Data Preprocessing
1.EDA & Data Profiling

EDA를 짧게 하는 걸 추천하지 않아요! 데이터를 많이 볼수록 기억에 오래 남는다, 데이터를 문자나, 숫자보다는 그래프를 활용하여 직관적으로 파악EDA(Exploratory Data Analysis)라고 함수집한 데이터를 분석하기 전에 그래프나 통계적인 방법을 이용하여
2.Missing Values
(개념) 데이터의 값이 누락된 것 = 결측값, Missing Values(표기) NA, N/A(Not Applicable or Not Available), NaN(Not a Number), Null(발생원인) 전산오류, 입력 누락, 인위적 누락 설문조사(survey)와
3.Outliers
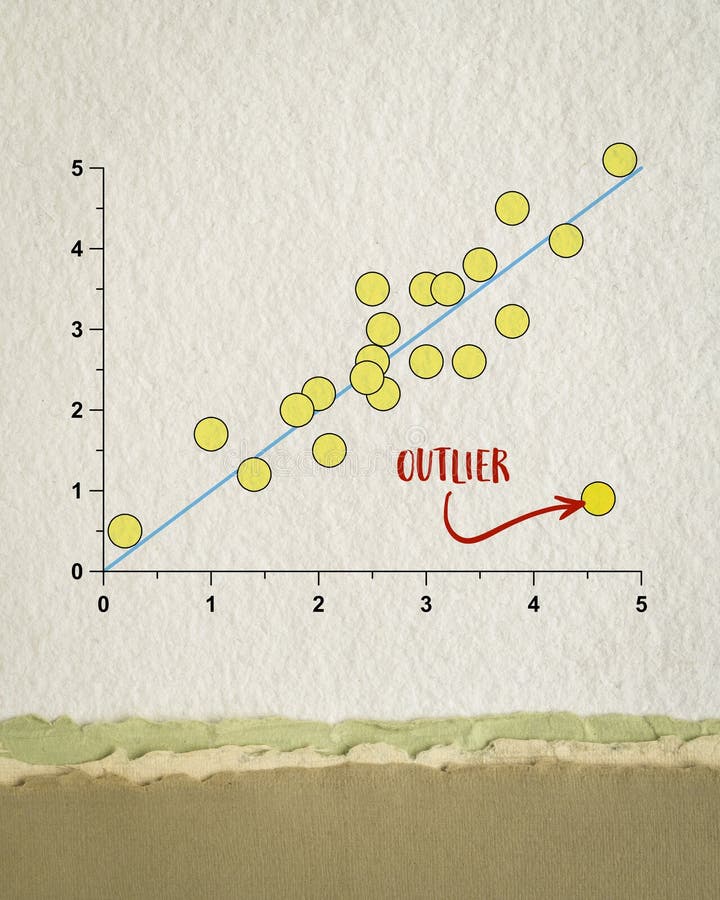
일부 관측치의 값이 전체 데이터의 범위에서 크게 벗어난 극단적인 값을 갖는 것 분산을 과도하게 증가시켜 검정력, 예측력 등 통계적 특성을 악화시킴 전체 데이터수가 많으면, 이상치의 영향이 감소함
4.Denoising
측정된 변수에 무작위의 오류(random error) 또는 분산(variance)이 존재하는 것데이터의 품질을 향상시키고 분석의 정확도를 높이기 위해서 노이즈를 제거할 필요가 잇음정형 데이터에서 노이즈는 분산(variance)으로 나타남분산은 데이터의 무작위 변동을 의
5.Scaling
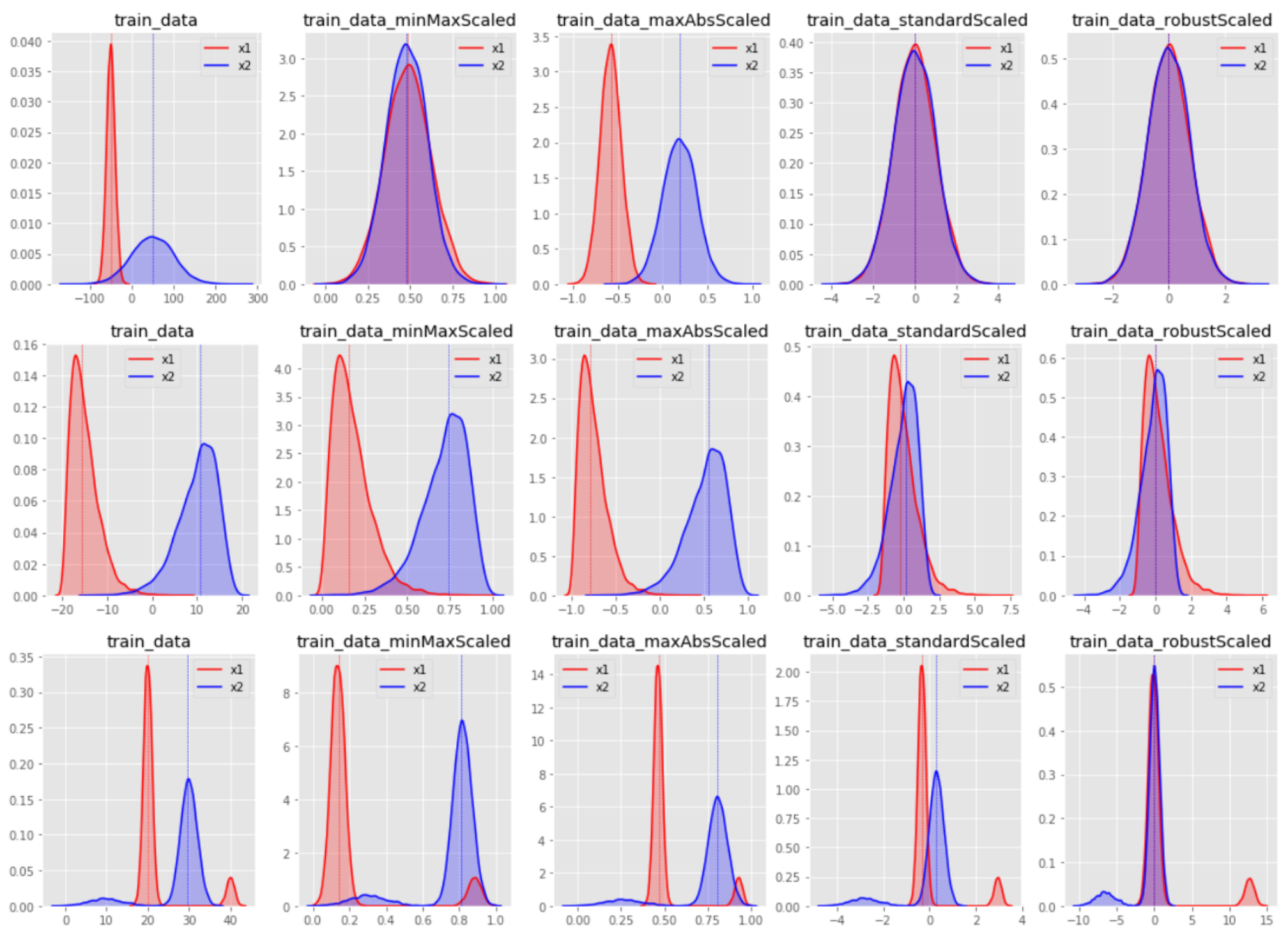
데이터의 범위를 조정하는 과정 다양한 특성들이 서로 다른 범위와 단계를 가질 때 이를 일관된 범위로 조정하여 모델이 효율적으로 학습할 수 있도록 함
6.Encoding & Discritization
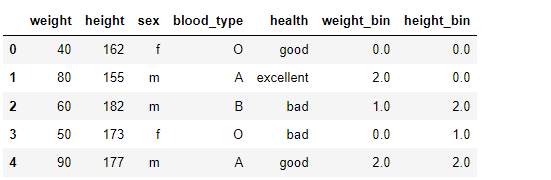
* 많은 실제 데이터셋에는 수치형(numerical)과 범주형(categorical) 변수가 혼재하고 있음 * 인코딩은 컴퓨터가 처리하기 용이하도록 기존의 데이터를 변경하는 것 * 범주형 데이터는 일반적으로 텍스트(string)로 되어 있으므로 이를 숫자(일반적으로 양
7.Feature Engineering(1) - 피쳐추출
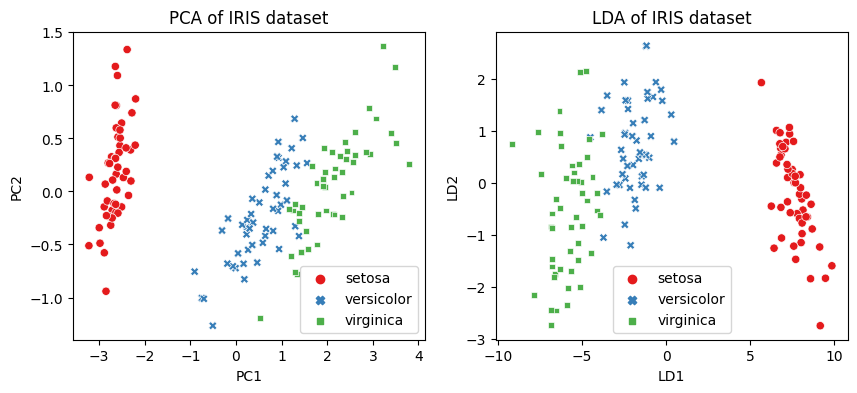
피쳐들 사이에 내재한 특성이나 관계를 분석하여 이들을 잘 표현할 수 있는 새로운 선형 혹은 비선형 결합 변수를 만들어 데이터를 줄이는 방법고차원의 원본 피쳐 공간을 저차원의 새로운 피쳐 공간으로 투영PCA(주성분 분석), LDA(선형 판별 분석)
8.Feature Engineering(2) - 피쳐선택
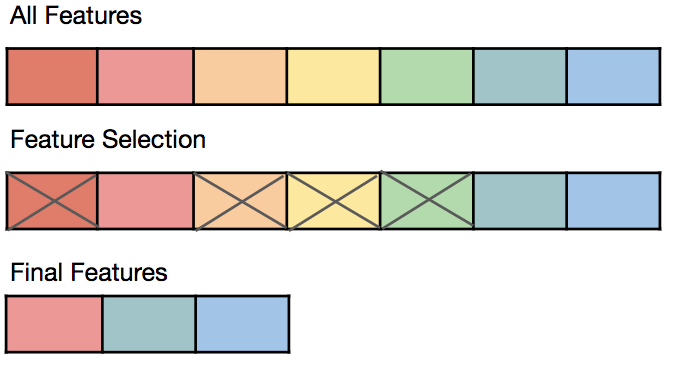
피처 선택은 타겟(목표값, Target)과 가장 관련이 높은 변수만을 선정하여 피쳐의 수를 줄이는 방법으로, 관련이 없거나 중복되는 피쳐들을 필터링하고 간결한 부분집합을 구성하는 과정이다. 이는 모델을 단순화해주고, 훈련 시간을 축소해주며 차원의 저주를 방지, 과적합을
9.Pipeline
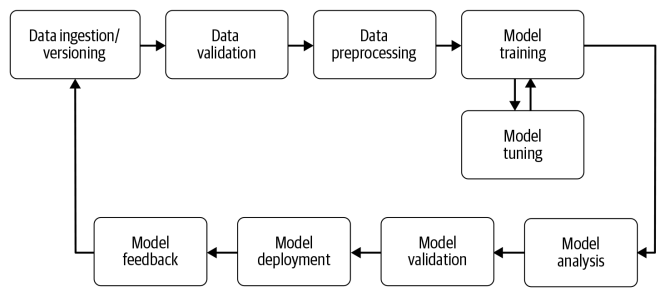
10.1 파이프라인이란? 10.1.1 파이프라인 여러 개의 데이터의 처리(preprocessor, classifier, regressor, estimator 등)를 하나의 처리과정(pipeline, sequence)으로 만들어 데이터를 일괄처리해 주는 기능 데이터
10.Imbalanced Data
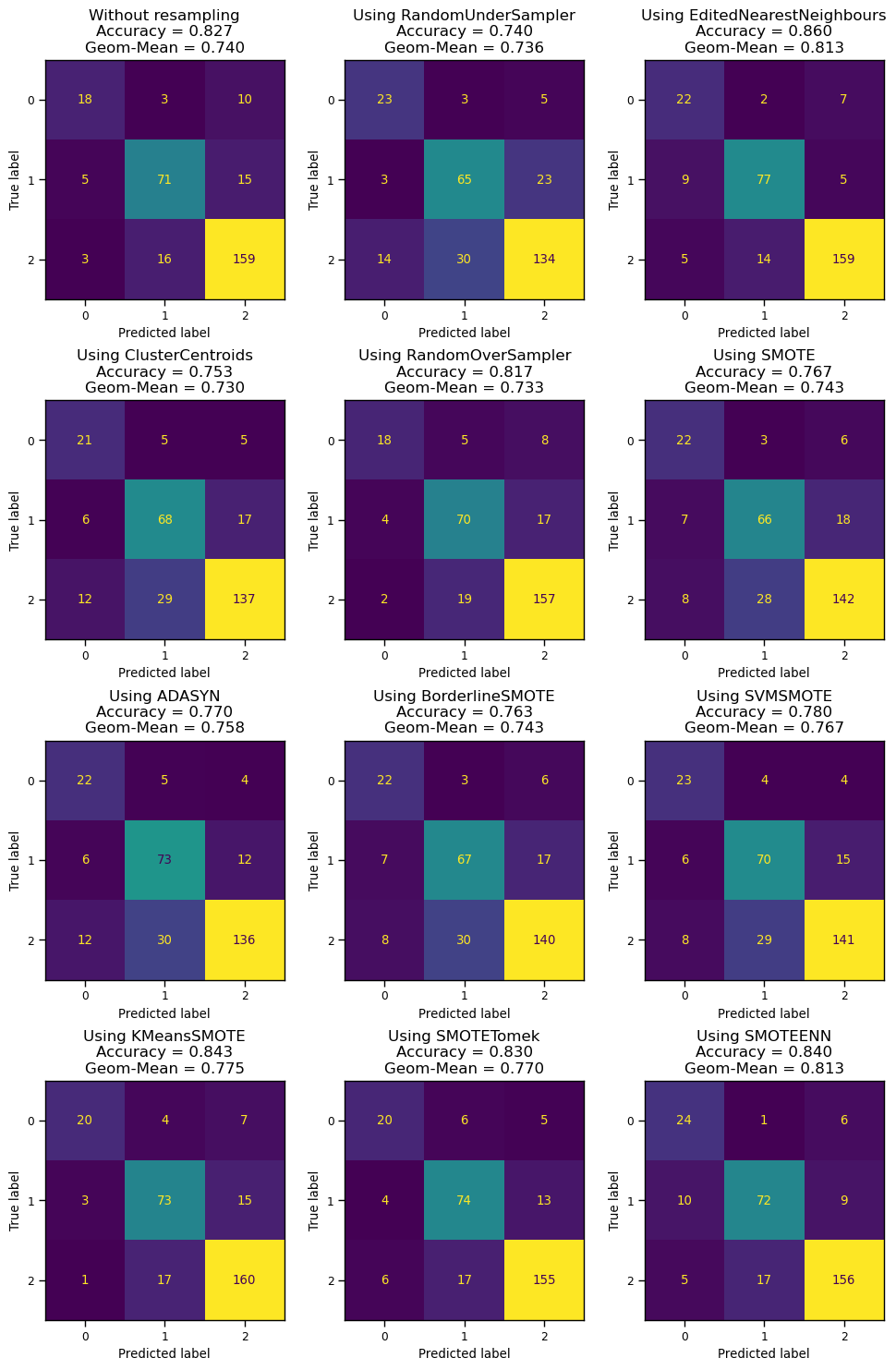
분류 문제에서 타겟 데이터의 범주가 한 쪽으로 치우친 데이터일반적으로 정상 데이터에 비해 이상 데이터가 매우 적은 경우 \- ex1. 양품 데이터에 비해 불량 데이터가 적은 경우ex2. 중상 사고 데이터에 비해 사망사고 데이터가 적은 경우 불균형 데이터는 모델의 성