Polynomial Regression
Introduction
Polynomial regression is a statistical technique that expands the capabilities of linear regression by modeling the relationship between the independent variable and the dependent variable as an -th degree polynomial. It provides a way to model a nonlinear relationship through a linear model, by introducing polynomial features, thereby accommodating a broader range of data structures.
Background and Theory
Polynomial Features and Vandermonde Matrix
Polynomial regression can be implemented by transforming the original input features into polynomial features. This process involves generating every combination of features raised to every power up to the th degree. For a single independent variable , the polynomial features would be . This transformation of the input variable into a set of polynomial features is represented by the Vandermonde matrix.
A Vandermonde matrix for a single independent variable with observations and a polynomial degree of is structured as follows:
This matrix is used to transform the single-dimensional input into a multi-dimensional feature space, where linear regression techniques can then be applied.
Polynomial Regression Model
Given the Vandermonde matrix and a response vector with observations, the polynomial regression model can be expressed as:
where:
- is the vector of observed values of the dependent variable,
- is the Vandermonde matrix of transformed polynomial features,
- is the vector of coefficients ,
- represents the vector of errors or residuals.
Derivation of the Normal Equation
The normal equation is derived from the principle of least squares, which aims to minimize the sum of squared residuals between the observed values and the values predicted by the model .
Given the model equation in matrix form as , where is the Vandermonde matrix of polynomial features and is the vector of observed values, the RSS is defined as:
To find the minimum of , we take its derivative with respect to and set it to zero. This process involves the following steps:
-
Expand the RSS equation:
-
Take the derivative of RSS with respect to :
-
Set the derivative to zero and solve for :
This final equation, , is known as the normal equation. It provides a direct method to compute the coefficients that minimize the , and thus, the error between the predicted and observed values.
Detailed Computation Steps
Normal Equation Computation
- Generate the Vandermonde Matrix for your data.
- Compute : Multiply the transpose of by .
- Compute : Find the inverse of the matrix obtained in step 2.
- Compute : Multiply the transpose of by the response vector .
- Calculate : Multiply the matrix from step 3 by the vector obtained in step 4.
Polynomial Feature Generation
To generate polynomial features and the Vandermonde matrix in practice, one often uses computational tools or libraries that automate this process, especially for datasets with multiple features and higher-degree polynomials.
Implementation
Parameters
deg:int, default = 2
Degree of a polynomial function
alpha:float, default = 1.0
Regularization strength
l1_ratio:float, default = 0.5
Balancing parameter between L1 and L2 regularization
Examples
from luma.regressor.poly import PolynomialRegressor
from luma.model_selection.search import RandomizedSearchCV
from luma.metric.regression import RSquaredScore
from luma.visual.evaluation import ResidualPlot
import matplotlib.pyplot as plt
import numpy as np
X = np.linspace(0.1, 3, 200).reshape(-1, 1)
y = (np.cos(X**2) * np.log(X)).flatten() + 0.2 * np.random.randn(200)
param_dist = {
"deg": range(2, 10),
"alpha": np.logspace(-3, 3, 5),
"l1_ratio": np.linspace(0, 1, 5),
"regularization": ["l1", "l2", "elastic-net"],
}
rand = RandomizedSearchCV(
estimator=PolynomialRegressor(),
param_dist=param_dist,
max_iter=100,
cv=5,
metric=RSquaredScore,
maximize=True,
refit=True,
shuffle=True,
random_state=42,
)
rand.fit(X, y)
print(rand.best_params, rand.best_score)
reg = rand.best_model
est_func = r""
for i, coef in enumerate(reg.coef_):
est_func = f"+({coef:.2f})x^{i}" + est_func
print(est_func)
fig = plt.figure(figsize=(10, 5))
ax1 = fig.add_subplot(1, 2, 1)
ax2 = fig.add_subplot(1, 2, 2)
ax1.scatter(X, y, s=10, c="black", alpha=0.4)
ax1.plot(X, reg.predict(X), lw=2, c="b", alpha=0.7, label="Predicted Plot")
ax1.fill_between(X.flatten(), y, reg.predict(X), color="b", alpha=0.1)
ax1.set_xlabel("x")
ax1.set_ylabel("y")
ax1.set_title(
f"{type(reg).__name__} Result ["
+ r"$R^2$"
+ f": {reg.score(X, y, metric=RSquaredScore):.4f}]"
)
ax1.legend()
ax1.grid(alpha=0.2)
res = ResidualPlot(reg, X, y)
res.plot(ax=ax2, show=True)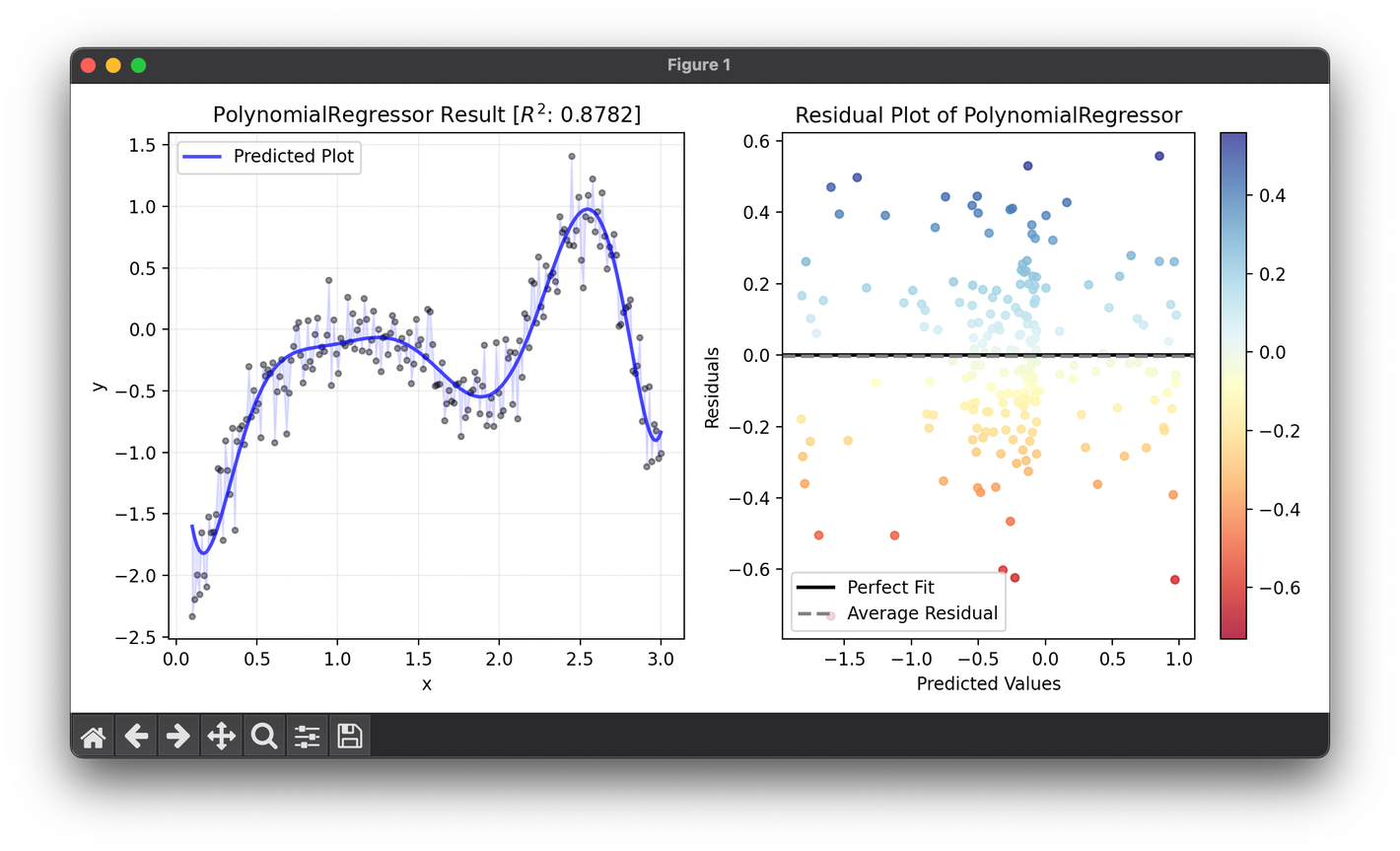
- Predicted plot:
Applications
Polynomial regression is widely used in fields such as:
- Economics: For modeling economic growth patterns or the impact of policy changes.
- Engineering: In signal processing and the analysis of stress-strain curves.
- Environmental Science: Modeling the relationship between environmental factors and biological responses.
Strengths and Limitations
Strengths
- Flexibility: Can model complex, nonlinear relationships between dependent and independent variables.
- Simplicity: Despite being able to fit nonlinear patterns, it remains a linear model, making it relatively straightforward to analyze and interpret.
Limitations
- Overfitting: Higher-degree polynomials can lead to overfitting the training data, capturing noise rather than the underlying trend.
- Extrapolation: Polynomial regression models can exhibit extreme behavior outside the range of the training data, making predictions less reliable.
- Computation: The inversion of can be computationally expensive and numerically unstable for high-degree polynomials or large datasets.
