
1. Introduction
1.1 최근 딥러닝
최근에는 Deep Learning의 눈부신 발전에 따라 다들 아시다시피, Text, Adudio, Image 등 전 분야에서 괄목할 만한 성능 향상을 볼 수 있습니다. 하지만 여기에는 가볍게 생각을 할 수 없는 한계점이 존재하는데, Text, Audio, Image 데이터를 다루는 모델들은 하나같이 모두 대용량 데이터를 필요로 한다는 것 입니다. 해결하고자하는 task에 맞춰진 정제된 데이터를 구하기는 쉽지않고, 지도학습 문제를 풀려고하면 label까지 있어야하니 데이터 구축은 더욱 어렵다는 문제가 있습니다.
따라서, 최근에는 이와 같은 문제점들을 해결하기 위해 Data Dependency를 낮추려고하는 연구들이 수행되고 있습니다.
1) Semi-Supervised Learning
2) Self-Supervised Learning
3) Meta-Learning
Few-shot Learning은 Meta-Learning의 일종의 개념 중 하나라고 생각하셔도 됩니다.
1.2 Meta-Learning / Few-shot Learning
Meta-Learning: "Learn to Learn", 간단하게 Meta-Learning에 대해 설명을 드리면, 현재 인공지능에서 핫한 연구 토픽 중 하나로 AGI(Artificial General Intelligence)로 발전할 수 있는 열쇠라고 볼 수 있는 개념입니다. 즉, Meta-Learning은 적은 데이터로 모델을 훈련하면 관련 Task를 모두 수행할 수 있도록하는 학습 방법입니다. (Task-A에 대해 훈련을 시키면, Task-B에 대응되는 별도의 추가 훈련 없이 수행 가능)
Few-Shot Learning: 적은 데이터로 좋은 성능을 도달하는 방법론을 탐구하는 연구입니다. 이는 종종 n-way k-shot learning이라고 불리는데, 여기서 n은 support set에 있는 class의 개수이고, k는 support set에 있는 각 클래스당 갖고 있는 데이터 개수입니다. 이 설명에 있어서는 뒤에가서 다시 자세히 설명을 드리겠습니다.
간혹 few-shot learning의 개념과 transfer learning의 개념에 있어 혼동하는 분들이 있어 한 번 설명을 드리면, Tranfer Learning은 사전학습된 모델을 기반으로 특정 테스크에 맞는 적은 dataset을 활용하여 Fine-Tuning하는 알고리즘인 반면에 Meta-Learning의 few-shot learning은 Transfer Learning보다 빠르게 Adapataiokn을 찾는 알고리즘입니다. 따라서, Few-shot Learning이 훨씬 더 적은 dataset을 targeting하여, 빠르게 최적화가 이루어질 수 있도록, "Generalization"에 초점이 맞춰진 알고리즘이라고 생각하시면 됩니다.
2. Few-shot Learning
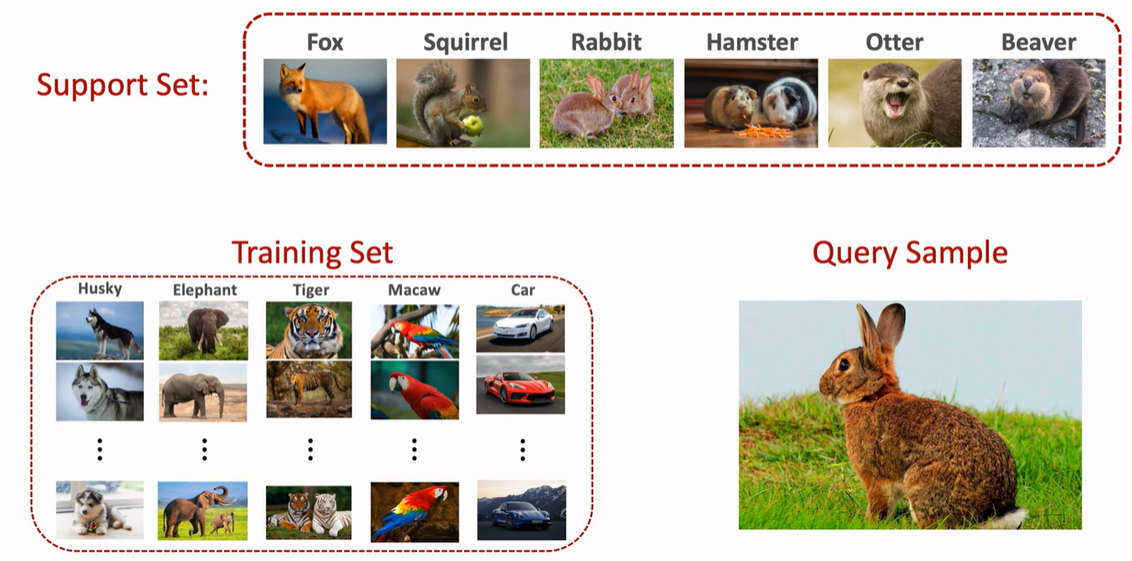
Few-shot learning의 전반적인 개요는 아래 그림을 보면 확인할 수 있습니다. training set이 다음과 같고 query data가 토끼 그림으로 다음과 같이 있을 때, 이 query를 분류 혹은 판단할 때 사용되는 데이터셋이 support set입니다. Few-shot Learning의 목적은 매우 적은 dataset으로 이루어진 support set을 기반으로 query data를 분류 및 예측하는 것입니다.
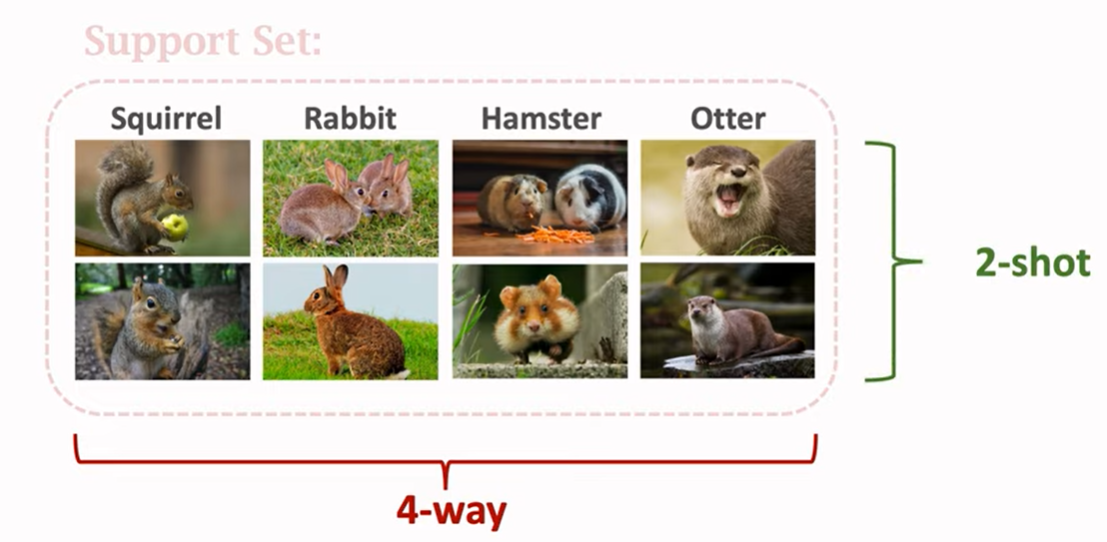
support set은 모델이 test할 시에 사용되는 데이터셋인데 이는 위에 말씀을 드린 바와 같이 n-way k-shot으로 구성되어 있는데, 여기 아래 보이는 예시 그림에서는 4개의 class와 2개의 shot으로 구성되어 있으니 4-way 2-shot learning이라고 볼 수 있습니다. 그리고 여기서 k값이 0이게 되면, 이는 zero-shot으로 볼 수 있습니다.
2.2 Dataset
이렇게 few-shot learning에서는 support set이라는 새로운 dataset을 필요로하기 때문에, 기존 딥러닝에서 사용되는 데이터셋에 대한 용어도 달라지게 됩니다.
Meta-Train Dataset --> Meta-Test Dataset
어떻게 보면, few-shot learning에서는 "학습" 과정이 두번 있다는 것을 알 수 있습니다. 처음 Meta-Train set을 한 번 학습한 뒤에, support set을 통해 adaptation을 학습하고, 마지막에 query를 기반으로 test set을 평가한다고 생각하시면 됩니다. 이 과정은 위에 설명했던대로 흡사 사전학습 모델을 특정 테스크에 Fine-Tuning하여 사용하는 점과 비슷하긴 하지만, 훨씬 적은 데이터를 필요로 한다는 점에서 다릅니다.
2.3 Types of Few-Shot Learning
Few-Shot Learning에 활용되는 알고리즘의 종류는 크게 세가지로 볼 수 있습니다.
1. Metric-based
2. Optimization-based
3. Model-based
2.3.1 Metric-based
Metric-based learning은 ML 방법론 중 K-means clustering과 비슷한 개념입니다. 이는 support set에 있는 데이터와 query와의 metric (ex.cos-sim)을 측정하는 방식입니다.
Idea: "Learn a Similiary Function"
1) Meta-train dataset에서 similarity function을 학습
2) 학습한 similiarity function을 예측에 사용
- suppport set과 query와의 유사도 계산

Siamese Network 구조를 통해 해당 방법을 주로 학습시킵니다.
아래 예시를 보면 같은 호랑이 객체에 대해서는 유사도가 높게 학습하고,
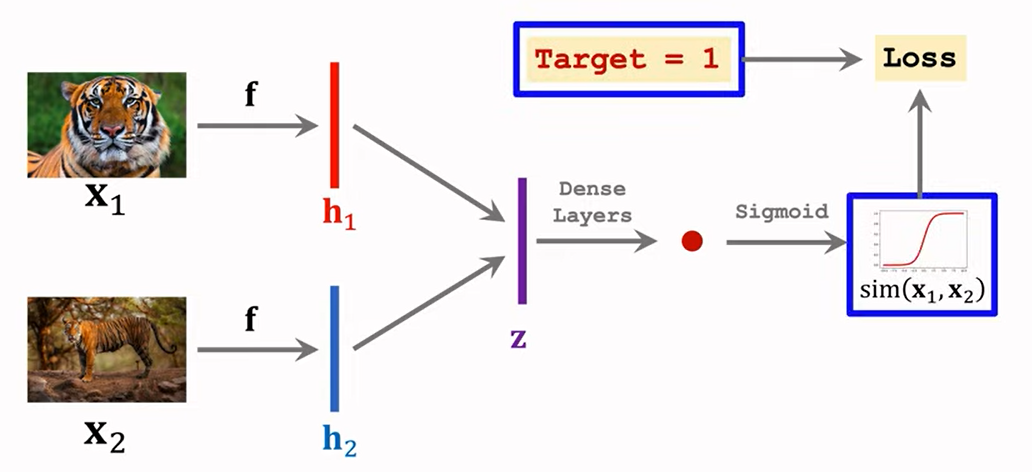
앵무세와 코끼리 간의 서로 다른 객체에 대해서는 유사도가 낮게 선정되게끔 학습합니다.
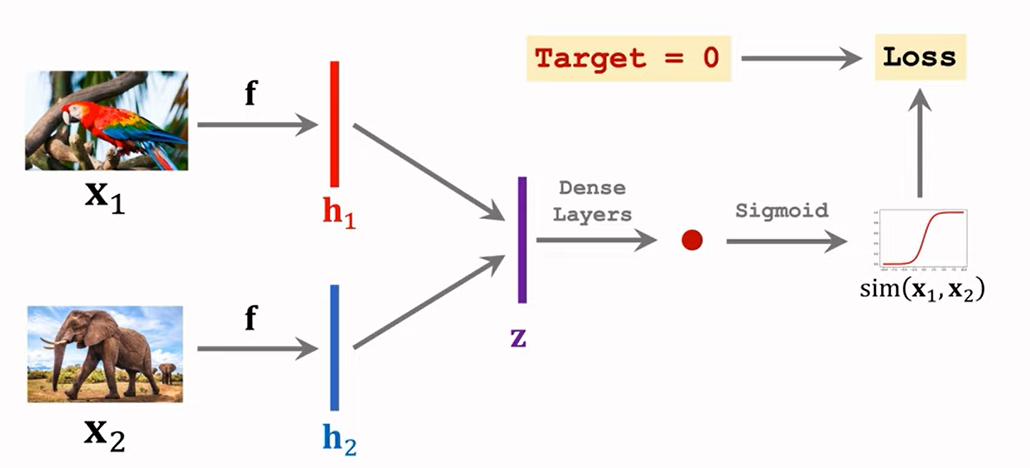
이런 식으로 large scale Meta-train set에 대해 학습을 진행을 하면, "Unseen Data"에 대해서도 support set을 통해 query와 같은 객체인지 여부에 대해서 분류할 수 있게 됩니다.
2.3.2 Optimization-based
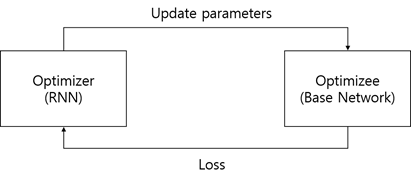
일반적인 Deep Learning based model을 학습할 때, 우리는 large scale dataset을 학습시키고 gradient descent 알고리즘과 같은 방법론으로 loss를 minimize하는 식으로 optimization을 진행합니다. 하지만, few-shot learning에서는 support set의 size가 매우 작기때문에 위와 같은 방법을 사용하기에는 적절하지 않습니다. 따라서, 해당 방법론은 base network와 meta network 두 가지를 활용해서 optimizer가 스스로 학습할 수 있게 만듭니다.
Base Network: 실제 task에 있어 train을 진행
Meta Network: Base Network를 optimize
"Learning to Learn gradient descent by gradient descent": 메타러닝의 알고리즘
-
일반적인 모델 학습
gradient descent을 활용하여 parameter update -> minimzie loss -
메타러닝 모델 학습
RNN 계열의 모델을 활용하여 parameter update -> RNN 계열의 모델을 optimization하기 위해 gradient descent 활용 -> minimize loss
(즉, 모델을 RNN을 통해 optimize하고, RNN은 gradient descent로 학습)
학습하는 것을 학습!!!
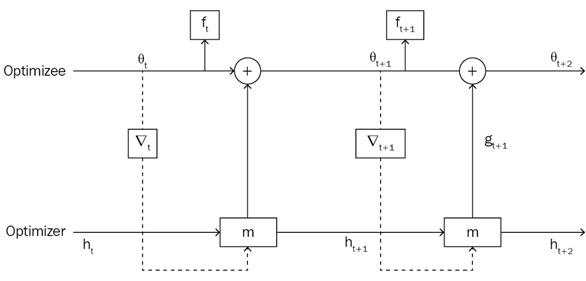
그림을 보면 optimizer를 통해 최적화된 parameter를 찾고, 이것을 optimizee에게 넘겨준다. optimizee는 해당 넘겨받은 parameter를 통해 loss를 연산하고 gradient descent를 통해 값을 최적화 하고 다시 optimizer로 넘겨준다. 이와 같은 방법을 계속 반복하면서 아래 그림과 같이 학습을 진행합니다.
MAML (Model-Agnostic Meta-Learning)
MAML은 gradient descent를 통해서 모든 모델에 적용이 가능한 일반화된 알고리즘입니다.
아래 update 식을 확인해보면, 타우i task에 대해 f(세타) 모델을 최적화하는 것을 볼 수 있습니다. 저희가 알고있는 일반적인 gradient descent 알고리즘을 통해 parameter를 얻을 수 있습니다.
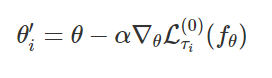
하지만 few-shot learning의 목표는 하나의 task에서만이 아닌 여러 task에서 일반화를 잘 나타내주는 optimal parameter를 찾는 것입니다.
따라서, 이전의 타우i task에서 얻은 parameter를 활용해 새로운 데이터셋을 통해 meta-objective를 update해주면서 optimal parameter를 찾을 수 있습니다.
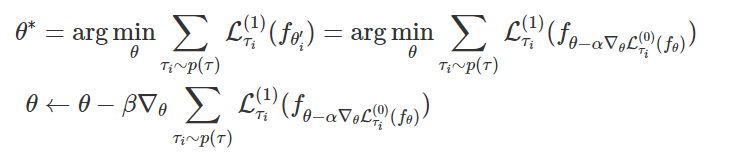
해당 내용을 아래 그림과 함께 다시 설명을 드리겠습니다.
먼저 MAML은 각기 다른 task로 부터 최적화를 수행해주고, 각 task별로 최적화된 모델로부터 gradient를 계산해 추후에 서로 다른 task에 대해 빠르게 최적화를 할 수 있는 공통의 초기 weight를 찾는 방식으로 학습을 진행합니다. 아래 그림에 나타난 회색 화살표가 "각 task별로 최적화된 모델로부터 gradient를 계산"하는 것을 의미하고 (overfitting 방지는 겸) + 검은색 화살표는 "추후에 서로 다른 task에 대해 계산이 되었던 gradient에 대한 gradient update를 실시한 것"을 의미하고 + 마지막으로 회색 점선은 "공통의 초기 weight에서 특정 task로 적응적으로 빨리 학습하여 각 task별 optimal weight을 찾는 과정"을 보여줍니다.
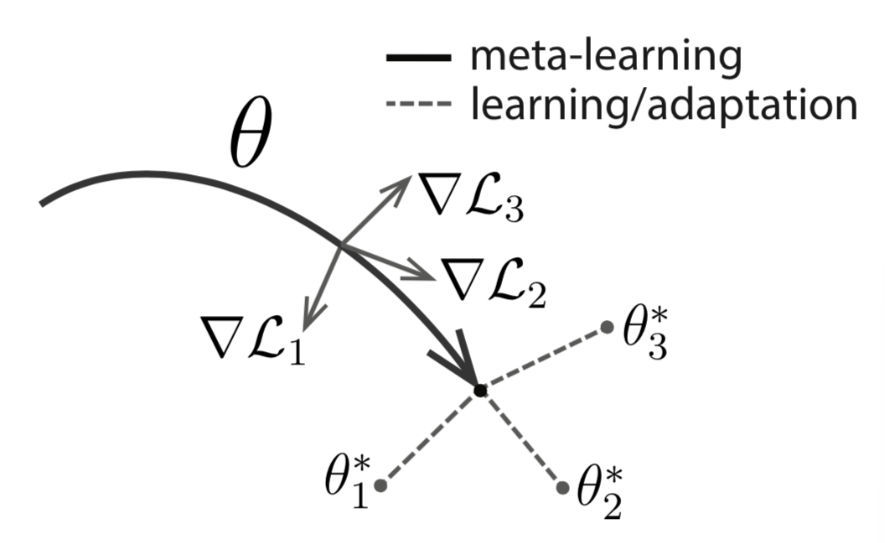
아래는 위에 과정을 코드로 설명한 수도 코드입니다.

2.3.3 Model-based
mode-based 방법론은 모델의 내부 구조를 변형시키거나 또다른 meta-learner 모델을 활용함으로써 몇번의 training step만 가지고 network의 parameter를 빠르게 학습하는 방법입니다.
MANN (Memory-Augmented Neural Networks)
별도의 storage buffer를 통해 network가 새로운 데이터에 대해 빠르게 학습하고, 나중에도 해당 정보들을 까먹지 않고 사용하는 모델을 MANN이라고 합니다.
(RNN계열의 LSTM,GRU는 내부 memory만 사용하기 때문에 MANN이라고 볼 수 없다)
아래 아키텍쳐와 같이 별도의 storage buffer를 갖고 있습니다. 이렇게 모델에 별도의 memory를 추가해줌으로써 새로운 정보에 대해 빠르게 처리하고 나중에도 해당 정보를 잊지 않을 수 있습니다.
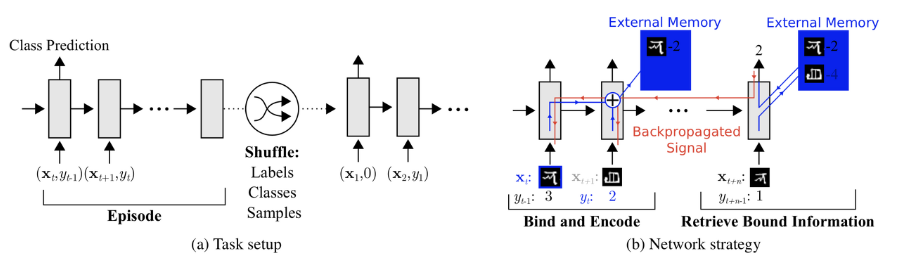
3. Applications
3.1 Computer Vision

3.2 Natural Language Processing

3.3 Audio Processing

Etc.
robotics, healthcare, others.
Reference
https://www.youtube.com/watch?v=hE7eGew4eeg
https://www.youtube.com/watch?v=4S-XDefSjTM
https://engineering-ladder.tistory.com/95
https://research.aimultiple.com/few-shot-learning/
https://talkingaboutme.tistory.com/entry/DL-Meta-Learning-Learning-to-Learn-Fast
https://velog.io/@tobigs-gm1/Few-shot-Learning-Survey#1-few-shot-learning-introduction
https://velog.io/@tobigs16gm/Few-Shot-Learning
