이 포스트는 Micigan Online 강의를 기반으로 작성하였습니다.
Object Detection 용어
-
Bounding Box (경계 상자)
물체를 감싸는 사각형 영역을 의미. 주로 [x_min, y_min, x_max, y_max] 또는 [x_center, y_center, width, height] 형식으로 표현된다. -
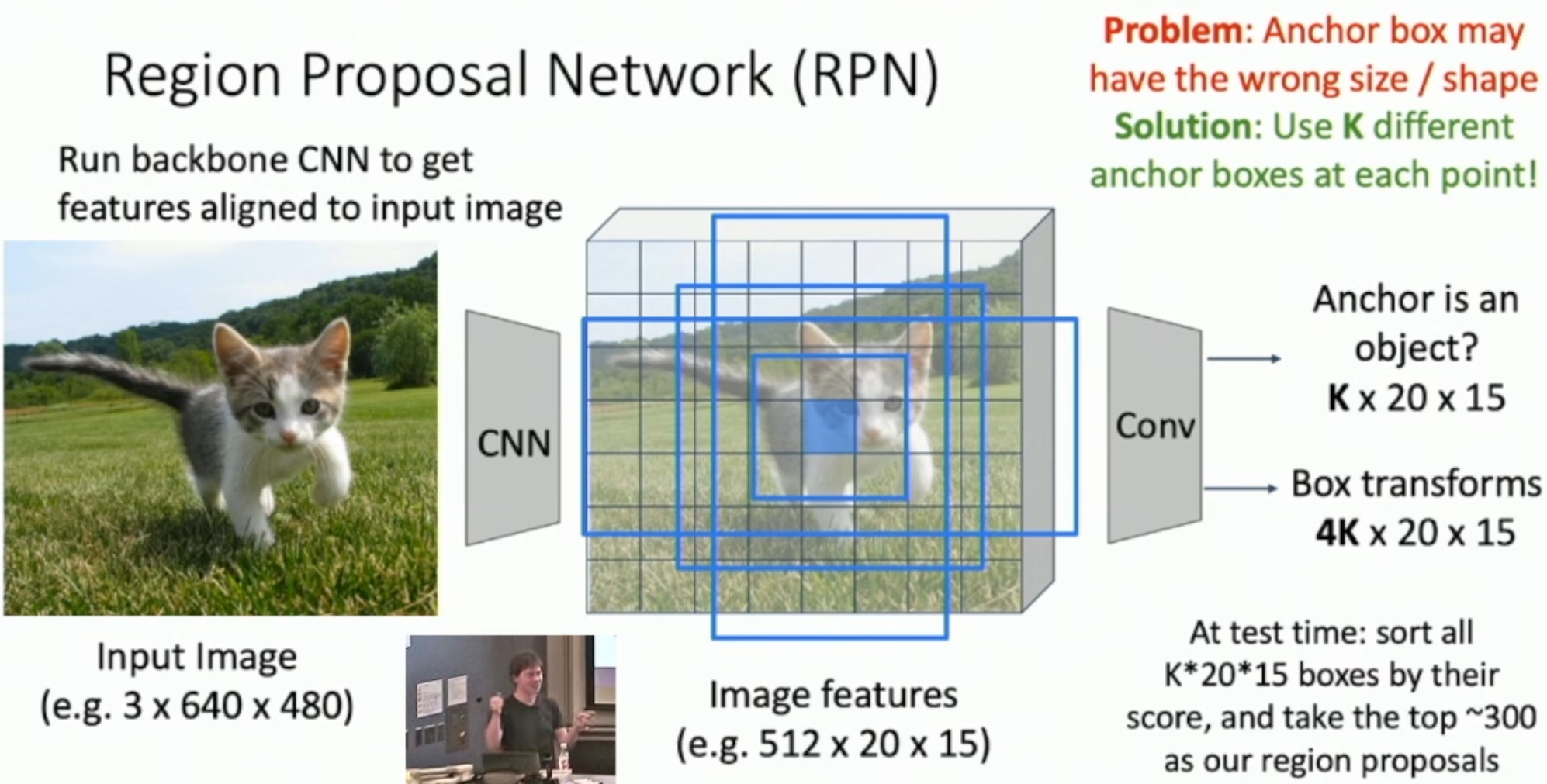
Anchor Box (앵커 박스)
이미지 내의 특정 위치에 사전 정의된 크기와 비율을 가진 고정된 박스이다. Region Proposal Network(RPN)에서 각 위치마다 여러 크기와 비율의 앵커 박스를 생성한다.
-
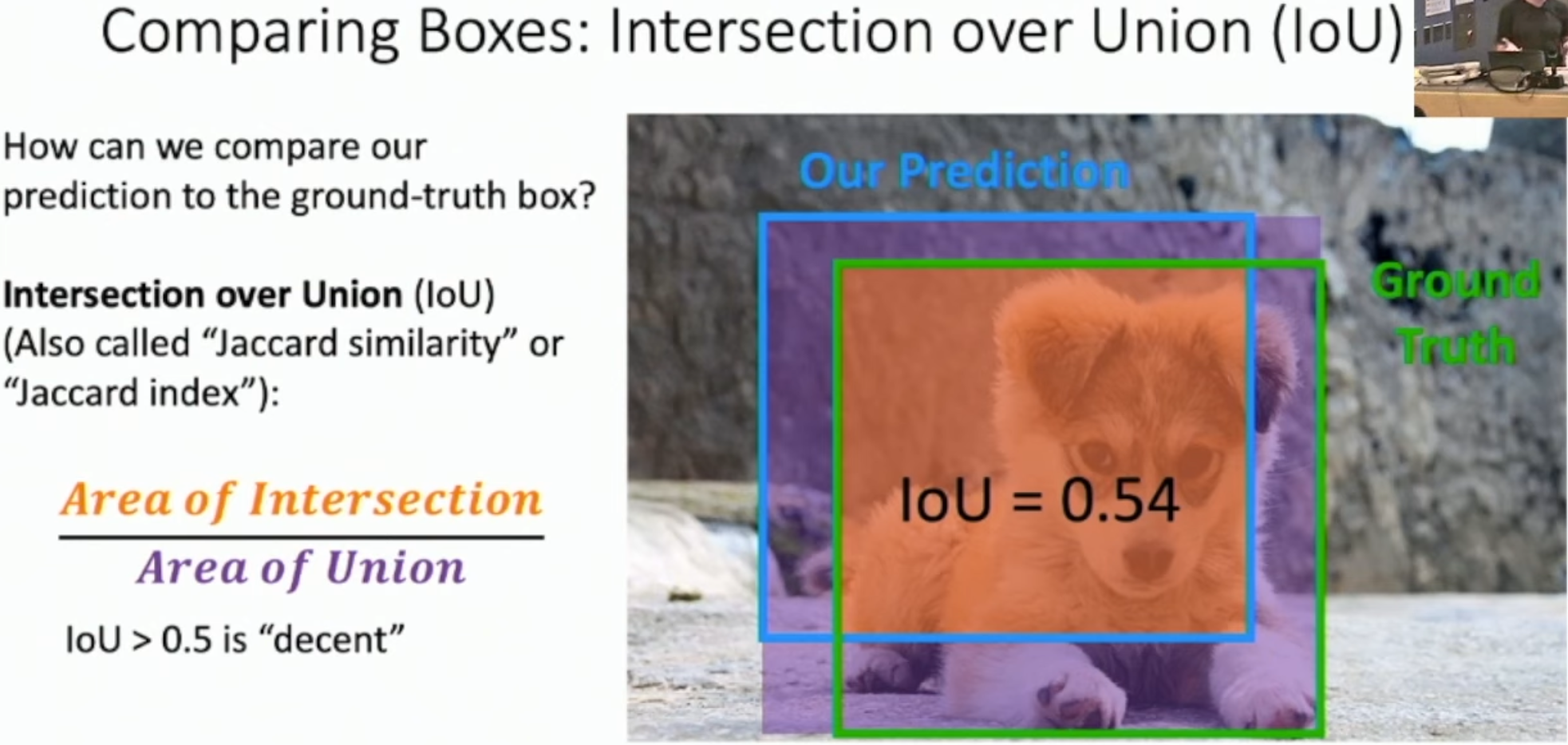
Intersection over Union (IoU)
두 개의 경계 상자 간의 겹치는 영역을 계산하는 지표이다. IoU는 두 박스의 교집합을 합집합으로 나눈 값으로, 모델의 예측 박스와 실제 박스의 일치도를 측정하는 데 사용된다.
-
Region Proposal
이미지 내에서 물체가 있을 가능성이 높은 영역을 제안하는 과정입니다. RPN이 주로 이 작업을 수행한다. (이전에는 해당 기법을 잘 하기위한 다양한 알고리즘들이 나왔다.) -
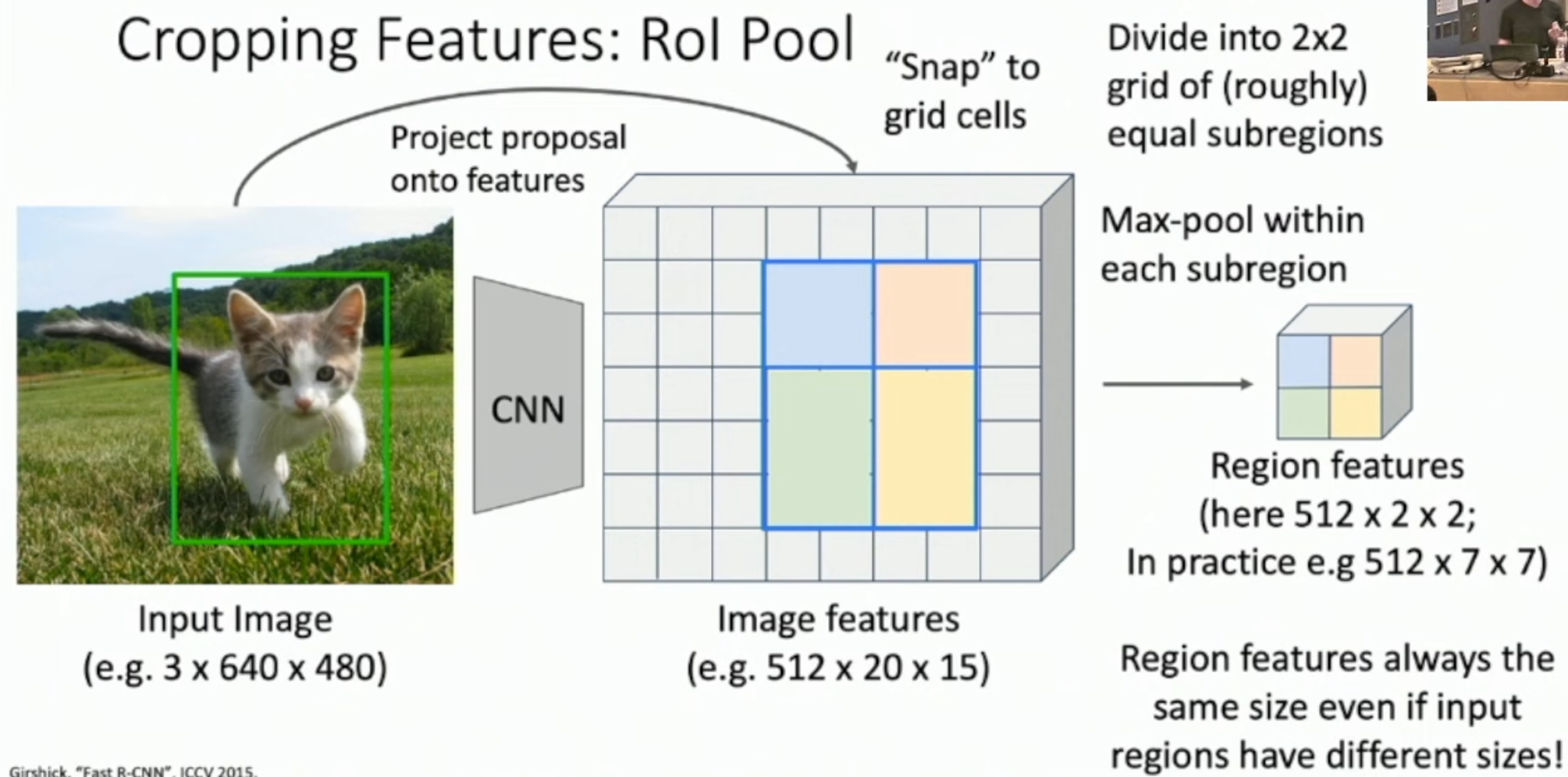
RoI Pooling (Region of Interest Pooling)
다양한 크기의 region proposals를 고정된 크기의 특징 맵으로 변환하는 과정이다. 이를 통해 CNN의 다음 계층에 입력될 수 있다. 자세히는 RoI가 정사각형이 아닐 수 있기 때문에 snapping(or RoI Align)을 통해 격자를 맞춰주고 2x2로 만들고 싶다면 RoI를 2x2로 가장 비슷하게 나눌 수 있도록 맞춘 후 pooling을 수행한다.
-
Non-Maximum Suppression (NMS)
예측된 여러 박스 중에서 중복된 박스를 제거하고, 가장 높은 점수를 가진 박스를 선택하는 과정이다. 주로 동일한 물체를 여러 번 예측하는 것을 방지한다.

-
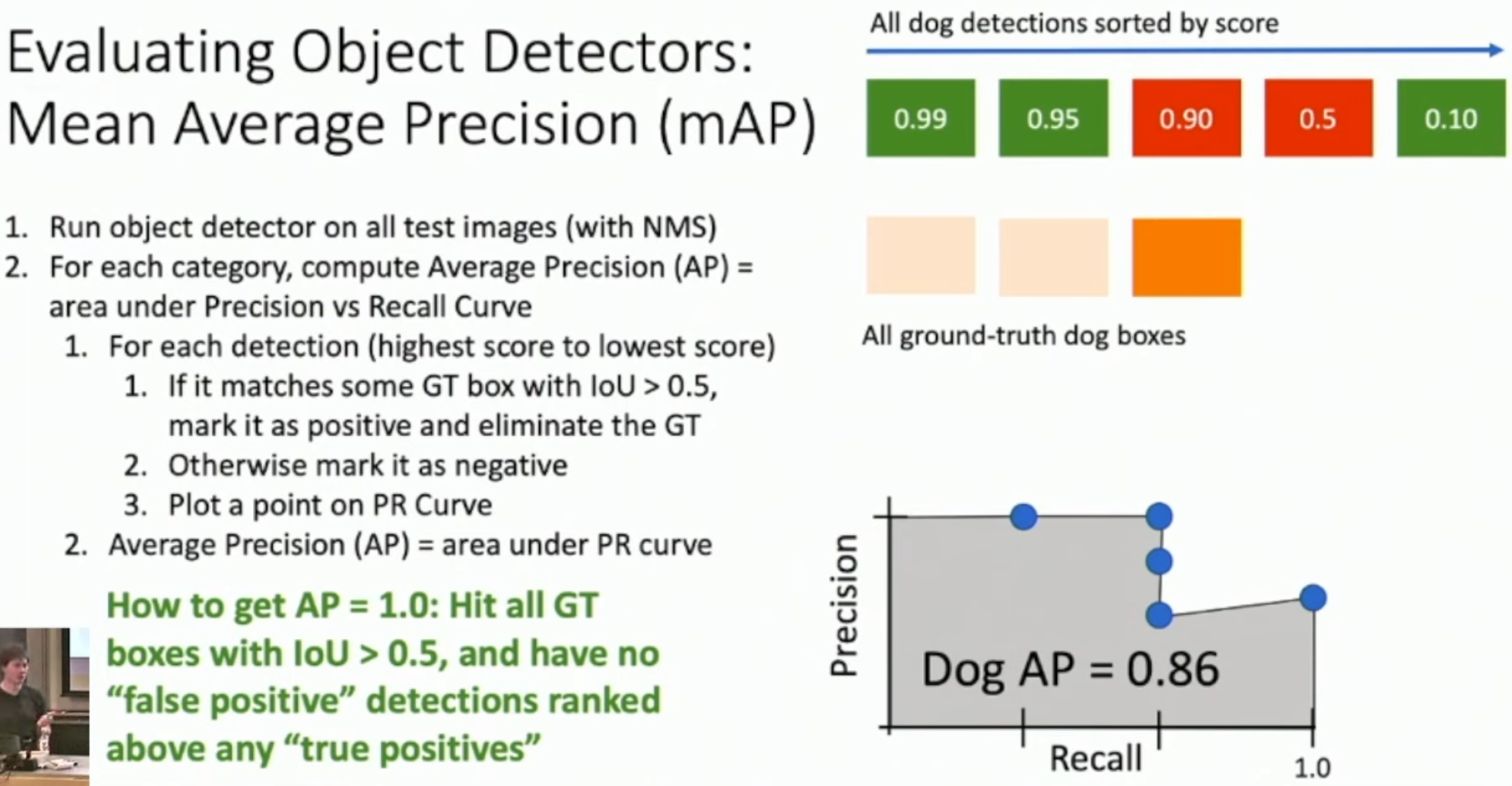
mAP (mean Average Precision)
다양한 IoU 임계값에서 모델의 평균 정밀도를 측정한 값이다. Object detection 성능을 평가하는 주요 지표이다.

-
Objectness Score
특정 앵커 박스가 물체를 포함하고 있을 확률을 나타내는 점수이다. RPN에서 각 앵커 박스에 대해 예측한다. -
Classification, Regression
Classification은 Softmax, Sigmoid의 출력값을 실제 정답값과 Entropy Loss등을 통해 학습할 수 있고, Regression은 L1 Loss의 차이로 학습할 수 있다.
이제 Object Detection의 시작인 R-CNN을 살펴보자.
R-CNN
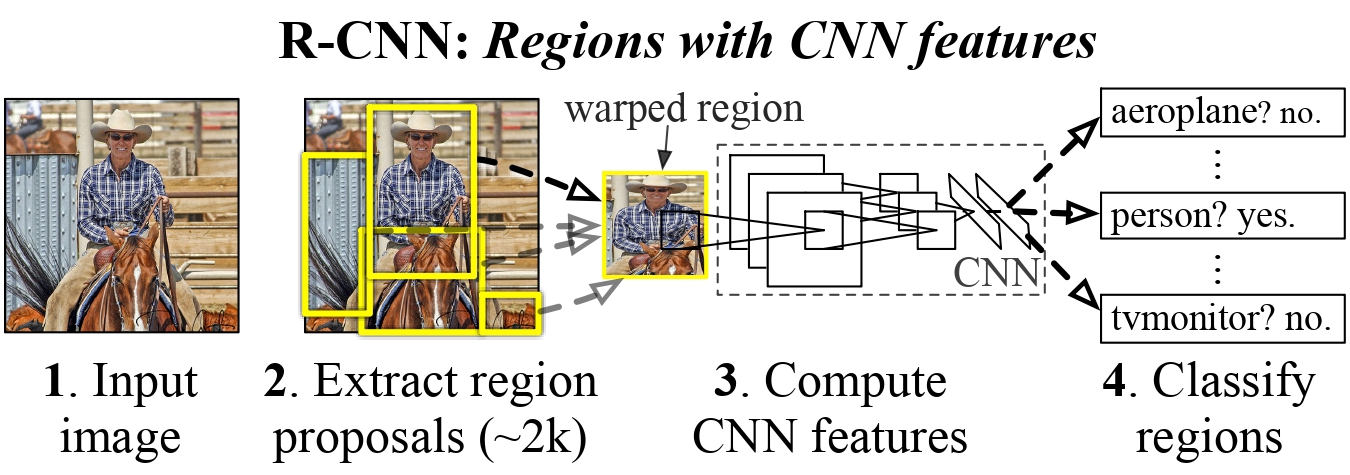
Input image를 Resion Proposal 알고리즘을 통해 추출 및 크기 조정 후 CNN 모델을 통해 Classification과 Regression을 수행한다. 보다 자세히 살펴보기 위해 아래의 그림을 보자.
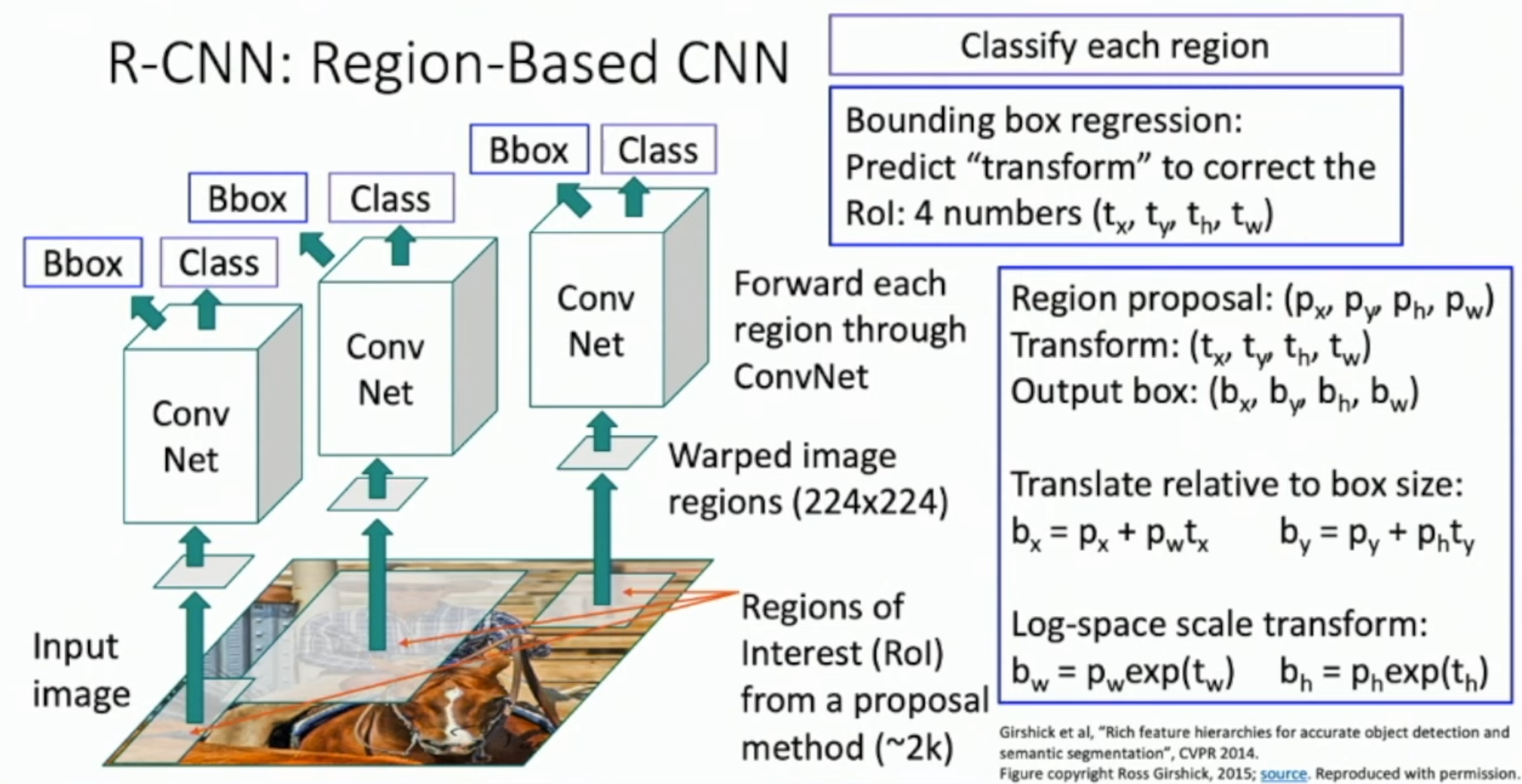
Box Regression의 경우 Transform 값을 찾는다. 왜 직접적으로 output box를 찾지 않고 transform 값을 찾을까?
- 학습의 안정성
앵커 박스와 ground truth 박스 사이의 상대적인 변화를 학습하기에 절대적인 좌표와 크기를 예측하는 것보다 더 안정적이다. 예를 들어, 작은 위치 변화와 크기 변화를 학습하는 것이 큰 절대값을 직접 예측하는 것보다 더 일관된 학습 결과를 제공한다.
아래의 GPT-4o 의 예시를 보자.


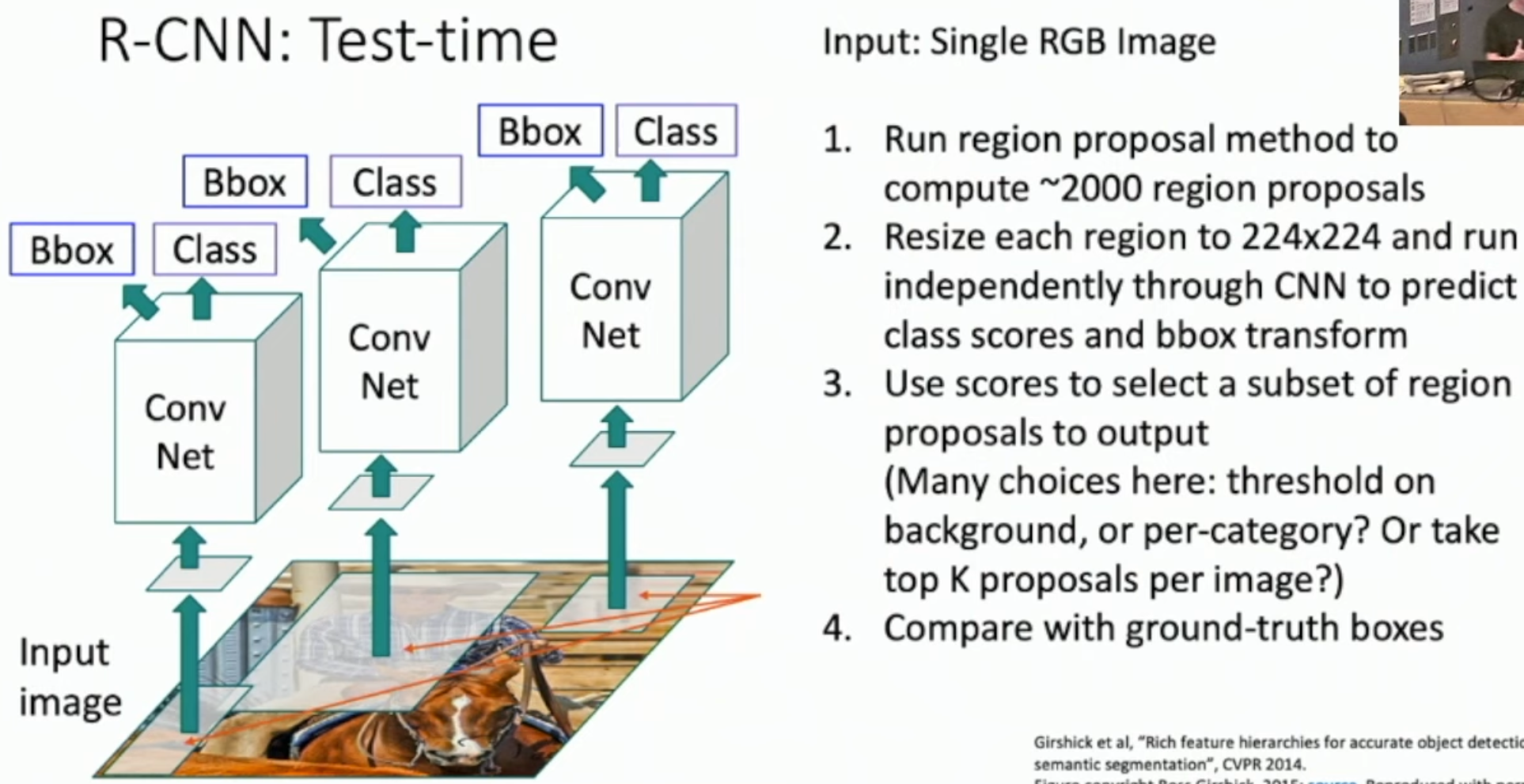
학습이 끝난 후 Test-time은 아래와 같이 수행된다.
Fast R-CNN
Fast라는 수식어가 붙었다. 차이는 Region Proposal과 ConvNet Backbone의 위치 차이이다. Fast R-CNN은 ConvNet 을 통과한 latent feature map에서 Resion Proposal을 수행하기 때문에 압도적으로 빠른 속도를 보여준다.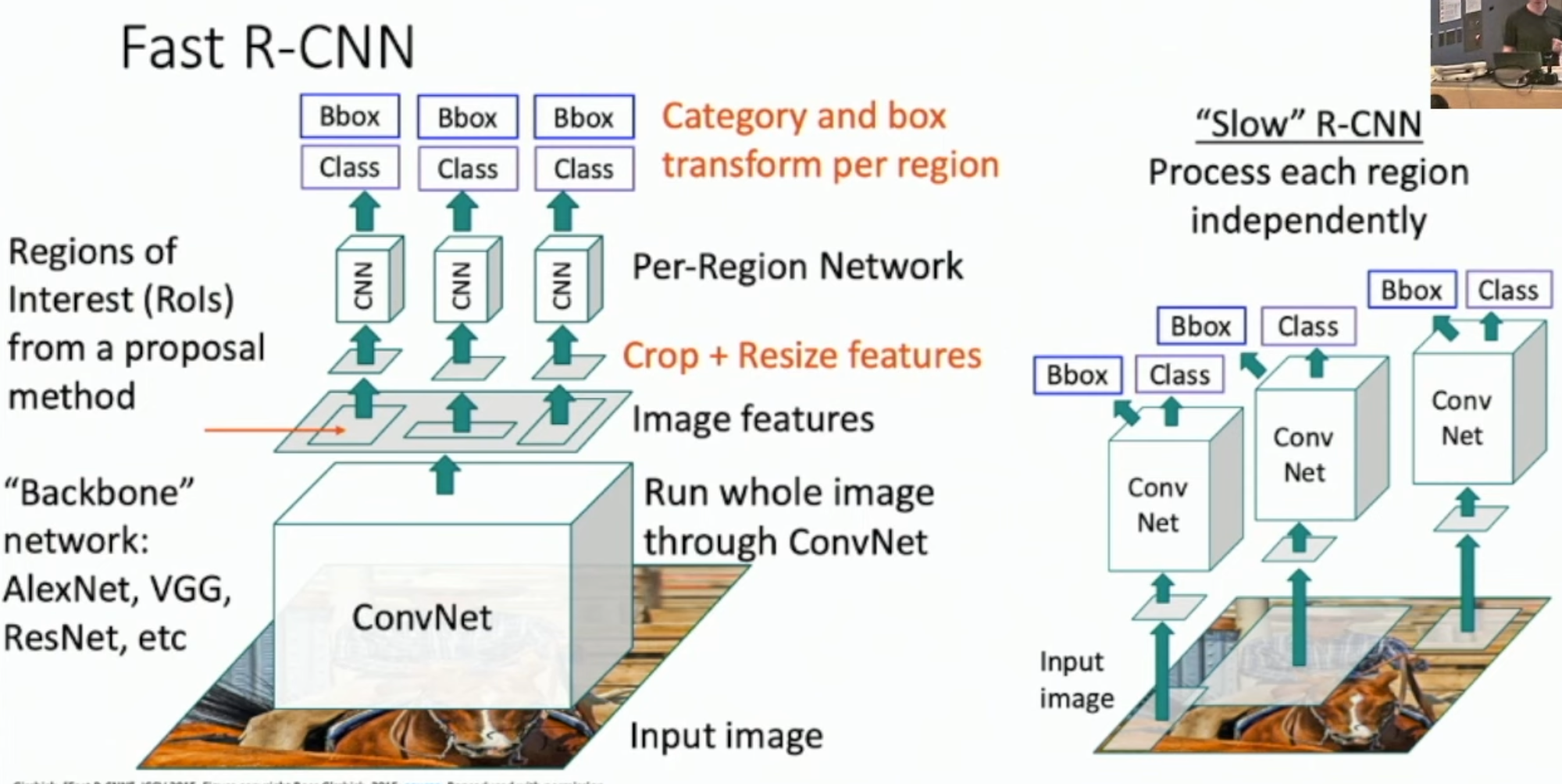
그리고 feature map 에서 region proposal 은 크기가 전부 다를 수 있다. 그러면 이를 그냥 resize, crop을 하게 된다면 역전파시 미분이 불가능하다는 문제가 생긴다. 따라서 Region of Interest Pooling 을 통해 해결한다.
Faster R-CNN
이제 수식어가 더 추가되었다. Faster!! 이는 Region Proposal을 알고리즘을 통해 추천하는 것이 아니라 Network로 학습하여 추천하자는 접근이다. 그리고 이때 사용되는 CNN 구조는 정말 간단한 구조로 설계하여 아주 빠르게 이미지에 적합한 Region을 추천해줄 수 있다.
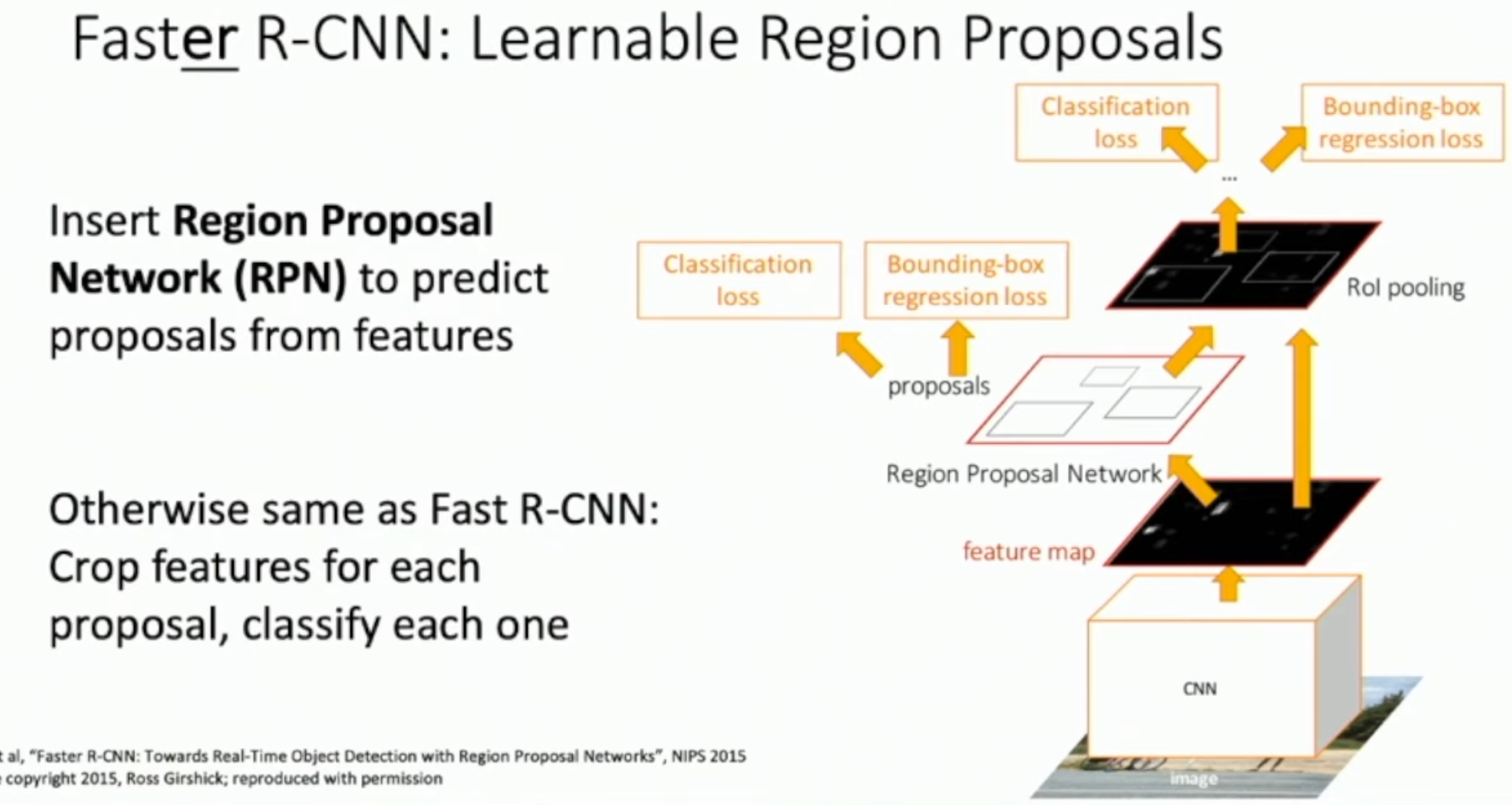
Faster R-CNN은 RPN 이 제안하였다. RPN이 중요하기에 조금 더 자세히 다뤄보자.
Anchor Box
앵커 박스가 무엇일까? 앵커는 닻이다. 따라서 feature map에 box마다 anchor를 내려서 해당 픽셀에 고정된 box라고 생각하면 된다.
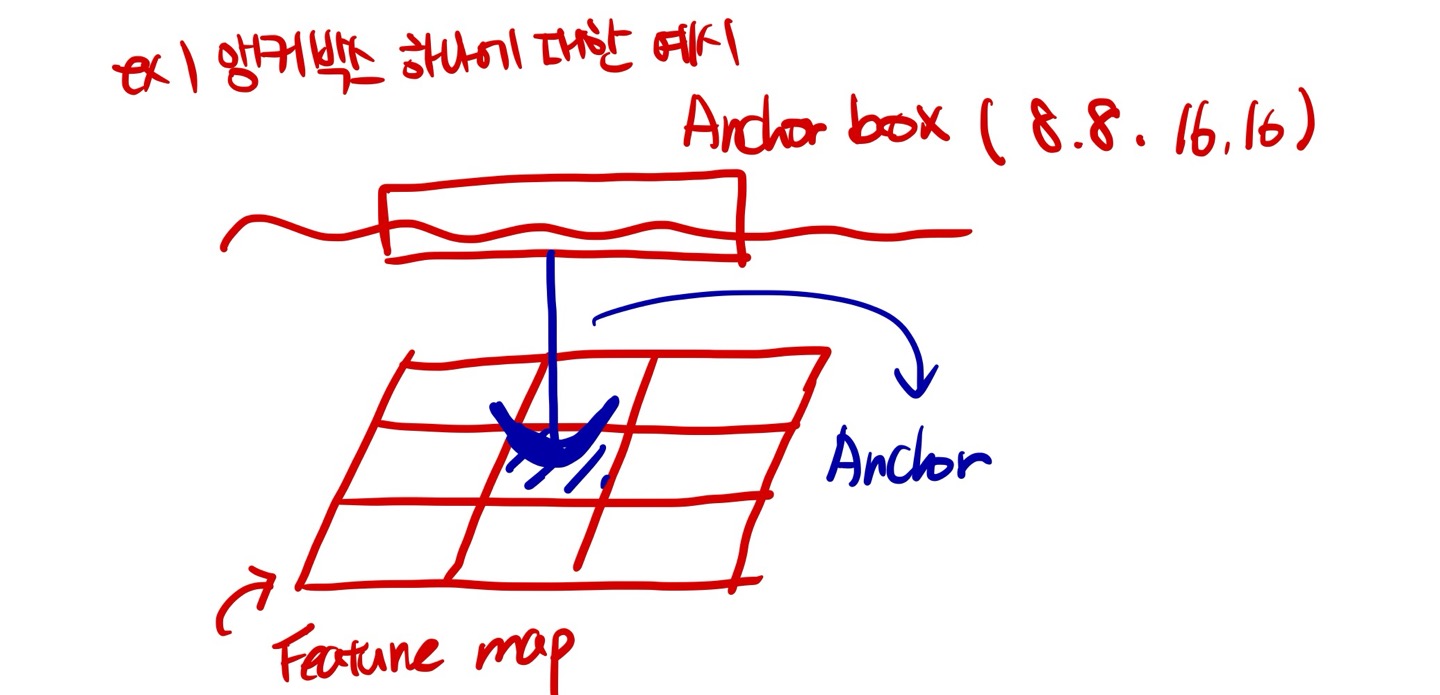
하나의 픽셀당 여러 개의 닻을 내릴 수 있고 scale과 tranform ratio 가 각각 3개라면 하나의 픽셀 당 9개의 박스가 존재하며 9개의 닻을 내릴 수 있다.

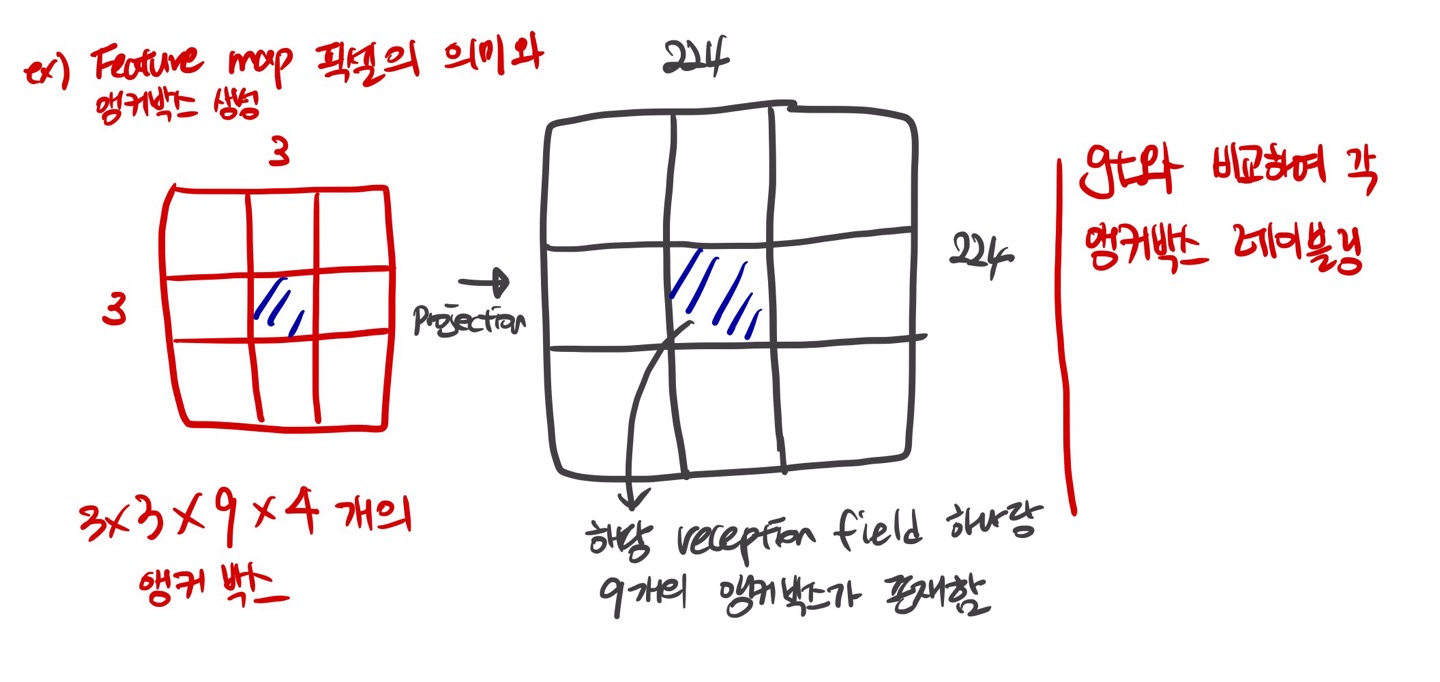
그러면 앵커 박스를 어떻게 만들까? 핵심은 닻은 feature map의 픽셀에 의존하고 각 픽셀 당 앵커 박스의 크기는 원본 이미지의 크기에 의존한다. 즉, "feature map의 한 픽셀 당 9개의 앵커 박스를 만든다"는 말은 feature map의 픽셀마다 앵커 박스를 만들기 때문에 feature map의 픽셀 개수에 맞춰서 총 앵커 박스의 개수가 만들어진다. 이때 앵커 박스의 크기는 해당 픽셀의 원본 이미지의 reception field 에서 9개가 생성되며 이때 4가지 값(x,y,w,h)으로 표현된다. 그리고 각 앵커박스당 실제 ground truth와 IoU 계산 및 thresholding을 통해 객체가 있으면 positive 없으면 negative를 레이블링을 부여한다. Thresholding은 보통 0.3 ~ 0.7 사이값으로 부여한다.
RPN Training
학습 단계를 크게 나눠보면
1. 원본 이미지에 맞춘 Translation-Invariant Anchors 생성
2. 미니 배치 학습에 사용할 Anchor boxes 추리기 (이때, 각 앵커 박스에 따른 positive, negative label 을 부여 = 정답값)
3. CNN Backbone (i.e. Vgg18) 을 거친 feature map 에서 3x3 conv 를 거친 후 1x1 conv 를 통해 classification과 regression 을 위한 RPN 을 학습한다.
여기서 헷갈릴 수 있는데, 이때 box regression의 경우 feature map의 픽셀 하나에 대해서 실제 박스의 크기를 예측한다 (x,y,w,h).
1, 2 단계는 위의 Anchor box에 대한 설명과 동일하다. 3단계는 아래의 그림과 같다.(DSBA연구실 소규성님 발표자료의 일부입니다.)
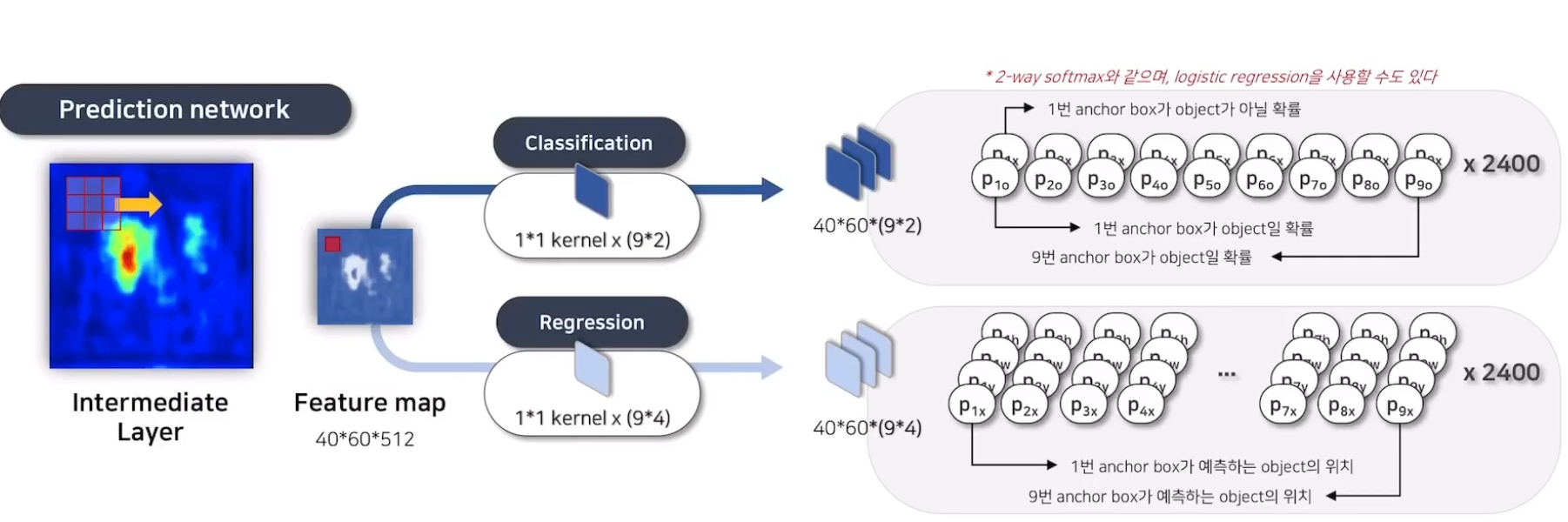
출력값에 대해서 아래의 Multi-task loss를 통해 학습과정 루프가 완료된다.
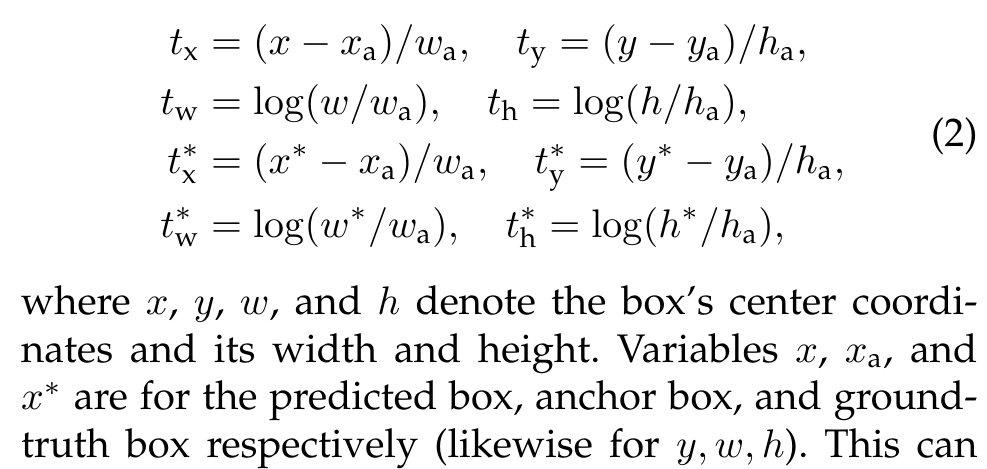
조금 눈여겨 볼 점은 실제 박스의 크기를 예측함을 알 수 있다.
Region Proposal Network(RPN) 의 학습을 간략하게 설명하면 카테고리를 구분하지 않고 단순히 object를 담고 있는지 안 담고 있는지 판단해서 학습하는 것이다. 그렇게 해서 next step에 예측을 한다면, 이를 Two-stage 방식이라고 한다.
그러면 더 빠른 속도를 내기 위해서는 어떻게 하면 좋을까? 특정한 class를 담고 있는지 안 담고 있는지를 앵커 박스 단계에서 학습하면 된다. 이때 개수는 C개의 클래스와 K개 모양의 앵커 박스와 이러한 앵커 박스를 픽셀 개수만큼 가진다. 여기서 C+1 인 이유는 아예 object가 포함되어있지 않을 수 있기 때문이다. 즉, region proposal 단계를 압축했다고 볼 수 있다.

One-Stage Vs Two-Stage
Region proposal만 해주는 RPN 네트워크와 이를 바탕으로 classification, regression하는 two-stage 방식과 한번에 앵커 박스에 대해서 classification, regression을 하는 것에 장단점이 무엇일까?
-
Two-Stage vs Single-Stage
Two-Stage 방법에서는 RPN이 단순히 객체가 있는지 여부만 판단하고, RoI Pooling 후 두 번째 단계에서 클래스와 경계 상자를 세부적으로 예측한다.
Single-Stage 방법에서는 단일 단계에서 앵커 박스의 클래스와 경계 상자를 동시에 예측한다. 이는 속도 면에서 더 효율적이지만, 복잡한 장면에서 정확도가 떨어질 수 있다. -
정보의 전달
Two-Stage에서는 RPN이 객체가 있는지 여부만 판단하기 때문에, RoI Pooling 이후의 단계에서 클래스 정보를 세부적으로 예측한다.
Single-Stage에서는 처음부터 클래스와 경계 상자를 동시에 예측하기 때문에, 앵커 박스의 클래스 정보가 직접적으로 전달된다.
대표적인 one-stage 방식이 Yolo 모델이다.
다음은 Segmentation과 advanced computer vision에 대해 다뤄보고자 한다!!
