예전에 읽었던 Feature Pyramid Networks의 후속 연구로 보이는 Panoptic Feature Pyramid Networks를 읽고 정리한 글이다. 논문의 제목에서 알 수 있듯이 panoptic segmentation을 위해서 새롭게 제시하는 feature pyramid network 아키텍쳐이다.
1. Introduction
Panoptic FPN에 대해서 설명하기 전에, 먼저 Panoptic segmentation이 뭔지 먼저 설명해야할 것 같다.
Segmentation에는 instance segmentation과 semantic segmentation이라는 종류가 있다. Panoptic segmentation까지 세가지 segmentation 외에 다른 종류가 더 있는지는 모르겠지만, semantic segmentation보다 instance segmentation이 좀 더 어려운 task여서 초기의 segmentation은 semantic segmentation(FCN)이었고, 최근의 segmentation은 instance segmentation(mask r-cnn같은 two-stage들)이 주로 연구되고 있는걸로 알고 있다. (아닐 수도 있음🧐)
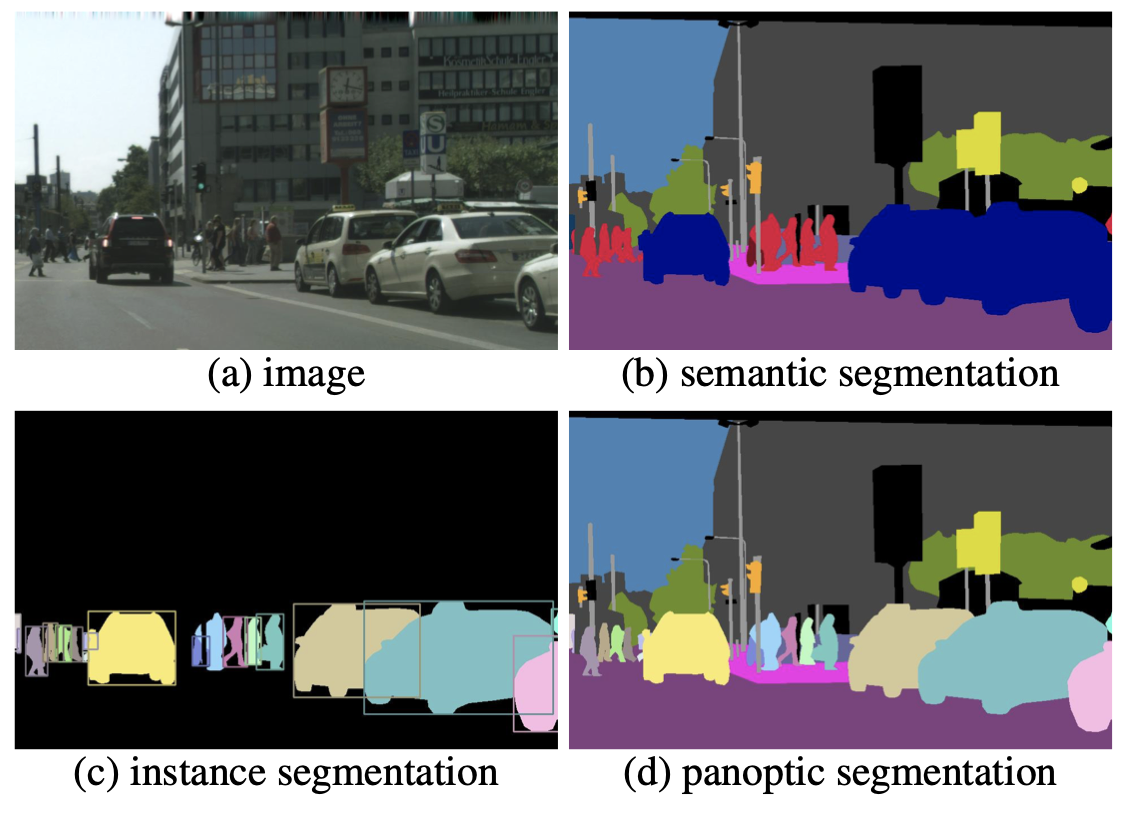
어쨌든 사진을 통해 object instance를 찾아내고 그 segment를 찾아내는 instance segmentation과 모든 픽셀에 class label을 달아주는 semantic segmentation의 차이를 볼 수 있다. 그 중 panoptic segmentation은 이 두 segmentation을 합쳐서 완전하고 segment 정보가 충분히 담긴 scene segmentation을 만들어 내는 task이다.
최근 instance segmentation과 semantic segmentation 이 두 task를 함께 해결하려는 관심이 생기고 있지만, 아직은 연산을 공유하는 것 없이 그냥 따로따로 모델을 사용하는 것에 불과했다. 그래서 이 논문에서는 instance segmentation과 semantic segmentation을 아키텍쳐 레벨에서 통합하고, 이를 기반으로 panoptic segmentation task를 해결한다.
2. Panoptic Feature Pyramid Networks
Instance segmentation과 semantic segmentation을 동시에 해결하기 위해서 논문 저자가 가장 먼저 접근했던 방식은 FPN backbone 기반 instance level segmentation 아키텍쳐에 semantic segmentation branch를 하나 더하는 것이었다.
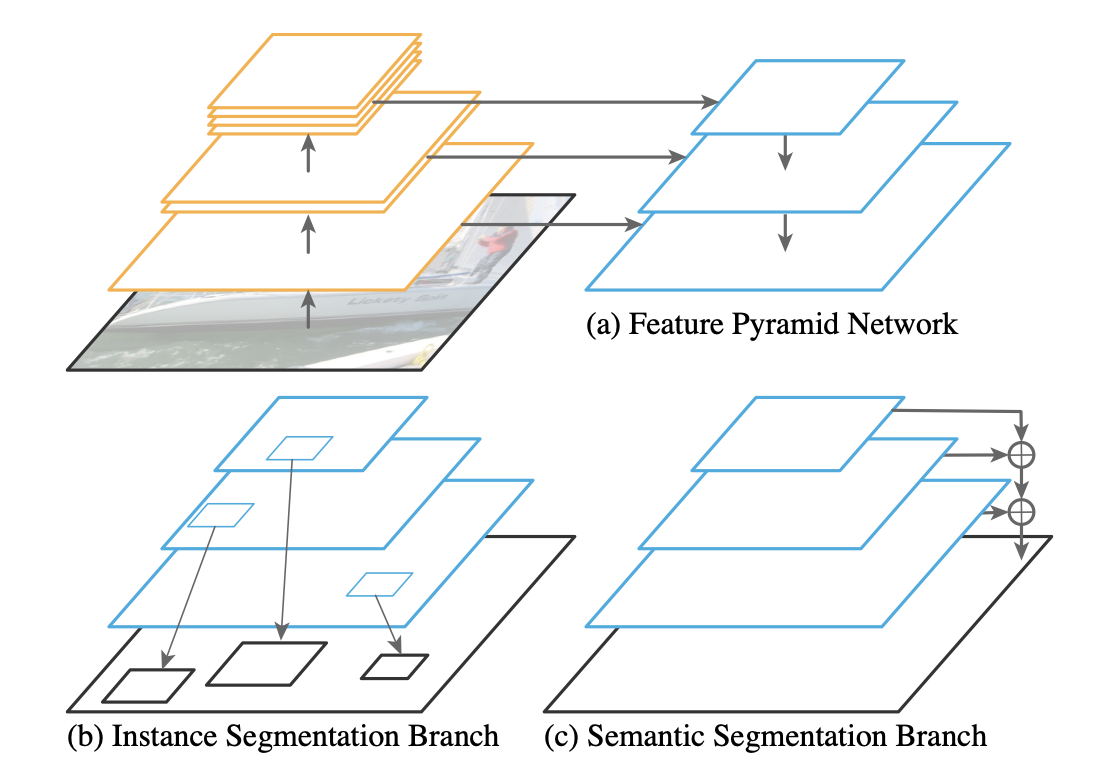
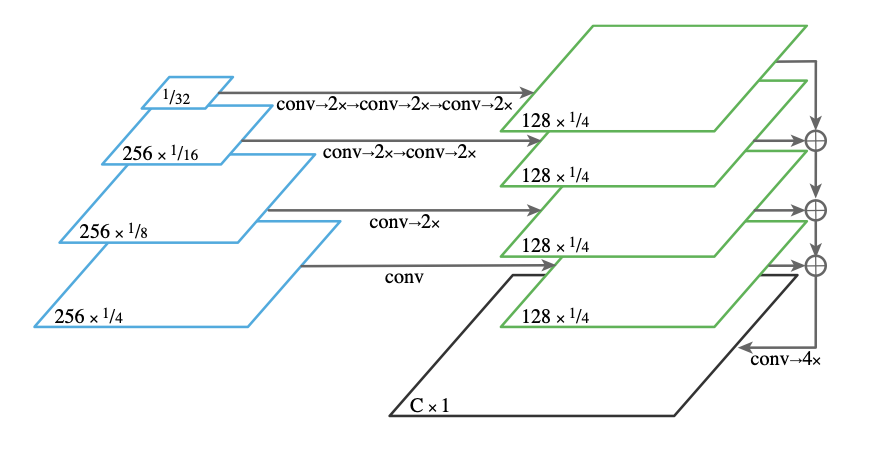
주어진 이미지에서 resolution을 줄였다가 다시 늘리면서 다양한 resolution의 feature map을 얻어내는 FPN과 그 다양한 feature map에서 프로포절을 찾고 RoIAlign으로 그 위치를 찾아내는 mask r-cnn의 구조(instance segmentation branch)에 semantic segmentation branch를 더한 것이 Panoptic FPN의 구조이다.
2.1. Model Architecture
전반적인 모델의 구조는 위에서 다 설명했지만 각 모듈별로 조금 더 상세하게 설명하려한다.
♠︎ Feature Pyramid Network
FPN paper에서 소개하는 FPN의 구조를 거의 그대로 가져와서 사용한다. FPN에서는 input image의 1/4 ~ 1/32배 resolution을 가지는 feature pyramid를 만들어 낸다.
♣︎ Instance segmentation branch
Instance segmentation branch의 경우 기존 Mask R-CNN에서 object를 찾고 그 segment mask를 찾아냈던 방법과 동일하다.
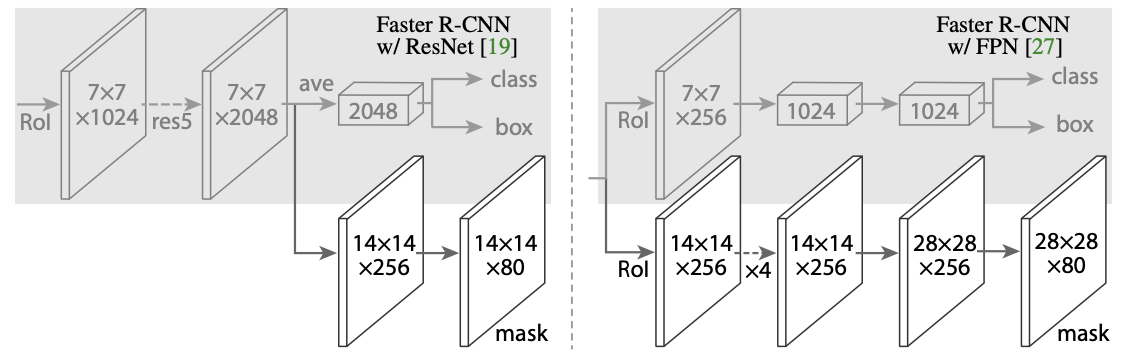
Mask R-CNN head의 구조를 보면 어떤 식으로 각 instance에 대해 segmentation 연산을 수행하는지 알 수 있을 것이다. (상단의 이미지는 프로포절 후 RoIAlign된 각각의 RoI에 대한 연산-head-의 구조이다.)
♥︎ Panoptic FPN
앞서 언급했듯이, panoptic FPN은 기존의 아키텍쳐를 살짝 변형해 pixel-wise semantic pridiction을 함께 수행하겠다는 목표를 가지고 있다. 이렇게 pixel-wise로 세밀한 task를 수행하기 위해서는 feature map이 가지고 있어야 하는 특징이 있다.
(1) 세밀한 구조를 잘 잡아내기 위해서 충분히 high resolution일 것
(2) 충분한 rich semantics information을 통해 class label 잘 예측할 것
(3) 다양한 크기의 stuff를 찾아내기 위해 multi-scale의 정보 가지고 있을 것
FPN은 이러한 조건들을 모두 만족할 수 있었기에, semantic segmentation branch에 FPN을 활용했다고 한다.
♦︎ Semantic segmentation branch
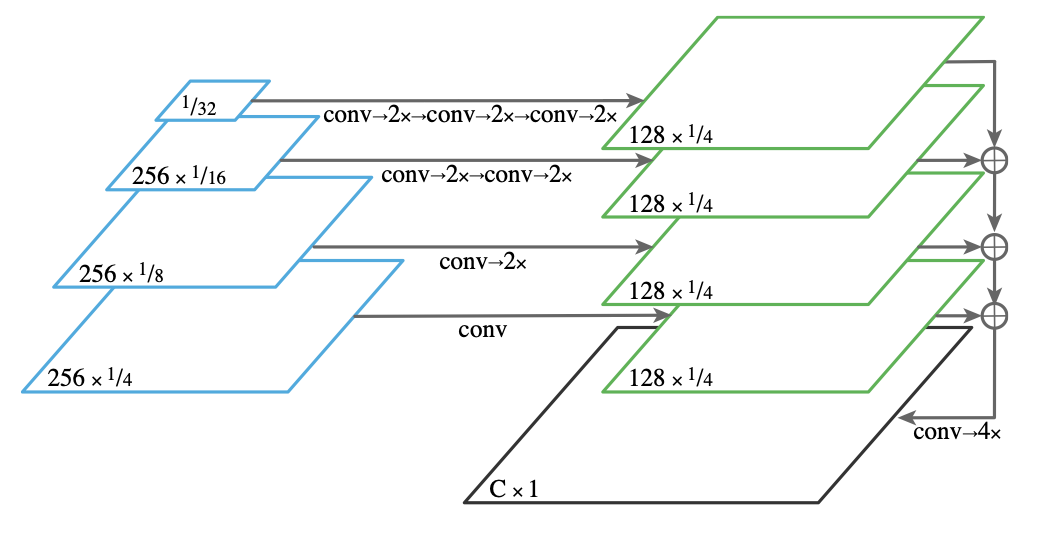
상단의 그림에서 왼쪽 파란색 네모들은 FPN level feature map들이다. 이 다양한 resolution의 feature map들을 일정한 크기(1/4)로 upsampling한 후 element-size summation하고, convolution과 upsampling 해주면 pixel-wise semantic segmentation output이 완성된다.
정확하게 어떤 연산(3x3 conv, group norm, ReLU, bilinear upsampling...)을 사용했는지 확인하기 위해서는 논문을 직접 확인해보면 좋을 것 같다.
2.2. Inference and Training
☻ Inference
Panoptic output format에서는 주어진 이미지에 대해서 pixel별로 어떤 class인지 알아야 하고, instance id도 찾아야 한다. 이때 중복되는 것을 막기 위해서 별도의 post-processing이 필요하다고 하는데 Panoptic Segmentation에서 설명하는 내용인 것 같다. 이 논문도 나중에 정리해서 올려야 겠다. (포스팅 대기큐 잔뜩 쌓여있음 😧)
☺︎ Training
Instance segmentation branch의 경우 classification loss , bounding-box loss , 그리고 mask loss 를 가진다. 그리고 semantic segmentation loss 는 픽셀간의 cross entropy로 계산할 수 있다. scale이 다른 loss들을 normalize 해준 최종 loss는 다음과 같다.
2.3. Analysis
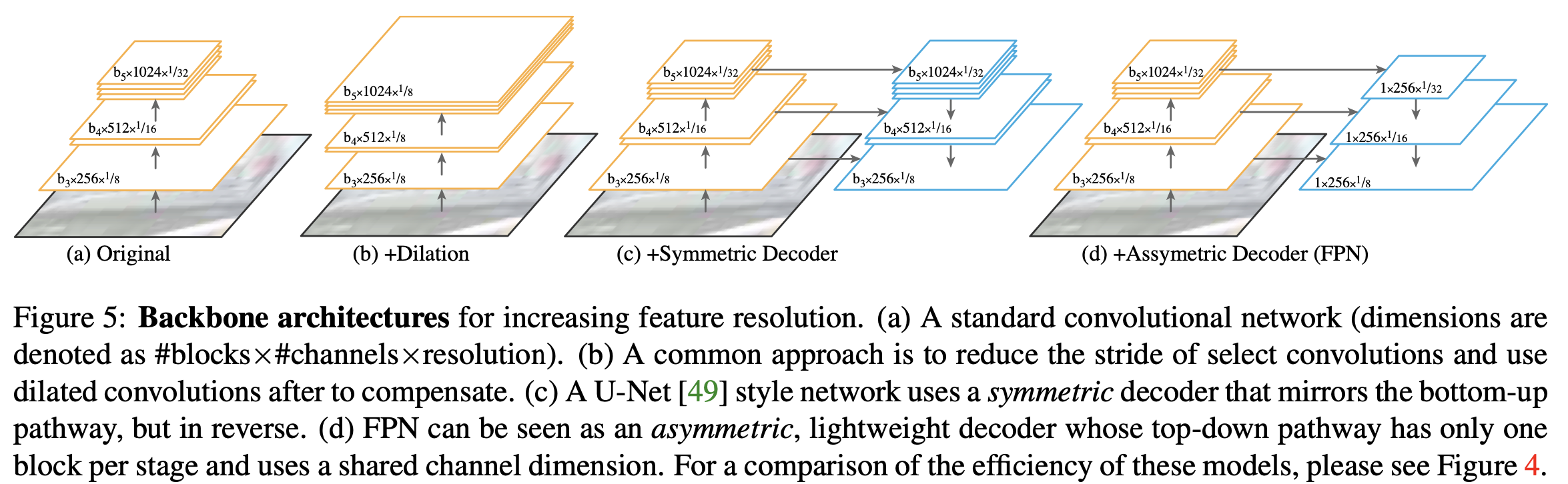
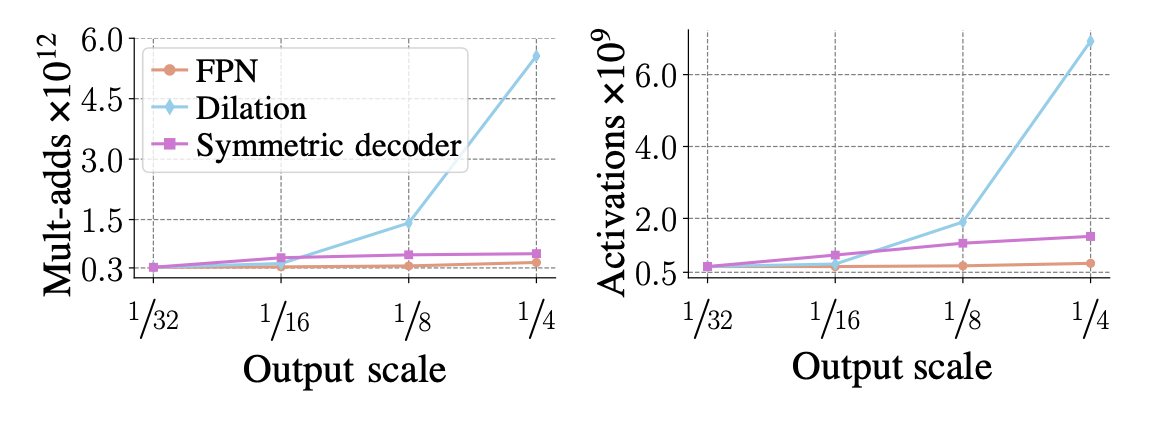
다양한 backbone 아키텍쳐와 그에 따른 연산량/효율성을 확인해볼 수 있는 figure들이다. 아래 Experiments에 넣어도 될 것 같지만.. 이 논문에서 목표한 바가 instance segmentation과 semantic segmentation을 동시에 수행할 수 있는 하나의 아키텍쳐를 제안하는 것이니 만큼, 다양한 backbone을 사용했을 때 그에 따른 효율성을 정리한 것 같다. 각각의 backbone에 따른 성능은 왜 따로 구하지 않았는지는 잘 모르겠다.. 아키텍쳐들이 다 high-resolution을 만들어낸다는 점에서 비슷할 것 같기는 하다만 그래도 dilation에 비해서 FPN을 썼을 때 성능이 비슷하거나 좋다는 걸 보였으면 더 좋았을텐데 🤷♀️
3. Experiments
이 논문에서 최종적으로 목표하는 것은 instance segmentation과 semantic segmentation을 동시에 수행할 수 있는 간단하고 효과적인 아키텍쳐를 제시하는 것이다.
이 아키텍쳐가 효과적이라는 것을 증명하기 위해서 instance segmentation의 성능, semantic segmentation의 성능, 나아가 panoptic segmentation task에서도 충분히 효과적이라는 것을 실험결과를 통해 얘기한다.
🌆 Instance segmentation
Instance segmentation의 경우 (AP averaged over categories and IoU thresholds)를 메인 평가 기준으로, 와 도 함께 평가 기준으로 삼았다.
그리고 이 task같은 경우는 기존 Mask R-CNN의 구조를 거의 그대로 사용했기 때문에 별다른 실험 table을 만들지 않은 것 같다. Loss 구할때 와 에 따른 성능변화 표만 정리되어 있길래 따로 가져오지는 않았다.
🏙 Semantic segmentation
Semantic segmentation에서는 평가기준으로 mIoU를 사용했고, 데이터는 COCO와 Cityscapes를 사용했다. COCO의 경우 fIoU를, Cityscpaes의 경우 iIoU를 함께 정리했다고 한다.
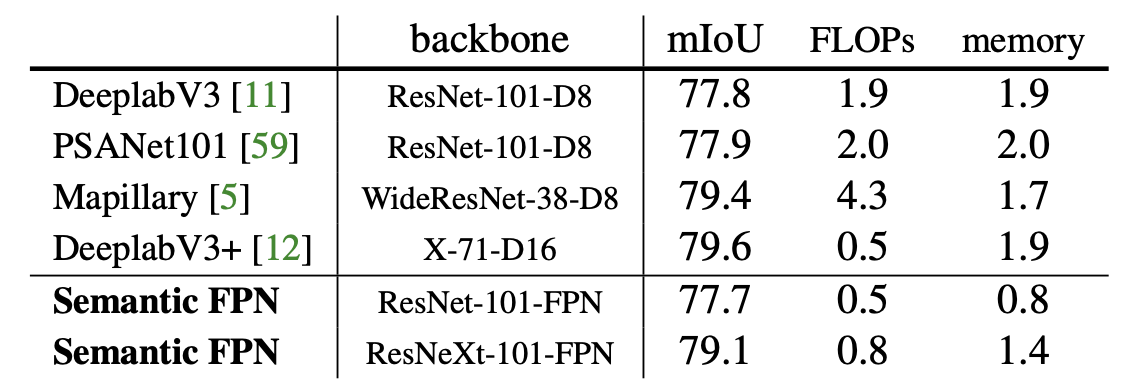
상단의 표는 Cityscapes val set에 대한 실험결과이다. semantic branch의 결과는 내가 생각했던 것보다 훨씬 괜찮았다. 사실 단순히 feature map 크기 맞추고 더해주고 conv연산 몇개 거친거라서 그렇게 연산 추가가 많지도 않은데 성능도 엇비슷하면서 연산량과 메모리 소비량이 확실히 적었다.

이거는 pyramid level에 있는 feature들의 크기를 1/4로 맞춘 다음 합칠때 element-wise로 summation하는 것과 채널 축으로 concat하는 걸 실험한건데 둘 다 성능은 비슷하게 좋다고 한다. 그 대신 단순 합이 더 효율적이기 때문에 이걸 선택했다.
사실 아직도 element-wise summation과 concat 의미 차이는 잘 이해되지 않는다..😥 예전에 교수님이 ResNet, DenseNet, Highway network 설명해주시면서 수식적으로 어떻게 차이나는지 설명해주셨었는데 그땐 이해를 못했었다 ㅜㅜ
🌃 Panoptic segmentation
PQ(panoptic quality)를 메인 평가 기준으로 삼았다. 구체적으로 PQ를 구하는 법은 여기를 확인하면 될 것 같다.

이 표는 COCO test에 대한 실험결과인데, 추가적인 테크닉을 사용하지 않았는데도 기존의 모델과 비교했을 때 성능이 뛰어남을 확인할 수 있다. (물론 지금은 많이 내려왔다)
4. Conclusion
이 논문에서는 FPN 기반 Mask R-CNN에서 시작해 간단하고 효과적인 semantic segmentation branch를 더해 panoptic segmentation을 할 수 있는 baseline 아키텍쳐를 제시한다.
Reference
