Support Vector Machines(SVM)
SVM은 분류, 회귀 등에 사용되는 비지도 학습 방법으로 다양한 장점이 존재하고 있다.
- 고차원에서 효율적임
- 샘플 수보다 차원수가 더 클 때 효율적임
- 결정 함수 내 훈련 포인트의 하위셋을 사용하기에 메모리 사용도 효율적임
- 결정 함수에서 여러가지 다른 커널 함수에 사용될 수 있어 다용성이 높음
그러나, SVM은 다음과 같은 단점이 존재하고 있다.
- 만약 샘플 수보다 특징 수가 훨씬 더 크면 커널 함수에서 과적합을 피하고 정규화하는데 어려움이 존재함
- SVM 은 직접적으로 가능한 지표를 제공하지 않기에 비싼 5-fold 교차검증 방식으로 실행함
분류(Classification)
SVM이 분류를 진행하는 과정에서 이진 혹은 다중 분류를 진행하는 경우에 SVC, NuSVC, LinearSVC를 사용한다.
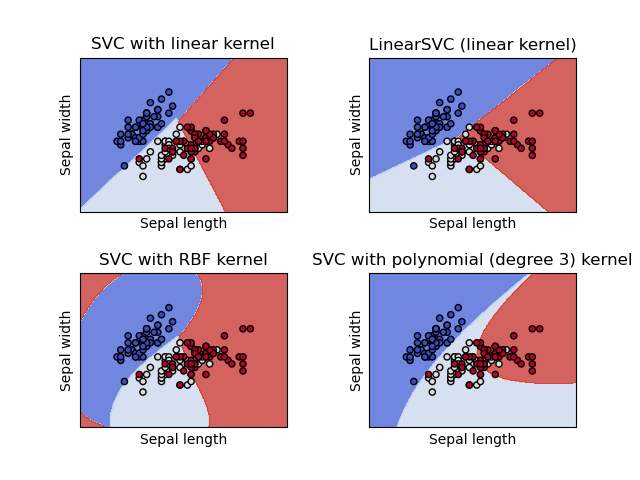
SVC와 NuSVC는 비슷하지만 약간씩 다른 파라미터와 수학 공식으로 미세한 차이가 존재한다. 반대로 LinearSVC는 선형 커널로 분류할 때 더 빠르게 실행한다는 장점이 있지만 kernel이라는 파라미터를 받지 않는다. 그 이유는 이미 선형 커널(Linear Kernel)로 가정하기 때문이다. SVC가 받는 X, Y의 형식은 아래와 같다.
- X : (n_samples, n_features)
- y : (strings or integers) 형식의 라벨이 있는 (n_samples)
기본 함수
from sklearn import svc
X = [[0, 0], [1, 1]]
y = [0, 1]
clf = svm.SVC()
clf.fit(X, y)
# 학습 후에 예측하는 경우
clf.predict([2, 2])
# support vectors를 가져오는 경우
clf.support_vectors_
# support vectors 지수를 가져오는 경우
clf.support_
# support vectors 각 클래수의 개수를 가져오는 경우
clf.n_support_수학 공식을 보며 차이점을 알아보자
SVM은 3차원을 2차원으로, 고차원을 저차원으로 줄이면서 인간이 알아볼 수 있는 구분 선, 공간을 삽입해 직관적으로 데이터들이 분류할 수 있도록 한다.
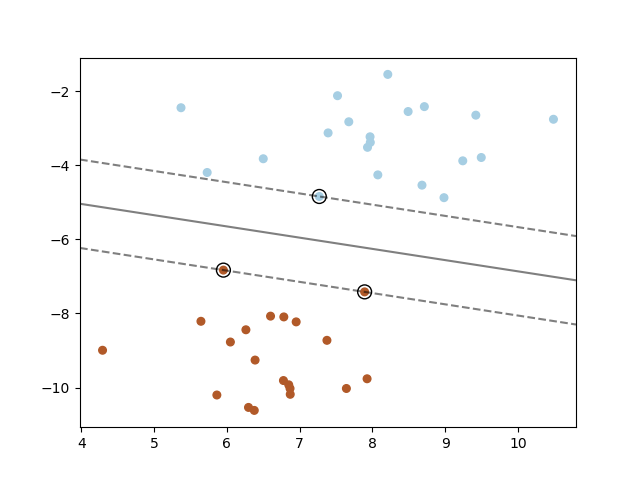
이 사진만 보더라도 빨강과 파랑의 최적의 경계선이 보이는데 3차원을 2차원으로 줄였을 때 분류하는 모습을 알 수 있다.
1. SVC (including NuSVC)
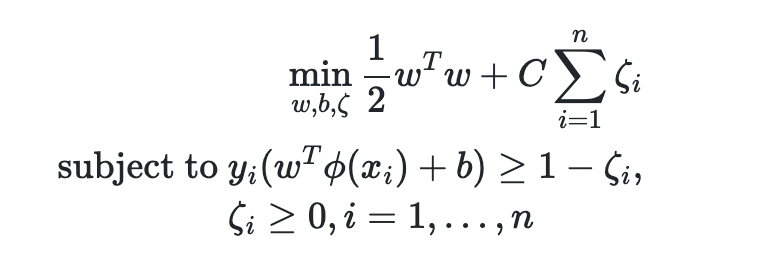
여기서 w^2가 최소가 되는 경계지점을 찾는 것이 중요하다. 그러나 고차원으로 넘어가면 계수나 차원 공간을 다루는 것들에 대하여 최적화 문제가 발생할 우려가 존재한다. 그래서 최종적인 SVC의 결정함수 형태를 살펴보게 되면 아래와 같은 모습을 볼 수 있다.
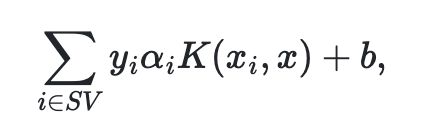
예측 클래스에 맞는 요소들에 대하여 샘플을 통해 파라미터들을 접근하며 평가할 수 있다.
NuSVC는 아까 특징에서 설명할 때도 파라미터 일부 추가한 것 외에는 거의 SVC와 비슷하기에 굳이 설명하지 않도록 하겠다.
2.LinearSVC
SVC에서 선형 커널 함수로 가정해 커널을 진행하는 것으로 수학 공식은 아래와 같다.
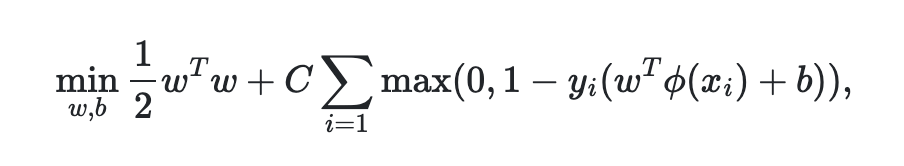
여기에 hinge loss가 있는데 이는 "maximum-margin" 분류를 하는 과정에서 사용이 되는 손실 요소이다. 예를 들어, t=+1 or -1이고 score가 y로 나타났을 때, 그림과 유도 식은 다음과 같다.
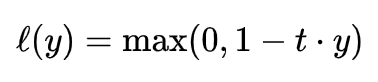

최종 값이 0이하일 때는 1로 고정되고 0 이상일 때는 주어진 식을 기준으로 점점 낮아지는 것을 알 수 있다.
즉, 기존 SVC에서 hinge loss 방식을 적용해 나타난 것임을 알 수 있다.
다중 클래스 분류
SVC, NuSVC는 다중 클래스 분류에서 1대1 접근을 통해 실행을 한다.
- n_classes * (n_classes - 1) / 2 개수의 분류가 생겨 각각이 2개의 클래스에서 데이터를 가져와 훈련한다.
기본 함수
X = [[0], [1], [2], [3]]
Y = [0, 1, 2, 3]
clf = svm.SVC(decision_function_shape='ovo')
clf.fit(X, Y)
dec = clf.decision_function([[1]])
dec.shape[1] # 4*3/2 = 6
>>> 6
clf.decision_function_shape = "ovr"
dec = clf.decision_function([[1]])
dec.shape[1] # 4 classes
>>> 4LinearSVC는 1대다 접근으로 분류를 진행한다.
lin_clf = svm.LinearSVC()
lin_clf.fit(X, Y)
>>> LinearSVC()
dec = lin_clf.decision_function([[1]])
dec.shape[1]
>>> 4불균형 데이터 문제
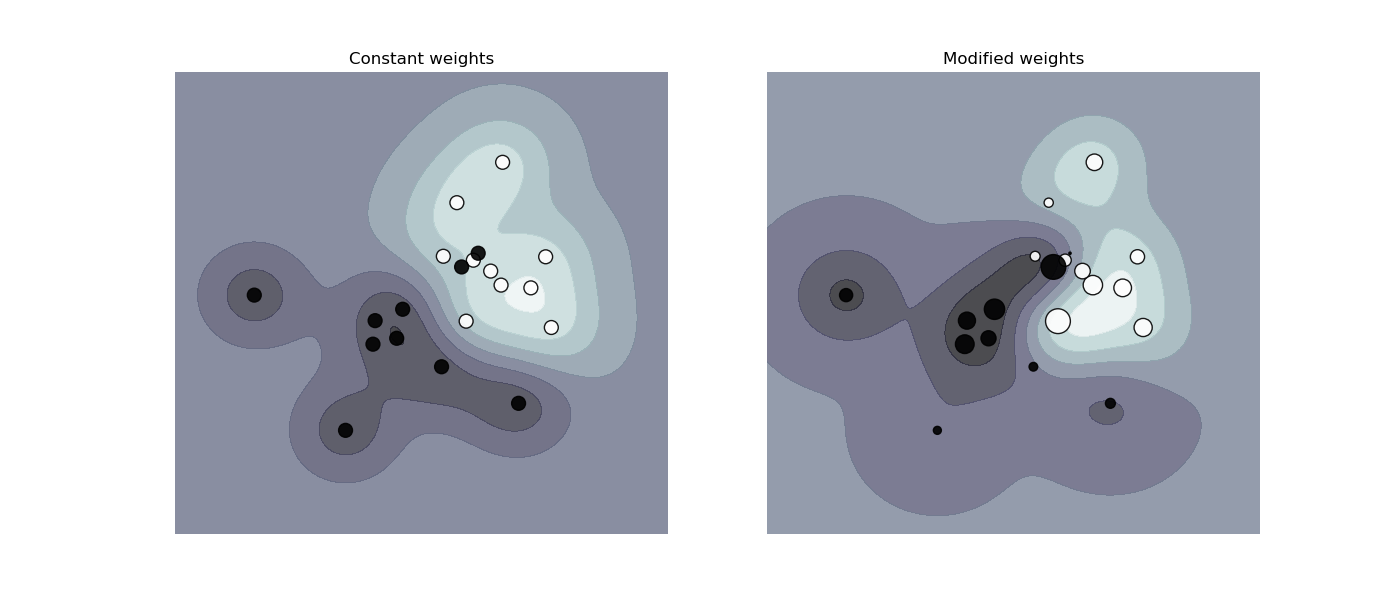
불균형 데이터 내에서 분류를 진행할 때 class_weight, sample_weight가 사용된다.
- 다른 함수를 살펴봐도 weight가 들어간다는 것은 불균형 데이터 셋의 weight로 어느정도 조절을 한다는 의미이다.
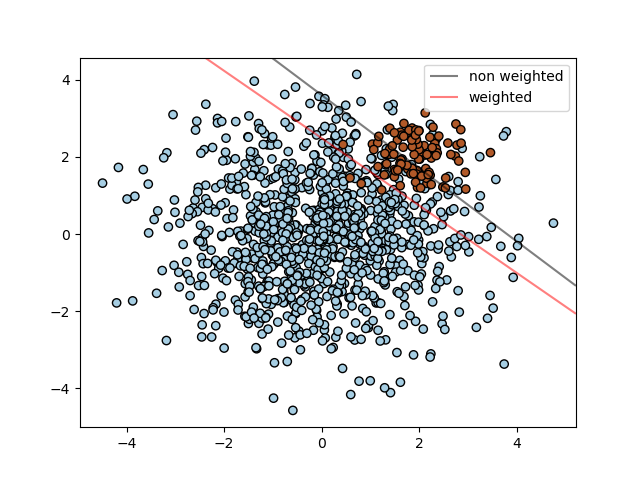
이 그림만 봐도 조절이 된 경우와 안된 경우를 살펴보면 분류하는 과정에서 큰 차이가 존재하고 있음을 알 수 있다.
SVC, NuSVC, SVR, NuSVR, LinearSVC, LinearSVR, OneClassSVM 모두 weight를 조절할 수 있다.
회귀(Regression)
회귀 과정에서도 분류와 비슷하게 훈련 세트의 하위 세트를 이용해 학습을 한다. 종류도 SVR, NuSVR, LinearSVR로 Classification -> Regression이 된 것을 알 수 있다.
기본 함수
from sklearn import svm
X = [[0, 0], [2, 2]]
y = [0.5, 2.5]
regr = svm.SVR()
regr.fit(X, y)
>>> SVR()
regr.predict([[1, 1]])
>>> array([1.5])SVM 꿀팁!
1. 데이터 복사를 피하라!
- 특정 방식을 통과하는 데이터가 연속적이거나 Double 정확성을 보이지 않으면, C 를 실행하기 전에 복사를 미리 해야한다.
2. 커널 사이즈 조절
- 커널 사이즈는 실행 시간에 매우 큰 영향을 준다. 주로 RAM을 이용하기에
cache_size를 설정하는 것을 권장한다.
3. C 세팅하기
- C는 기본적으로 1이지만 만약 관찰되는 소음이 많으면 줄이면서 정규화하는 것이 좋다.
- 그러나, 가장 좋은 것은
StandardScaler과 같은 조정 함수를 통해 데이터 스케일을 줄이고 나서 SVM을 실행하는 것을 권장한다.
지금까지 공부하고 작성한 것은 기본 Scikit-Learn Docs를 기반으로 되어있습니다.
