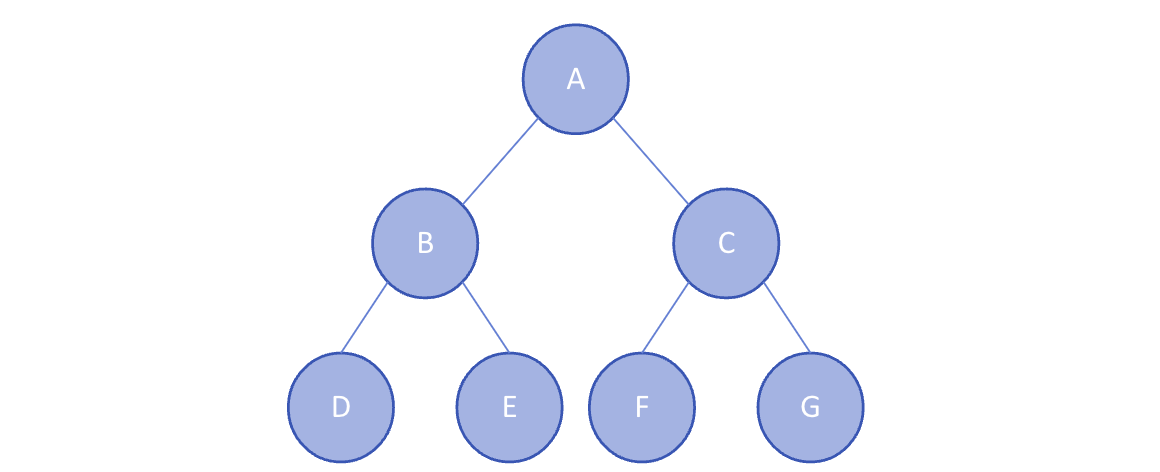 Leaf Node를 제외한 모든 노드의 차수가 2개로 이루어져 있는 경우를 의미한다. 이 경우 해당 차수에 몇 개의 노드가 존재하는지 바로 알 수 있으므로 노드의 개수를 파악할 때 용이한 장점이 있다.
Leaf Node를 제외한 모든 노드의 차수가 2개로 이루어져 있는 경우를 의미한다. 이 경우 해당 차수에 몇 개의 노드가 존재하는지 바로 알 수 있으므로 노드의 개수를 파악할 때 용이한 장점이 있다. -
완전 이진 트리(Complete Binary Tree)
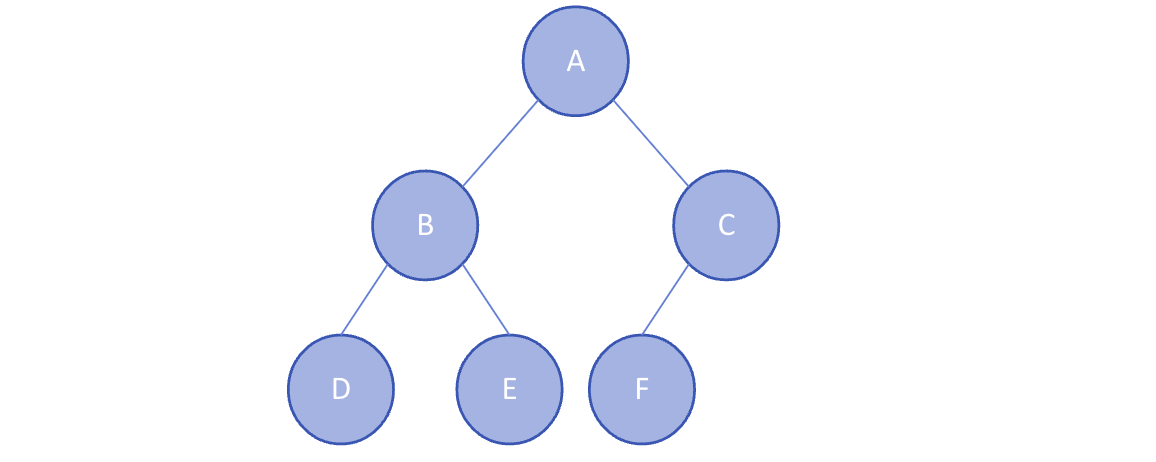 마지막 레벨을 제외한 모든 레벨이 완전히 채워져 있고, 마지막 레벨은 왼쪽부터 차근차근 채워지는 이진 트리이다.
마지막 레벨을 제외한 모든 레벨이 완전히 채워져 있고, 마지막 레벨은 왼쪽부터 차근차근 채워지는 이진 트리이다.
* 힙(Heap)은 완전 이진 트리의 일종이다. -
균형 이진 트리(Balanced Binary Tree)
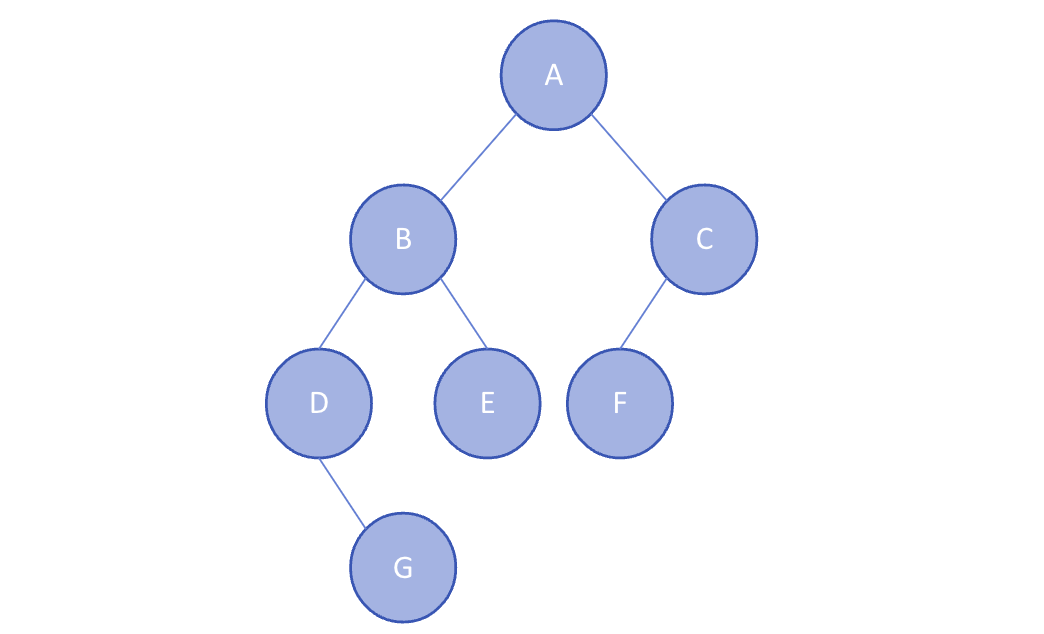 트리의 높이를 최소화하며 균형을 유지하는 트리로, 모든 노드의 왼쪽과 오른쪽 하위 트리의 높이 차이가 최대 1만큼 날 수 있다. 균형 이진 트리의 종류로는 AVL 트리와 레드-블랙 트리 등이 있다.
트리의 높이를 최소화하며 균형을 유지하는 트리로, 모든 노드의 왼쪽과 오른쪽 하위 트리의 높이 차이가 최대 1만큼 날 수 있다. 균형 이진 트리의 종류로는 AVL 트리와 레드-블랙 트리 등이 있다. -
편향 이진 트리(Skewed Binary Tree)
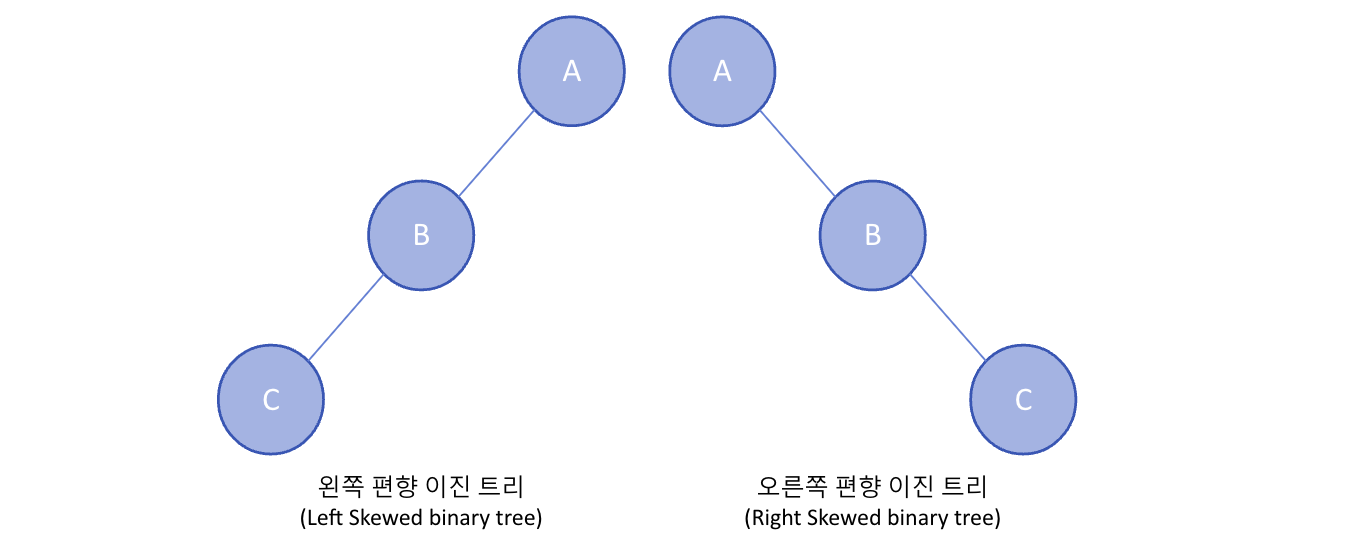 모든 노드가 한쪽 방향(왼쪽 또는 오른쪽)으로만 자식 노드를 가지는 트리로, 사실상 하나의 차수로만 이루어진 구조를 의미한다. 이러한 구조는 배열(리스트)과 같은 선형 구조이므로 Leaf Node 탐색 시 모든 데이터를 전부 탐색해야 하는 단점이 있어 효율적이지 못하다.
모든 노드가 한쪽 방향(왼쪽 또는 오른쪽)으로만 자식 노드를 가지는 트리로, 사실상 하나의 차수로만 이루어진 구조를 의미한다. 이러한 구조는 배열(리스트)과 같은 선형 구조이므로 Leaf Node 탐색 시 모든 데이터를 전부 탐색해야 하는 단점이 있어 효율적이지 못하다.
이진 탐색 트리(Binary Search Tree)
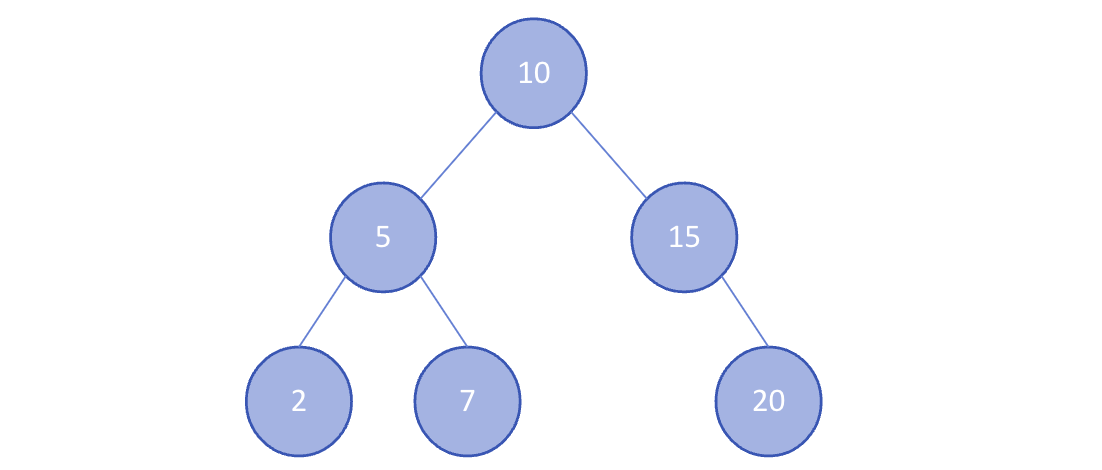
[10, 5, 15, 2, 7, 20]으로 이진 탐색 트리의 형태로 만들면 위와 같은 형태가 된다.
부모 노드들의 왼쪽 노드는 부모 노드보다 작은 값을 가지며, 오른쪽 노드는 부모 노드보다 큰 값을 가지며, 모든 노드는 중복된 값을 가지지 않는다.
* 원하는 값을 찾을 때까지 현재의 노드값보다 찾고자하는 값이 작으면 왼쪽으로 움직이고, 크면 오른쪽으로 움직이면 되기 때문에 효율적인 검색, 삽입, 삭제 연산을 제공한다.
힙(Heap)
완전 이진 트리의 일종으로, 우선순위 큐를 위해 만들어진 자료구조이다.
힙을 이용하여 우선순위 큐를 구현하면 데이터를 삽입, 삭제하는데 O(log n) 시간이 걸린다. 여러 개의 값들 중 최댓값이나 최솟값을 빠르게 찾아낼 수 있는 자료구조이다.
-
최대 힙(Max Heap)
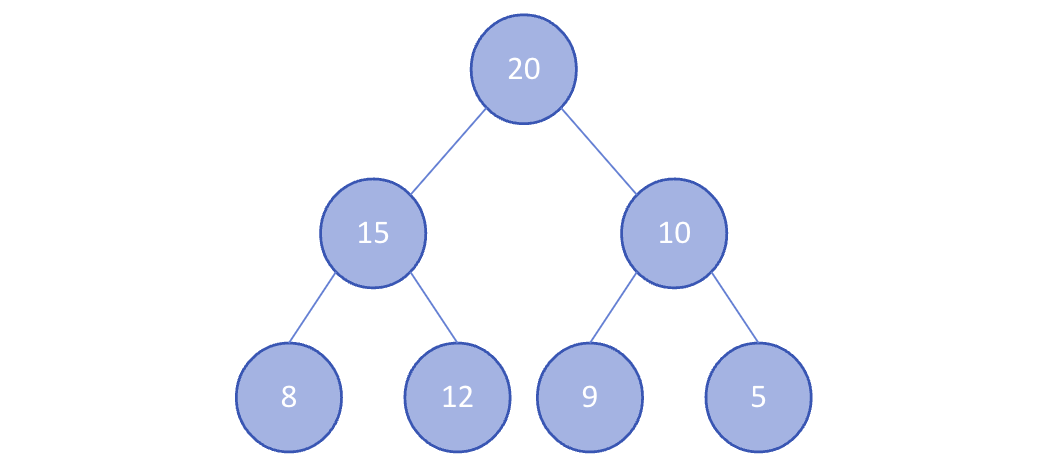 부모 노드의 값이 자식 노드의 값보다 크거나 같은 완전 이진 트리이다.
부모 노드의 값이 자식 노드의 값보다 크거나 같은 완전 이진 트리이다.
따라서 최댓값은 항상 루트 노드에 위치한다. -
최소 힙(Min Heap)
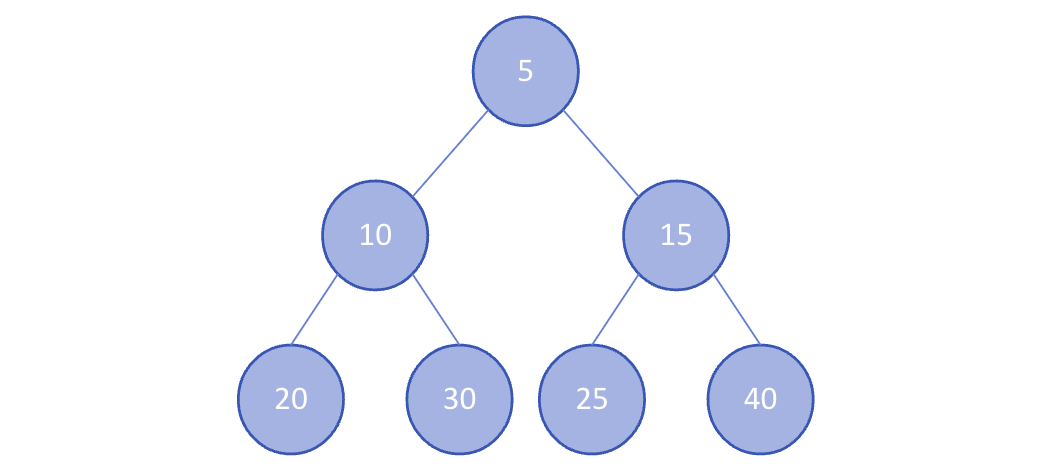 부모 노드의 값이 자식 노드의 값보다 작거나 같은 완전 이진 트리이다.
부모 노드의 값이 자식 노드의 값보다 작거나 같은 완전 이진 트리이다.
따라서 최솟값은 항상 루트 노드에 위치한다.
B-트리(B-Tree)
이진 탐색 트리는 각 노드가 최대 두 개의 자식을 가지므로, 트리의 높이가 커질 수 있는 문제점이 있다. 이를 해결하기 위해, 차수를 2에서 m으로 확장한 m-원 검색 트리가 도입되었다.
m-원 검색 트리로 높이를 줄이는 데는 성공했지만, 여전히 균형이 맞지 않는 문제가 발생했다. 이러한 균형 문제를 해결하기 위해 B-트리가 등장하였으며, B-트리는 m-원 검색 트리의 좌우 균형을 맞추는 데 효과적이다.
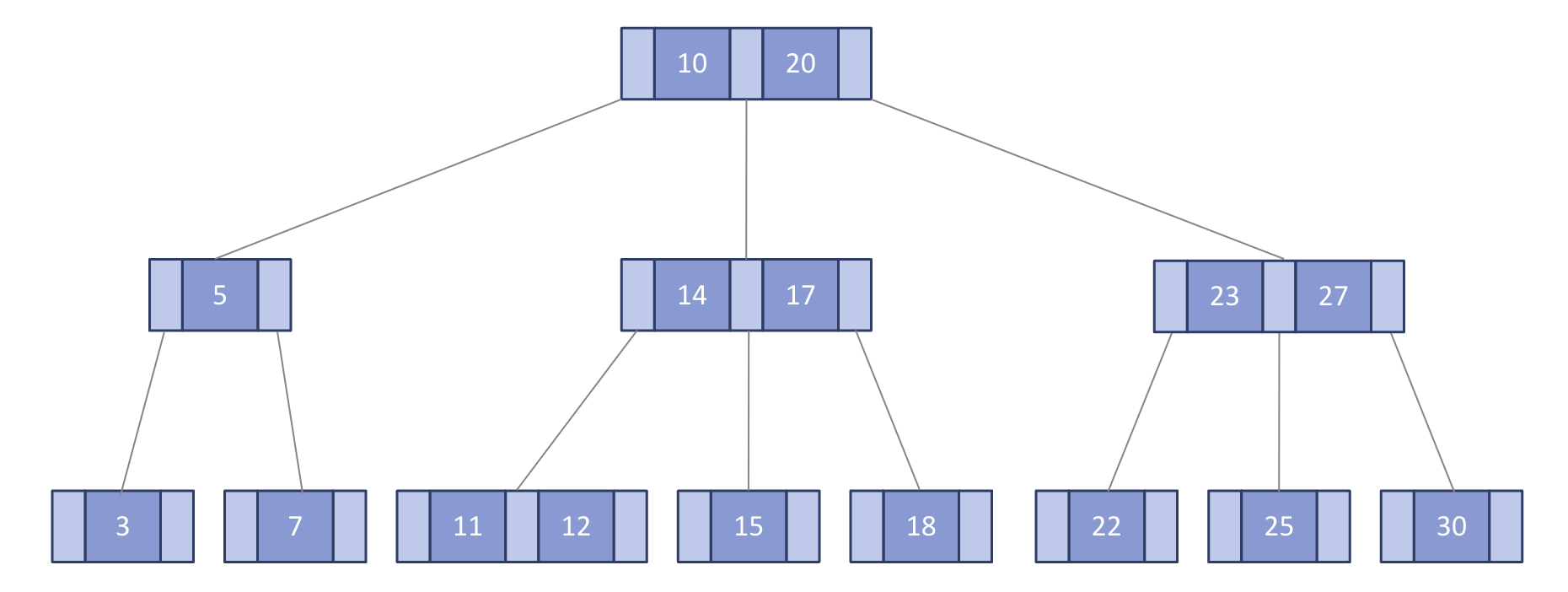 많은 양의 데이터를 저장하고 검색하기 위해 설계된 균형 트리로, 데이터베이스와 파일 시스템에 자주 사용된다.
많은 양의 데이터를 저장하고 검색하기 위해 설계된 균형 트리로, 데이터베이스와 파일 시스템에 자주 사용된다.
각 노드는 여러 개의 자식 노드를 가질 수 있으며, 모든 리프 노드가 동일한 깊이를 가진다.
B-트리는 이진 트리와 다르게 하나의 노드에 많은 수의 키를 가질 수 있으며, 최대 M개의 자식을 가질 수 있는 B-트리를 M차 B-트리라고 한다.
-
노드의 자식 노드 수: 노드는 최대 M개의 자식 노드를 가질 수 있으며, 최소 ⌈M/2⌉개의 자식 노드를 가져야 한다.
ex) 3차 B-트리라면, 각 노드는 최대 3개의 자식 노드를 가질 수 있고, 최소 2개의 자식 노드를 가져야 한다. -
노드의 키 수: 노드는 최대 M-1개의 키를 가질 수 있으며, 최소 ⌈M/2⌉ - 1개의 키를 가져야 한다.
ex) 3차 B-트리라면, 각 노드는 최대 2개의 키를 가질 수 있고, 최소 1개의 키를 가져야 한다. -
노드의 키와 자식 관계: 내부 노드가 x개의 키를 가지면, 자식 노드의 수는 x + 1개이다.
ex) 3차 B-트리라면, 노드가 2개의 키를 가지고 있다면, 3개의 자식 노드를 가질 수 있다. -
최소 차수: 최소 차수는 자식 수의 하한값을 의미하며, 최소차수 t라면 M = 2t - 1을 만족한다.
ex) 최소차수 t가 2라면, 3차 B-트리가 된다. -
정렬된 키: 모든 노드에 있는 키들은 정렬된 상태로 저장되며, 키들은 내부 노드와 리프 노드에 모두 분산되어 저장된다.
B+ 트리(B+ Tree)
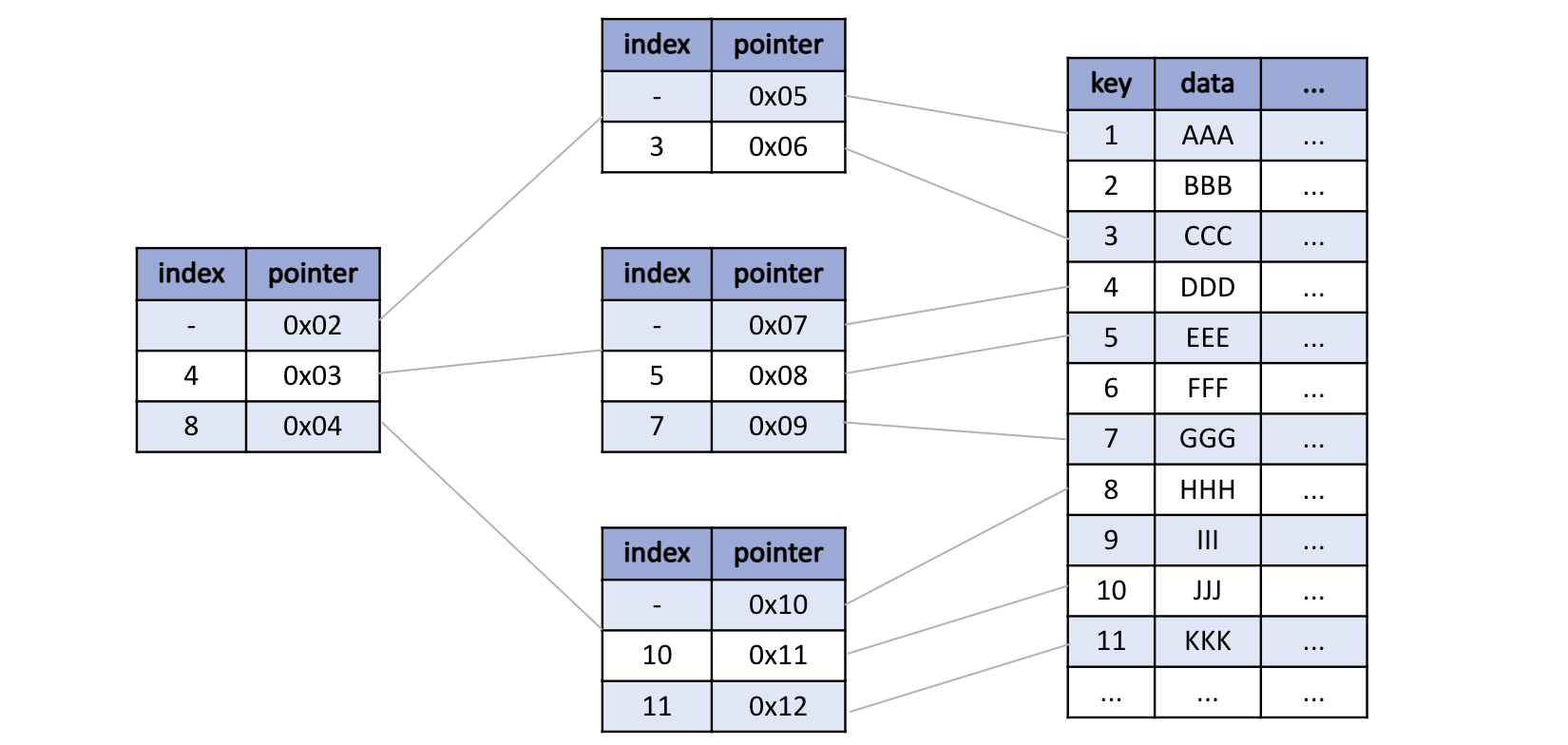
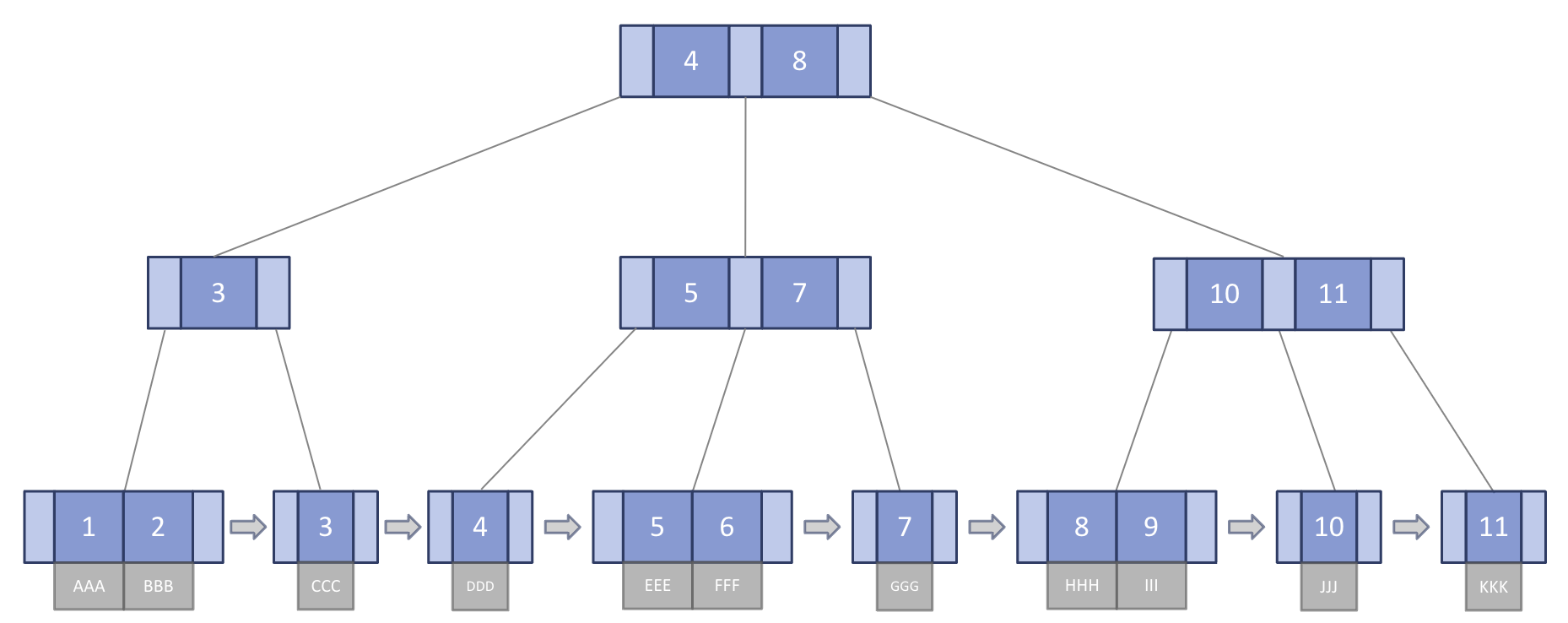
B+트리는 순차 검색이 힘든 B-트리를 보완하기 위해 등장한 자료구조로, 데이터의 효율적인 삽입, 검색, 삭제를 추구한다.
B-트리와 달리 삽입과 삭제 연산이 리프 노드에서만 이루어지며, 모든 실제 데이터는 리프 노드에 저장되고 리프 노드끼리 연결 리스트로 연결되어 있어 순차 탐색과 범위 검색에 매우 유리하다.
직접 탐색 성능은 B-트리와 유사하지만, 순차 탐색 성능은 더 뛰어나다. 이 구조로 인해 B+트리는 대량의 데이터를 효율적으로 관리하고 빠르게 순차 탐색을 수행할 수 있다.
-
노드의 자식 노드 수: 노드는 최대 M개의 자식 노드를 가질 수 있으며, 최소 ⌈M/2⌉개의 자식 노드를 가져야 한다.
ex) 3차 B+트리라면, 각 노드는 최대 3개의 자식 노드를 가질 수 있고, 최소 2개의 자식 노드를 가져야 한다. -
노드의 키 수: 노드는 최대 M-1개의 키를 가질 수 있으며, 최소 ⌈M/2⌉ - 1개의 키를 가져야 한다.
ex) 3차 B+트리라면, 각 노드는 최대 2개의 키를 가질 수 있고, 최소 1개의 키를 가져야 한다. -
노드의 키와 자식 관계: 내부 노드가 x개의 키를 가지면, 자식 노드의 수는 x + 1개이다.
ex) 3차 B+트리라면, 노드가 2개의 키를 가지고 있다면, 3개의 자식 노드를 가질 수 있다. -
최소 차수: 최소 차수는 자식 수의 하한값을 의미하며, 최소차수 t라면 M = 2t - 1을 만족한다.
ex) 최소차수 t가 2라면, 3차 B+트리가 된다. -
정렬된 키: 모든 키들은 리프 노드에만 저장되며, 리프 노드에서 정렬된 상태로 유지된다.
내부 노드는 탐색을 위한 인덱스 역할을 한다.
트라이(Trie)
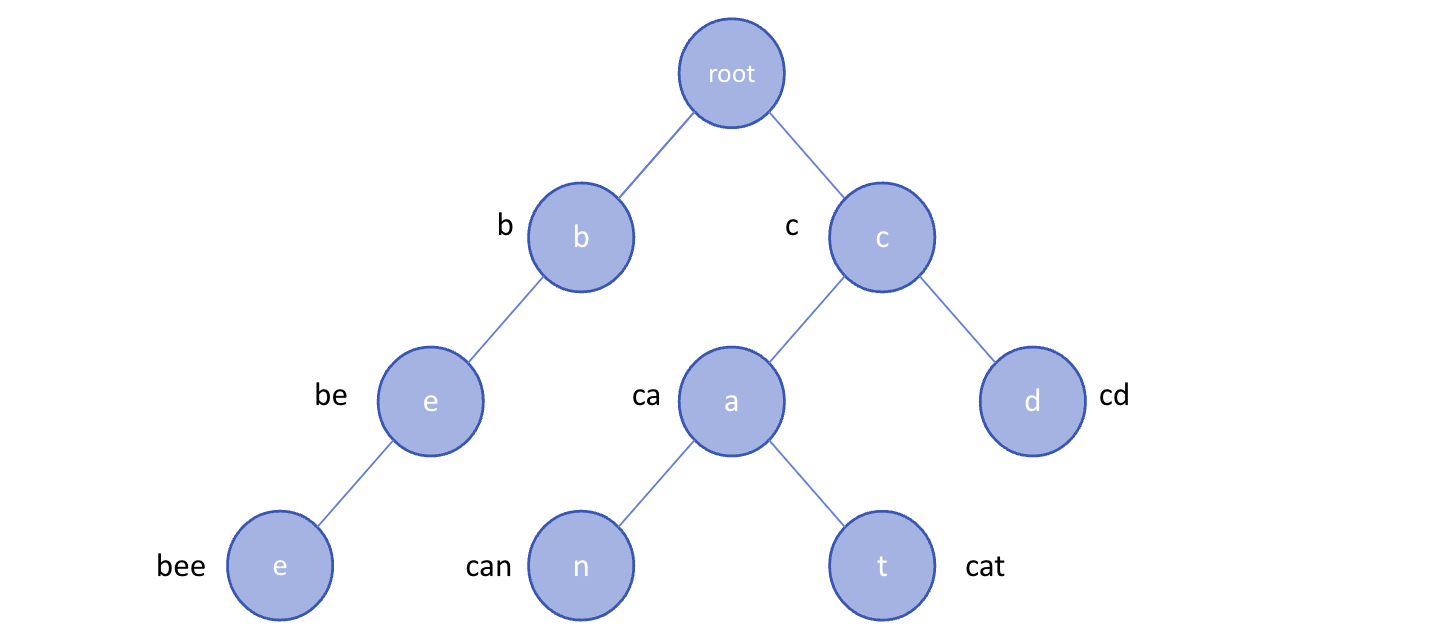 문자열을 효율적으로 저장하고 검색하기 위한 트리형태의 자료구조이다.
문자열을 효율적으로 저장하고 검색하기 위한 트리형태의 자료구조이다.
우리가 검색할 때 볼 수 있는 자동완성 기능, 사전 검색 등 문자열을 탐색하는데 특화되어 있는 자료구조이다.
정수형에서 이진 탐색 트리를 이용하면 시간 복잡도가 O(logN)이지만, 문자열을 적용했을 경우에는 문자열의 최대 길이(M)에 따라 시간 복잡도가 O(M*logN)만큼 측정된다.
트라이를 활용하면 O(M)으로 문자열 검색이 가능하다.
트리의 순회 방법
트리의 모든 노드들을 방문하는 과정을 트리 순회(Tree Traversal)라고 한다.
선형 자료 구조(연결 리스트, 스택, 큐 등)는 순차적으로 요소에 접근하지만 트리 자료구조는 다른 방식을 사용해야 한다. 일반적으로 트리 순회에는 전위 순회, 중위 순회, 후위 순회 등이 있으며, 이러한 순회는 보통 재귀로 쉽게 구현할 수 있다.
전위 순회(Preorder Traversal)
전위 순회는 깊이 우선 순회(DFT, Depth-First Traversal)이라고도 한다.
트리를 복사하거나 전위 표기법을 구하는데 주로 사용되는데, 트리를 복사할 때 전위 순회를 사용하는 이유는 트리를 생성할 때 자식 노드보다 부모 노드가 먼저 생성되어야 하기 때문이다.
전위 순회의 순회 방향은 [루트 → 왼쪽 → 오른쪽] 순이다.
A → B → D → H → I → E → J → C → F → G
중위 순회(Inorder Traversal)
중위 순회는 왼쪽 오른쪽 대칭 순서로 순회를 하기 때문에 대칭 순회(Symmetric Traversal)라고도 한다. 중위 순회는 이진 탐색 트리(BST)에서 오름차순 또는 내림차순으로 값을 가져올 때 사용된다. 내림차순으로 값을 가져오기 위해서는 역순(오른쪽 → 루트 → 왼쪽)으로 중위 순회를 하면된다.
중위 순회의 순회 방향은 [왼쪽 → 루트 → 오른쪽] 순이다.
H → D → I → B → J → E → A → F → C → G
후위 순회(Postorder Traversal)
후위 순회는 트리를 삭제하는데 주로 사용된다. 그 이유는 삭제하기 전에 자식 노드를 삭제하는 순으로 노드를 삭제해야 하기 때문이다.
후위 순회의 순회 방향은 [왼쪽 → 오른쪽 → 루트] 순이다.
H → I → D → J → E → B → F → G → C → A
레벨 순서 순회 (Level Order Traversal)
레벨 순서 순회는 트리의 각 레벨을 차례대로 방문하는 방법이다. 이 순회 방법은 너비 우선 탐색(BFS, Breadth-First Search)과 밀접한 관련이 있다.
레벨 순서 순회의 순회 방향은 [루트부터 아래 레벨] 순이다.
A → B → C → D → E → F → G → H → I → J
위 개념들에 대해서 상세하게 공부하고싶다면 아래 블로그를 참고!!
- 이진 트리의 종류
https://velog.io/@dlgosla/CS-%EC%9E%90%EB%A3%8C%EA%B5%AC%EC%A1%B0-%EC%9D%B4%EC%A7%84-%ED%8A%B8%EB%A6%AC-Binary-Tree-vzdhb2sp- 이진 트리, 트리 순회
https://velog.io/@kimdukbae/%EC%9E%90%EB%A3%8C%EA%B5%AC%EC%A1%B0-%ED%8A%B8%EB%A6%AC-Tree- 힙
https://velog.io/@humblechoi/%EC%9E%90%EB%A3%8C%EA%B5%AC%EC%A1%B0-%ED%8A%B8%EB%A6%AC%EC%99%80-%ED%9E%99- B-트리
https://velog.io/@chanyoung1998/B%ED%8A%B8%EB%A6%AC- B+트리
https://velog.io/@emplam27/%EC%9E%90%EB%A3%8C%EA%B5%AC%EC%A1%B0-%EA%B7%B8%EB%A6%BC%EC%9C%BC%EB%A1%9C-%EC%95%8C%EC%95%84%EB%B3%B4%EB%8A%94-B-Plus-Tree- B+트리 시각화 사이트
https://www.cs.usfca.edu/~galles/visualization/BPlusTree.html- 트라이
https://velog.io/@kimdukbae/%EC%9E%90%EB%A3%8C%EA%B5%AC%EC%A1%B0-%ED%8A%B8%EB%9D%BC%EC%9D%B4-Trie- 데이터베이스 인덱스는 왜 B-Tree를 선택하였는가?
https://velog.io/@kimdukbae/%EC%9E%90%EB%A3%8C%EA%B5%AC%EC%A1%B0-%ED%8A%B8%EB%9D%BC%EC%9D%B4-Trie
[참고 자료]
https://yoongrammer.tistory.com/68
https://velog.io/@kwontae1313/%ED%8A%B8%EB%A6%ACTree%EC%97%90-%EB%8C%80%ED%95%B4%EC%84%9C-%EC%95%8C%EC%95%84%EB%B3%B4%EC%9E%90
https://yoongrammer.tistory.com/70
https://wonit.tistory.com/198
