Object Detection
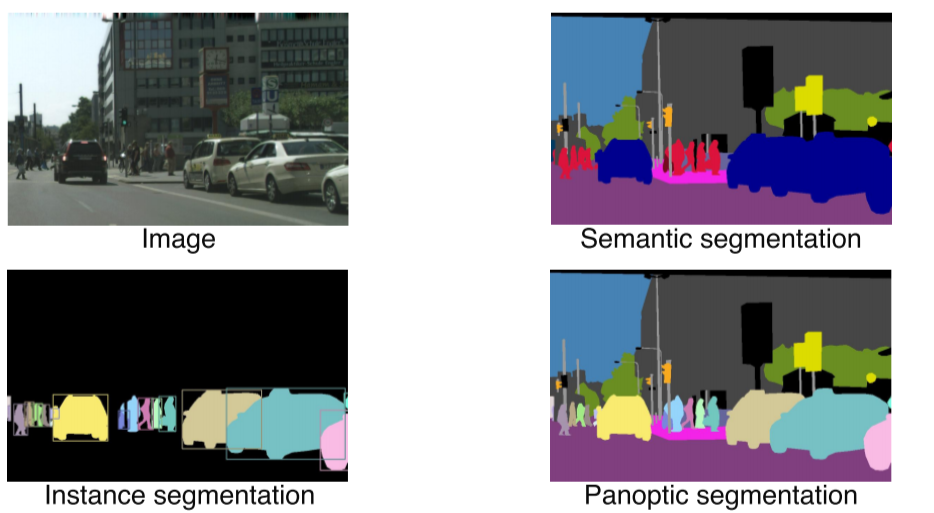
- Instance, panoptic segmentation은 똑같은 class라도 각각 개체마다 다르게 분류할 수 있기 때문에 훨씬 유용한 정보제공이 가능
- 이러한 각 객체를 구분하는 기술이 object detection
Semantic segmentation 보다 더 구체적이고 전반적인 이해를 위해 필요한 근본적 기술

- Object detection은 classification과 bounding box localization의 결합
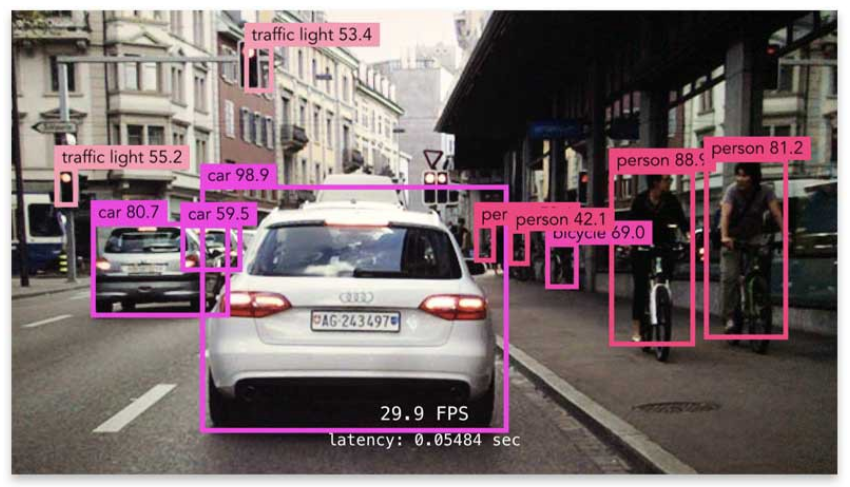

- 자동운전, OCR(Optical Character Recognition) 등 다양한 분야에 쓰이는만큼 산업적 가치가 높음
Two-stage detector(R-CNN family)

- 영상의 경계선(Gradient)을 기준으로 물체를 찾기 위한 방법
- HOG: 구역마다 edge의 분포를 모델링
- Feature를 사람이 정교하게 설계하고 학습가능한 부분인 ML 알고리즘은 간단한 linear model을 사용

- 사람이나 특정 물체뿐만 아니라 다양한 물체 후보군에 대해 영역(bounding box)을 특정해서 제안하는 방식
- 영역을 비슷한 색끼리 분할
- 잘게 분할된 영역을 색깔, graient의 특징, 분포등을 기준으로 비슷한 영역끼리 합침
- 2번 과정을 반복 후 남은 영역을 포함하는 b-box를 추출해서 물체의 후보군으로 사용
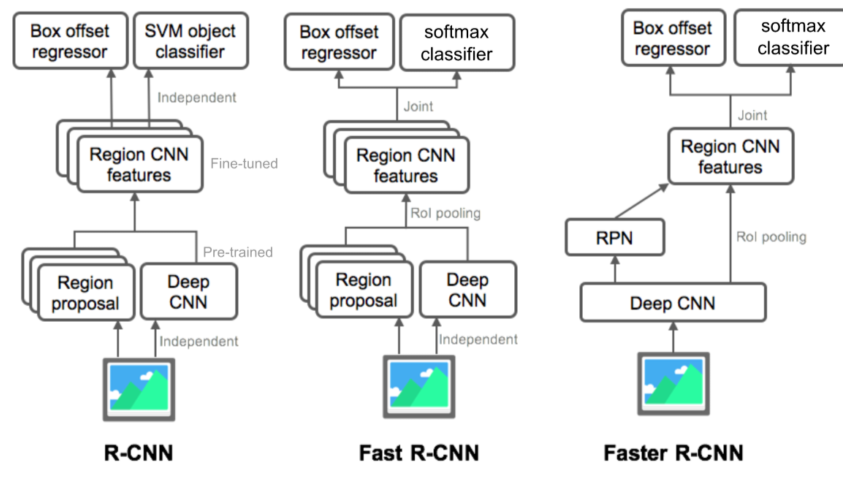
R-CNN
AlexNet이 image classification에서 큰 성능을 거둔 후 바로 object detection에 응용된 기술
AlexNet과 마찬가지로 기존의 방법들에 비해 압도적으로 높은 성능을 보여줬다
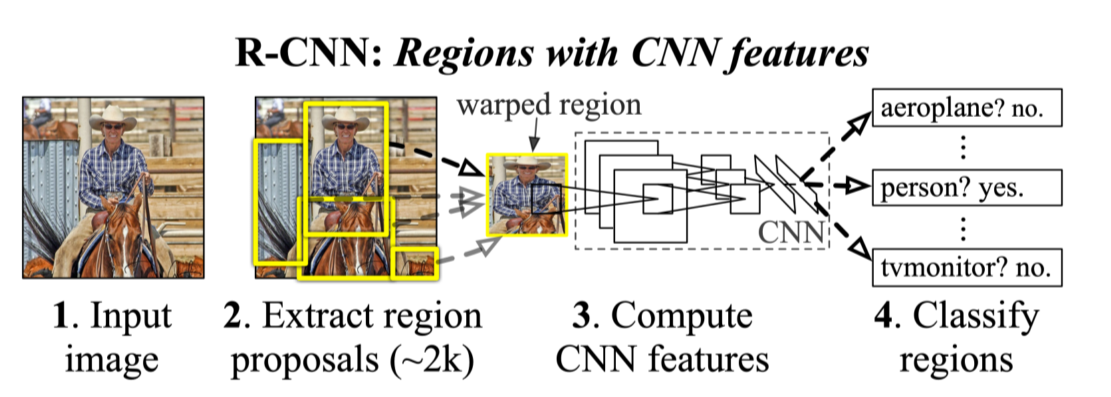
- Selective search 같은 방법으로 2k개의 region을 구함
- 1에서 구한 region을 CNN의 input으로 넣어줌
- FC layer에서 추출된 feature를 기반으로 SVM에 넣어서 결과를 출력
- 각각 region마다 CNN에 넣어야하기 때문에 속도가 굉장히 느림
- Region proposal은 selective search 같은 인간이 설계한 별도의 방법을 사용했기 때문에 data만 갖고 성능 향상에 한계가 있음
Fast R-CNN
R-CNN의 단점을 개선하고자 기존 저자들이 제시한 방법
영상 전체에 대한 feature를 한번에 추출하고 이를 재활용해 여러 object를 detect하게 해줌
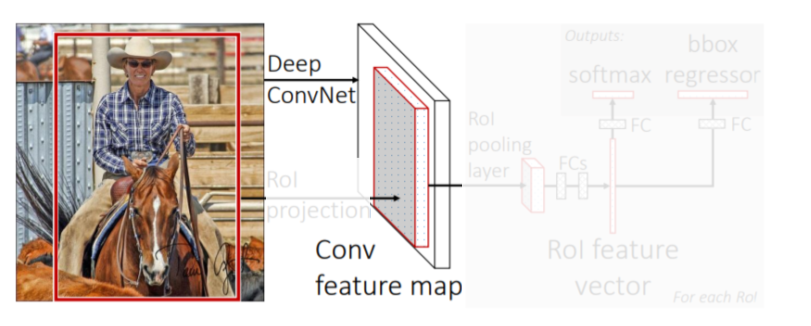
- CNN에서 convolution layer까지 feature map을 미리 뽑아둠
conv layer만 거친 feature map은 tensor 형태를 갖고있다
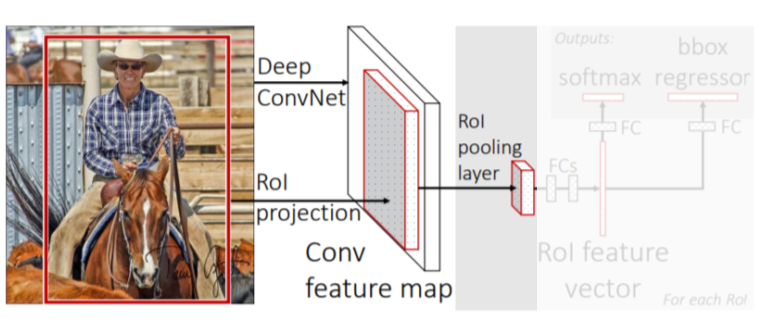
- RoI(Region of Interest) proposal이 제시한 물체의 후보 위치들(bounding box)을 feature map에 넣어서 feature를 추출
추출된 feature는 일정한 size를 가지도록 resampling됨
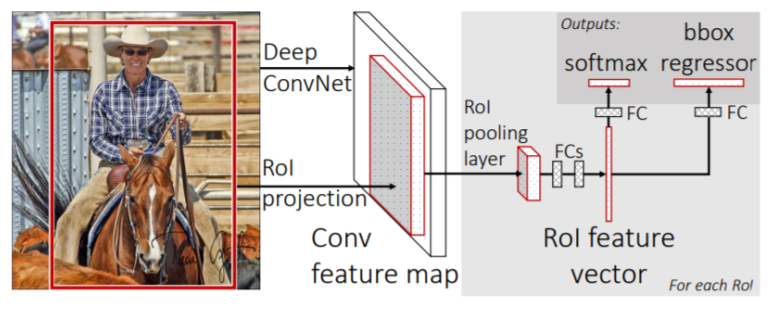
- 3개의 fc layer로 더 정밀한 class와 b-box를 찾음
- 최대 R-CNN보다 18배 빠른 성능
- 하지만 여전히 region proposal은 별도의 방법을 사용했기 때문에 data만으로 성능을 높이는데 한계가 있었음
Faster R-CNN
Region proposal을 NN 기반으로 대체해서 최초의 end-to-end model이 됨
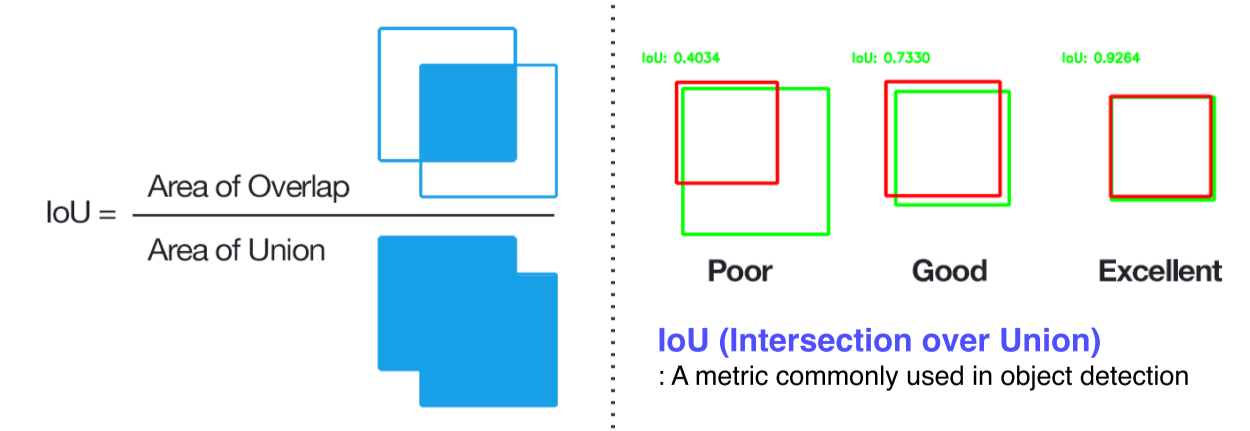
IoU: Intersection of Union
두 영역의 overlap을 측정하는 기준
이 수치가 높을수록 두 영역이 잘 결합했다고 판단
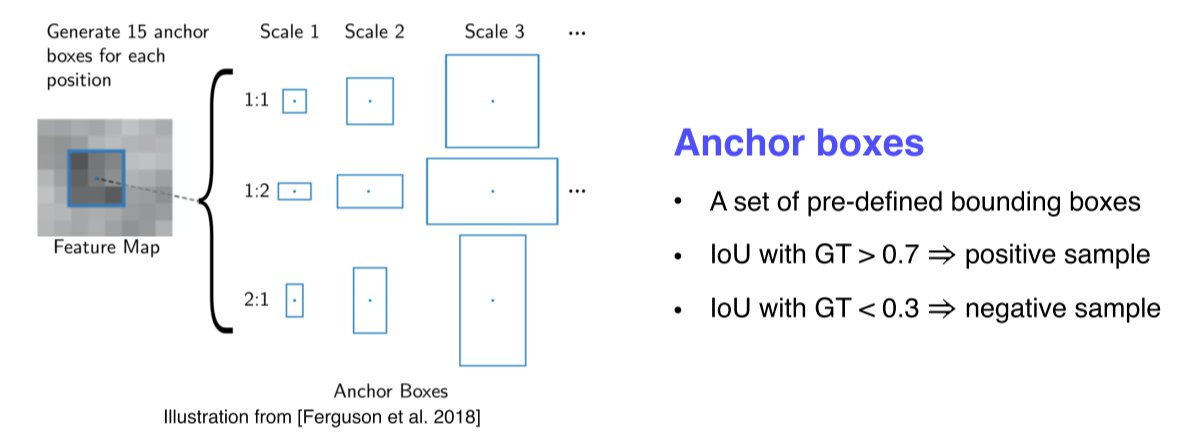
Anchor box: 각 위치에서 발생할 것 같은 box들을 정의해둔 후보군
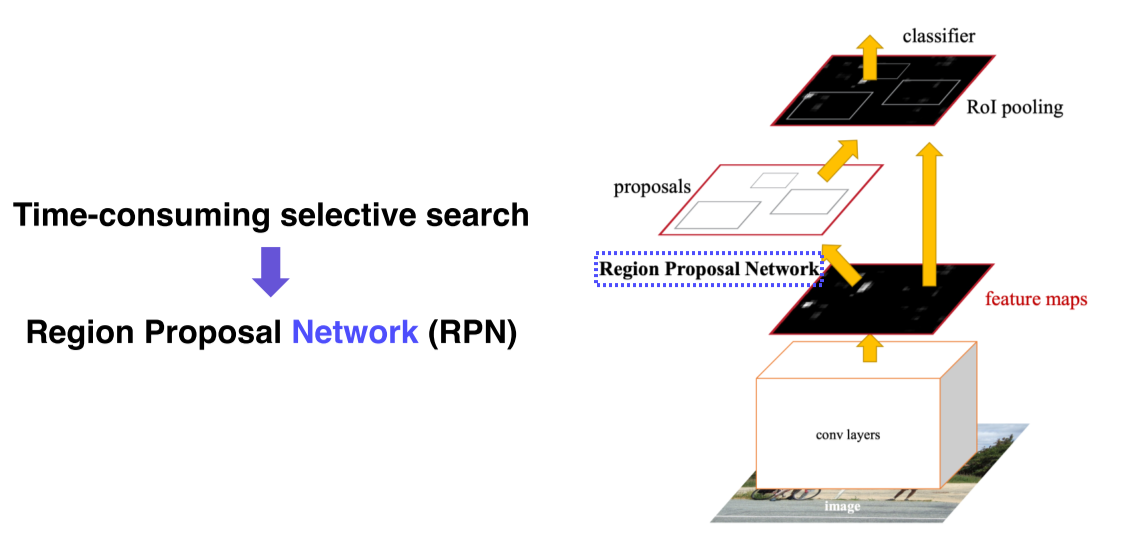
- Image에서 공유되는 feature map을 미리 뽑아두고, RPN에서 region proposal을 여러개 제안
- 그 region proposal을 바탕으로 RoI pooling을 실시해서 classification과 b-box regression을 수행
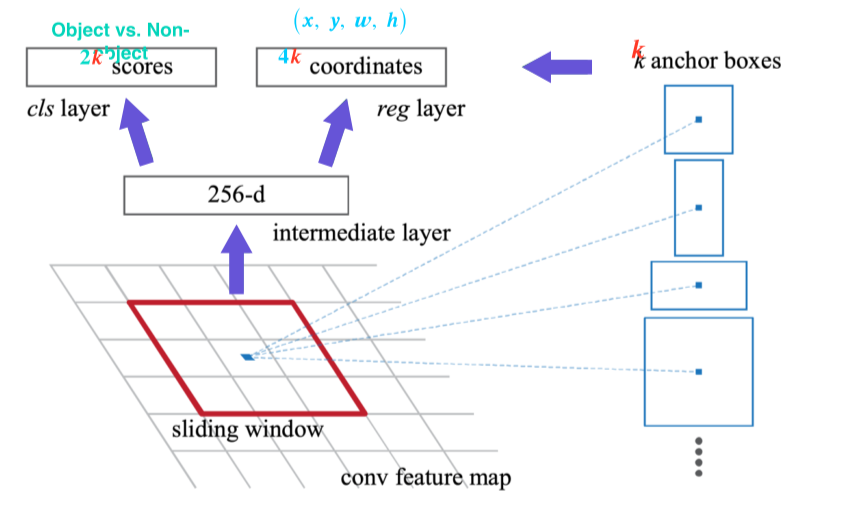
- Feature map에서 fully convolutional하게 window sliding하면서 매 위치마다 k개의 anchor box를 고려
- window에서 256 dimension의 feature vector를 추출하고, vector를 바탕으로 object 유무를 판별하는 2k개의 classification score와 b-box의 정교한 위치를 regression하는 4k개의 output을 출력
- 분할정복을 위해 적당한 양의 대표적인 anchor box를 미리 만들어두고, detail은 regression을 통해 얻음
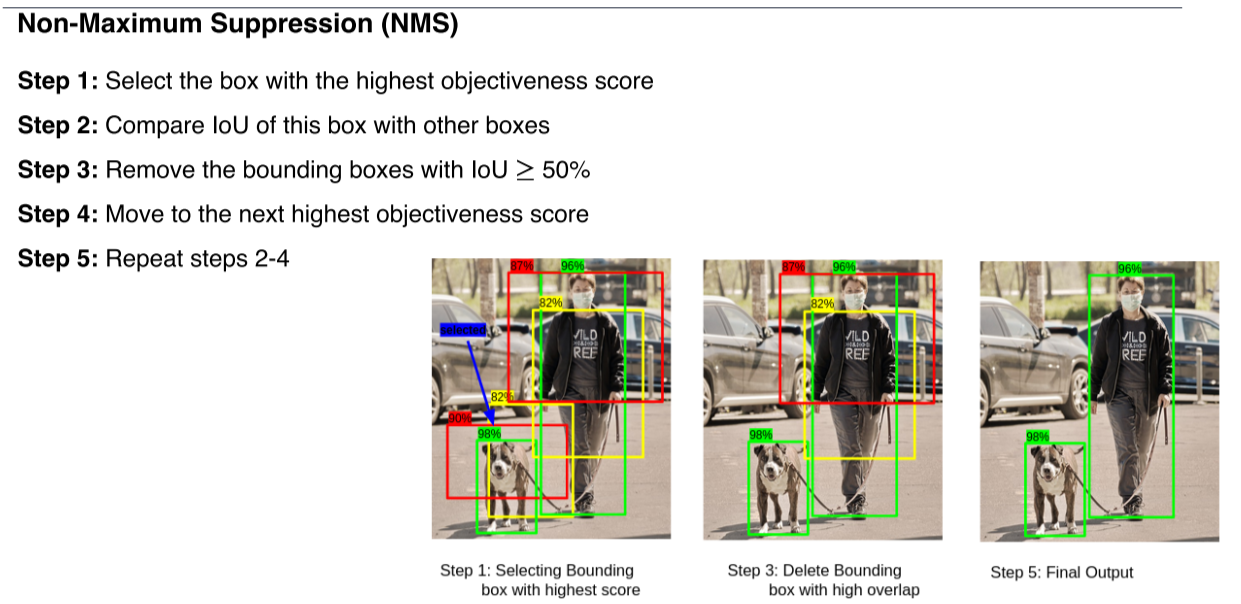
- RPN은 진짜 많은 region을 propose하기 때문에 이를 효과적으로 filtering하기 위한 방법이 필요
Summary
Single-stage detector
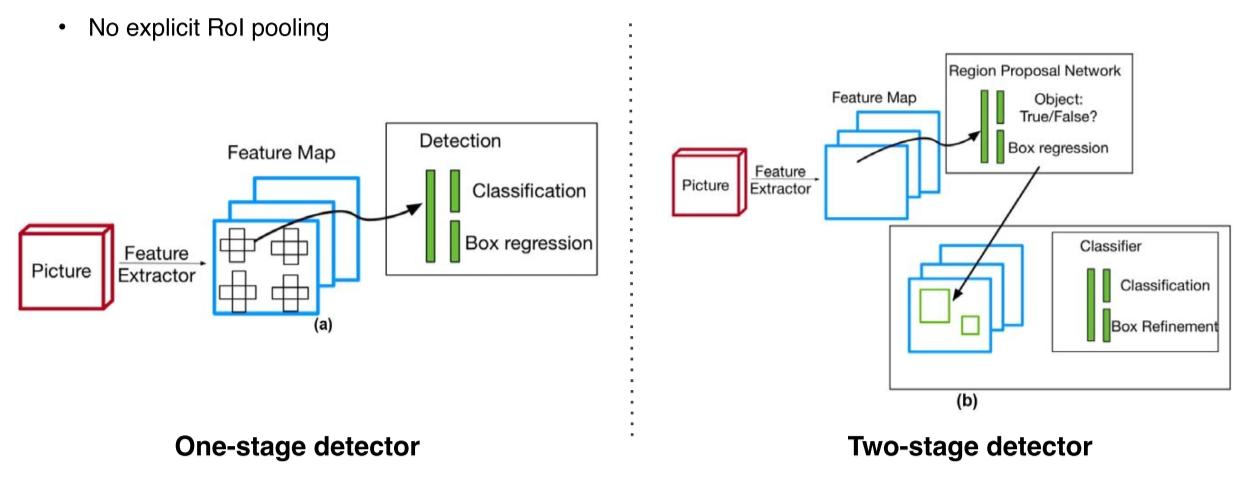
- 정확도를 좀 포기하더라도 속도를 높여서 real-time detection이 가능하도록 설계
- RoI detect가 따로 없음
YOLO
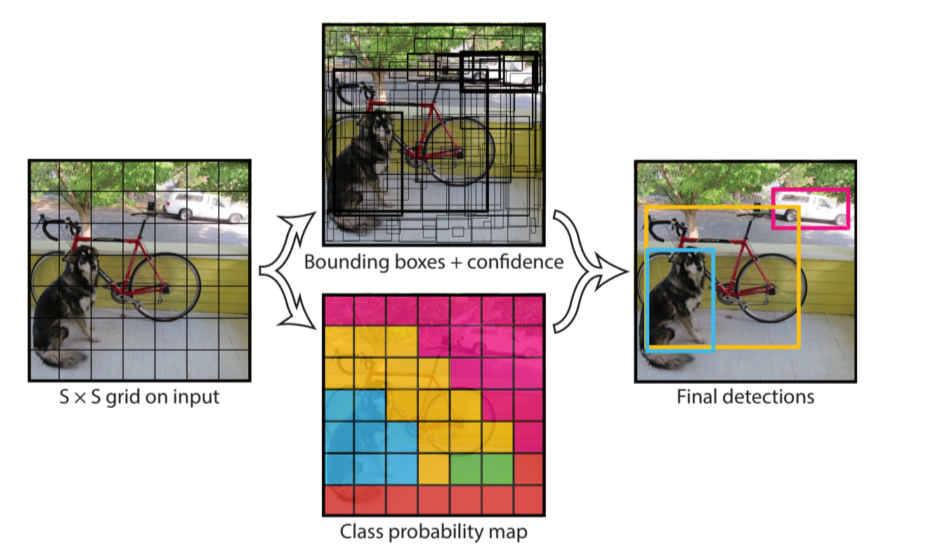
- b-box와 class를 나눠서 판단
- 최종 결과는 NMV를 거친 b-box를 출력
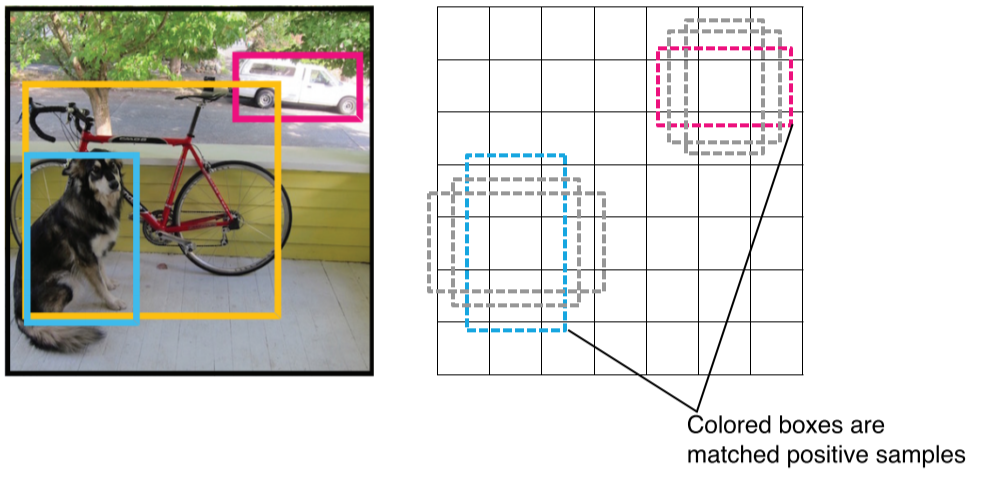
- 학습시킬땐 ground truth와 match된 b-box와 학습 label를 positive로 간주
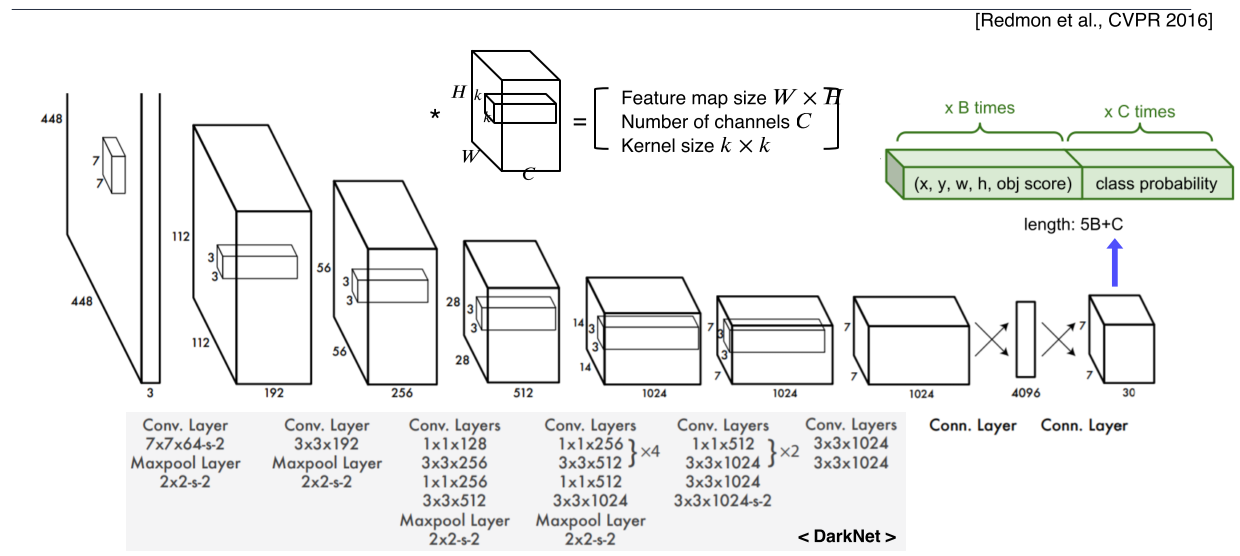
- 최종 결과는 7x7 x 30 channel
b-box anchor는 2개 --> x, y, w, h, obj score x 2 = 10 channel
object class는 20개를 고려 = 20 channel
SSD
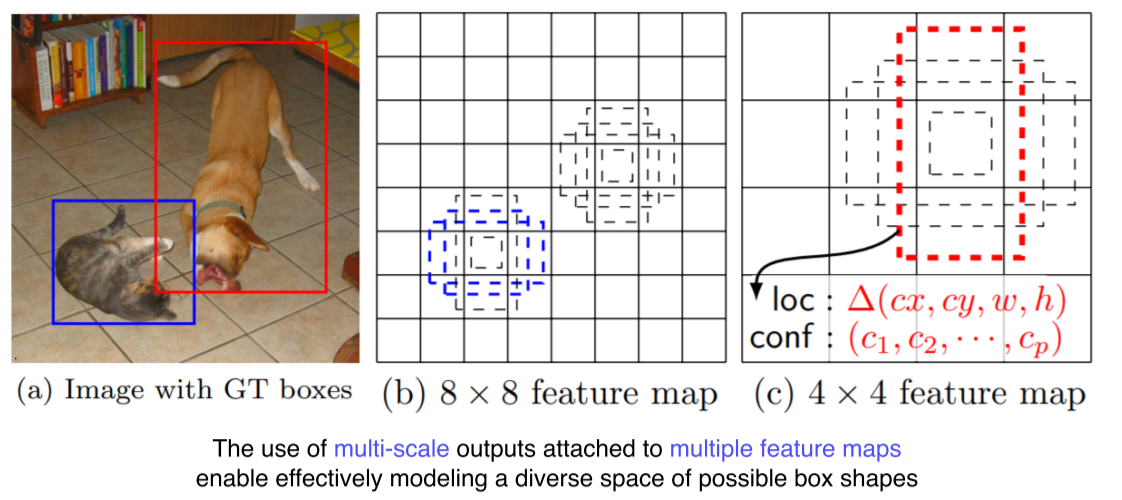
- Multi-scale object를 더 잘 처리하기 위해 중간 feature map을 각 해상도에 적절한 b-box를 출력할 수 있는 multi-scale 구조를 만듬
- 각 scale마다 object detection을 출력하게 해서 다양한 scale의 object에 대해 더 잘 대응할 수 있게 설계함
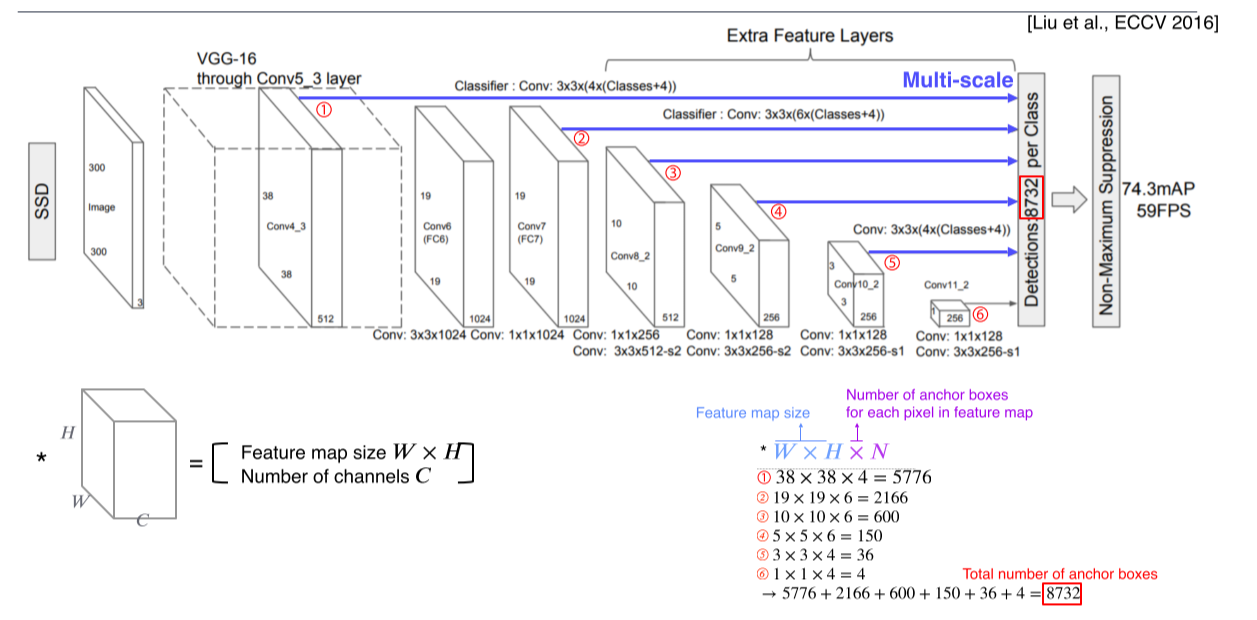
- 각 feature map마다 몇 개의 anchor box가 각 위치마다 존재하는지를 계산 후, 각 layer의 결과를 더해주면 anchor box들의 총 숫자가 나옴
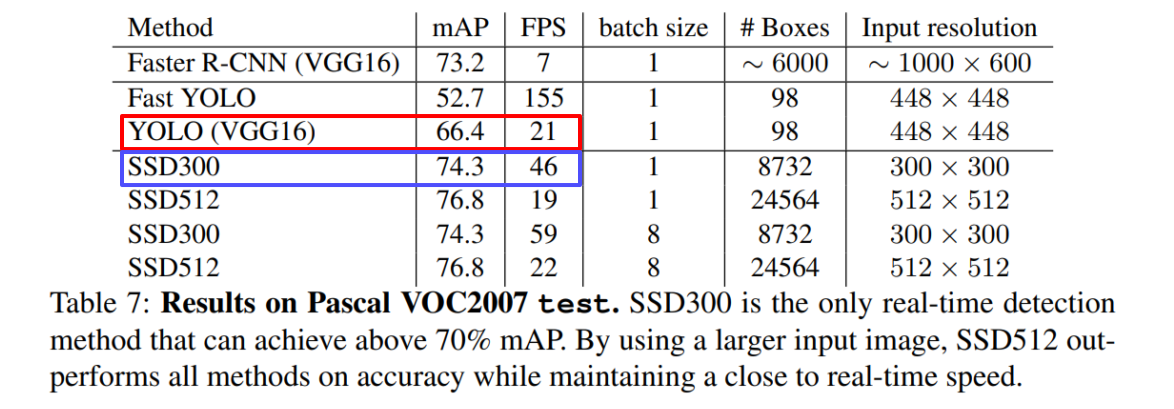
- Faster R-CNN, YOLO보다 훨씬 빠르고 성능도 좋음
Single-stage vs two-stage
Focal loss
-
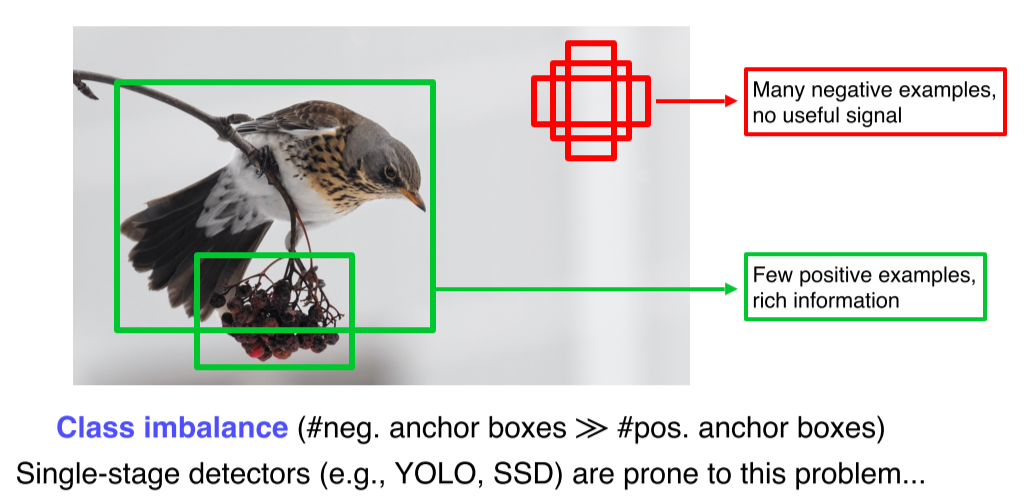
Single-stage는 RoI pooling이 없기 때문에 모든 영역에서의 loss가 계산되고, 일정 gradient가 발생
-
실제 필요한 것은 object에 대한 b-box인데 배경도 다 b-box가 만들어져 고려되기 때문에 class imbalance가 발생
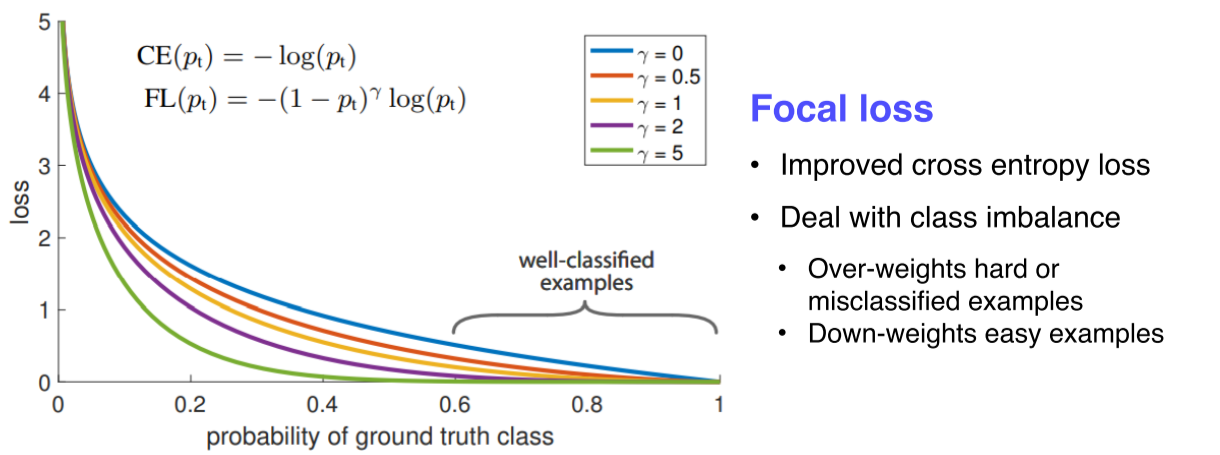
-
Focal loss는 cross-entropy loss의 확장
-
가 클수록 잘 맞추면 gradient가 0에 가까워 무시되고, 못 맞추면 sharp한 gradient가 발생해 큰 영향을 줌
-
어렵고 잘못 판별된 예제들에 대해선 강한 weight를 주고, 쉬운 것들에 대해서는 작은 weight를 줌
RetinaNet
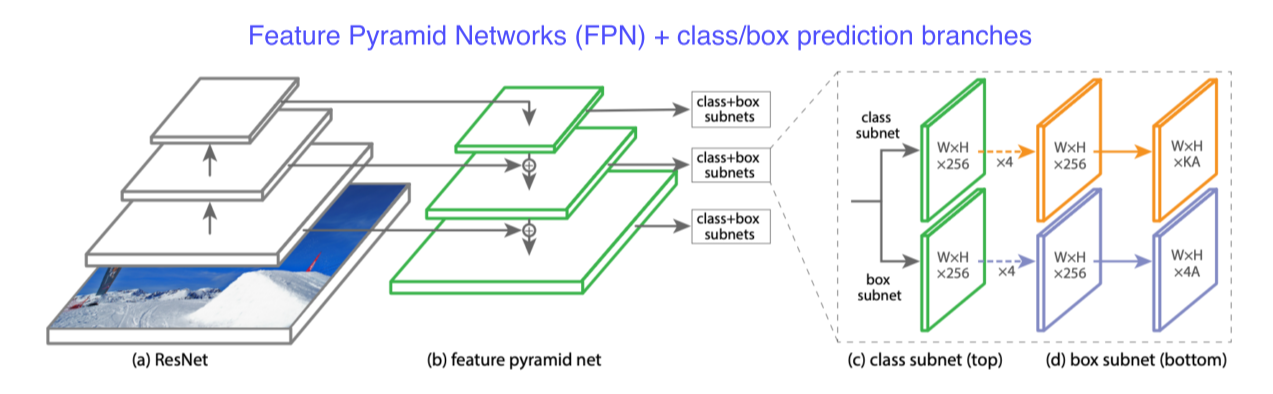
-
low level의 특징 layer들과 high level의 특징을 둘 다 잘 활용하면서도 각 scale별로 물체를 잘 찾기 위한 설계
-
U-Net과 달리 concat이 아니라 add
-
class, box head가 각각 구성돼서 classification과 box regression을 dense하게 각 위치마다 수행
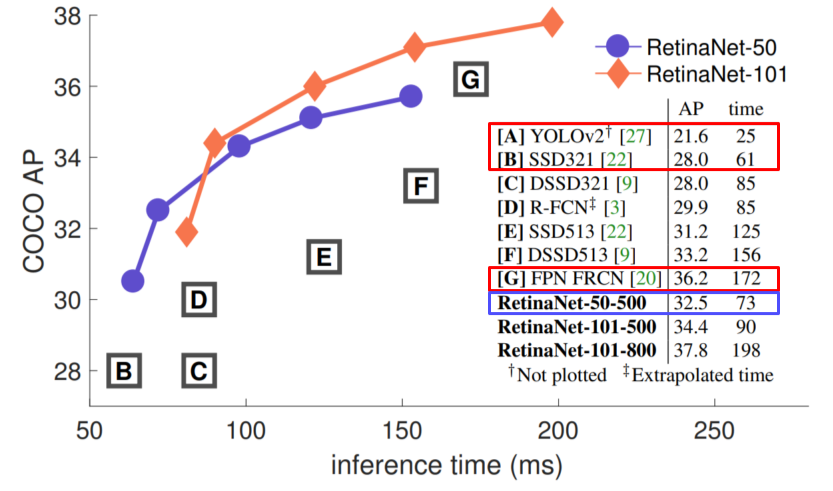
- SSD보다 빠르면서 성능이 좋음
Detection with Transformer
DETR
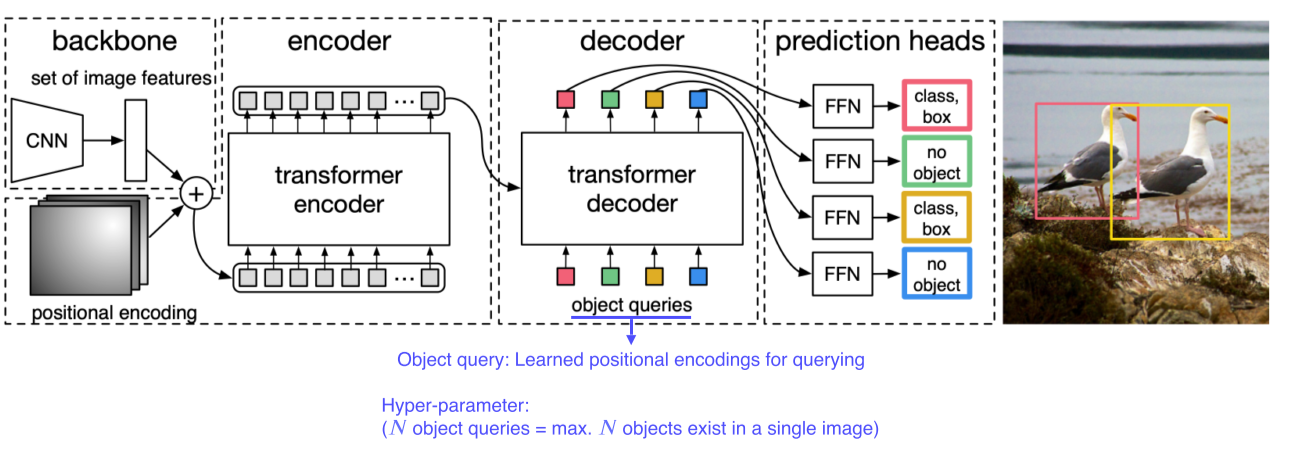
-
Transformer를 object detection에 적용한 사례
-
CNN의 feature map과 각 위치를 multi dimension으로 표현한 encoding을 섞어 입력토큰을 만듬
-
Encoding된 feature들을 decoder에 넣으면, query(각 위치)에 해당하는 물체가 무엇인지 b-box에 대한 정보와 함께 parsing돼서 나온다
Further reading

- 요즘엔 b-box regression을 하지 말고 다른 형태의 데이터 구조로 탐지가 가능한지 연구중
Reference

