Grokking the Machine Learning Interview - Recommendation System (3) Architectural Components
Recommendation System
Grokking the Machine Learning Interview - Recommendation System
3. Architectural Components
대규모 영화 데이터에서는 다단계 순위 문제로 최상의 추천을 생성하는 것을 고려하는 것이 합리적이다.
그 이유는 우리가 선택할 수 있는 영화가 너무나 많기 때문에 개인화된 추천을 제공하려면 복잡한 모델이 필요하다.
그러나 복잡한 모델을 전체 말뭉치(코퍼스)에서 실행하려고 하면 실행 시간과 컴퓨팅 리소스 사용량 측면에서 비효율적이다.
따라서 추천 작업을 두 단계로 나눌 수 있다.
1단계: 후보자 생성 (Candidate generation)
2단계: 생성된 후보자의 순위 (Ranking of generated candidates)
- 1단계에서는간단한 메커니즘을 사용하여 가능한 추천 후보자를 찾기 위해 전체 자료를 선별한다.
- 2단계에서는 1단계에서 제시한 후보자들만을 대상으로 복합적인 전략을 사용하여 개인화된 추천을 제시한다.
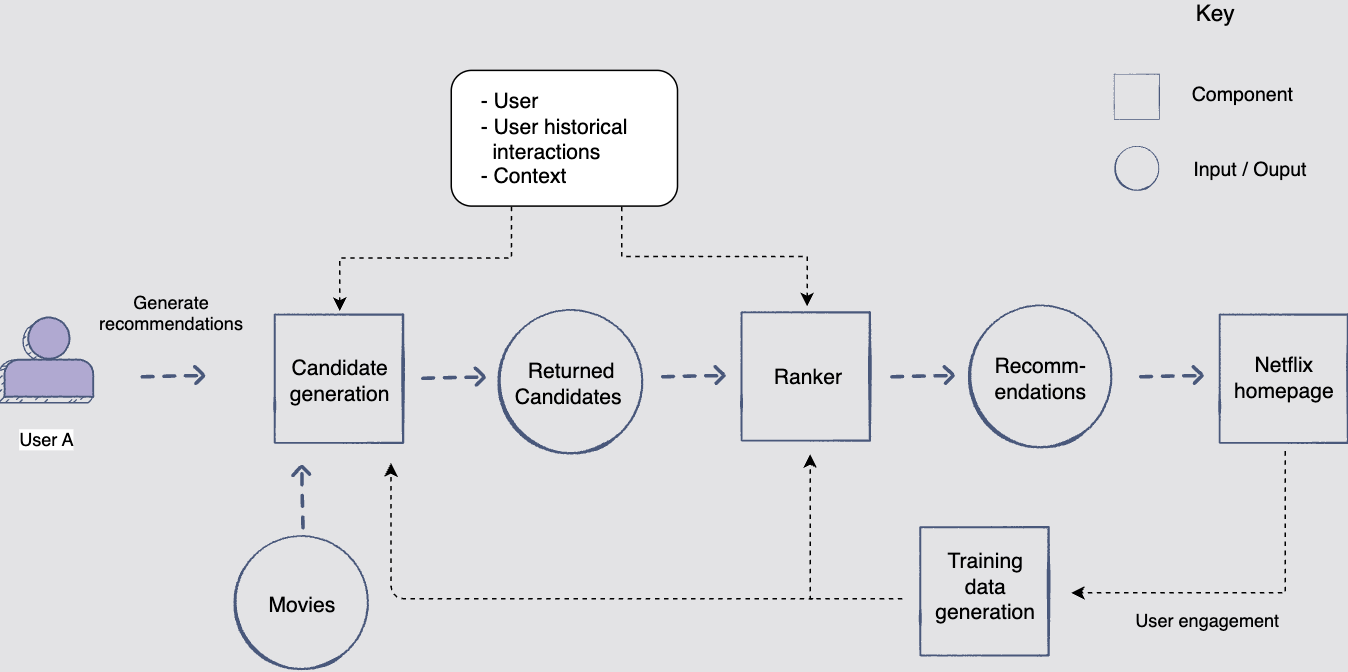
[그림 : Architectural diagram of the recommendation system]
Candidate generation
-
추천을 위한 후보자 생성은 사용자를 위한 추천를 제시하는 첫 번째 단계이다.
-
여러 기술을 사용하여 사용자와 미디어 및 컨텍스트의 과거 상호 작용을 바탕으로 사용자에게 가장 적합한 영화/쇼 후보를 찾는다.
-
📝 이 구성 요소는 더 높은 recall(재현율)에 초점을 맞춘다. 즉, 모든 관점에서 사용자가 관심을 가질 수 있는 영화를 수집하는 데 중점을 둔다.
(예를 들어 과거 사용자 관심 사항을 기반으로 관련된 미디어나 지역 동향 등)
Ranker
-
랭커 구성 요소는 후보자 데이터 생성 구성 요소에서 생성된 후보인 영화 및 쇼가 사용자에게 얼마나 흥미로울지에 따라 점수를 매기는 것이다.
-
📝 이 구성 요소는 더 높은 precision(정밀도)에 중점을 둔다. 즉, 상위 k의 추천 순위에 중점을 둡니다.
-
점수의 직접 비교가 어려운 여러 미디에서 나온 후보자들의 다양한 점수를 앙상블한다.
-
또한 관련성이 높고 개인화된 결과를 보장하기 위해 밀도가 높고 희박한 다른 많은 피처를 사용한다.
Training data generation
- Netflix 홈페이지의 추천에 대한 사용자의 참여는 순위 구성 요소와 후보 생성 구성 요소 모두에 대한 훈련 데이터를 생성하는 데 도움이 된다.
참고사이트
