자세한 프로젝트 과정은 밑에 있는 링크를 통해 보시면 좋을 것 같습니다.
😁프로젝트 진행 코드 및 설명 링크입니다!!
이번 프로젝트 에서는 핀테크 산업에서 머신러닝 모델의 흥미로운 사용 사례를 다뤄볼려합니다.
실무에서 사용하는 데이터와 비슷한 데이터를 다뤄볼려 하는데 이러한 데이터들은 대부분 정제되어 있지 않기 때문에 모델 준비를 위해 많은 전처리가 필요합니다.
시각화는 matplotlib, seaborn 데이터 처리는 numpy 를 사용해 다뤄봅시다.
또한 모두 분류 형식으로 분류에 대한 모델과 유효성 검사 및 튜닝의 다른 방법도 알아봅시다.
1. 개요
앱 행동 분석을 통해 고객을 subscribing products( 대표적인 예로 youtube premium, pandora premium 등이 있습니다. )로 안내하는 모델 입니다.
유튜브 프리미엄으로 예를 들자면 유투브에서 프리미엄을 가입하지 않은 고객들에게 1~2개월 무료 사용을 홍보하곤 합니다. 이것이 구독 제품을 사용하게 하려는 마케팅입니다. 이 프로젝트의 대상은 회사의 무료 제품을 사용하는 고객입니다. 제품 자체는 업종 불문 무엇이든 상관없지만 무료, 유료 버전 둘다 있어야 합니다.
가장 중요한 프로젝트의 목표는 무료 유저를 유료 멤버로 전환하는 것입니다.
즉 우리에게 주어진 업무는 유료 버전의 앱을 등록할 가능성이 없는 유저를 식별하는 모델을 구축하는 것이라 생각하면 편합니다.
-> 이런식으로 한다면 회사에서는 식별한 사용자를 대상으로 마케팅을 하여 예산을 사용하고 확실히 유료로 전환할 것 같은 유저들은 대상에서 제외하여 비용을 절감할 수 있을 것입니다.
2. 데이터
모바일 앱을 제공하는 기업에 근무한다고 생각한다면 풍부한 데이터 특히 모든 사용자의 앱 행동 데이터에 접근할 수 있습니다. 이 데이터는 방문한 앱 화면으로 특정지어집니다.
앱 사용 데이터는 앱을 처음 실행한 후 24시간 동안의 데이터입니다. 회사의 무료 평가판은 24시간이 지나면 만료되기 때문입니다. 회사는 무료 평가판이 종료된 직후 마케팅 캠페인을 시작하려고 하므로 앱 사용 데이터와 같은 특정 데이터만 필요 합니다.
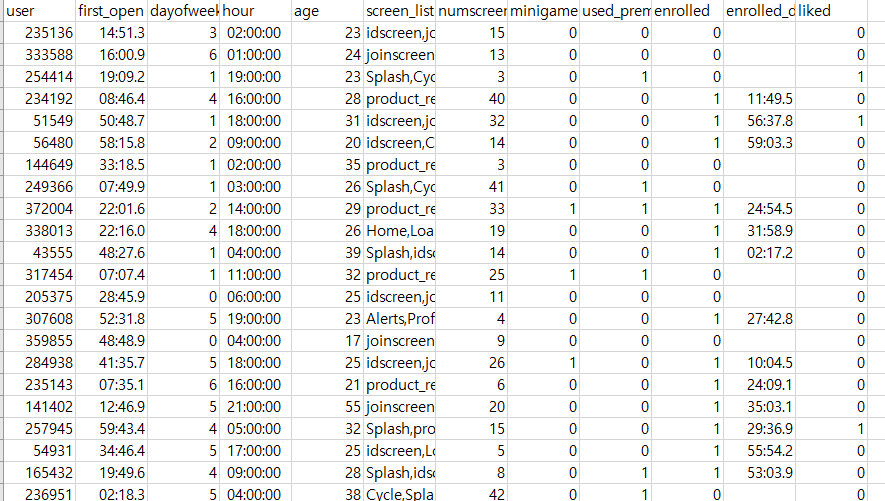
각 feature 들을 알아보겠습니다.
- user : 숫자로 표현된 index
- first_open : 유저가 최초로 앱을 연 날짜와 시간
- dayofweek : 일~토 이 0~6으로 표현 ( 0=일요일, 6= 토요일 )
- hour : 앱을 처음 연 시각 (first_open 과 상관관계가 있어보임)
- age : 나이
- screen_list : 유저가 처음 24시간 동안 방문한 모든 단일 화면 이름 ( 중요한 feature이라고 생각됌 )
쉼표로 구분된 문자열 -> 데이터 처리를 해봐야겠구나
- numsreens : screen_list에 표시되는 화면의 수
- minigame : 앱 내 유저가 원하는 경우 미니게임을 할 수 있는데 미니게임을 한번이라도 한다면1 아니면 0
- liked : 앱 내 어떤 기능에 좋아요를 눌렀다면 1, 아니면 0
- used_premium_feature : 앱 내 유료 기능을 사용해 본적이 있다면 1, 아니면 0
- enrolled :
프로젝트의 반응변수즉, 체험판 종료 후 유료 제품 등록 여부로 등록하면 1, 아니면 0 - enrolled_date : 유료 제품에 가입했다면 가입한 시각
Correlation matrix code
개인적으로 자주 사용하는 예쁜 모양의 상관행렬 heatmap 코드이다.
# correlation matrix -> 각 필드간의 관련성을 알아볼 수 있습니다. 머신러닝 모델을 구축할 때 각 필드들은 독립적이라는 가정을 합니다.
# 특성들이 종속되어 있으면 이 가정은 깨어지고 모델이 이상하게 변합니다.
sns.set(style = 'white', font_scale=2) # 배경을 만드는 코드
corr = dataset2.corr() # Compute the correlation matrix
mask = np.zeros_like(corr, dtype=np.bool)
mask[np.triu_indices_from(mask)] = True # generate a mask for the upper trangle -> 행렬이 대칭이기 떄문에 한쪽만 보이게
f, ax = plt.subplots(figsize=(18,15))
f.suptitle('Correlation Matrix', fontsize=40) #set up the matplotlib figure
cmap = sns.diverging_palette(220,10, as_cmap=True)
sns.heatmap(corr, mask=mask, cmap=cmap, vmax=.3, center=0, square=True, linewidths=.5, cbar_kws={'shrink':.5}, annot=True)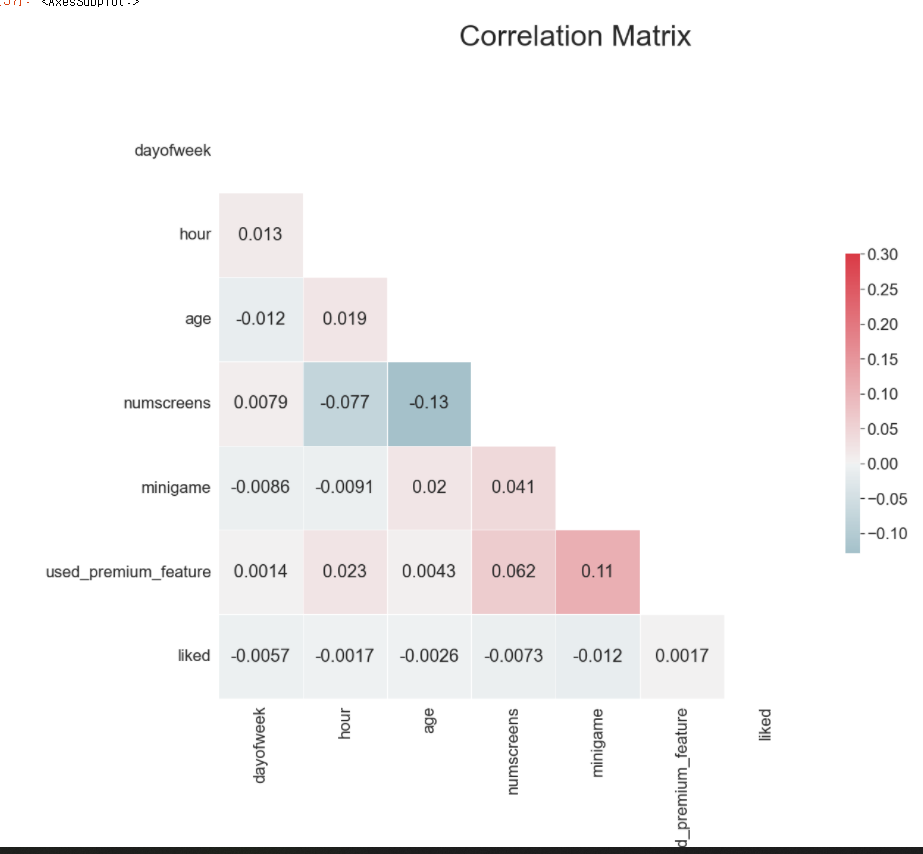
😎 마치며
데이터 전처리, 시각화, 모델구축 ( 위 링크에 코드들 설명과 프로젝트 과정 자세히 작성 되어 있습니다.!! )을 하며 어떤 user들이 subscribing을 할지 알아보았습니다. 마지막으로는 각 유저들과 enrolled feature를 매칭하면서 마무리 까지 잘 된 모습입니다.
이러한 과정은 다양한 분야에 실용성 있게 사용 될 수 있다고 생각합니다. 유투브 premium으로 생각해보자면, 프리미엄 가입을 하지 않은 사람에게 집중적으로 마케팅 비용을 투자할 수 있으며, 이미 가입되어 있지만 탈퇴가 예상되는 사람들에게는 50% 할인쿠폰 등 유지 서비스에 집중 할 수 있을 것 같습니다.
accuracy = 77% 정도 나타났습니다. 나중에 grid search 까지 사용하여 parameter들을 최적화 한다면 어떨지 궁금하니 다음에 해보도록 하겠습니다!
감사합니다.
