K-평균 군집화
K-means clustering(줄여서 kc)운 입력받은 데이터를 토대로 k개의 중심(centeroid)을 기준으로 군집을 형성하는 알고리즘입니다.
k값
단점이자 특징으로는 이때 k는 hyperparameter이라는 점입니다. KNN처럼 K-means는 유클리드 거리를 기준으로 분류를 하는데 이때 k값이 결정적인 역할을 하기에 적절한 알고리즘이 실행되기 위해서는 trial-and-error이 필수적입니다. k값을 정하는데 아래와 같은 방법들이 존재합니다.
Rule of Thumb
데이터의 수가 n일 때,
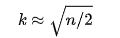
으로 대략적으로 계산 가능하다.
Elbow Method
혹은 클러스터의 수를 지속적으로 늘려가면서 더 나은 결과가 나오지 않을 경우 거기서 멈추는 trial-and-error 방식이 존재한다.
학습 과정
KC는 EM 알고리즘을 기반으로 작동합니다. Expectation과 Maximization으로 이루어진 EM 알고리즘은 아래 그림을 보면 이해가 될겁니다.
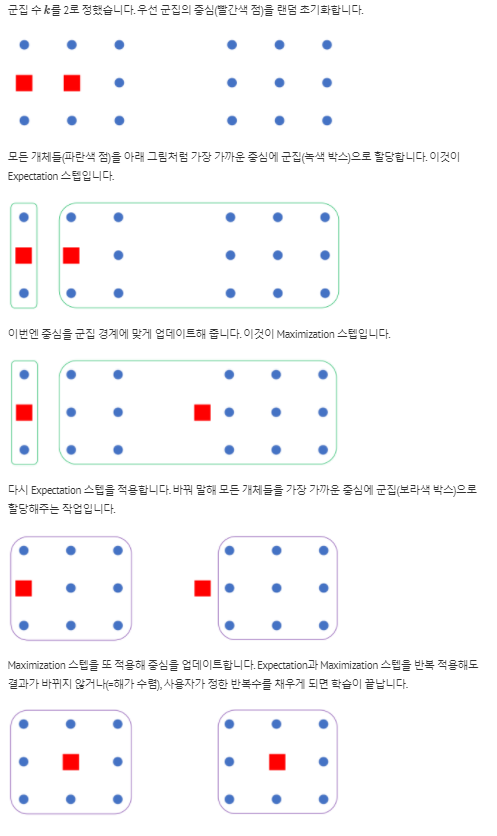
특징
- centeroid가 랜덤하게 나오기에 매번 같은 결과를 기대하기 힘듭니다.
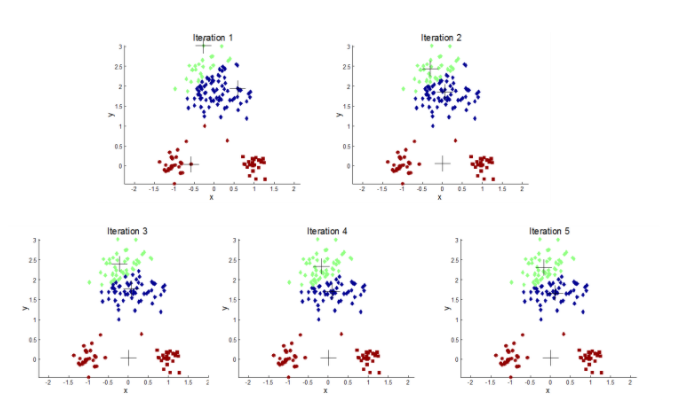
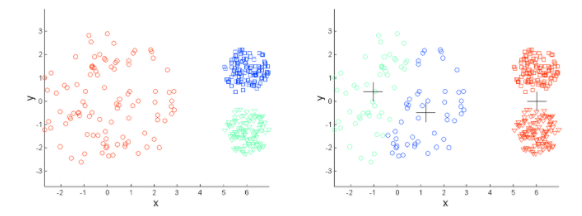
- 군집의 크기가 다를 경우 제대로 작동하지 않을 수 있습니다.
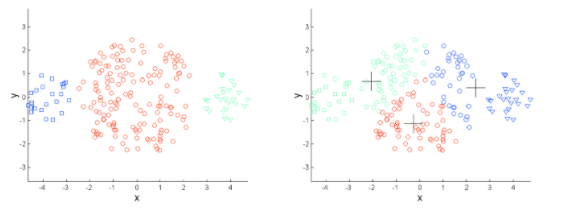
- 군집의 밀도가 다를 경우 제대로 작동하지 않을 수 있습니다.
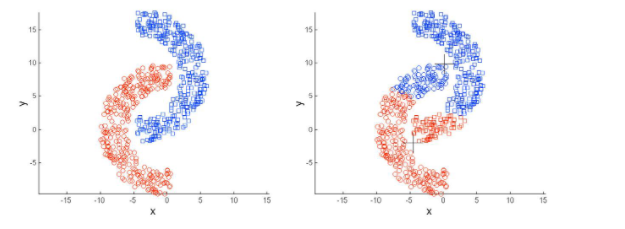
- 데이터 분포가 특이한 케이스도 군집이 잘 이루어지기 힘듭니다.
따라서 KC는 실제로는 여러번 군집화를 진행하고 가장 빈번히 등장하는 군집을 선정하는 majority voting 방법을 통해 사용하는 경우가 많다고 합니다. 계산 과정이 간단하기에 (계산 복잡성 O(n)) 여러 번 사용하기 용이합니다.
출처
https://ratsgo.github.io/machine%20learning/2017/04/19/KC/
https://www.notion.so/Machine-Learning-Study-60a6a4fa5a474d02a94e62c4ecc7894c#9157c37318334501a38341b34596d411
https://ko.wikipedia.org/wiki/K-%ED%8F%89%EA%B7%A0_%EC%95%8C%EA%B3%A0%EB%A6%AC%EC%A6%98

centeroid -> centroid 오타가 있습니다. 글 잘봤습니다.